Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server no Linux
SQL Server no Linux
Este documento descreve como executar as tarefas a seguir para o SQL Server em um cluster de failover de disco compartilhado com o Red Hat Enterprise Linux.
- Fazer failover do cluster manualmente
- Monitorar um serviço SQL Server de cluster de failover
- Adicionar um nó de cluster
- Remover um nó de cluster
- Alterar a frequência de monitoramento de recursos do SQL Server
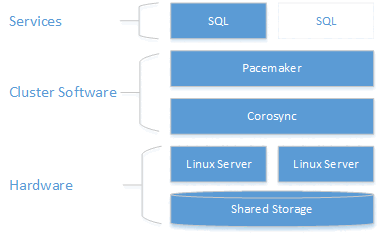
Descrição da arquitetura
A camada de clustering baseia-se no complemento de HA do RHEL (Red Hat Enterprise Linux) criado com base no Pacemaker. O Corosync e o Pacemaker coordenam a comunicação de cluster e o gerenciamento de recursos. A Instância do SQL Server está ativa em um nó ou no outro.
O diagrama a seguir ilustra os componentes em um cluster do Linux com o SQL Server.
Para saber mais sobre configuração de cluster, opções de agentes de recursos e gerenciamento, acesse a Documentação de referência do RHEL.
Fazer failover de cluster manualmente
O comando resource move cria uma restrição que força o recurso a ser reiniciado no nó de destino. Depois de executar o comando move, a execução do recurso clear removerá a restrição, de modo que seja possível mover o recurso novamente ou fazer o failover do recurso automaticamente.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
O exemplo a seguir move o recurso mssqlha para um nó chamado sqlfcivm2 e, em seguida, remove a restrição, de modo que o recurso possa ser movido para outro nó posteriormente.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
Monitorar um serviço SQL Server de cluster de failover
Exiba o status atual do cluster:
sudo pcs status
Exiba o status ativo de cluster e recursos:
sudo crm_mon
Exiba os logs do agente de recursos em /var/log/cluster/corosync.log
Adicionar um nó a um cluster
Verifique o endereço IP de cada nó. O script a seguir mostra o endereço IP do nó atual.
ip addr showO novo nó precisa de um nome exclusivo que tenha 15 caracteres ou menos. Por padrão, no Red Hat Linux, o nome do computador é
localhost.localdomain. Esse nome padrão pode não ser exclusivo e é muito longo. Defina o nome do computador como o novo nó. Defina o nome do computador adicionando-o a/etc/hosts. O script a seguir permite que você edite/etc/hostscomvi.sudo vi /etc/hostsO exemplo a seguir mostra
/etc/hostscom adições para três nós nomeadossqlfcivm1,sqlfcivm2, esqlfcivm3.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3O arquivo deve ser o mesmo em todos os nós.
Interrompa o serviço SQL Server no novo nó.
Siga as instruções para montar o diretório do arquivo de banco de dados na localização compartilhada:
No servidor NFS, instale
nfs-utils:sudo yum -y install nfs-utilsAbra o firewall em clientes e servidor NFS:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadEdite o arquivo
/etc/fstabpara incluir o comando mount:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrExecute
mount -apara que as alterações entrem em vigor.No novo nó, crie um arquivo para armazenar o nome de usuário e a senha do SQL Server para o logon do Pacemaker. O comando a seguir cria e popula este arquivo:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<password>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwdCuidado
Sua senha deve seguir a política de senha padrão do SQL Server. Por padrão, a senha precisa ter pelo menos oito caracteres e conter caracteres de três dos seguintes quatro conjuntos: letras maiúsculas, letras minúsculas, dígitos de base 10 e símbolos. As senhas podem ter até 128 caracteres. Use senhas longas e complexas.
No novo nó, abra as portas do firewall do Pacemaker. Para abrir essas portas com o
firewalld, execute o seguinte comando:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSe você estiver usando outro firewall que não tenha uma configuração de alta disponibilidade interna, as portas a seguir precisarão ser abertas para que o Pacemaker possa se comunicar com outros nós no cluster:
- TCP: portas 2224, 3121 e 21064
- UDP: porta 5405
Instale os pacotes do Pacemaker no novo nó.
sudo yum install pacemaker pcs fence-agents-all resource-agentsDefina a senha do usuário padrão criado ao instalar pacotes do Pacemaker e do Corosync. Use a mesma senha dos nós existentes.
sudo passwd haclusterHabilite e inicie o serviço
pcsde o Pacemaker. Isso permitirá que o novo nó reingresse no cluster após a reinicialização. Execute o comando a seguir no novo nó.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstalar o agente do recurso FCI para SQL Server. Execute os comandos a seguir no novo nó.
sudo yum install mssql-server-haEm um nó existente do cluster, autentique o novo nó e adicione-o ao cluster:
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>O exemplo a seguir adiciona um nó chamado vm3 ao cluster.
sudo pcs cluster auth sudo pcs cluster start
Remover nós de um cluster
Para remover um nó de um cluster, execute o seguinte comando:
sudo pcs cluster node remove <nodeName>
Alterar a frequência do intervalo de monitoramento do recurso sqlservr
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
O seguinte exemplo define o intervalo de monitoramento como 2 segundos para o recurso mssql:
sudo pcs resource op monitor interval=2s mssqlha
Solução de problemas do cluster de disco compartilhado do Red Hat Enterprise Linux para o SQL Server
Ao solucionar de problemas do cluster, é útil entender como os três daemons funcionam em conjunto para gerenciar os recursos de cluster.
| Dimons | Descrição |
|---|---|
| Corossíncrono | Fornece associação de quorum e mensagens entre os nós de cluster. |
| Marca-passo | Reside na parte superior do Corosync e fornece computadores de estado para recursos. |
| PCSD | Gerencia o Pacemaker e o Corosync por meio das ferramentas pcs. |
O PCSD precisa estar em execução para que as ferramentas pcs sejam usadas.
Status atual do cluster
sudo pcs status retorna informações básicas sobre o cluster, o quorum, os nós, os recursos e o status do daemon de cada nó.
Um exemplo de uma saída de quorum íntegra do Pacemaker é:
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
No exemplo, partition with quorum significa que um quorum de maioria dos nós está online. Se o cluster perder um quorum de maioria dos nós, pcs status retornará partition WITHOUT quorum e todos os recursos serão interrompidos.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] retorna o nome de todos os nós que participam atualmente do cluster. Se algum nó não estiver participando, pcs status retornará OFFLINE: [<nodename>].
PCSD Status mostra o status do cluster de cada nó.
Motivos pelos quais um nó pode estar offline
Verifique os itens a seguir quando um nó estiver offline.
Firewall
As portas a seguir precisam ser abertas em todos os nós para que o Pacemaker possa se comunicar.
- **TCP: 2224, 3121, 21064
Serviços do Pacemaker ou do Corosync em execução
Comunicação dos nós
Mapeamentos de nomes de nós