Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x) no Linux
SQL Server 2019 (15.x) no Linux
A integração do Python está disponível no SQL Server 2017 e posterior, quando você inclui a opção do Python em uma instalação de Serviços de Machine Learning (no banco de dados).
Observação
No momento, este artigo se aplica a SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) e SQL Server 2019 (15.x) somente para Linux.
Para desenvolver e implantar soluções Python para SQL Server, instale o revoscalepy da Microsoft e outras bibliotecas do Python em sua estação de trabalho de desenvolvimento. A biblioteca revoscalepy, que também está na instância do SQL Server remoto, coordena as solicitações de computação entre os dois sistemas.
Neste artigo, saiba como configurar uma estação de trabalho de desenvolvimento do Python para que você possa interagir com um SQL Server remoto habilitado para aprendizado de máquina e para integração com o Python. Depois de concluir as etapas neste artigo, você terá as mesmas bibliotecas do Python que aquelas existentes no SQL Server. Você também saberá como enviar por push cálculos de uma sessão local do Python para uma sessão remota do Python no SQL Server.
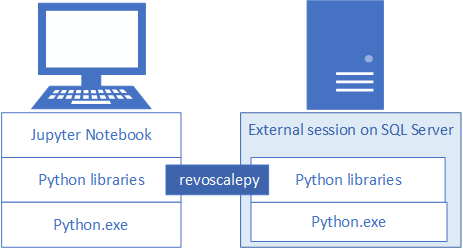
Para validar a instalação, você pode usar Jupyter Notebooks internos conforme descrito neste artigo ou vincular as bibliotecas ao PyCharm ou a qualquer outro IDE que você normalmente use.
Dica
Para ver uma demonstração em vídeo desses exercícios, confira Executar R e Python remotamente no SQL Server de Jupyter Notebooks.
Ferramentas usadas com frequência
Seja você um desenvolvedor de Python não familiarizado com o SQL ou um desenvolvedor do SQL não familiarizado com o Python e a análise no banco de dados, você precisará de uma ferramenta de desenvolvimento Python e de um editor de consultas T-SQL (como o SSMS, SQL Server Management Studio) para fazer uso de todas as funcionalidades da análise no banco de dados.
Para o desenvolvimento em Python, você pode usar Jupyter Notebooks, que vêm agrupados na distribuição do Anaconda instalada pelo SQL Server. Este artigo explica como iniciar o Jupyter Notebooks para que você possa executar o código Python localmente e remotamente no SQL Server.
O SSMS é um download separado, útil para criar e executar procedimentos armazenados no SQL Server, incluindo aqueles que contêm código Python. Praticamente qualquer código Python que você escreva nos Jupyter Notebooks poderá ser inserido em um procedimento armazenado. Você pode percorrer outros guias de início rápido para saber mais sobre SSMS e Python inserido.
1 – Instalar pacotes do Python
As estações de trabalho locais precisam ter as mesmas versões de pacote do Python que aquelas do SQL Server, incluindo o Anaconda 4.2.0 base com a distribuição 3.5.2 do Python e pacotes específicos da Microsoft.
Um script de instalação adiciona três bibliotecas específicas da Microsoft ao cliente Python. O script instala:
- o revoscalepy, que é usado para definir os objetos de origens de dados e o contexto de computação.
- microsoftml, fornecendo algoritmos de machine learning.
- o azureml, que se aplica a tarefas de operacionalização associadas com um contexto de servidor autônomo e pode ser de uso limitado para análises no banco de dados.
Baixe um script de instalação. Na página apropriada do GitHub, apresentada a seguir, selecione Fazer download do arquivo RAW.
Install-PyForMLS.ps1 instala a versão 9.2.1 dos pacotes do Microsoft Python. Essa versão corresponde a uma instância do SQL Server padrão.
Install-PyForMLS.ps1 instala a versão 9.3 dos pacotes do Microsoft Python.
Abra uma janela do PowerShell com permissões de administrador elevadas (clique com o botão direito do mouse em Executar como administrador).
Vá para a pasta em que você baixou o instalador e execute o script. Adicione o argumento de linha de comando
-InstallFolderpara especificar uma localização de pasta para as bibliotecas. Por exemplo:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Se você omitir a pasta de instalação, o padrão será %ProgramFiles%\Microsoft\PyForMLS.
A instalação leva algum tempo para ser concluída. Você pode monitorar o progresso na janela do PowerShell. Quando a instalação for concluída, você terá um conjunto completo de pacotes.
Dica
Recomendamos as Perguntas frequentes sobre o Python para o Windows para obter informações gerais sobre a execução de programas Python no Windows.
2 – Localizar os executáveis
Ainda no PowerShell, liste o conteúdo da pasta de instalação para confirmar se o Python.exe, os scripts e outros pacotes estão instalados.
Insira
cd \para ir para a unidade raiz e, em seguida, insira o caminho especificado para-InstallFolderna etapa anterior. Se você omitir esse parâmetro durante a instalação, o padrão serácd %ProgramFiles%\Microsoft\PyForMLS.Insira
dir *.exepara listar os executáveis. Você deve ver python.exe, pythonw.exe e uninstall-anaconda.exe.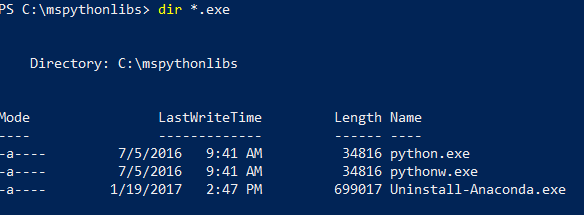
Em sistemas com várias versões do Python, lembre-se de usar esse Python. exe específico se você quiser carregar revoscalepy e outros pacotes da Microsoft.
Observação
O script de instalação não modifica a variável de ambiente PATH no seu computador, o que significa que o novo interpretador do Python e os módulos que você acabou de instalar não ficam automaticamente disponíveis para outras ferramentas que você possa ter. Para obter ajuda sobre como vincular o interpretador do Python e as bibliotecas a ferramentas, confira Instalar um IDE.
3 – Abrir Jupyter Notebooks
O Anaconda inclui Jupyter Notebooks. Como uma próxima etapa, crie um notebook e execute código Python contendo as bibliotecas que você acabou de instalar.
No prompt do PowerShell, ainda no diretório
%ProgramFiles%\Microsoft\PyForMLS, abra os Jupyter Notebooks na pasta Scripts:.\Scripts\jupyter-notebookUm notebook deve ser aberto no navegador padrão em
https://localhost:8889/tree.Outra maneira de começar é clicar duas vezes em jupyter-notebook.exe.
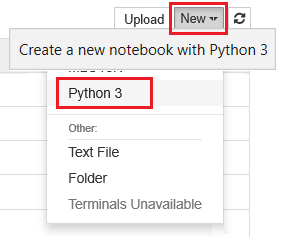
Selecione Novo e escolha Python 3.
Insira
import revoscalepye execute o comando para carregar uma das bibliotecas específicas da Microsoft.Insira e execute
print(revoscalepy.__version__)para retornar as informações de versão. Você deverá ver 9.2.1 ou 9.3.0. Você pode usar qualquer uma dessas versões com revoscalepy no servidor.Insira uma série mais complexa de instruções. Este exemplo gera estatísticas de resumo usando rx_summary em um conjunto de dados local. Outras funções obtêm a localização dos dados de exemplo e criam um objeto de fonte de dados para um arquivo .xdf local.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
A captura de tela a seguir mostra a entrada e uma parte da saída, reduzida para fins de brevidade.

4 – Obter Permissões do SQL
Para se conectar a uma instância do SQL Server para executar scripts e fazer upload de dados, você deve ter um logon válido no servidor de banco de dados. Você pode usar um logon SQL ou a autenticação integrada do Windows. Geralmente, é recomendável usar a autenticação integrada do Windows, mas usar o logon do SQL é mais simples para alguns cenários, especialmente quando o script contém cadeias de conexão para dados externos.
No mínimo, a conta usada para executar o código deve ter permissão para ler os bancos de dados com os quais você está trabalhando, além da permissão especial EXECUTE ANY EXTERNAL SCRIPT. A maioria dos desenvolvedores também exige permissões para criar procedimentos armazenados e para gravar dados em tabelas que contêm dados de treinamento ou dados pontuados.
Peça ao administrador do banco de dados para configurar as permissões a seguir para sua conta, no banco de dados em que você usa o Python:
- EXECUTE ANY EXTERNAL SCRIPT para executar o Python no servidor.
- Privilégios de db_datareader para executar as consultas usadas para treinar o modelo.
- db_datawriter para gravar dados de treinamento ou dados pontuados.
- db_owner para criar objetos como procedimentos armazenados, tabelas e funções. Você também precisa de db_owner para criar bancos de dados de exemplo e de teste.
Se o código exigir pacotes que não sejam instalados por padrão com o SQL Server, providencie junto ao administrador de banco de dados para que os pacotes sejam instalados com a instância. O SQL Server é um ambiente seguro e há restrições sobre onde os pacotes podem ser instalados. A instalação ad hoc de pacotes como parte do seu código não é recomendada, mesmo que você tenha direitos para tal. Além disso, sempre considere cuidadosamente as implicações de segurança antes de instalar novos pacotes na biblioteca do servidor.
5 – Criar dados de teste
Se tiver permissões para criar um banco de dados no servidor remoto, você poderá executar o código a seguir para criar o banco de dados de demonstração Iris usado para as etapas restantes neste artigo.
5.1 – Criar o banco de dados irissql remotamente
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5.2 – Importar o exemplo do Iris de SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5.3 – Usar APIs Revoscalepy para criar uma tabela e carregar os dados do Iris
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 – Testar a conexão remota
Antes de tentar esta próxima etapa, verifique se você tem permissões na instância do SQL Server e uma cadeia de conexão para o banco de dados de exemplo do Iris. Se o banco de dados não existir e você tiver permissões suficientes, você poderá Criar um banco de dados usando essas instruções embutidas.
Substitua a cadeia de conexão por valores válidos. O código de exemplo usa "Server=localhost;Database=irissql;Trusted_Connection=Yes;", mas seu código deve especificar um servidor remoto, possivelmente com um nome de instância, bem como uma opção de credencial que mapeie para o logon de usuário do banco de dados.
6.1 – Definir uma função
O código a seguir define uma função que você enviará para o SQL Server em uma etapa posterior. Quando executado, ele usa dados e bibliotecas (revoscalepy, pandas, matplotlib) no servidor remoto para criar gráficos de dispersão do conjunto de dados Iris. Ele retorna o fluxo de bytes do .png para os Jupyter Notebooks para que ele seja renderizado no navegador.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6.2 – Enviar a função para o SQL Server
Neste exemplo, crie o contexto de computação remota e, em seguida, envie a execução da função para o SQL Server com rx_exec. A função rx_exec é útil porque aceita um contexto de computação como um argumento. Qualquer função que você desejar executar remotamente deverá ter um argumento de contexto de computação. Algumas funções, tais como rx_lin_mod, oferecem suporte direto a esse argumento. Para operações que não oferecem, você pode usar rx_exec para entregar seu código em um contexto de computação remota.
Neste exemplo, nenhum dado bruto foi transferido do SQL Server para o Jupyter Notebook. Toda a computação ocorre no banco de dados Iris e apenas o arquivo de imagem é retornado ao cliente.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
A captura de tela a seguir mostra a entrada e a saída de gráfico de dispersão.

7 – Iniciar o Python por meio das ferramentas
Já que os desenvolvedores muitas vezes trabalham com várias versões do Python, a instalação não adiciona o Python ao seu PATH. Para usar o executável do Python e as bibliotecas instaladas juntamente com a instalação principal, vincule o IDE a Python.exe no caminho que também fornece revoscalepy e microsoftml.
Linha de comando
Quando você executa Python.exe em %ProgramFiles%\Microsoft\PyForMLS (ou em qualquer localização especificada para a instalação da biblioteca de clientes do Python), você tem acesso à distribuição completa do Anaconda e aos módulos do Microsoft Python, revoscalepy e microsoftml.
- Vá para
%ProgramFiles%\Microsoft\PyForMLSe execute Python.exe. - Abra a ajuda interativa:
help(). - Digite o nome de um módulo no prompt de ajuda:
help> revoscalepy. A ajuda retorna o nome, o conteúdo do pacote, a versão e a localização do arquivo. - Retorne as informações de versão e de pacote no prompt ajuda>:
revoscalepy. Pressione Enter algumas vezes para sair da ajuda. - Importar um módulo:
import revoscalepy.
Blocos de anotações Jupyter
Este artigo usa Jupyter Notebooks internos para demonstrar chamadas de função para revoscalepy. Caso não esteja familiarizado com essa ferramenta, a captura de tela a seguir ilustra como as peças se encaixam e por que tudo "simplesmente funciona".
A pasta pai %ProgramFiles%\Microsoft\PyForMLS contém o Anaconda e os pacotes da Microsoft. Os Jupyter Notebooks estão inclusos no Anaconda, na pasta Scripts, e os executáveis do Python são registrados automaticamente com Jupyter Notebooks. Os pacotes encontrados em pacotes de site podem ser importados para um notebook, incluindo os três pacotes da Microsoft usados para ciência de dados e aprendizado de máquina.
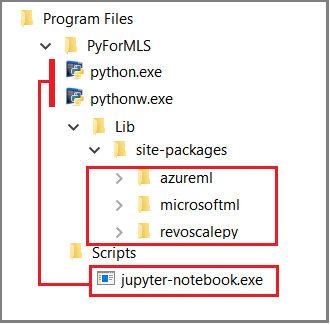
Se você estiver usando outro IDE, será necessário vincular os executáveis do Python e as bibliotecas de funções à sua ferramenta. As seções a seguir contêm instruções sobre ferramentas usadas com frequência.
Visual Studio
Se você tiver o Python no Visual Studio, use as opções de configuração a seguir para criar um ambiente do Python que inclua os pacotes do Microsoft Python.
| Definição de configuração | valor |
|---|---|
| Caminho do prefixo | %ProgramFiles%\Microsoft\PyForMLS |
| Caminho do interpretador | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Interpretador em janelas | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Para obter ajuda na configuração de um ambiente Python, confira Gerenciar ambientes Python no Visual Studio.
PyCharm
No PyCharm, defina o interpretador para o executável do Python instalado.
Em um novo projeto, em Configurações, selecione Adicionar Local.
Digite
%ProgramFiles%\Microsoft\PyForMLS\.
Agora você pode importar os módulos revoscalepy, microsoftml ou azureml. Você também pode escolher Ferramentas>Console do Python para abrir uma Janela interativa.