Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() SQL Server 2017 (14.x) e versões posteriores
SQL Server 2017 (14.x) e versões posteriores
Este artigo descreve a extensão do Python para executar scripts de Python externos com os Serviços de Machine Learning do SQL Server. A extensão adiciona:
- Um ambiente de execução de Python
- Uma distribuição do Anaconda com o runtime e o interpretador do Python 3.5
- Bibliotecas e ferramentas padrão
- Pacotes de Python da Microsoft:
- revoscalepy para análise em escala.
- microsoftml para algoritmos de machine learning.
A instalação do interpretador e do runtime do Python 3.5 garante a compatibilidade quase completa com soluções Python padrão. O Python é executado em um processo separado do SQL Server, a fim de garantir que as operações de banco de dados não sejam comprometidas.
Componentes do Python
O SQL Server inclui pacotes de software livre e proprietários. O runtime do Python instalado pela instalação é Anaconda 4.2 com Python 3.5. O ambiente de execução do Python é instalado independentemente das ferramentas SQL e é executado fora dos processos do mecanismo principal, no framework de extensibilidade. Como parte da instalação dos Serviços de Machine Learning com o Python, você deve consentir com os termos da Licença Pública de GNU.
O SQL Server não modifica os executáveis do Python, mas você deve usar a versão do Python instalada pela instalação, pois essa versão é aquela na qual os pacotes proprietários são compilados e testados. Para obter uma lista de pacotes compatíveis com a distribuição Anaconda, consulte o site da Continuum Analytics: Lista de pacotes do Anaconda.
A distribuição Anaconda associada a uma instância específica do mecanismo de banco de dados pode ser encontrada na pasta correspondente. Por exemplo, se você tiver instalado o mecanismo de banco de dados do SQL Server 2017 com os Serviços de Machine Learning e o Python na instância padrão, procure em C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Os pacotes do Python adicionados pela Microsoft para cargas de trabalho paralelas e distribuídas incluem as bibliotecas a seguir.
| Biblioteca | Descrição |
|---|---|
| revoscalepy | É compatível com objetos de fonte de dados e exploração, manipulação, transformação e visualização de dados. Ele é compatível com a criação de contextos de computação remota, bem como com vários modelos de machine learning escalonáveis, como rxLinMod. Para obter mais informações, confira o módulo revoscalepy com o SQL Server. |
| microsoftml | Contém algoritmos de aprendizado de máquina que foram otimizados para velocidade e precisão, bem como transformações em linha para trabalhar com texto e imagens. Para obter mais informações, confira o módulo microsoftml com o SQL Server. |
Microsoftml e revoscalepy estão rigidamente acoplados; as fontes de dados usadas em microsoftml são definidas como objetos revoscalepy. Limitações de contexto de computação na transferência do revoscalepy para microsoftml. Ou seja, todas as funcionalidades estão disponíveis para operações locais, mas alternar para um contexto de computação remota requer o RxInSqlServer.
Como usar o Python no SQL Server
Você importa o módulo revoscalepy para o código Python e, em seguida, chama funções do módulo, como ocorre com qualquer outra função do Python.
As fontes de dados compatíveis incluem bancos de dados ODBC, SQL Server e formato de arquivo XDF para trocar dados com outras fontes ou com soluções de R. Os dados de entrada para Python devem ser tabulares. Todos os resultados do Python devem ser retornados na forma de um quadro de dados do Pandas.
Os contextos de computação compatíveis incluem o contexto de computação local ou remota do SQL Server. Um contexto de computação remota refere-se à execução de código que começa em um computador, como uma estação de trabalho, mas, em seguida, alterna a execução do script para um computador remoto. Alternar o contexto de computação requer que ambos os sistemas tenham a mesma biblioteca revoscalepy.
O contexto de computação local, como você pode esperar, inclui a execução do código Python no mesmo servidor que a instância do mecanismo de banco de dados, com o código dentro de T-SQL ou inserido em um procedimento armazenado. Você também pode executar o código de um IDE Python local e fazer com que o script seja executado no computador SQL Server, definindo um contexto de computação remota.
Arquitetura de execução
Os diagramas a seguir descrevem a interação dos componentes do SQL Server com o runtime do Python em cada um dos cenários compatíveis: execução de script no banco de dados e execução remota de um terminal do Python, usando um contexto de computação do SQL Server.
Scripts Python executados no banco de dados
Ao executar o Python "dentro" do SQL Server, você precisa encapsular o script Python dentro de um procedimento armazenado especial, o sp_execute_external_script.
Depois que o script tiver sido inserido no procedimento armazenado, qualquer aplicativo que possa fazer uma chamada de procedimento armazenado poderá iniciar a execução do código Python. Então, o SQL Server gerencia a execução de código, conforme resumido no diagrama a seguir.
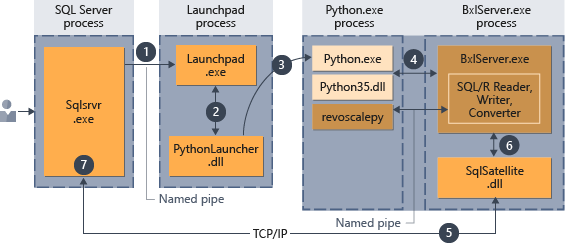
- Uma solicitação para o runtime de Python é indicada pelo parâmetro
@language='Python'passado para o procedimento armazenado. O SQL Server envia essa solicitação para o serviço Launchpad. No Linux, o SQL usa um serviço Launchpad para se comunicar com um processo Launchpad separado para cada usuário. Veja o Diagrama da arquitetura de extensibilidade para obter detalhes. - O serviço Launchpad inicia o inicializador apropriado; neste caso, PythonLauncher.
- O PythonLauncher inicia o processo Python35 externo.
- O BxlServer coordena-se com o runtime do Python para gerenciar a troca de dados e o armazenamento de resultados funcionais.
- O Satélite SQL gerencia as comunicações sobre processos e tarefas relacionadas com o SQL Server.
- O BxlServer usa Satélite SQL para comunicar o status e os resultados ao SQL Server.
- O SQL Server obtém resultados e fecha os processos e tarefas relacionados.
Scripts Python executados de um cliente remoto
Você pode executar scripts Python de um computador remoto, tal como um laptop, fazendo com que eles sejam executados no contexto do computador SQL Server, se estas condições forem atendidas:
- Você cria os scripts adequadamente
- O computador remoto instalou as bibliotecas de extensibilidade usadas pelo Serviços de Machine Learning. O pacote revoscalepy é necessário para usar contextos de computação remota.
O diagrama a seguir resume o fluxo de trabalho geral quando os scripts são enviados de um computador remoto.
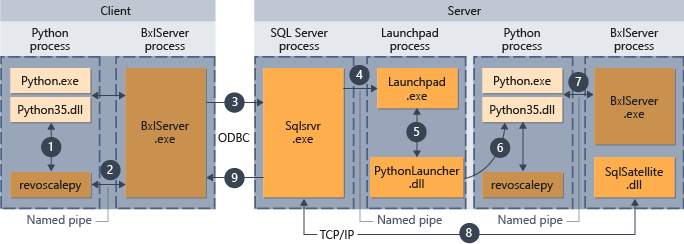
- Para funções compatíveis com o revoscalepy, o runtime do Python chama uma função de vinculação que, por sua vez, chama o BxlServer.
- O BxlServer está incluído com Serviços de Machine Learning (no banco de dados) e é executado em um processo separado do runtime do Python.
- O BxlServer determina o destino da conexão e inicia uma conexão usando o ODBC, passando as credenciais fornecidas como parte da cadeia de conexão no script Python.
- O BxlServer abre uma conexão para a instância do SQL Server.
- Quando um runtime de script externo é chamado, o serviço Launchpad é invocado e, por sua vez, inicia o inicializador apropriado, que nesse caso é PythonLauncher.dll. Depois disso, o processamento do código Python é tratado em um fluxo de trabalho semelhante àquele de quando o código Python é invocado de um procedimento armazenado no T-SQL.
- O PythonLauncher faz uma chamada para a instância do Python instalada no computador do SQL Server.
- Os resultados são retornados ao BxlServer.
- O Satélite SQL gerencia a comunicação com o SQL Server e a limpeza dos objetos de trabalho relacionados.
- O SQL Server passa os resultados de volta para o cliente.