Aprendizado de máquina para pesquisa visual computacional
A capacidade de usar filtros para aplicar efeitos a imagens é útil em tarefas de processamento de imagem, algo que você pode executar com o software de edição de imagem. No entanto, o objetivo da pesquisa visual computacional é, muitas vezes, extrair significado ou, pelo menos, insights acionáveis de imagens, o que requer a criação de modelos de machine learning treinados para reconhecer recursos com base em grandes volumes de imagens existentes.
Dica
Esta unidade pressupõe que você esteja familiarizado com os princípios fundamentais do aprendizado de máquina e tenha conhecimento conceitual do aprendizado profundo com redes neurais. Se você não estiver familiarizado com o aprendizado de máquina, considere concluir o módulo de Princípios básicos do aprendizado de máquina no Microsoft Learn.
Redes neurais convolucionais (CNNs)
Uma das arquiteturas de modelos de machine learning mais comuns para a pesquisa visual computacional é uma rede neural convolucional (CNN). As CNNs usam filtros para extrair mapas de recursos numéricos de imagens e, em seguida, alimentam os valores desses recursos em um modelo de aprendizado profundo para gerar uma previsão de rótulo. Por exemplo, em um cenário de classificação de imagem, o rótulo representa o assunto principal da imagem (em outras palavras, do que se trata essa imagem?). Você pode treinar um modelo de CNN com imagens de diferentes tipos de frutas (como maçã, banana e laranja) para que o rótulo previsto seja o tipo de fruta em uma determinada imagem.
No processo de treinamento de uma CNN, os kernels de filtro são inicialmente definidos usando valores de peso gerados aleatoriamente. À medida que o processo de treinamento avança, as previsões de modelos são avaliadas em relação aos valores dos rótulos conhecidos, e os pesos do filtro são ajustados para melhorar a precisão. Eventualmente, o modelo treinado para classificação de imagens de frutas usa os pesos dos filtros que melhor extraem recursos, ajudando na identificação de diferentes tipos de frutas.
O diagrama a seguir ilustra como funciona uma CNN para um modelo de classificação de imagem:
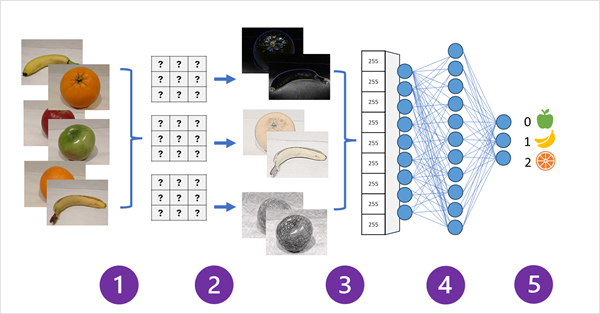
- Imagens com rótulos conhecidos (por exemplo, 0: maçã, 1: banana ou 2: laranja) são alimentadas na rede para treinar o modelo.
- Uma ou mais camadas de filtros são usadas para extrair recursos de cada imagem conforme ela é alimentada pela rede. Os kernels de filtro começam com pesos atribuídos aleatoriamente e geram matrizes de valores numéricos chamados mapas de recursos.
- Os mapas de recursos são mesclados em uma única matriz dimensional de valores de recurso.
- Os valores de recurso são alimentados em uma rede neural totalmente conectada.
- A camada de saída da rede neural usa uma função softmax ou similar para produzir um resultado que contenha um valor de probabilidade para cada possível classe, por exemplo [0,2, 0,5, 0,3].
Durante o treinamento, as probabilidades de saída são comparadas com o rótulo de classe real. Por exemplo, uma imagem de uma banana (classe 1) deve ter o valor [0,0, 1,0, 0,0]. A diferença entre as pontuações de classe previstas e reais é usada para calcular a perda no modelo. Em seguida, os pesos na rede neural totalmente conectada e os kernels de filtro nas camadas de extração de recursos são modificados para reduzir essa perda.
O processo de treinamento é repetido em várias épocas até que um conjunto ideal de pesos seja aprendido. Em seguida, os pesos são salvos e o modelo pode ser usado para prever rótulos de novas imagens para as quais o rótulo é desconhecido.
Observação
Geralmente, as arquiteturas da CNN incluem várias camadas de filtro convolucional e camadas adicionais para reduzir o tamanho dos mapas de recursos, restringir os valores extraídos e manipular os valores dos recursos. Neste exemplo simplificado, essas camadas foram omitidas para se concentrar no conceito principal, que é a utilização dos filtros para extrair recursos numéricos de imagens e, posteriormente, usá-los em uma rede neural para prever rótulos de imagem.
Transformadores e modelos multimodais
As CNNs têm sido o cerne das soluções em pesquisa visual computacional há muitos anos. Embora sejam comumente empregadas para resolver problemas de classificação de imagem, como descrito anteriormente, as CNNs também servem de base para modelos de pesquisa visual computacional mais complexos. Por exemplo, os modelos de detecção de objetos combinam camadas de extração de recursos de CNN com a identificação de regiões de interesse em imagens para localizar várias classes de objeto na mesma imagem.
Transformadores
Os avanços na pesquisa visual computacional ao longo das décadas foram, em grande parte, impulsionados por melhorias nos modelos baseados em CNN. No entanto, em outra disciplina de IA, o processamento de linguagem natural (NLP), a arquitetura de rede neural conhecida como transformer possibilitou o desenvolvimento de modelos sofisticados para o processamento linguístico. Os transformers funcionam processando grandes volumes de dados, codificando tokens de linguagem (que representam palavras ou frases individuais) como incorporações baseadas em vetores (matrizes de valores numéricos). Uma incorporação pode ser concebida como a representação de um conjunto de dimensões que expressam algum atributo semântico do token. As incorporações são criadas de forma a posicionar dimensionalmente tokens frequentemente usados no mesmo contexto mais próximos uns dos outros do que palavras não relacionadas.
Para que tenha um exemplo simples, o diagrama a seguir mostra algumas palavras codificadas como vetores tridimensionais e plotadas em um espaço 3D:
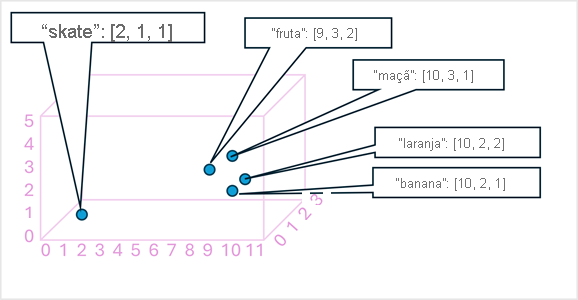
Tokens semanticamente semelhantes são codificados em posições semelhantes, criando um modelo de linguagem semântica que possibilita a criação de soluções NLP sofisticadas para análise de texto, tradução, geração de idiomas e outras tarefas.
Observação
Usamos apenas três dimensões, porque isso é fácil de visualizar. Na realidade, os codificadores em redes transformer criam vetores com muito mais dimensões, estabelecendo relações semânticas complexas entre tokens com base em cálculos algébricos lineares. A matemática envolvida é complexa, assim como a arquitetura de um modelo transformer. Nosso objetivo aqui é apenas fornecer uma compreensão conceitual de como a codificação cria um modelo que encapsula as relações entre entidades.
Modelos multimodais
O sucesso dos transformadores como forma de criar modelos de linguagem levou os pesquisadores de IA a considerar se essa mesma abordagem seria eficaz para dados de imagem. O resultado é o desenvolvimento de modelos multimodais, nos quais o modelo é treinado usando um grande volume de imagens legendadas, sem rótulos fixos. Um codificador de imagem extrai recursos de imagens com base em valores de pixel e os combina com inserções de texto criadas por um codificador de idioma. O modelo geral encapsula as relações entre inserções de token de linguagem natural e recursos de imagem, conforme mostrado aqui:
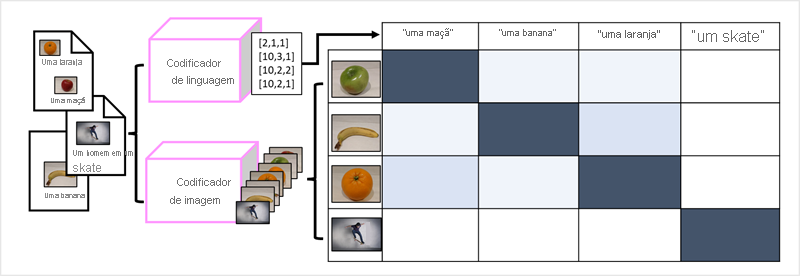
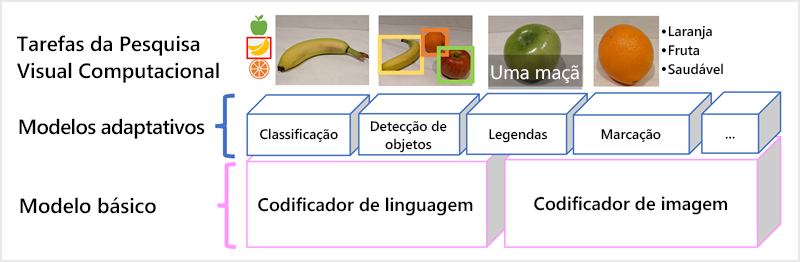
O modelo Florence da Microsoft é um exemplo desses modelos. Treinado com grandes volumes de imagens legendadas da Internet, ele inclui tanto um codificador de idioma quanto um codificador de imagem. O Florence é um exemplo de modelo base. Em outras palavras, trata-se de um modelo geral pré-treinado a partir do qual você pode criar vários modelos adaptáveis para tarefas especializadas. Por exemplo, você pode usar o Florence como um modelo base para modelos adaptáveis que executam:
- Classificação de imagens: identifica a categoria à qual uma imagem pertence.
- Detecção de Objetos: localiza objetos individuais dentro de uma imagem.
- Legendas: gera descrições apropriadas de imagens.
- Marcação: compila uma lista de marcas de texto relevantes para uma imagem.
Os modelos multimodais, como o Florence, estão na vanguarda da pesquisa visual computacional e da inteligência artificial em geral, impulsionando avanços nos tipos de solução que a IA possibilita.