Ajuste automático
Aplica-se a:![]() SQL Server 2017 (14.x) e versões posteriores
SQL Server 2017 (14.x) e versões posteriores ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
O ajuste automático é um recurso de banco de dados que fornece informações sobre possíveis problemas de desempenho de consultas, recomenda soluções e corrige automaticamente os problemas identificados.
O ajuste automático, introduzido no SQL Server 2017 (14.x), notifica você sempre que um possível problema de desempenho é detectado e permite aplicar as ações corretivas ou permite que o Mecanismo de Banco de Dados corrija automaticamente os problemas de desempenho. O ajuste automático do SQL Server identifica e corrige problemas de desempenho causados por regressões de escolha do plano de execução de consulta. O ajuste automático no Banco de Dados SQL do Azure também cria índices necessários e descarta índices não utilizados. Para obter mais informações sobre planos de execução de consulta, confira Planos de Execução.
O Mecanismo de Banco de Dados do SQL Server monitora as consultas que são executadas no banco de dados e melhora automaticamente o desempenho da carga de trabalho. O Mecanismo de Banco de Dados tem um mecanismo de inteligência interno que pode ajustar e aprimorar o desempenho de suas consultas adaptando dinamicamente o banco de dados de acordo com sua carga de trabalho de maneira automática. Há dois recursos de ajuste automático disponíveis:
A correção automática do plano identifica planos de execução de consulta problemáticos, como problemas de detecção de parâmetros ou de sensibilidade de parâmetros, e corrige problemas de desempenho relacionados ao plano de execução de consulta forçando o último plano válido conhecido antes da regressão ocorrer. Aplica-se a: SQL Server (a partir do SQL Server 2017 (14.x)) e Banco de Dados SQL do Azure e Instância Gerenciada de SQL do Azure]
Gerenciamento automático de índice: identifica os índices que devem ser adicionados ao seu banco de dados e aqueles que devem ser removidos. Aplica-se a: Banco de Dados SQL do Azure
Por que usar o ajuste automático?
Três das principais tarefas na administração de banco de dados clássica são monitorar a carga de trabalho, identificar consultas Transact-SQL críticas e identificar índices que devem ser adicionados para aprimorar o desempenho ou índices que são raramente usados e podem ser removidos para melhorar o desempenho. O Mecanismo de Banco de Dados do SQL Server fornece insights detalhados sobre as consultas e os índices que você precisa monitorar. No entanto, monitorar o banco de dados é uma tarefa difícil e entediante, principalmente ao lidar com muitos bancos de dados. Gerenciar um grande número de bancos de dados pode ser impossível de se fazer com eficiência. Em vez de monitorar e ajustar o banco de dados manualmente, considere delegar algumas das ações de monitoramento e ajustes usando o recurso de ajuste automático do Mecanismo de Banco de Dados.
Como funciona o trabalho de ajuste automático?
O ajuste automático é um processo de análise e monitoramento contínuo que constantemente aprende sobre as características da sua carga de trabalho e identifica possíveis problemas e aprimoramentos.
Esse processo permite que o banco de dados adapte-se dinamicamente à sua carga de trabalho, localizando quais planos e índices podem melhorar o desempenho das cargas de trabalho e quais índices afetam suas cargas de trabalho. Com base nessas conclusões, o ajuste automático aplica ações de ajuste que aprimoram o desempenho da carga de trabalho. Além disso, o ajuste automático monitora continuamente o desempenho do banco de dados depois de implementar qualquer alteração para garantir que ela aprimore o desempenho da carga de trabalho. Qualquer ação que não melhora o desempenho é revertida automaticamente. Esse processo de verificação é um recurso fundamental que garante que qualquer alteração feita pelo ajuste automático não diminua o desempenho geral da carga de trabalho.
Correção automática de plano
A correção automática do plano é um recurso de ajuste automático que identifica a regressão de escolha do plano de execução e corrige automaticamente o problema forçando o último plano válido conhecido. Para obter mais informações sobre os planos de execução de consulta e o Otimizador de Consulta, confira Guia da Arquitetura de Processamento de Consultas.
Importante
A correção automática do plano depende de Repositório de Consultas estar habilitado para acompanhamento da carga de trabalho no banco de dados.
O que é regressão de escolha do plano de execução?
O Mecanismo de Banco de Dados do SQL Server pode usar planos de execução diferentes para executar as consultas Transact-SQL. Os planos de consulta dependem de estatísticas, índices e outros fatores. O plano ideal que deve ser usado para executar uma consulta Transact-SQL pode mudar ao longo do tempo, dependendo das alterações desses fatores. Em alguns casos, o novo plano pode não ser melhor do que o anterior e pode causar uma regressão de desempenho, como um problema relacionado à detecção de parâmetros ou sensibilidade de parâmetros.
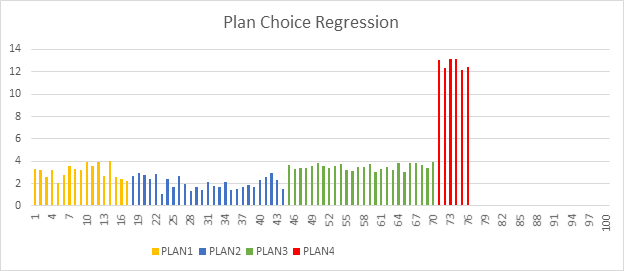
Sempre que observar que ocorreu uma regressão de escolha de plano, você deverá encontrar um plano válido anterior e forçá-lo a ser usado em vez do atual. Isso pode ser feito usando o procedimento sp_query_store_force_plan. O Mecanismo de Banco de Dados no SQL Server 2017 (14.x) fornece informações sobre planos regredidos e ações corretivas recomendadas. Além disso, o Mecanismo de Banco de Dados permite automatizar totalmente esse processo e deixar que o Mecanismo de Banco de Dados corrija qualquer problema encontrado relacionado à alteração do plano.
Importante
A correção automática do plano deve ser usada no escopo de uma atualização no nível de compatibilidade do banco de dados, depois que uma linha de base for capturada, para mitigar automaticamente os riscos de atualização da carga de trabalho. Para obter mais informações sobre este caso de uso, confira Manter a estabilidade do desempenho durante a atualização para a versão mais recente do SQL Server.
Correção automática da escolha do plano
O Mecanismo de Banco de Dados poderá alternar automaticamente para o último plano válido conhecido sempre que uma regressão da escolha do plano for detectada.
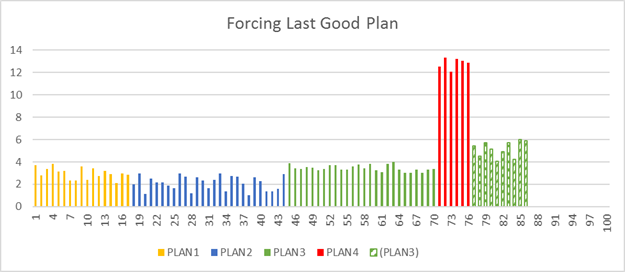
O Mecanismo de Banco de Dados detecta automaticamente qualquer possível regressão de escolha do plano, incluindo o plano que deve ser usado em vez do plano incorreto. O plano de execução resultante forçado pela correção automática do plano será o mesmo ou semelhante ao último plano válido conhecido. Como o plano resultante pode não ser idêntico ao último plano válido conhecido, o desempenho do plano forçado pode variar. Em casos raros, a diferença de desempenho poderá ser significativa e negativa; nesse caso, a correção automática do plano interromperá automaticamente a tentativa de forçar o plano substituto.
Quando o Mecanismo de Banco de Dados aplica o último plano válido conhecido antes da regressão ocorrer, ele automaticamente monitora o desempenho do plano forçado. Se o plano forçado não for melhor do que o plano regredido, o novo plano não será forçado e o Mecanismo de Banco de Dados compilará um novo plano. Se o Mecanismo de Banco de Dados verificar que o plano forçado é melhor que o plano regredido, o plano forçado será mantido. Ele será mantido até que ocorra uma recompilação (por exemplo, na próxima atualização de estatística ou alteração de esquema). Para obter mais informações sobre imposição de planos e os tipos de planos que podem ser forçados, confira Limitações ao forçar planos.
Observação
Se a instância do SQL Server for reiniciada antes que uma ação de forçar plano seja verificada, o forçamento desse plano será automaticamente cancelado. Caso contrário, o forçamento do plano será mantido nas reinicializações do SQL Server.
Habilitar a correção automática da escolha do plano
Habilite o ajuste automático por banco de dados e especifique que o último plano válido deve ser forçado sempre que uma regressão da alteração do plano for detectada. O ajuste automático é habilitado com o seguinte comando:
ALTER DATABASE <yourDatabase>
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
Depois que você habilitar essa opção, o Mecanismo de Banco de Dados forçará automaticamente qualquer recomendação em que o ganho estimado de CPU seja maior do que 10 segundos ou que o número de erros no novo plano seja maior do que o número de erros no plano recomendado e verificará se o plano forçado é melhor do que o atual.
Para habilitar o ajuste automático no Banco de Dados SQL do Azure e na Instância Gerenciada SQL do Azure, consulte Habilitar o ajuste automático no Banco de Dados SQL do Azure usando o portal do Azure.
Alternativa – correção manual da escolha do plano
Sem o ajuste automático, os usuários deverão monitorar o sistema periodicamente e procurar as consultas que foram regredidas. Se algum plano tiver regredido, o usuário deverá encontrar um plano anterior válido e forçá-lo em substituição ao atual usando o procedimento sp_query_store_force_plan. A prática recomendada seria forçar o último plano válido conhecido porque planos mais antigos podem estar inválidos devido a alterações estatísticas ou de índice. O usuário que força o último plano válido conhecido deve monitorar o desempenho da consulta executada usando o plano forçado e verificar se o plano forçado funciona conforme o esperado. Dependendo dos resultados do monitoramento e da análise, o plano deverá ser forçado ou o usuário deverá encontrar outra maneira de otimizar a consulta, como reescrevê-la. Planos forçados manualmente não devem ser forçados para sempre, porque o Mecanismo de Banco de Dados deve ser capaz de aplicar planos ideais. O usuário ou o DBA devem, eventualmente, cancelar a imposição do plano usando o procedimento sp_query_store_unforce_plan e permitir que o Mecanismo de Banco de Dados encontre o plano ideal.
Dica
Como alternativa, use o modo de exibição Consultas com planos forçados do Repositório de Consultas para localizar e cancelar o forçamento de planos.
O SQL Server fornece todos os modos de exibição e procedimentos necessários para monitorar o desempenho e corrigir problemas no Repositório de Consultas.
No SQL Server 2016 (13.x), você pode encontrar regressões de escolha de plano usando os modos de exibição do sistema do Repositório de Consultas. A partir do SQL Server 2017 (14.x), o Mecanismo de Banco de Dados detecta e mostra possíveis regressões de escolha do plano e as ações recomendadas que devem ser aplicadas na DMV sys.dm_db_tuning_recommendations (Transact-SQL). A DMV mostra informações sobre o problema, a importância do problema e detalhes como a consulta identificada, a ID do plano regredido, a ID do plano usado como linha de base para comparação e a instrução Transact-SQL que pode ser executada para corrigir o problema.
| tipo | descrição | DATETIME | score | detalhes | ... |
|---|---|---|---|---|---|
FORCE_LAST_GOOD_PLAN |
Tempo de CPU alterado de 4 ms para 14 ms | 17/03/2017 | 83 | queryId recommendedPlanId regressedPlanId T-SQL |
|
FORCE_LAST_GOOD_PLAN |
Tempo de CPU alterado de 37 ms para 84 ms | 16/03/2017 | 26 | queryId recommendedPlanId regressedPlanId T-SQL |
Algumas colunas desse modo de exibição estão descritas na seguinte lista:
- Tipo da ação recomendada
FORCE_LAST_GOOD_PLAN. - Descrição que contém informações por que o Mecanismo de Banco de Dados acha que essa alteração de plano é uma possível regressão de desempenho.
- Datetime de quando a regressão potencial foi detectada.
- Pontuação dessa recomendação.
- Detalhes sobre os problemas como ID do plano detectado, ID do plano regredido, ID do plano que deve ser forçado para corrigir o problema, script Transact-SQL que pode ser aplicado para corrigir o problema etc. Os detalhes estão armazenados em formato JSON.
Use a consulta a seguir para obter um script que corrija o problema e informações adicionais sobre o ganho estimado:
SELECT reason, score,
script = JSON_VALUE(details, '$.implementationDetails.script'),
planForceDetails.*,
estimated_gain = (regressedPlanExecutionCount + recommendedPlanExecutionCount)
* (regressedPlanCpuTimeAverage - recommendedPlanCpuTimeAverage)/1000000,
error_prone = IIF(regressedPlanErrorCount > recommendedPlanErrorCount, 'YES','NO')
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
regressedPlanId int '$.regressedPlanId',
recommendedPlanId int '$.recommendedPlanId',
regressedPlanErrorCount int,
recommendedPlanErrorCount int,
regressedPlanExecutionCount int,
regressedPlanCpuTimeAverage float,
recommendedPlanExecutionCount int,
recommendedPlanCpuTimeAverage float
) AS planForceDetails;
Este é o conjunto de resultados.
| reason | score | Script | query_id | plan_id atual | plan_id recomendada | estimated_gain | error_prone |
|---|---|---|---|---|---|---|---|
| Tempo de CPU alterado de 3 ms para 46 ms | 36 | EXEC sp_query_store_force_plan 12, 17; | 12 | 28 | 17 | 11,59 | 0 |
A coluna estimated_gain representa o número estimado de segundos que seriam economizados se o plano recomendado fosse usado para execução da consulta em vez do plano atual. O plano recomendado deve ser forçado em substituição do plano atual se o ganho for maior que 10 segundos. Se houver mais erros (por exemplo, tempo limite ou execuções anuladas) no plano atual do que no plano recomendado, a coluna error_prone será definida com o valor YES. Um plano propenso a erros é outro motivo pelo qual o plano recomendado deve ser forçado em vez do atual.
Embora o Mecanismo de Banco de Dados forneça todas as informações necessárias para identificar regressões de escolha do plano, o monitoramento contínuo e a correção de problemas de desempenho podem se tornar um processo tedioso. O ajuste automático torna esse processo muito mais fácil.
Observação
Os dados na DMV sys.dm_db_tuning_recommendations não são mantidos após uma reinicialização do mecanismo de banco de dados. Use a coluna sqlserver_start_time em sys.dm_os_sys_info para localizar a última hora de inicialização do mecanismo de banco de dados.
Gerenciamento de índice automático
No Banco de Dados SQL do Azure, o gerenciamento de índice é fácil porque o Banco de Dados SQL do Azure aprende sobre sua carga de trabalho e garante que seus dados são indexados sempre da melhor forma. Um design de índice apropriado é crucial para otimizar o desempenho da carga de trabalho e o gerenciamento de índice automático pode ajudar a otimizar seus índices. O gerenciamento de índice automático pode corrigir problemas de desempenho em bancos de dados indexados incorretamente ou manter e aprimorar os índices no esquema de banco de dados existente. O ajuste automático no Banco de Dados SQL do Azure executa as seguintes ações:
- Identifica índices que podem aprimorar o desempenho de consultas Transact-SQL que leem dados das tabelas.
- Identifica índices redundantes ou índices que não foram usados em um período maior de tempo e que poderiam ser removidos. A remoção de índices desnecessários melhora o desempenho das consultas que atualizam dados em tabelas.
Por que você precisa de gerenciamento de índice?
Os índices aceleram algumas de suas consultas que leem dados nas tabelas; no entanto, eles podem retardar as consultas que atualizam dados. Você precisa analisar cuidadosamente quando criar um índice e quais colunas você precisa incluir no índice. Alguns índices podem não ser mais necessários após algum tempo. Portanto, você precisa identificar periodicamente e descartar esses índices que não geram nenhum benefício. Se você ignorar os índices não utilizados, o desempenho das consultas que atualizam dados será reduzido sem nenhum benefício nas consultas de leitura de dados. Índices não utilizados também afetam o desempenho geral do sistema porque atualizações adicionais precisam do log desnecessário.
Descobrir o conjunto ideal de índices que melhoram o desempenho das consultas de leitura de dados das tabelas e que tenham um impacto mínimo sobre as atualizações pode exigir uma análise contínua e complexa.
O Banco de Dados SQL do Azure usa inteligência interna e regras avançadas que analisam suas consultas, identificam índices que seriam ideais para suas cargas de trabalho atuais e identificam os índices que podem ter que ser removidos. O Banco de Dados SQL do Azure garante que você tenha um conjunto mínimo necessário de índices que otimizam as consultas que leem dados, com menor impacto sobre as outras consultas.
Gerenciamento de índice automático
Além da detecção, o Banco de Dados SQL do Azure pode aplicar automaticamente recomendações identificadas. Se você achar que as regras internas melhoram o desempenho do seu banco de dados, você pode permitir que Banco de Dados SQL do Azure gerencie automaticamente seus índices.
Quando o Banco de Dados SQL do Azure aplica uma recomendação CREATE INDEX ou DROP INDEX, ele monitora automaticamente o desempenho das consultas afetadas pelo índice. O novo índice será mantido somente se os desempenhos das consultas afetadas forem aprimorados. O índice descartado será recriado automaticamente se houver consultas que sejam executadas mais lentamente devido à ausência do índice.
Considerações sobre o gerenciamento de índice automático
As ações necessárias para criar os índices necessários no Banco de Dados SQL do Azure podem consumir recursos e afetar o desempenho da carga de trabalho temporariamente. Para minimizar o impacto da criação de índice no desempenho da carga de trabalho, o Banco de Dados SQL do Azure localiza uma janela de tempo apropriada para qualquer operação de gerenciamento de índice. A ação de ajuste é adiada se o banco de dados precisar de recursos para executar sua carga de trabalho e é reiniciada quando o banco de dados tiver uma quantidade suficiente de recursos não utilizados que possam ser usados para a tarefa de manutenção. Um recurso importante no gerenciamento de índice automático é a verificação das ações. Quando o Banco de Dados SQL do Azure cria ou descarta um índice, um processo de monitoramento analisa o desempenho da carga de trabalho para verificar se a ação melhorou o desempenho geral. Se essa ação não gerar uma melhoria significativa ela será revertida imediatamente. Dessa forma, o Banco de Dados SQL do Azure garante que as ações de ajuste automáticas não afetem negativamente o desempenho da carga de trabalho. Os índices criados com o ajuste automático são transparentes para a operação de manutenção no esquema subjacente. Alterações de esquema como remover ou renomear colunas não são bloqueadas pela presença de índices criados automaticamente. Os índices criados automaticamente pelo Banco de Dados SQL do Azure são imediatamente descartados quando a tabela ou as colunas relacionadas são descartadas.
Alternativa – gerenciamento manual de índice
Sem o gerenciamento automático de índice, um usuário ou DBA precisaria consultar manualmente a exibição sys.dm_db_missing_index_details (Transact-SQL) ou usar o relatório do Painel de Desempenho no Management Studio para encontrar índices que possam aprimorar o desempenho, criar índices usando os detalhes fornecidos nessa exibição e monitorar manualmente o desempenho da consulta. Para localizar os índices que devem ser descartados, os usuários precisam monitorar as estatísticas de uso operacional dos índices para localizar índices raramente usados.
O Banco de Dados SQL do Azure simplifica esse processo. O Banco de Dados SQL do Azure analisa sua carga de trabalho, identifica as consultas que podem ser executadas mais rapidamente com um novo índice e identifica os índices duplicados ou não utilizados. Encontre mais informações sobre a identificação de índices que devem ser alterados em Encontrar recomendações de índice no portal do Azure.
Próximas etapas
- Ajuste automático no Banco de Dados SQL do Azure e na Instância Gerenciada de SQL do Azure
- ALTER DATABASE SET AUTOMATIC_TUNING (Transact-SQL)
- sys.database_automatic_tuning_options (Transact-SQL)
- sys.dm_db_tuning_recommendations (Transact-SQL)
- sys.dm_db_missing_index_details (Transact-SQL)
- sp_query_store_force_plan (Transact-SQL)
- sys.query_store_plan_forcing_locations (Transact-SQL)
- sp_query_store_unforce_plan (Transact-SQL)
- sys.database_query_store_options (Transact-SQL)
- sys.dm_os_sys_info (Transact-SQL)
- Funções JSON
- Planos de Execução
- Monitorar e ajustar o desempenho
- Ferramentas para monitoramento e ajuste de desempenho
- Monitorando o desempenho com o repositório de consultas
- Assistente de Ajuste de Consulta
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de