Exercício – Dimensionar o desempenho da carga de trabalho
Neste exercício, você usará o problema encontrado no primeiro exercício e fará aprimoramentos no desempenho dimensionando mais CPUs para o Banco de Dados SQL do Azure. Você usará o banco de dados implantado no exercício anterior.
Você pode encontrar todos os scripts deste exercício na pasta 04-Performance\monitor_and_scale no repositório GitHub clonado ou no arquivo zip que você baixou.
Escalar verticalmente o desempenho do SQL Azure
Para dimensionar o desempenho quando parece haver um problema de capacidade de CPU, você precisa decidir quais são suas opções e, então, dimensionar as CPUs usando as interfaces fornecidas para o SQL Azure.
Decida como dimensionar o desempenho. Como a carga de trabalho é limitada pela CPU, uma forma de aprimorar o desempenho é aumentar a capacidade ou velocidade da CPU. Um usuário do SQL Server precisaria mudar para um computador diferente ou reconfigurar uma VM para obter mais capacidade de CPU. Em alguns casos, até mesmo um administrador do SQL Server pode não ter permissão para fazer essas alterações de escala. O processo pode levar tempo e até mesmo exigir uma migração de banco de dados.
No Azure, você pode usar
ALTER DATABASE, a CLI do Azure ou o portal do Azure para aumentar a capacidade da CPU sem que seja necessária uma migração de banco de dados por parte do usuário.Usando o portal do Azure, você pode ver as opções de dimensionamento para obter mais recursos de CPU. No painel Visão geral do banco de dados, selecione o tipo de preço para a implantação atual. O tipo de Preço permite que você altere a camada de serviço e o número de vCores.
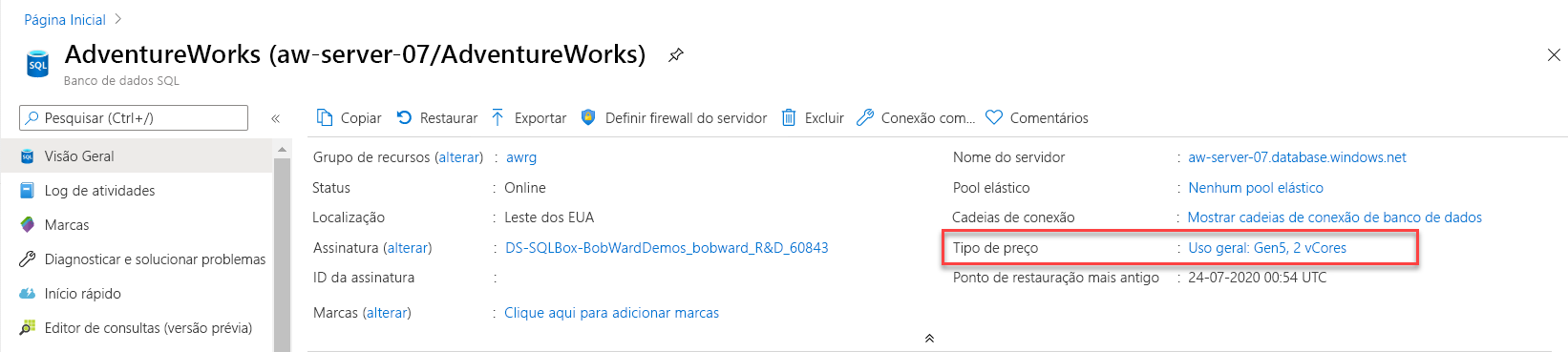
Aqui, você pode ver opções para alterar ou dimensionar recursos de computação. No Uso Geral, você pode facilmente escalar verticalmente para algo como oito vCores.
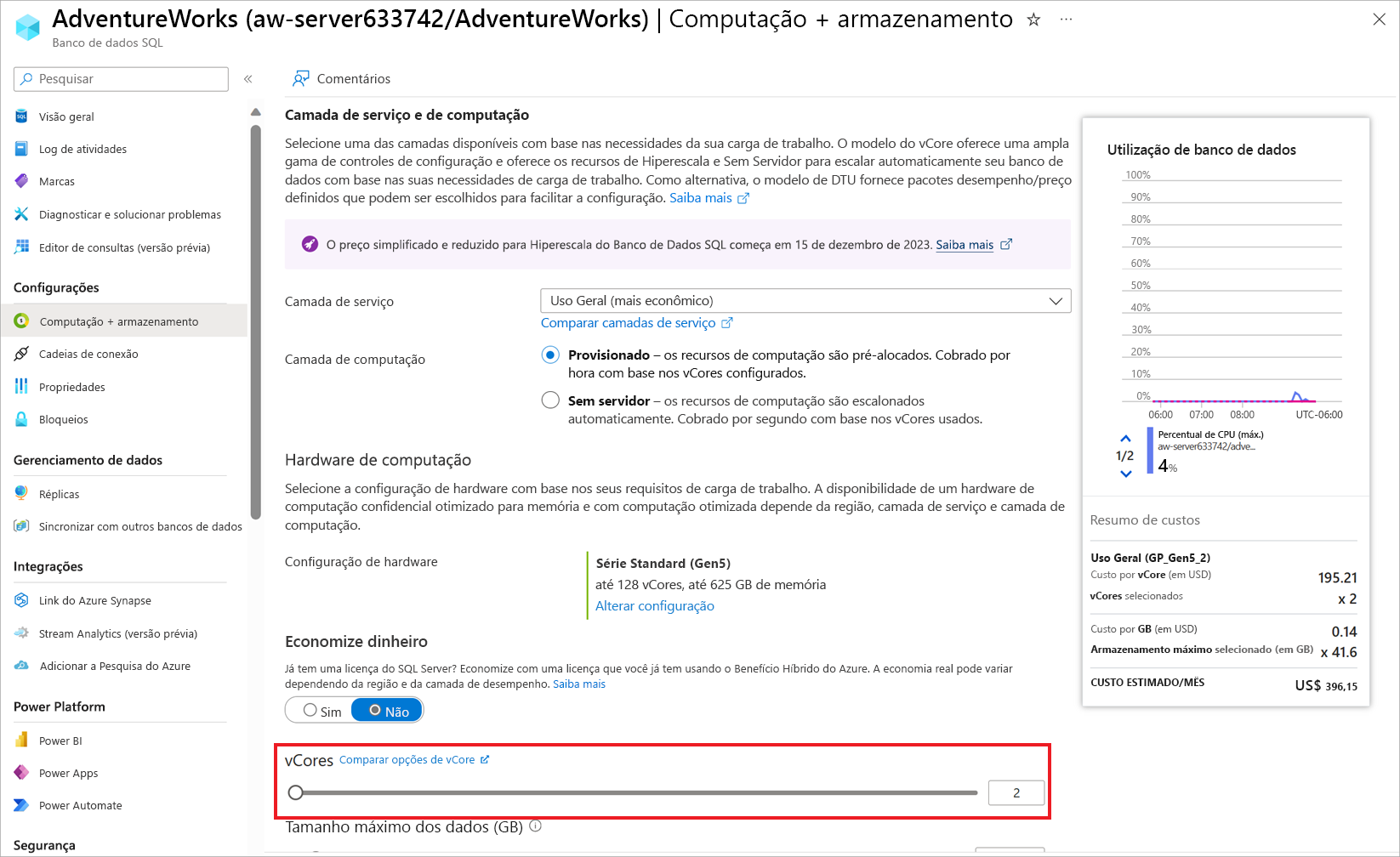
Você também pode usar um método diferente para dimensionar a carga de trabalho.
Neste exercício, para que possa ver as diferenças nos relatórios, primeiro você precisa liberar o Repositório de Consultas. No SSMS (SQL Server Management Studio), selecione o banco de dados AdventureWorks e use o menu Arquivo>Abrir>Arquivo. Abra o script flushhquerystore.sql no SSMS no contexto do banco de dados AdventureWorks. A janela do editor de consultas deverá ser semelhante ao seguinte texto:
EXEC sp_query_store_flush_db;Selecione Executar para executar este lote T-SQL.
Observação
A execução da consulta anterior libera a parte na memória dos dados do Repositório de Consultas para o disco.
Abra o script get_service_objective.sql no SSMS. A janela do editor de consultas deverá ser semelhante ao seguinte texto:
SELECT database_name,slo_name,cpu_limit,max_db_memory, max_db_max_size_in_mb, primary_max_log_rate,primary_group_max_io, volume_local_iops,volume_pfs_iops FROM sys.dm_user_db_resource_governance; GO SELECT DATABASEPROPERTYEX('AdventureWorks', 'ServiceObjective'); GOEste é um método para descobrir sua camada de serviço usando o T-SQL. O preço ou a camada de serviço também é conhecida como um objetivo de serviço. Selecione Executar para executar os lotes T-SQL.
Para a implantação atual do Banco de Dados SQL do Azure, seus resultados devem ser semelhantes à seguinte imagem:
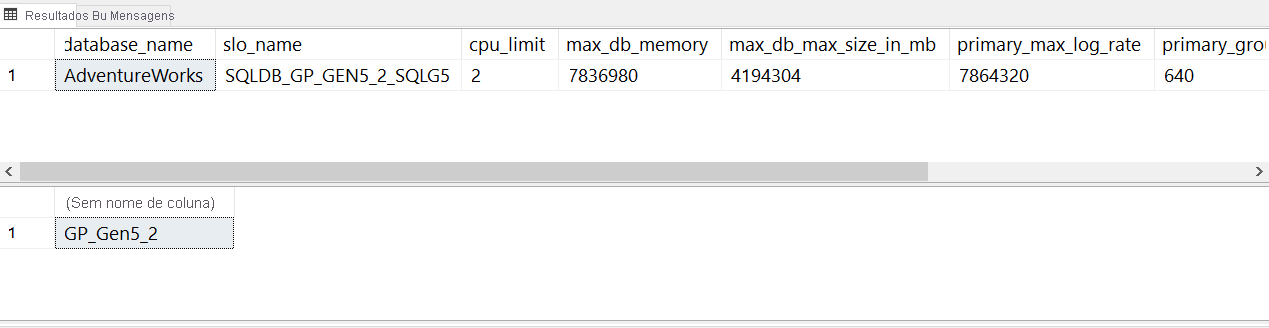
Observe que o termo slo_name também é usado para o objetivo de serviço. slo significa objetivo de nível de serviço.
Os diferentes valores de
slo_namenão estão documentados, mas você pode ver no valor da cadeia de caracteres que esse banco de dados usa uma camada de serviço de uso geral com dois vCores:Observação
SQLDB_OP_...é a cadeia de caracteres usada para a camada Comercialmente Crítico.Quando vir a documentação de ALTER DATABASE, observe a capacidade selecionar a implantação de destino do SQL Server para obter as opções de sintaxe corretas. Selecione o pool elástico/banco de dados individual do Banco de Dados SQL para ver as opções referentes ao Banco de Dados SQL do Azure. Para corresponder à escala de computação encontrada no portal, você precisa do objetivo de serviço
'GP_Gen5_8'.Modifique o objetivo de serviço para o banco de dados para dimensionar mais CPUs. Abra o script modify_service_objective.sql no SSMS e execute o lote T-SQL. A janela do editor de consultas deverá ser semelhante ao seguinte texto:
ALTER DATABASE AdventureWorks MODIFY (SERVICE_OBJECTIVE = 'GP_Gen5_8');Essa instrução retorna imediatamente, mas o dimensionamento dos recursos de computação ocorre em segundo plano. Uma escala tão pequena deve levar menos de um minuto e, por um curto período, o banco de dados fica offline para que a mudança entre em vigor. Você pode monitorar o progresso da atividade de dimensionamento usando o portal do Azure.
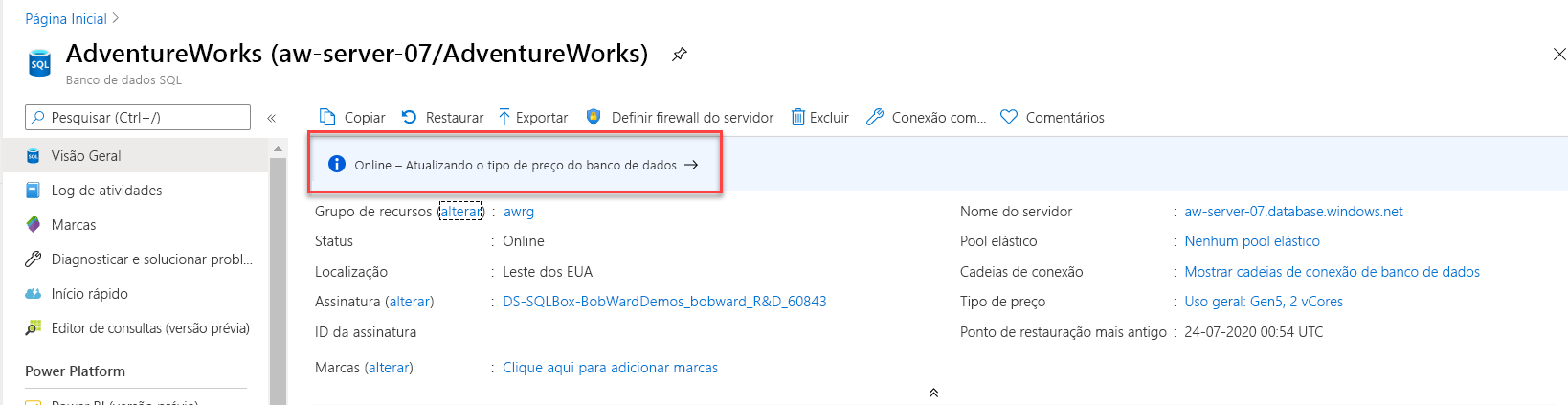
No Pesquisador de Objetos, na pasta Bancos de Dados do Sistema, clique com o botão direito do mouse no banco de dados mestre e selecione Nova Consulta. Execute esta consulta na janela do editor de consultas do SSMS:
SELECT * FROM sys.dm_operation_status;Essa é outra maneira de monitorar o progresso de uma alteração do objetivo de serviço do Banco de Dados SQL do Azure. Essa DMV (exibição de gerenciamento dinâmico) expõe um histórico das alterações no banco de dados com ALTER DATABASE para o objetivo de serviço. Ela mostra o progresso ativo da alteração.
Veja um exemplo da saída dessa DMV em um formato de tabela após você executar a instrução ALTER DATABASE anterior:
Item Valor session_activity_id 97F9474C-0334-4FC5-BFD5-337CDD1F9A21 resource_type 0 resource_type_desc Banco de dados major_resource_id AdventureWorks minor_resource_id operation ALTER DATABASE state 1 state_desc IN_PROGRESS percent_complete 0 error_code 0 error_desc error_severity 0 error_state 0 start_time [data/hora] last_modify_time [data/hora] Durante uma alteração do objetivo do serviço, as consultas são permitidas no banco de dados até que a alteração final seja implementada. Um aplicativo não pode se conectar por um curto período. Para a Instância Gerenciada de SQL do Azure, uma alteração de camada permite consultas e conexões, mas impede todas as operações de banco de dados, como sua criação. Nesses casos, você receberá a seguinte mensagem de erro: "A operação não pôde ser concluída porque a uma alteração da camada de serviço está em andamento para a instância gerenciada '[servidor]'. Aguarde a conclusão da operação em andamento e tente novamente."
Quando isso ocorrer, use as consultas anteriores listadas em get_service_objective.sql no SSMS para verificar se o novo objetivo de serviço ou a camada de serviço de oito vCores entrou em vigor.
Executar a carga de trabalho após escalar verticalmente
Agora que o banco de dados tem mais capacidade de CPU, vamos executar a carga de trabalho que executamos no exercício anterior para observar se há algum aprimoramento no desempenho.
Agora que o dimensionamento foi concluído, verifique se a duração da carga de trabalho está mais rápida e se as esperas por recursos da CPU foram reduzidas. Execute a carga de trabalho novamente usando o comando sqlworkload.cmd executado no exercício anterior.
Usando o SSMS, execute a mesma consulta do primeiro exercício deste módulo para observar os resultados do script dmdbresourcestats.sql:
SELECT * FROM sys.dm_db_resource_stats;Você deverá ver que a média de uso dos recursos de CPU diminuíram com relação ao uso de quase 100% do exercício anterior. Normalmente,
sys.dm_db_resource_statsexibe uma hora de atividade. Redimensionar o banco de dados faz com quesys.dm_db_resource_statsele seja redefinido.Usando o SSMS, execute a mesma consulta do primeiro exercício deste módulo para observar os resultados do script dmexecrequests.sql.
SELECT er.session_id, er.status, er.command, er.wait_type, er.last_wait_type, er.wait_resource, er.wait_time FROM sys.dm_exec_requests er INNER JOIN sys.dm_exec_sessions es ON er.session_id = es.session_id AND es.is_user_process = 1;Você verá que há mais consultas com o status EXECUTANDO. Isso significa que nossos trabalhos têm mais capacidade de CPU para serem executados.
Observe a nova duração da carga de trabalho. A duração da carga de trabalho de sqlworkload.cmd agora deve ser muito menor, de aproximadamente 25 a 30 segundos.
Observar os relatórios do Repositório de Consultas
Vamos examinar os mesmos relatórios do Repositório de Consultas que vimos no exercício anterior.
Usando as mesmas técnicas do primeiro exercício do módulo, examine o relatório Principais Consultas de Consumo de Recursos do SSMS:
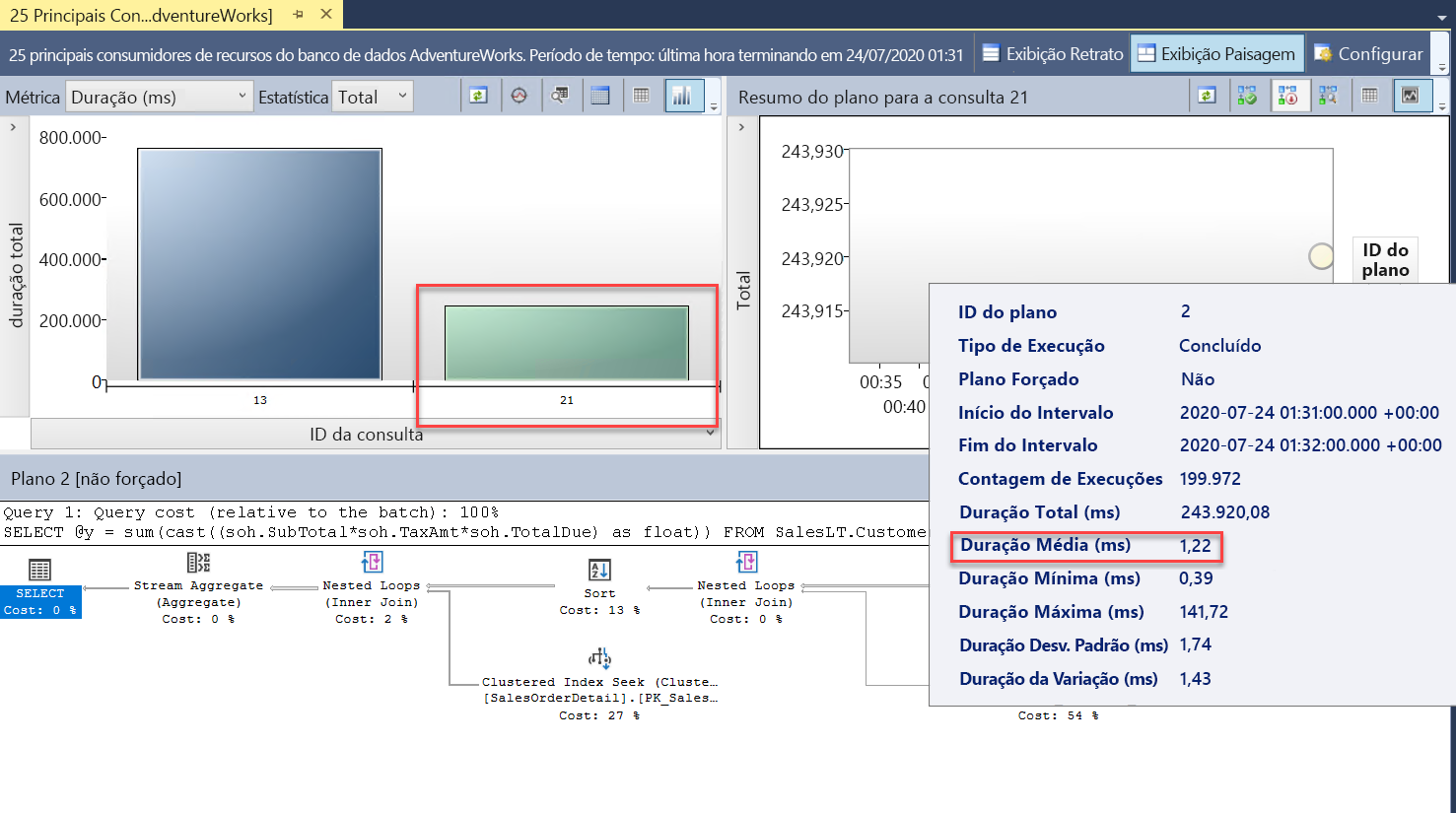
Agora, você verá duas consultas (
query_id). Elas são a mesma consulta, mas aparecem com valores dequery_iddiferentes no Repositório de Consultas porque a operação de escala exigiu uma reinicialização e a consulta precisou ser recompilada. Você pode ver no relatório que a duração geral e a duração média foram significativamente menores.Examine também o relatório Estatísticas de Espera de Consulta e selecione a barra de espera da CPU. Você pode ver que o tempo de espera médio geral da consulta é menor e representa um percentual menor da duração geral. Essa é uma boa indicação de que a CPU não é um gargalo de recursos tão significativo como quando o banco de dados tinha um número menor de vCores:
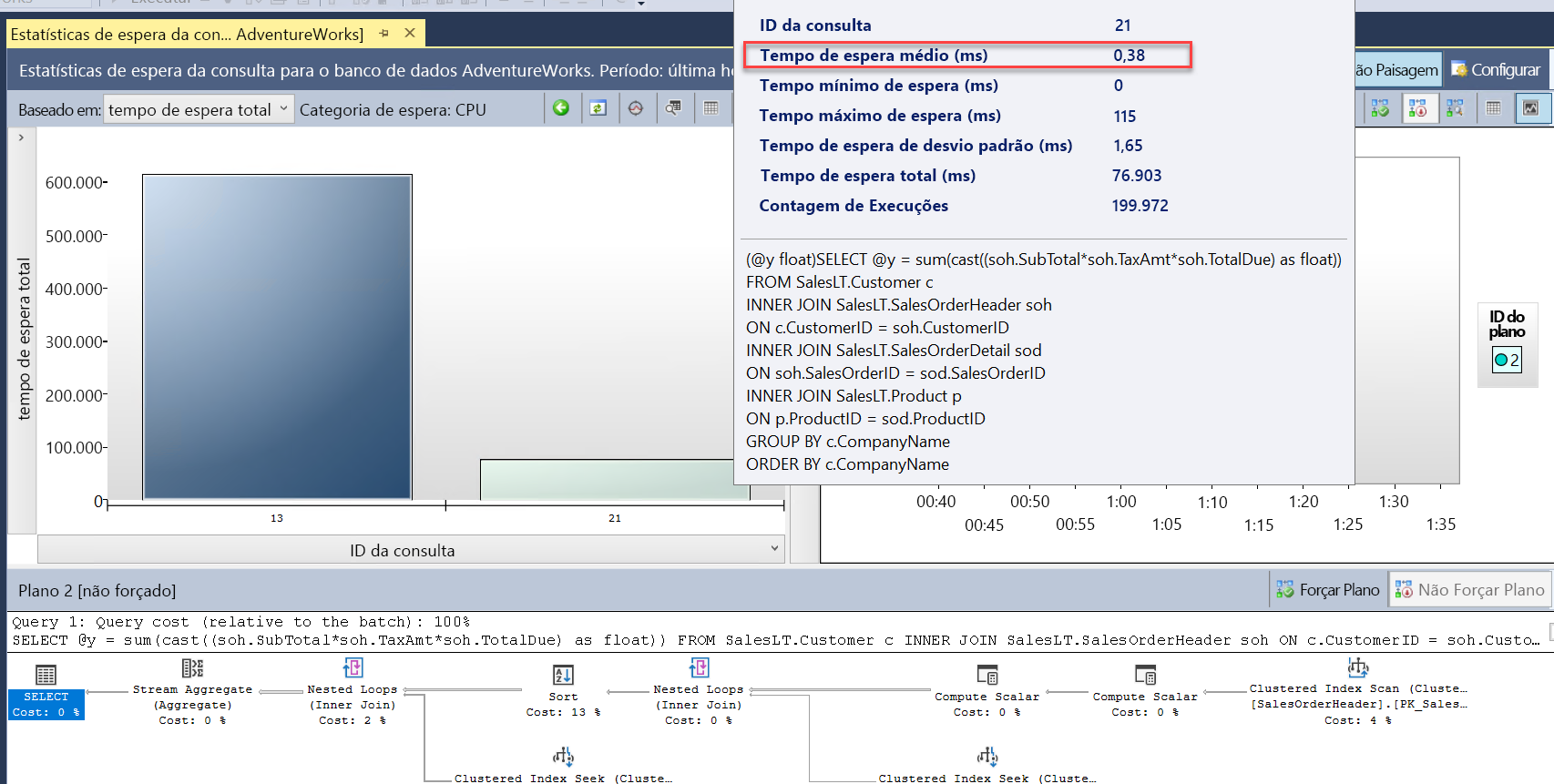
Você pode fechar todos os relatórios e janelas do editor de consultas. Deixe o SSMS conectado, pois você precisará dele no próximo exercício.
Observar alterações nas Métricas do Azure
Vá até o banco de dados AdventureWorks no portal do Azure e examine a guia Monitoramento no painel Visão Geralnovamente para ver a Utilização de Computação:
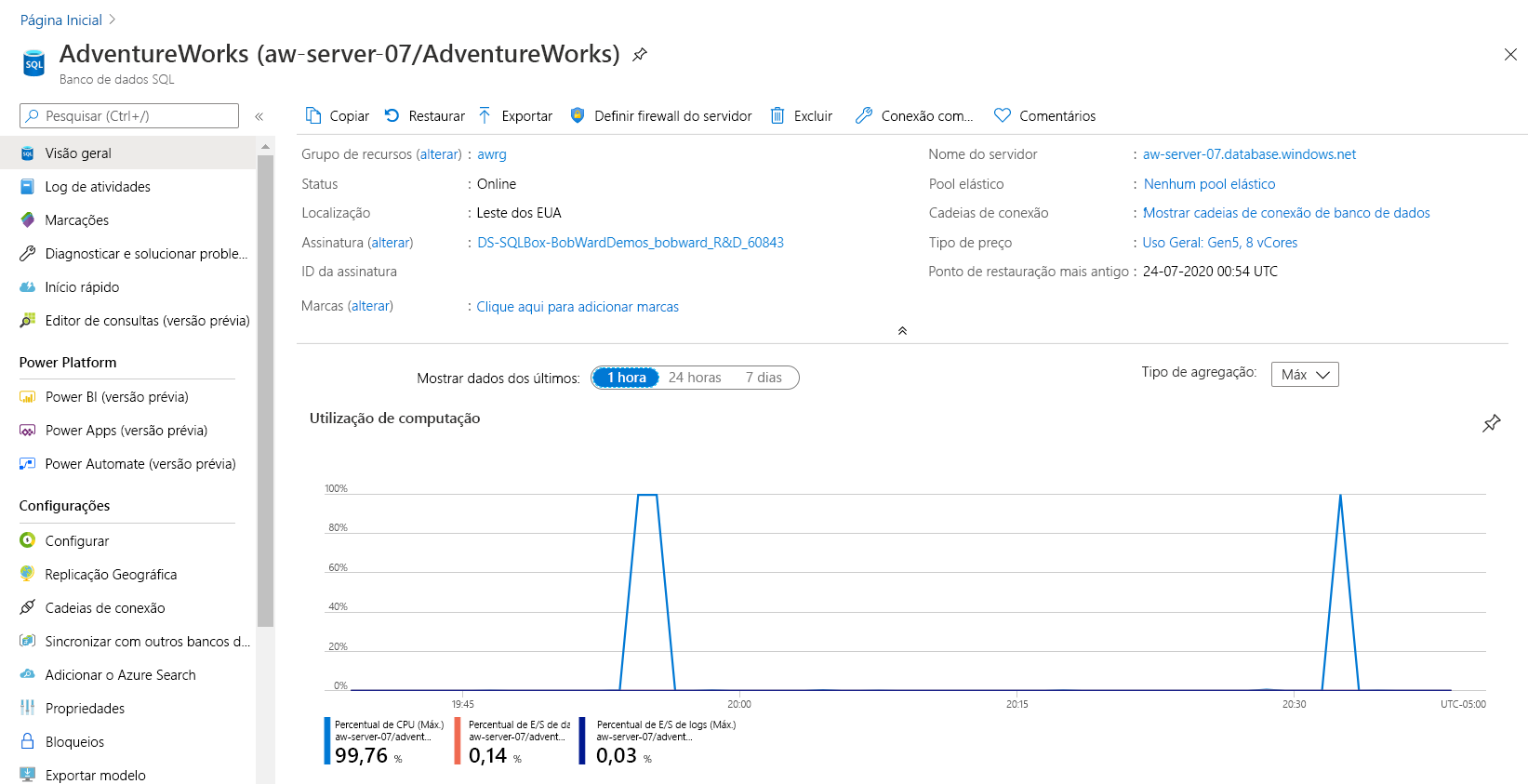
Observe que a duração referente à alta utilização da CPU é menor, o que indica uma queda geral nos recursos de CPU necessários para executar a carga de trabalho.
Esse gráfico pode ser um pouco enganoso. No menu Monitoramento, use Métricase defina a Métrica como limite de CPU. O gráfico de comparação de CPU é mais parecido com o seguinte:
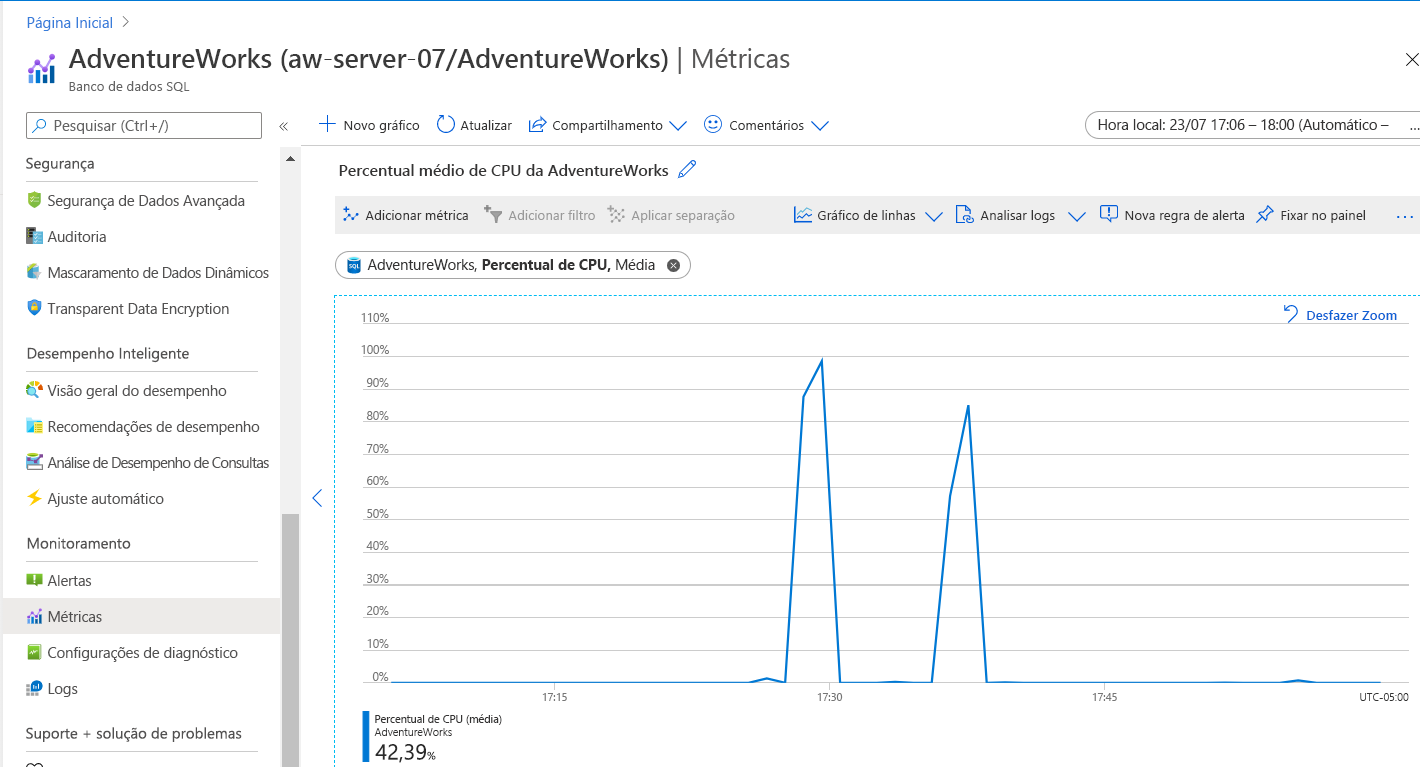
Dica
Se continuar aumentando os vCores desse banco de dados, você poderá aprimorar o desempenho até um limite em que todas as consultas tenham muitos recursos de CPU. Isso não significa que você precisa que o número de vCores corresponda ao número de usuários simultâneos de sua carga de trabalho. Além disso, você pode alterar o Tipo de preço para usar a Camada de computação Sem servidor em vez da Provisionada. Isso ajuda a ter uma abordagem com "dimensionamento mais automático" à carga de trabalho. Por exemplo, para essa carga de trabalho, se você escolher um valor mínimo de dois e um valor máximo de oito vCores, essa carga de trabalho será dimensionada imediatamente para oito vCores.
No próximo exercício, você observará um problema de desempenho e o resolverá aplicando as melhores práticas de desempenho do aplicativo.