CREATE EXTERNAL TABLE (Transact-SQL)
Cria uma tabela externa.
Este artigo fornece a sintaxe, os argumentos, os comentários, as permissões e os exemplos de qualquer produto SQL que você escolher.
Para obter mais informações sobre as convenções de sintaxe, confira Convenções de sintaxe Transact-SQL.
Selecionar um produto
Na linha a seguir, selecione o nome do produto em que você tem interesse e somente as informações do produto serão exibidas.
* SQL Server *
Visão geral: SQL Server
Este comando cria uma tabela externa do PolyBase para acessar os dados armazenados em um cluster Hadoop, um Armazenamento de Blobs do Azure ou uma tabela externa do PolyBase que referencia os dados armazenados em um cluster Hadoop ou um Armazenamento de Blobs do Azure.
Aplica-se a: SQL Server 2016 (ou posterior)
Use uma tabela externa com uma fonte de dados externa para consultas do PolyBase. Fontes de dados externas são usadas para estabelecer a conectividade e dar suporte a estes casos de uso principal:
- Virtualização de dados e carregamento dados usando o PolyBase
- Operações de carregamento em massa usando o SQL Server ou o Banco de Dados SQL usando
BULK INSERTouOPENROWSET
Confira também CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Sintaxe
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumentos
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
O nome de uma a três partes da tabela a ser criada. Para uma tabela externa, o SQL armazena apenas os metadados da tabela, junto com estatísticas básicas sobre o arquivo ou a pasta referenciada no Hadoop ou no Armazenamento de Blobs do Azure. Nenhum dado real é movido ou armazenado no SQL Server.
Importante
Para ter o melhor desempenho, se o driver da fonte de dados externa tem suporte para um nome de três partes, é altamente recomendável fornecer esse nome.
<column_definition> [ ,...n ]
O CREATE EXTERNAL TABLE é compatível com a configuração de nome de coluna, tipo de dados, nulidade e ordenação. Não é possível usar a DEFAULT CONSTRAINT em tabelas externas.
As definições de coluna, incluindo os tipos de dados e o número de colunas, devem corresponder aos dados nos arquivos externos. Se houver uma incompatibilidade, as linhas do arquivo serão rejeitadas ao consultar os dados propriamente ditos.
LOCATION = 'folder_or_filepath'
Especifica a pasta ou o caminho do arquivo e o nome de arquivo dos dados reais no Hadoop ou no Armazenamento de Blobs do Azure. Além disso, há suporte para o armazenamento de objetos compatível com S3 a partir do SQL Server 2022 (16.x). O local inicia da pasta raiz. A pasta raiz é o local de dados especificado na fonte de dados externa.
No SQL Server, a instrução CREATE EXTERNAL TABLE cria o caminho e a pasta, caso ela ainda não exista. Em seguida, use INSERT INTO para exportar dados de uma tabela local do SQL Server para uma fonte de dados externa. Para saber mais, confira Consultas do PolyBase.
Se você especificar LOCATION para que ele seja uma pasta, uma consulta do PolyBase que seleciona por meio da tabela externa recuperará os arquivos da pasta e todas as suas subpastas. Assim como o Hadoop, o PolyBase não retorna pastas ocultas. Ele também não retorna arquivos dos quais o nome do arquivo começa com um sublinhado (_) ou um ponto final (.).
Na imagem de exemplo a seguir, se LOCATION='/webdata/', uma consulta do PolyBase retornará linhas de mydata.txt e mydata2.txt. Ela não retornará mydata3.txt porque esse é um arquivo que está em uma pasta oculta. E ele não retorna _hidden.txt porque é um arquivo oculto.
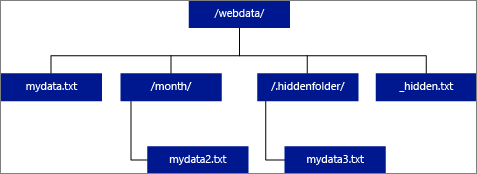
Para alterar o padrão e somente ler da pasta raiz, defina o atributo <polybase.recursive.traversal> como 'false' no arquivo de configuração core-site.xml. Esse arquivo está localizado em <SqlBinRoot>\PolyBase\Hadoop\Conf na raiz bin do SQL Server. Por exemplo, C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Especifica o nome da fonte de dados externa que contém o local dos dados externos. Essa localização é um HDFS (Sistema de Arquivos Hadoop), um contêiner de Armazenamento de Blobs do Azure ou um Azure Data Lake Store. Para criar uma fonte de dados externa, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica o nome do objeto de formato de arquivo externo que armazena o tipo de arquivo e o método de compactação para os dados externos. Para criar um formato de arquivo externo, use CREATE EXTERNAL FILE FORMAT.
Formatos de arquivo externos podem ser reutilizados por vários arquivos externos semelhantes.
Opções de rejeição
Essa opção pode ser usada somente com fontes de dados externas em que TYPE = HADOOP.
Especifique parâmetros de rejeição que determinam como o PolyBase manipulará registros sujos recuperados da fonte de dados externa. Um registro de dados é considerado 'sujo' se os tipos de dados reais ou o número de colunas não correspondem às definições de coluna da tabela externa.
Quando você não especifica nem altera os valores de rejeição, o PolyBase usa valores padrão. Essas informações sobre os parâmetros de rejeição são armazenadas como metadados adicionais quando você cria uma tabela externa com a instrução CREATE EXTERNAL TABLE. Quando uma instrução SELECT futura ou instrução INTO SELECT selecionar dados da tabela externa, o PolyBase usará as opções de rejeição para determinar o número ou o percentual de linhas que pode ser rejeitado antes que a consulta real falhe. A consulta retorna resultados (parciais) até que o limite de rejeição seja excedido. Em seguida, ela falha com a mensagem de erro apropriada.
REJECT_TYPE = value | percentage
Esclarece se a opção REJECT_VALUE é especificada como um valor literal ou um percentual.
value
REJECT_VALUE é um valor literal, não um percentual. A consulta falhará quando o número de linhas rejeitadas exceder o reject_value.
Por exemplo, se REJECT_VALUE = 5 e REJECT_TYPE = value, a consulta SELECT falhará depois que cinco linhas forem rejeitadas.
percentage
REJECT_VALUE é um percentual, não um valor literal. Uma consulta falhará quando a porcentagem de linhas com falha exceder reject_value. O percentual de linhas com falha é calculado em intervalos.
REJECT_VALUE = reject_value
Especifica o valor ou o percentual de linhas que pode ser rejeitado antes da falha da consulta.
Para REJECT_TYPE = value, reject_value deve ser um inteiro entre 0 e 2.147.483.647.
Para REJECT_TYPE = percentage, reject_value deve ser um float entre 0 e 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Esse atributo é obrigatório quando você especifica REJECT_TYPE = percentage. Ele determina o número de linhas de tentativa de recuperação antes que o PolyBase recalcule a percentual de linhas rejeitadas.
O parâmetro reject_sample_value deve ser um inteiro entre 0 e 2.147.483.647.
Por exemplo, se REJECT_SAMPLE_VALUE = 1000, o PolyBase calculará o percentual de linhas com falha depois de tentar importar 1000 linhas do arquivo de dados externo. Se o percentual de linhas com falha for menor que reject_value, o PolyBase tentará recuperar outras 1.000 linhas. Ele continuará recalculando o percentual de linhas com falha depois de tentar importar cada 1.000 linhas adicionais.
Observação
Como o PolyBase calcula o percentual de linhas com falha em intervalos, o percentual real de linhas com falha pode exceder reject_value.
Exemplo:
Este exemplo mostra como as três opções REJECT interagem. Por exemplo, se REJECT_TYPE = percentage, REJECT_VALUE = 30 e REJECT_SAMPLE_VALUE = 100, o seguinte cenário poderá ocorrer:
- O PolyBase tenta recuperar as 100 primeiras linhas; 25 falharão e 75 serão bem-sucedidas.
- O percentual de linhas com falha é calculado como 25%, que é menor que o valor de rejeição de 30%. Como resultado, o PolyBase continuará recuperando dados da fonte de dados externa.
- O PolyBase tenta carregar as próximas 100 linhas; dessa vez, 25 são bem-sucedidas e 75 falham.
- O percentual de linhas com falha é recalculado como 50%. O percentual de linhas com falha excedeu o valor de rejeição de 30%.
- A consulta do PolyBase falha com 50% de linhas rejeitadas depois de tentar retornar as 200 primeiras linhas. Observe que as linhas correspondentes foram retornadas antes de a consulta do PolyBase detectar que o limite de rejeição foi excedido.
REJECTED_ROW_LOCATION = Local do diretório
Aplica-se ao: SQL Server 2019 CU6 e versões posteriores, Azure Synapse Analytics.
Especifica o diretório na fonte de dados externos em que as linhas rejeitadas e o arquivo de erro correspondente devem ser gravados.
Se o caminho especificado não existir, PolyBase criará um em seu nome. Um diretório filho é criado com o nome "_rejectedrows". O caractere "_" garante que o diretório tenha escape para outro processamento de dados, a menos que explicitamente nomeado no parâmetro de localização. Dentro desse diretório, há uma pasta criada com base na hora do envio do carregamento no formato YearMonthDay -HourMinuteSecond (por exemplo, 20230330-173205). Nessa pasta, dois tipos de arquivos são gravados, o arquivo _reason e o arquivo de dados. Esta opção só pode ser usada com fontes de dados externas em que TYPE = HADOOP e com tabelas externas que usam DELIMITEDTEXT FORMAT_TYPE. Para saber mais, confira CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
Os arquivos de motivo e os arquivos de dados têm o queryID associado à instrução CTAS. Já que os dados e o motivo estão em arquivos separados, arquivos correspondentes têm um sufixo correspondente.
Permissões
Exige estas permissões de usuário:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (só se aplica a fontes de dados externas do Hadoop e do Armazenamento do Azure)
- CONTROL DATABASE (aplica-se somente a fontes de dados externas do Hadoop e do Armazenamento do Azure)
Observe que o logon remoto especificado na DATABASE SCOPED CREDENTIAL usada no comando CREATE EXTERNAL TABLE deve ter permissão de leitura para o caminho/tabela/coleção na fonte de dados externa especificada no parâmetro LOCATION. Se você estiver planejando usar essa EXTERNAL TABLE para exportar dados para uma fonte de dados externa do Hadoop ou do Armazenamento do Azure, o logon especificado deverá ter permissão de gravação no caminho especificado em LOCATION. Observe que, atualmente, não há suporte para o Hadoop no SQL Server 2022 (16.x).
Para o Armazenamento de Blobs do Azure, ao configurar as chaves de acesso e a SAS (assinatura de acesso compartilhado) no portal do Azure, no Armazenamento de Blobs do Azure ou nas conas de armazenamento do ADLS Gen2, configure as Permissões aceitas para conceder pelo menos permissões de Leitura e Gravação. A permissão deLista também pode ser necessária ao pesquisar entre pastas. Você também deve selecionar Contêiner e Objeto como os tipos de recursos permitidos.
Importante
A permissão ALTER ANY EXTERNAL DATA SOURCE concede a qualquer entidade de segurança a capacidade de criar e modificar qualquer objeto de fonte de dados externa e, portanto, isso também concede a capacidade de acessar todas as credenciais no escopo do banco de dados no banco de dados. Essa permissão precisa ser considerada como altamente privilegiada e, portanto, ser concedida somente para entidades de segurança confiáveis no sistema.
Tratamento de erros
Ao executar a instrução CREATE EXTERNAL TABLE, o PolyBase tenta se conectar à fonte de dados externa. Se a tentativa de conexão falhar, a instrução falhará e a tabela externa não será criada. Pode levar um minuto ou mais para que o comando falhe, porque o PolyBase tenta a conexão novamente antes de, no fim, falhar a consulta.
Comentários
Em cenários de consulta ad hoc, assim como SELECT FROM EXTERNAL TABLE, o PolyBase armazena as linhas recuperadas da fonte de dados externa em uma tabela temporária. Após a conclusão da consulta, o PolyBase remove e exclui a tabela temporária. Nenhum dado permanente é armazenado em tabelas SQL.
Por outro lado, no cenário de importação, assim como SELECT INTO FROM EXTERNAL TABLE, o PolyBase armazena as linhas recuperadas da fonte de dados externa como dados permanentes na tabela SQL. A nova tabela é criada durante a execução de consulta quando o PolyBase recupera os dados externos.
O PolyBase pode enviar por push uma parte da computação de consulta para o Hadoop para melhorar o desempenho da consulta. Essa ação é chamada de aplicação de predicado. Para habilitá-la, especifique a opção de local do gerenciador de recursos do Hadoop em CREATE EXTERNAL DATA SOURCE.
Você pode criar várias tabelas externas que referenciam as mesmas fontes de dados externas ou fontes diferentes.
Limitações e restrições
Como os dados de uma tabela externa não residem no controle de gerenciamento direto do SQL Server, eles podem ser alterados ou removidos a qualquer momento por um processo externo. Por isso, não há garantia de que os resultados da consulta em uma tabela externa sejam determinísticos. A mesma consulta pode retornar resultados diferentes a cada vez que ela é executada em uma tabela externa. Da mesma forma, uma consulta pode falhar se os dados externos são removidos ou realocados.
Você pode criar várias tabelas externas que referenciam fontes de dados externas diferentes. Se você executar consultas simultaneamente em diferentes fontes de dados do Hadoop, cada fonte do Hadoop deverá usar a mesma definição de configuração do servidor 'hadoop connectivity'. Por exemplo, não é possível executar simultaneamente uma consulta em um cluster Cloudera Hadoop e um cluster Hortonworks Hadoop, pois eles usam configurações diferentes. Para obter definições de configuração e combinações compatíveis, confira Configuração de conectividade do PolyBase.
Quando a tabela externa está usando DELIMITEDTEXT, CSV, PARQUET ou DELTA como tipos de dados, as tabelas externas oferecem suporte apenas a estatísticas para uma coluna por comando CREATE STATISTICS.
Somente estas instruções DDL (linguagem de definição de dados) são permitidas em tabelas externas:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Constructos e operações não compatíveis:
- A restrição DEFAULT em colunas de tabela externa
- Operações DML (linguagem de manipulação de dados) de exclusão, inserção e atualização
Limitações da consulta
O PolyBase pode consumir um máximo de 33 mil arquivos por pasta durante a execução de 32 consultas simultâneas do PolyBase. O número máximo inclui arquivos e subpastas em cada pasta do HDFS. Se o grau de simultaneidade é menor que 32, um usuário pode executar consultas do PolyBase em pastas do HDFS que contêm mais de 33 mil arquivos. Recomendamos que você mantenha os caminhos de arquivo externo curtos e use, no máximo, 30 mil arquivos por pasta do HDFS. Quando muitos arquivos são referenciados, pode ocorrer uma exceção de memória insuficiente da JVM (Máquina Virtual Java).
Limitações de largura da tabela
o PolyBase no SQL Server 2016 tem um limite de largura de linha de 32 KB, com base no tamanho máximo de uma única linha válida por definição de tabela. Se a soma do esquema de coluna for maior que 32 KB, o PolyBase não poderá consultar os dados.
Limitações do tipo de dados
Os seguintes tipos de dados não podem ser usados em tabelas externas do PolyBase:
geographygeometryhierarchyidimagetextnTextxml- Qualquer tipo definido pelo usuário
Limitações específicas da fonte de dados
Oracle
Não há suporte a sinônimos Oracle para uso com o PolyBase.
Tabelas externas para coleções do MongoDB que contêm matrizes
Para criar tabelas externas para coleções do MongoDB que contêm matrizes, você deve usar a extensão de Virtualização de Dados para o Azure Data Studio para produzir uma instrução CREATE EXTERNAL TABLE com base no esquema detectado pelo Driver ODBC do PolyBase para MongoDB. As ações de nivelamento são executadas automaticamente pelo driver. Como alternativa, você pode usar sp_data_source_objects (Transact-SQL) para detectar o esquema de coleção (colunas) e criar manualmente a tabela externa. O procedimento armazenado sp_data_source_table_columns também executa automaticamente o nivelamento por meio do driver ODBC do PolyBase para o driver MongoDB. A extensão de Virtualização de Dados para o Azure Data Studio e o sp_data_source_table_columns usam os mesmos procedimentos armazenados internos para consultar o esquema externo.
Bloqueio
Bloqueio compartilhado no objeto SCHEMARESOLUTION.
Segurança
Os arquivos de dados para uma tabela externa são armazenados no Hadoop ou no Armazenamento de Blobs do Azure. Esses arquivos de dados são criados e gerenciados por seus próprios processos. É sua responsabilidade gerenciar a segurança dos dados externos.
Exemplos
a. Criar uma tabela externa com os dados em um formato delimitado por texto
Este exemplo mostra todas as etapas necessárias para criar uma tabela externa que tem os dados formatados em arquivos delimitados por texto. Ele define uma fonte de dados externa mydatasource e um formato de arquivo externo myfileformat. Em seguida, esses objetos no nível do banco de dados são referenciados na instrução CREATE EXTERNAL TABLE. Para saber mais, confira CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Criar uma tabela externa com os dados no formato RCFile
Este exemplo mostra todas as etapas necessárias para criar uma tabela externa que tem os dados formatados como RCFiles. Ele define uma fonte de dados externa mydatasource_rc e um formato de arquivo externo myfileformat_rc. Em seguida, esses objetos no nível do banco de dados são referenciados na instrução CREATE EXTERNAL TABLE. Para saber mais, confira CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Criar uma tabela externa com os dados no formato ORC
Este exemplo mostra todas as etapas necessárias para criar uma tabela externa que tem os dados formatados como arquivos ORC. Ele define uma fonte de dados externa mydatasource_orc e um formato de arquivo externo myfileformat_orc. Em seguida, esses objetos no nível do banco de dados são referenciados na instrução CREATE EXTERNAL TABLE. Para saber mais, confira CREATE EXTERNAL DATA SOURCE e CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Consultar dados do Hadoop
O ClickStream é uma tabela externa que se conecta ao arquivo de texto delimitado employee.tbl em um cluster Hadoop. A consulta a seguir se parece com uma consulta em uma tabela padrão. No entanto, essa consulta recupera dados do Hadoop e, em seguida, calcula os resultados.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Unir dados do Hadoop a dados do SQL
Essa consulta se parece com um JOIN padrão em duas tabelas SQL. A diferença é que o PolyBase recupera os dados de clickstream do Hadoop e, em seguida, une-os na tabela UrlDescription. Uma tabela é uma tabela externa e a outra é uma tabela SQL padrão.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Importar dados do Hadoop para uma tabela SQL
Este exemplo cria uma tabela SQL ms_user que armazena permanentemente o resultado de uma junção entre a tabela SQL padrão user e a tabela externa ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Criar uma tabela externa para o SQL Server
Antes de criar uma credencial no escopo do banco de dados, o banco de dados de usuário precisa ter uma chave mestra para proteger a credencial. Para obter mais informações, confira CREATE MASTER KEY e CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Crie uma fonte de dados externa chamada SQLServerInstance, e uma tabela externa chamada sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
I. Criar uma tabela externa para Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Criar uma tabela externa para Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Criar uma tabela externa para MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Consultar o armazenamento de objetos em conformidade com S3 por meio de tabela externa
Aplica-se a: SQL Server 2022 (16.x) e versões posteriores
O exemplo a seguir demonstra o uso de T-SQL para consultar um arquivo Parquet armazenado no armazenamento de objetos em conformidade com o S3 por meio da consulta de tabela externa. O exemplo usa um caminho relativo dentro da fonte de dados externa.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Próximas etapas
Saiba mais sobre conceitos relacionados nos seguintes artigos:
* Banco de Dados SQL do Azure *
Visão geral: Banco de Dados SQL do Azure
No Banco de Dados SQL do Azure, cria uma tabela externa oara consultas elásticas (em versão prévia).
Confira também CREATE EXTERNAL DATA SOURCE.
Sintaxe
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Argumentos
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
O nome de uma a três partes da tabela a ser criada. Para uma tabela externa, o SQL armazena somente os metadados da tabela junto com estatísticas básicas sobre o arquivo ou a pasta referenciada no Banco de Dados SQL do Azure. Nenhum dado real é movido ou armazenado no Banco de Dados SQL do Azure.
Importante
Para ter o melhor desempenho, se o driver da fonte de dados externa tem suporte para um nome de três partes, é altamente recomendável fornecer esse nome.
<column_definition> [ ,...n ]
O CREATE EXTERNAL TABLE é compatível com a configuração de nome de coluna, tipo de dados, nulidade e ordenação. Não é possível usar a DEFAULT CONSTRAINT em tabelas externas.
Observação
Text, nText e XML não são tipos de dados com suporte para colunas em tabelas externas para o Banco de Dados SQL do Azure.
As definições de coluna, incluindo os tipos de dados e o número de colunas, devem corresponder aos dados nos arquivos externos. Se houver uma incompatibilidade, as linhas do arquivo serão rejeitadas ao consultar os dados propriamente ditos.
Opções de tabela externa fragmentada
Especifica a fonte de dados externa (uma fonte de dados não SQL Server) e um método de distribuição para a consulta elástica.
DATA_SOURCE
A cláusula DATA_SOURCE define a fonte de dados externa (um mapa de fragmentos) usada para a tabela externa. Para obter um exemplo, confira Criar tabelas externas.
Importante
O Banco de Dados SQL do Azure dá suporte à criação de tabelas externas para tipos RDMS e SHARD_MAP_MANAGER de FONTE DE DADOS EXTERNA. O Banco de Dados SQL do Azure não dá suporte à criação de tabelas externas para o Armazenamento de Blobs do Azure.
SCHEMA_NAME e OBJECT_NAME
As cláusulas SCHEMA_NAME e OBJECT_NAME mapeiam a definição da tabela externa para uma tabela em um esquema diferente. Se for omitido, o esquema do objeto remoto será considerado "dbo" e seu nome será considerado como sendo idêntico ao nome da tabela externa que está sendo definido. Isso é útil se o nome da tabela remota já existe no banco de dados em que você deseja criar a tabela externa. Por exemplo, você deseja definir uma tabela externa para obter uma exibição agregada de exibições de catálogo ou de DMVs em sua camada de dados expandida. Como as exibições de catálogo e as DMVs já existem localmente, você não pode usar seus nomes para a definição da tabela externa. Em vez disso, use outro nome e a exibição do catálogo ou o nome da DMV nas cláusulas SCHEMA_NAME e/ou OBJECT_NAME. Para obter um exemplo, confira Criar tabelas externas.
DISTRIBUTION
Opcional. Esse argumento é necessário para bancos de dados do tipo SHARD_MAP_MANAGER. Esse argumento controla se uma tabela é tratada como uma tabela fragmentada ou uma tabela replicada. Com tabelas SHARDED (column name), os dados de tabelas diferentes não se sobrepõem. REPLICATED especifica que as tabelas têm os mesmos dados em cada fragmento. ROUND_ROBIN indica que um método específico ao aplicativo é usado para distribuir os dados.
A cláusula DISTRIBUTION especifica a distribuição de dados usada para esta tabela. O processador de consultas utiliza as informações fornecidas na cláusula DISTRIBUTION para criar planos de consulta mais eficientes.
- SHARDED significa que os dados são particionados horizontalmente entre os bancos de dados. A chave de particionamento para a distribuição de dados é o parâmetro
sharding_column_name. - REPLICATED significa que cópias idênticas da tabela estão presentes em cada banco de dados. É sua responsabilidade assegurar que as réplicas sejam idênticas entre os bancos de dados.
- ROUND_ROBIN significa que a tabela é particionada horizontalmente com um método de distribuição dependente do aplicativo.
Permissões
Usuários com acesso à tabela externa têm acesso automaticamente a tabelas remotas subjacentes com a credencial fornecida na definição de fonte de dados externa. Evite a elevação de privilégios indesejada usando credencial da fonte de dados externa. Use GRANT ou REVOKE para uma tabela externa como se fosse uma tabela normal. Depois de definir a fonte de dados externa e as tabelas externas, agora você poderá usar o T-SQL completo nas tabelas externas.
Tratamento de erros
Ao executar a instrução CREATE EXTERNAL TABLE, se a tentativa de conexão falhar, a instrução falhará e a tabela externa não será criada. Pode levar um minuto ou mais para que o comando falhe, porque o Banco de Dados SQL tenta a conexão novamente antes de, no fim, falhar a consulta.
Comentários
Em cenários de consulta ad hoc, como SELECT FROM EXTERNAL TABLE, o Banco de Dados SQL armazena as linhas recuperadas da fonte de dados externa em uma tabela temporária. Após a conclusão da consulta, o Banco de Dados SQL remove e exclui a tabela temporária. Nenhum dado permanente é armazenado em tabelas SQL.
Por outro lado, no cenário de importação, assim como SELECT INTO FROM EXTERNAL TABLE, o Banco de Dados SQL armazena as linhas recuperadas da fonte de dados externa como dados permanentes na tabela SQL. A nova tabela é criada durante a execução de consulta quando o Banco de Dados SQL recupera os dados externos.
Você pode criar várias tabelas externas que referenciam as mesmas fontes de dados externas ou fontes diferentes.
Limitações e restrições
O acesso a dados por meio de uma tabela externa não adere à semântica de isolamento dentro do SQL Server. Isso significa que a consulta de uma tabela externa não impõe nenhum isolamento de bloqueio ou instantâneo e, portanto, o retorno de dados poderá ser alterado se os dados na fonte de dados externa estiverem sendo alterados. A mesma consulta pode retornar resultados diferentes a cada vez que ela é executada em uma tabela externa. Da mesma forma, uma consulta pode falhar se os dados externos são removidos ou realocados.
Você pode criar várias tabelas externas que referenciam fontes de dados externas diferentes.
Somente estas instruções DDL (linguagem de definição de dados) são permitidas em tabelas externas:
- CREATE TABLE e DROP TABLE.
- CREATE VIEW e DROP VIEW.
Constructos e operações não compatíveis:
- A restrição DEFAULT em colunas de tabela externa.
- Operações DML (Linguagem de Manipulação de Dados) de exclusão, inserção e atualização.
- Máscara Dinâmica de Dados em colunas da tabela externa.
- Não há suporte para cursores em tabelas externas no Banco de Dados SQL do Azure.
Somente predicados literais definidos em uma consulta podem ser enviados por push para a fonte de dados externa. Isso é diferente de servidores vinculados e do acesso em que os predicados determinados durante a execução da consulta podem ser usados, ou seja, quando usados em conjunto com um loop aninhado em um plano de consulta. Geralmente, isso fará com que toda a tabela externa seja copiada localmente e, em seguida, unida.
-- Assuming External.Orders is an external table and Customer is a local table.
-- This query will copy the whole of the external locally as the predicate needed
-- to filter isn't known at compile time. Its only known during execution of the query
SELECT Orders.OrderId, Orders.OrderTotal
FROM External.Orders
WHERE CustomerId IN (
SELECT TOP 1 CustomerId
FROM Customer
WHERE CustomerName = 'MyCompany'
);
O uso de tabelas externas impede o uso de paralelismo no plano de consulta.
As tabelas externas são implementadas como Consulta Remota e, como tal, o número estimado de linhas retornadas geralmente é 1000; há outras regras com base no tipo de predicado usado para filtrar a tabela externa. Elas são estimativas baseadas em regras em vez de estimativas baseadas nos dados reais na tabela externa. O otimizador não acessa a fonte de dados remota para obter uma estimativa mais precisa.
Limitações do tipo de dados
Os seguintes tipos de dados não podem ser usados em tabelas externas do PolyBase:
geographygeometryhierarchyidimagetextnTextxml- Qualquer tipo definido pelo usuário
Bloqueio
Bloqueio compartilhado no objeto SCHEMARESOLUTION.
Exemplos
a. Criar tabela externa para o Banco de Dados SQL do Azure
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Criar uma tabela externa para uma fonte de dados fragmentada
Este exemplo remapeia uma DMV remota para uma tabela externa usando as cláusulas SCHEMA_NAME e OBJECT_NAME.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Próximas etapas
Saiba mais sobre tabelas externas no Banco de Dados SQL do Azure nos seguintes artigos:
* Azure Synapse
Analytics *
Visão geral: Azure Synapse Analytics
Use uma tabela externa para:
- Os pools de SQL dedicados podem consultar, importar e armazenar dados do Hadoop, do Armazenamento de Blobs do Azure e do Azure Data Lake Storage Gen1 e Gen2.
- Os pools de SQL sem servidor podem consultar, importar e armazenar dados do Armazenamento de Blobs do Azure e o Azure Data Lake Storage Gen1 e Gen2. Dispositivos sem servidor não dão suporte a
TYPE=Hadoop.
Confira também CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Para obter mais diretrizes e exemplos sobre como usar tabelas externas com o Azure Synapse, confira como Usar tabelas externas com o SQL do Synapse.
Sintaxe
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argumentos
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
O nome de uma a três partes da tabela a ser criada. Para uma tabela externa, apenas os metadados da tabela, junto com estatísticas básicas sobre o arquivo ou a pasta referenciada no Azure Data Lake, no Hadoop ou no Armazenamento de Blobs do Azure. Nenhum dado real é movido ou armazenado quando tabelas externas são criadas.
Importante
Para ter o melhor desempenho, se o driver da fonte de dados externa tem suporte para um nome de três partes, é altamente recomendável fornecer esse nome.
<column_definition> [ ,...n ]
O CREATE EXTERNAL TABLE é compatível com a configuração de nome de coluna, tipo de dados, nulidade e ordenação. Não é possível usar a DEFAULT CONSTRAINT em tabelas externas.
Observação
Os tipos de dados preteridos text, ntext e XML não são compatíveis com tipos de dados para colunas em tabelas externas do Synapse Analytics.
- Ao ler arquivos delimitados, as definições de coluna, incluindo os tipos de dados e o número de colunas, devem corresponder aos dados nos arquivos externos. Se houver uma incompatibilidade, as linhas do arquivo serão rejeitadas ao consultar os dados propriamente ditos.
- Ao ler em arquivos Parquet, você pode especificar apenas as colunas que deseja ler e ignorar o restante.
LOCATION = 'folder_or_filepath'
Especifica a pasta ou o caminho do arquivo e o nome de arquivo para os dados reais no Azure Data Lake, Hadoop ou no Armazenamento de Blobs do Azure. O local inicia da pasta raiz. A pasta raiz é o local de dados especificado na fonte de dados externa. A instrução CREATE EXTERNAL TABLE AS SELECT cria o caminho e a pasta, caso ela não exista. CREATE EXTERNAL TABLE não cria o caminho e a pasta.
Se você especificar LOCATION para que ele seja uma pasta, uma consulta do PolyBase que seleciona por meio da tabela externa recuperará os arquivos da pasta e todas as suas subpastas. Assim como o Hadoop, o PolyBase não retorna pastas ocultas. Ele também não retorna arquivos dos quais o nome do arquivo começa com um sublinhado (_) ou um ponto final (.).
Na imagem de exemplo a seguir, se LOCATION='/webdata/', uma consulta do PolyBase retornará linhas de mydata.txt e mydata2.txt. Ela não retornará mydata3.txt porque ele está em uma subpasta de uma pasta oculta. E ele não retorna _hidden.txt porque é um arquivo oculto.
Ao contrário das tabelas externas do Hadoop, as tabelas externas nativas não retornam subpastas a menos que você especifique /** no final do caminho. Neste exemplo, se LOCATION='/webdata/', uma consulta do pool de SQL sem servidor retornará linhas de mydata.txt. Ele não retornará mydata2.txt e mydata3.txt porque eles estão localizados em uma subpasta. As tabelas do Hadoop retornarão todos os arquivos dentro de qualquer subpasta.
Tanto as tabelas do Hadoop quanto as externas nativas ignoram os arquivos com nomes que começam com um sublinhado (_) ou um ponto final (.).
DATA_SOURCE = external_data_source_name
Especifica o nome da fonte de dados externa que contém o local dos dados externos. Esse local está no Azure Data Lake. Para criar uma fonte de dados externa, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica o nome do objeto de formato de arquivo externo que armazena o tipo de arquivo e o método de compactação para os dados externos. Para criar um formato de arquivo externo, use CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Especifica o conjunto de opções que descrevem como ler os arquivos subjacentes. Atualmente, a única opção disponível é {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}, que instrui a tabela externa a ignorar as atualizações feitas nos arquivos subjacentes, mesmo que isso possa causar algumas operações de leitura inconsistentes. Use essa opção somente em casos especiais em que você tenha arquivos acrescentados com frequência. Essa opção está disponível no pool de SQL sem servidor para formato CSV.
opções REJECT
As opções de rejeição estão em versão prévia para pools de SQL sem servidor no Azure Synapse Analytics.
Essa opção pode ser usada somente com fontes de dados externas em que TYPE = HADOOP.
Especifique parâmetros de rejeição que determinam como o PolyBase manipulará registros sujos recuperados da fonte de dados externa. Um registro de dados é considerado 'sujo' se os tipos de dados reais ou o número de colunas não correspondem às definições de coluna da tabela externa.
Quando você não especifica nem altera os valores de rejeição, o PolyBase usa valores padrão. Essas informações sobre os parâmetros de rejeição são armazenadas como metadados adicionais quando você cria uma tabela externa com a instrução CREATE EXTERNAL TABLE. Quando uma instrução SELECT futura ou instrução INTO SELECT selecionar dados da tabela externa, o PolyBase usará as opções de rejeição para determinar o número ou o percentual de linhas que pode ser rejeitado antes que a consulta real falhe. A consulta retorna resultados (parciais) até que o limite de rejeição seja excedido. Em seguida, ela falha com a mensagem de erro apropriada.
A opção de formato PARSER_VERSION só tem suporte em pools de SQL sem servidor.
REJECT_TYPE = value | percentage
Esclarece se a opção REJECT_VALUE é especificada como um valor literal ou um percentual.
value
REJECT_VALUE é um valor literal, não um percentual. A consulta do PolyBase falhará quando o número de linhas rejeitadas exceder reject_value.
Por exemplo, se REJECT_VALUE = 5 e REJECT_TYPE = value, a consulta SELECT do PolyBase falhará depois de cinco linhas serem rejeitadas.
percentage
REJECT_VALUE é um percentual, não um valor literal. Uma consulta do PolyBase falhará quando o percentage de linhas com falha exceder reject_value. O percentual de linhas com falha é calculado em intervalos.
REJECT_VALUE = reject_value
Especifica o valor ou o percentual de linhas que pode ser rejeitado antes da falha da consulta.
- Para REJECT_TYPE = value, reject_value deve ser um inteiro entre 0 e 2.147.483.647.
- Para REJECT_TYPE = percentage, reject_value deve ser um float entre 0 e 100. A porcentagem só é válida para pools de SQL dedicados em que
TYPE=HADOOP.
A consulta falhará quando o número de linhas rejeitadas exceder o reject_value. Por exemplo, se REJECT_VALUE = 5 e REJECT_TYPE = value, a consulta SELECT falhará depois que cinco linhas forem rejeitadas.
REJECT_SAMPLE_VALUE = reject_sample_value
Esse atributo é obrigatório quando você especifica REJECT_TYPE = percentage. Ele determina o número de linhas de tentativa de recuperação antes que o PolyBase recalcule a percentual de linhas rejeitadas.
O parâmetro reject_sample_value deve ser um inteiro entre 0 e 2.147.483.647.
Por exemplo, se REJECT_SAMPLE_VALUE = 1000, o PolyBase calculará o percentual de linhas com falha depois de tentar importar 1000 linhas do arquivo de dados externo. Se o percentual de linhas com falha for menor que reject_value, o PolyBase tentará recuperar outras 1.000 linhas. Ele continuará recalculando o percentual de linhas com falha depois de tentar importar cada 1.000 linhas adicionais.
Observação
Como o PolyBase calcula o percentual de linhas com falha em intervalos, o percentual real de linhas com falha pode exceder reject_value.
Exemplo:
Este exemplo mostra como as três opções REJECT interagem. Por exemplo, se REJECT_TYPE = percentage, REJECT_VALUE = 30 e REJECT_SAMPLE_VALUE = 100, o seguinte cenário poderá ocorrer:
- O PolyBase tenta recuperar as 100 primeiras linhas; 25 falharão e 75 serão bem-sucedidas.
- O percentual de linhas com falha é calculado como 25%, que é menor que o valor de rejeição de 30%. Como resultado, o PolyBase continuará recuperando dados da fonte de dados externa.
- O PolyBase tenta carregar as próximas 100 linhas; dessa vez, 25 são bem-sucedidas e 75 falham.
- O percentual de linhas com falha é recalculado como 50%. O percentual de linhas com falha excedeu o valor de rejeição de 30%.
- A consulta do PolyBase falha com 50% de linhas rejeitadas depois de tentar retornar as 200 primeiras linhas. Observe que as linhas correspondentes foram retornadas antes de a consulta do PolyBase detectar que o limite de rejeição foi excedido.
REJECTED_ROW_LOCATION = Local do diretório
Especifica o diretório na fonte de dados externos em que as linhas rejeitadas e o arquivo de erro correspondente devem ser gravados.
Se o caminho especificado não existir, ele será criado. Um diretório filho é criado com o nome _rejectedrows. O caractere _ garante que o diretório tenha escape para outro processamento de dados, a menos que explicitamente nomeado no parâmetro de localização.
- Em pools de SQL sem servidor, o caminho é
YearMonthDay_HourMinuteSecond_StatementID. Você pode usar a ID da instrução para correlacionar a pasta com a consulta que a gerou. - Em pools de SQL dedicados, o caminho criado baseia-se na hora do envio de carregamento no formato
YearMonthDay -HourMinuteSecond, por exemplo20180330-173205.
Nessa pasta, dois tipos de arquivos são gravados, o arquivo _reason e o arquivo de dados.
Para obter mais informações, consulte CREATE EXTERNAL DATA SOURCE.
Os arquivos de motivo e os arquivos de dados têm o queryID associado à instrução CTAS. Já que os dados e o motivo estão em arquivos separados, arquivos correspondentes têm um sufixo correspondente.
Em pools de SQL sem servidor, o arquivo error.json contém uma matriz JSON com erros encontrados relacionados a linhas rejeitadas. Cada elemento que representa o erro contém os seguintes atributos:
| Atributo | Descrição |
|---|---|
| Erro | Motivo pelo qual a linha é rejeitada. |
| Linha | Número ordinal de linha rejeitado no arquivo. |
| Coluna | Número ordinal de coluna rejeitada. |
| Valor | Valor de coluna rejeitado. Se o valor for maior que 100 caracteres, somente os primeiros 100 caracteres serão exibidos. |
| Arquivo | Caminho para o arquivo ao qual a linha pertence. |
Permissões
Exige estas permissões de usuário:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Observação
As permissões CONTROL DATABASE são necessárias para criar somente MASTER KEY, DATABASE SCOPED CREDENTIAL e EXTERNAL DATA SOURCE
Observe que o logon que cria a fonte de dados externa deve ter a permissão de leitura e gravação na fonte de dados externa, localizada no Hadoop ou no Armazenamento de Blobs do Azure.
Importante
A permissão ALTER ANY EXTERNAL DATA SOURCE concede a qualquer entidade de segurança a capacidade de criar e modificar qualquer objeto de fonte de dados externa e, portanto, isso também concede a capacidade de acessar todas as credenciais no escopo do banco de dados no banco de dados. Essa permissão precisa ser considerada como altamente privilegiada e, portanto, ser concedida somente para entidades de segurança confiáveis no sistema.
Tratamento de erros
Ao executar a instrução CREATE EXTERNAL TABLE, o PolyBase tenta se conectar à fonte de dados externa. Se a tentativa de conexão falhar, a instrução falhará e a tabela externa não será criada. Pode levar um minuto ou mais para que o comando falhe, porque o PolyBase tenta a conexão novamente antes de, no fim, falhar a consulta.
Comentários
Em cenários de consulta ad hoc, assim como SELECT FROM EXTERNAL TABLE, o PolyBase armazena as linhas recuperadas da fonte de dados externa em uma tabela temporária. Após a conclusão da consulta, o PolyBase remove e exclui a tabela temporária. Nenhum dado permanente é armazenado em tabelas SQL.
Por outro lado, no cenário de importação, assim como SELECT INTO FROM EXTERNAL TABLE, o PolyBase armazena as linhas recuperadas da fonte de dados externa como dados permanentes na tabela SQL. A nova tabela é criada durante a execução de consulta quando o PolyBase recupera os dados externos.
O PolyBase pode enviar por push uma parte da computação de consulta para o Hadoop para melhorar o desempenho da consulta. Essa ação é chamada de aplicação de predicado. Para habilitá-la, especifique a opção de local do gerenciador de recursos do Hadoop em CREATE EXTERNAL DATA SOURCE.
Você pode criar várias tabelas externas que referenciam as mesmas fontes de dados externas ou fontes diferentes.
Preste atenção aos dados de origem usando a ordenação UTF-8. Para qualquer dado de origem que use a ordenação UTF-8, você precisa fornecer manualmente uma ordenação não UTF-8 em cada coluna UTF-8 na instrução CREATE EXTERNAL TABLE. Isso ocorre porque o suporte a UTF-8 não se estende a tabelas externas. Ao tentar criar uma tabela externa com uma ordenação UTF-8, você receberá uma mensagem de erro Unsupported collation. Se a ordenação de banco de dados da tabela externa for uma ordenação UTF-8, a criação de tabela externa falhará, a menos que você forneça uma ordenação explícita de colunas não UTF-8, por exemplo, [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,.
Pools de SQL dedicados e sem servidor no Azure Synapse Analytics usam bases de código diferentes para virtualização de dados. Os pools de SQL sem servidor dão suporte à tecnologia de virtualização de dados nativa. Os pools de SQL dedicados dão suporte à virtualização de dados nativa e do PolyBase. A virtualização de dados do PolyBase é usada quando a FONTE DE DADOS EXTERNA é criada com TYPE=HADOOP.
Limitações e restrições
Como os dados de uma tabela externa não residem no controle de gerenciamento direto do Azure Synapse, eles podem ser alterados ou removidos a qualquer momento por um processo externo. Por isso, não há garantia de que os resultados da consulta em uma tabela externa sejam determinísticos. A mesma consulta pode retornar resultados diferentes a cada vez que ela é executada em uma tabela externa. Da mesma forma, uma consulta pode falhar se os dados externos são removidos ou realocados.
Você pode criar várias tabelas externas que referenciam fontes de dados externas diferentes.
Somente estas instruções DDL (linguagem de definição de dados) são permitidas em tabelas externas:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Constructos e operações não compatíveis:
- A restrição DEFAULT em colunas de tabela externa
- Operações DML (linguagem de manipulação de dados) de exclusão, inserção e atualização
- Máscara Dinâmica de Dados em colunas da tabela externa
Limitações da consulta
recomendamos não exceder 30 mil arquivos por pasta. Quando arquivos em excesso são referenciados, pode ocorrer uma exceção de memória insuficiente da JVM (Máquina Virtual Java) ou uma degradação do desempenho.
Limitações de largura da tabela
o PolyBase no Data Warehouse do Azure tem um limite de largura de linha de 1 MB, com base no tamanho máximo de uma única linha válida por definição de tabela. Se a soma do esquema de coluna for maior que 1 MB, o PolyBase não poderá consultar os dados.
Limitações do tipo de dados
Os seguintes tipos de dados não podem ser usados em tabelas externas do PolyBase:
geographygeometryhierarchyidimagetextnTextxml- Qualquer tipo definido pelo usuário
Bloqueio
Bloqueio compartilhado no objeto SCHEMARESOLUTION.
Exemplos
a. Importar dados do ADLS Gen 2 para o Azure Synapse Analytics
Confira exemplos para ADLS Gen 1 em Criar fonte de dados externa.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Importar dados do Parquet para o Azure Synapse Analytics
O exemplo a seguir cria uma tabela externa. Ele retorna a primeira linha:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Próximas etapas
Saiba mais sobre tabelas externas e conceitos relacionados nos seguintes artigos:
* Analytics
Platform System (PDW) *
Visão geral: Sistema de plataforma de análise
Use uma tabela externa para:
- Consulte dados do Hadoop ou do Armazenamento de Blobs do Azure com instruções Transact-SQL.
- Importar e armazenar dados do Hadoop ou do Armazenamento de Blobs do Azure no Analytics Platform System.
Confira também CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Sintaxe
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Argumentos
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
O nome de uma a três partes da tabela a ser criada. Para uma tabela externa, o Analytics Platform System armazena somente os metadados da tabela junto com estatísticas básicas sobre o arquivo ou a pasta referenciada no Hadoop ou no Armazenamento de Blobs do Azure. Nenhum dado real é movido ou armazenado no Analytics Platform System.
Importante
Para ter o melhor desempenho, se o driver da fonte de dados externa tem suporte para um nome de três partes, é altamente recomendável fornecer esse nome.
<column_definition> [ ,...n ]
O CREATE EXTERNAL TABLE é compatível com a configuração de nome de coluna, tipo de dados, nulidade e ordenação. Não é possível usar a DEFAULT CONSTRAINT em tabelas externas.
As definições de coluna, incluindo os tipos de dados e o número de colunas, devem corresponder aos dados nos arquivos externos. Se houver uma incompatibilidade, as linhas do arquivo serão rejeitadas ao consultar os dados propriamente ditos.
LOCATION = 'folder_or_filepath'
Especifica a pasta ou o caminho do arquivo e o nome de arquivo dos dados reais no Hadoop ou no Armazenamento de Blobs do Azure. O local inicia da pasta raiz. A pasta raiz é o local de dados especificado na fonte de dados externa.
No Analytics Platform System, a instrução CREATE EXTERNAL TABLE AS SELECT cria o caminho e a pasta, caso não existam. CREATE EXTERNAL TABLE não cria o caminho e a pasta.
Se você especificar LOCATION para que ele seja uma pasta, uma consulta do PolyBase que seleciona por meio da tabela externa recuperará os arquivos da pasta e todas as suas subpastas. Assim como o Hadoop, o PolyBase não retorna pastas ocultas. Ele também não retorna arquivos dos quais o nome do arquivo começa com um sublinhado (_) ou um ponto final (.).
Na imagem de exemplo a seguir, se LOCATION='/webdata/', uma consulta do PolyBase retornará linhas de mydata.txt e mydata2.txt. Ela não retornará mydata3.txt porque ele está em uma subpasta de uma pasta oculta. E ele não retorna _hidden.txt porque é um arquivo oculto.
Para alterar o padrão e somente ler da pasta raiz, defina o atributo <polybase.recursive.traversal> como 'false' no arquivo de configuração core-site.xml. Esse arquivo está localizado em <SqlBinRoot>\PolyBase\Hadoop\Conf\ na raiz bin do SQL Server. Por exemplo, C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Especifica o nome da fonte de dados externa que contém o local dos dados externos. Esse local é o Hadoop ou o Armazenamento de Blobs do Azure. Para criar uma fonte de dados externa, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica o nome do objeto de formato de arquivo externo que armazena o tipo de arquivo e o método de compactação para os dados externos. Para criar um formato de arquivo externo, use CREATE EXTERNAL FILE FORMAT.
Opções de rejeição
Essa opção pode ser usada somente com fontes de dados externas em que TYPE = HADOOP.
Especifique parâmetros de rejeição que determinam como o PolyBase manipulará registros sujos recuperados da fonte de dados externa. Um registro de dados é considerado 'sujo' se os tipos de dados reais ou o número de colunas não correspondem às definições de coluna da tabela externa.
Quando você não especifica nem altera os valores de rejeição, o PolyBase usa valores padrão. Essas informações sobre os parâmetros de rejeição são armazenadas como metadados adicionais quando você cria uma tabela externa com a instrução CREATE EXTERNAL TABLE. Quando uma instrução SELECT futura ou instrução INTO SELECT selecionar dados da tabela externa, o PolyBase usará as opções de rejeição para determinar o número ou o percentual de linhas que pode ser rejeitado antes que a consulta real falhe. A consulta retorna resultados (parciais) até que o limite de rejeição seja excedido. Em seguida, ela falha com a mensagem de erro apropriada.
REJECT_TYPE = value | percentage
Esclarece se a opção REJECT_VALUE é especificada como um valor literal ou um percentual.
value
REJECT_VALUE é um valor literal, não um percentual. A consulta do PolyBase falhará quando o número de linhas rejeitadas exceder reject_value.
Por exemplo, se REJECT_VALUE = 5 e REJECT_TYPE = value, a consulta SELECT do PolyBase falhará depois de cinco linhas serem rejeitadas.
percentage
REJECT_VALUE é um percentual, não um valor literal. Uma consulta do PolyBase falhará quando o percentage de linhas com falha exceder reject_value. O percentual de linhas com falha é calculado em intervalos.
REJECT_VALUE = reject_value
Especifica o valor ou o percentual de linhas que pode ser rejeitado antes da falha da consulta.
Para REJECT_TYPE = value, reject_value deve ser um inteiro entre 0 e 2.147.483.647.
Para REJECT_TYPE = percentage, reject_value deve ser um float entre 0 e 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Esse atributo é obrigatório quando você especifica REJECT_TYPE = percentage. Ele determina o número de linhas de tentativa de recuperação antes que o PolyBase recalcule a percentual de linhas rejeitadas.
O parâmetro reject_sample_value deve ser um inteiro entre 0 e 2.147.483.647.
Por exemplo, se REJECT_SAMPLE_VALUE = 1000, o PolyBase calculará o percentual de linhas com falha depois de tentar importar 1000 linhas do arquivo de dados externo. Se o percentual de linhas com falha for menor que reject_value, o PolyBase tentará recuperar outras 1.000 linhas. Ele continuará recalculando o percentual de linhas com falha depois de tentar importar cada 1.000 linhas adicionais.
Observação
Como o PolyBase calcula o percentual de linhas com falha em intervalos, o percentual real de linhas com falha pode exceder reject_value.
Exemplo:
Este exemplo mostra como as três opções REJECT interagem. Por exemplo, se REJECT_TYPE = percentage, REJECT_VALUE = 30 e REJECT_SAMPLE_VALUE = 100, o seguinte cenário poderá ocorrer:
- O PolyBase tenta recuperar as 100 primeiras linhas; 25 falharão e 75 serão bem-sucedidas.
- O percentual de linhas com falha é calculado como 25%, que é menor que o valor de rejeição de 30%. Como resultado, o PolyBase continuará recuperando dados da fonte de dados externa.
- O PolyBase tenta carregar as próximas 100 linhas; dessa vez, 25 são bem-sucedidas e 75 falham.
- O percentual de linhas com falha é recalculado como 50%. O percentual de linhas com falha excedeu o valor de rejeição de 30%.
- A consulta do PolyBase falha com 50% de linhas rejeitadas depois de tentar retornar as 200 primeiras linhas. Observe que as linhas correspondentes foram retornadas antes de a consulta do PolyBase detectar que o limite de rejeição foi excedido.
Permissões
Exige estas permissões de usuário:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
- CONTROL DATABASE
Observe que o logon que cria a fonte de dados externa deve ter a permissão de leitura e gravação na fonte de dados externa, localizada no Hadoop ou no Armazenamento de Blobs do Azure.
Importante
A permissão ALTER ANY EXTERNAL DATA SOURCE concede a qualquer entidade de segurança a capacidade de criar e modificar qualquer objeto de fonte de dados externa e, portanto, isso também concede a capacidade de acessar todas as credenciais no escopo do banco de dados no banco de dados. Essa permissão precisa ser considerada como altamente privilegiada e, portanto, ser concedida somente para entidades de segurança confiáveis no sistema.
Tratamento de erros
Ao executar a instrução CREATE EXTERNAL TABLE, o PolyBase tenta se conectar à fonte de dados externa. Se a tentativa de conexão falhar, a instrução falhará e a tabela externa não será criada. Pode levar um minuto ou mais para que o comando falhe, porque o PolyBase tenta a conexão novamente antes de, no fim, falhar a consulta.
Comentários
Em cenários de consulta ad hoc, assim como SELECT FROM EXTERNAL TABLE, o PolyBase armazena as linhas recuperadas da fonte de dados externa em uma tabela temporária. Após a conclusão da consulta, o PolyBase remove e exclui a tabela temporária. Nenhum dado permanente é armazenado em tabelas SQL.
Por outro lado, no cenário de importação, assim como SELECT INTO FROM EXTERNAL TABLE, o PolyBase armazena as linhas recuperadas da fonte de dados externa como dados permanentes na tabela SQL. A nova tabela é criada durante a execução de consulta quando o PolyBase recupera os dados externos.
O PolyBase pode enviar por push uma parte da computação de consulta para o Hadoop para melhorar o desempenho da consulta. Essa ação é chamada de aplicação de predicado. Para habilitá-la, especifique a opção de local do gerenciador de recursos do Hadoop em CREATE EXTERNAL DATA SOURCE.
Você pode criar várias tabelas externas que referenciam as mesmas fontes de dados externas ou fontes diferentes.
Limitações e restrições
Como os dados de uma tabela externa não residem no controle de gerenciamento direto do dispositivo, eles podem ser alterados ou removidos a qualquer momento por um processo externo. Por isso, não há garantia de que os resultados da consulta em uma tabela externa sejam determinísticos. A mesma consulta pode retornar resultados diferentes a cada vez que ela é executada em uma tabela externa. Da mesma forma, uma consulta pode falhar se os dados externos são removidos ou realocados.
Você pode criar várias tabelas externas que referenciam fontes de dados externas diferentes. Se você executar consultas simultaneamente em diferentes fontes de dados do Hadoop, cada fonte do Hadoop deverá usar a mesma definição de configuração do servidor 'hadoop connectivity'. Por exemplo, não é possível executar simultaneamente uma consulta em um cluster Cloudera Hadoop e um cluster Hortonworks Hadoop, pois eles usam configurações diferentes. Para obter definições de configuração e combinações compatíveis, confira Configuração de conectividade do PolyBase.
Somente estas instruções DDL (linguagem de definição de dados) são permitidas em tabelas externas:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Constructos e operações não compatíveis:
- A restrição DEFAULT em colunas de tabela externa
- Operações DML (linguagem de manipulação de dados) de exclusão, inserção e atualização
- Máscara Dinâmica de Dados em colunas da tabela externa
Limitações da consulta
O PolyBase pode consumir um máximo de 33 mil arquivos por pasta durante a execução de 32 consultas simultâneas do PolyBase. O número máximo inclui arquivos e subpastas em cada pasta do HDFS. Se o grau de simultaneidade é menor que 32, um usuário pode executar consultas do PolyBase em pastas do HDFS que contêm mais de 33 mil arquivos. Recomendamos que você mantenha os caminhos de arquivo externo curtos e use, no máximo, 30 mil arquivos por pasta do HDFS. Quando muitos arquivos são referenciados, pode ocorrer uma exceção de memória insuficiente da JVM (Máquina Virtual Java).
Limitações de largura da tabela
o PolyBase no SQL Server 2016 tem um limite de largura de linha de 32 KB, com base no tamanho máximo de uma única linha válida por definição de tabela. Se a soma do esquema de coluna for maior que 32 KB, o PolyBase não poderá consultar os dados.
No Azure Synapse Analytics, essa limitação foi aumentada para 1 MB.
Limitações do tipo de dados
Os seguintes tipos de dados não podem ser usados em tabelas externas do PolyBase:
geographygeometryhierarchyidimagetextnTextxml- Qualquer tipo definido pelo usuário
Bloqueio
Bloqueio compartilhado no objeto SCHEMARESOLUTION.
Segurança
Os arquivos de dados para uma tabela externa são armazenados no Hadoop ou no Armazenamento de Blobs do Azure. Esses arquivos de dados são criados e gerenciados por seus próprios processos. É sua responsabilidade gerenciar a segurança dos dados externos.
Exemplos
a. Unir os dados do HDFS com os do Analytics Platform System
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Importar dados de linha do HDFS para uma tabela distribuída do Analytics Platform System
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Importar dados de linha do HDFS para uma tabela replicada do Analytics Platform System
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Próximas etapas
Saiba mais sobre tabelas externas no Analytics Platform System nos seguintes artigos:
* Instância Gerenciada de SQL do Azure*
Visão geral: Instância Gerenciada do Azure SQL
Cria uma tabela de dados externa na Instância Gerenciada de SQL do Azure. Para obter informações completas, confira Virtualização de dados com a Instância Gerenciada de SQL do Azure.
A virtualização de dados na Instância Gerenciada de SQL do Azure fornece acesso a dados externos em uma variedade de formatos de arquivo no Azure Data Lake Storage Gen2 ou no Armazenamento de Blobs do Azure e para consultá-los com instruções T-SQL, até mesmo combina os dados com os dados relacionais armazenados localmente usando junções.
Confira também CREATE EXTERNAL DATA SOURCE e DROP EXTERNAL TABLE.
Sintaxe
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumentos
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
O nome de uma a três partes da tabela a ser criada. Para uma tabela externa, apenas os metadados da tabela, junto com estatísticas básicas sobre o arquivo ou a pasta referenciada no Azure Data Lake ou no Armazenamento de Blobs do Azure. Nenhum dado real é movido ou armazenado quando tabelas externas são criadas.
Importante
Para ter o melhor desempenho, se o driver da fonte de dados externa tem suporte para um nome de três partes, é altamente recomendável fornecer esse nome.
<column_definition> [ ,...n ]
O CREATE EXTERNAL TABLE é compatível com a configuração de nome de coluna, tipo de dados, nulidade e ordenação. Não é possível usar a DEFAULT CONSTRAINT em tabelas externas.
As definições de coluna, incluindo os tipos de dados e o número de colunas, devem corresponder aos dados nos arquivos externos. Se houver uma incompatibilidade, as linhas do arquivo serão rejeitadas ao consultar os dados propriamente ditos.
LOCATION = 'folder_or_filepath'
Especifica a pasta ou o caminho do arquivo e o nome de arquivo para os dados reais no Azure Data Lake ou no Armazenamento de Blobs do Azure. O local inicia da pasta raiz. A pasta raiz é o local de dados especificado na fonte de dados externa. CREATE EXTERNAL TABLE não cria o caminho e a pasta.
Se você especificar que LOCATION seja uma pasta, a consulta da Instância Gerenciada de SQL do Azure, que seleciona na tabela externa, recuperará os arquivos da pasta mas não de todas as respectivas subpastas.
A Instância Gerenciada de SQL do Azure não consegue localizar arquivos em subpastas nem em pastas ocultas. Ele também não retorna arquivos dos quais o nome do arquivo começa com um sublinhado (_) ou um ponto final (.).
Na imagem de exemplo a seguir, se LOCATION='/webdata/', uma consulta retornará linhas de mydata.txt. Ela não retornará mydata2.txt porque está em uma subpasta, não retornará mydata3.txt porque está em uma pasta oculta e não retornará _hidden.txt porque é um arquivo oculto.
DATA_SOURCE = external_data_source_name
Especifica o nome da fonte de dados externa que contém o local dos dados externos. Esse local está no Azure Data Lake. Para criar uma fonte de dados externa, use CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica o nome do objeto de formato de arquivo externo que armazena o tipo de arquivo e o método de compactação para os dados externos. Para criar um formato de arquivo externo, use CREATE EXTERNAL FILE FORMAT.
Permissões
Exige estas permissões de usuário:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT
Observação
As permissões CONTROL DATABASE são necessárias para criar somente MASTER KEY, DATABASE SCOPED CREDENTIAL e EXTERNAL DATA SOURCE
Observe que o logon que cria a fonte de dados externa deve ter a permissão de leitura e gravação na fonte de dados externa, localizada no Hadoop ou no Armazenamento de Blobs do Azure.
Importante
A permissão ALTER ANY EXTERNAL DATA SOURCE concede a qualquer entidade de segurança a capacidade de criar e modificar qualquer objeto de fonte de dados externa e, portanto, isso também concede a capacidade de acessar todas as credenciais no escopo do banco de dados no banco de dados. Essa permissão precisa ser considerada como altamente privilegiada e, portanto, ser concedida somente para entidades de segurança confiáveis no sistema.
Comentários
Em cenários de consulta ad hoc, assim como SELECT FROM EXTERNAL TABLE, as linhas que são recuperadas da fonte de dados externa são armazenadas em uma tabela temporária. Depois que a consulta for concluída, as linhas serão removidas e a tabela temporária será excluída. Nenhum dado permanente é armazenado em tabelas SQL.
Por outro lado, no cenário de importação, assim como no SELECT INTO FROM EXTERNAL TABLE, as linhas que são recuperadas da fonte de dados externa são armazenadas como dados permanentes na tabela SQL. A nova tabela é criada durante a execução de consulta quando os dados externos são recuperados.
Atualmente, a virtualização de dados com a Instância Gerenciada de SQL do Azure é somente leitura.
Você pode criar várias tabelas externas que referenciam as mesmas fontes de dados externas ou fontes diferentes.
Limitações e restrições
Como os dados de uma tabela externa não ficam no controle de gerenciamento direto da Instância Gerenciada de SQL do Azure, eles podem ser alterados ou removidos a qualquer momento por um processo externo. Por isso, não há garantia de que os resultados da consulta em uma tabela externa sejam determinísticos. A mesma consulta pode retornar resultados diferentes a cada vez que ela é executada em uma tabela externa. Da mesma forma, uma consulta pode falhar se os dados externos são removidos ou realocados.
Você pode criar várias tabelas externas que referenciam fontes de dados externas diferentes.
Somente estas instruções DDL (linguagem de definição de dados) são permitidas em tabelas externas:
- CREATE TABLE e DROP TABLE
- CREATE STATISTICS e DROP STATISTICS
- CREATE VIEW e DROP VIEW
Constructos e operações não compatíveis:
- A restrição DEFAULT em colunas de tabela externa
- Operações DML (linguagem de manipulação de dados) de exclusão, inserção e atualização
Limitações de largura da tabela
O limite de largura de linha de 1 MB, com base no tamanho máximo de uma única linha válida por definição de tabela. Se a soma do esquema de coluna for maior que 1 MB, as consultas da virtualização de dados falharão.
Limitações do tipo de dados
Os seguintes tipos de dados não podem ser usados em tabelas externas na Instância Gerenciada de SQL do Azure:
geographygeometryhierarchyidimagetextnTextxml- Qualquer tipo definido pelo usuário
Bloqueio
Bloqueio compartilhado no objeto SCHEMARESOLUTION.
Exemplos
a. Consultar dados externos da Instância Gerenciada de SQL do Azure com uma tabela externa
Para obter mais exemplos, confira Criar fonte de dados externa ou veja Virtualização de dados com a Instância Gerenciada de SQL do Azure.
Crie a chave mestra do banco de dados, se ela não existir.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOCrie a credencial com escopo do banco de dados usando um token SAS. Você também pode usar uma identidade gerenciada.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOCrie a fonte de dados externa usando a credencial.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOCrie um EXTERNAL FILE FORMAT e uma EXTERNAL TABLE para consultar os dados como se fossem uma tabela local.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Próximas etapas
Saiba mais sobre tabelas externas e conceitos relacionados nos seguintes artigos:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de