Antes da nuvem
Agora que definimos o que é a computação em nuvem, vamos examinar exemplos de como a computação foi utilizada em domínios diferentes, como computação comercial, computação científica e computação pessoal antes do surgimento da computação em nuvem.
Computação comercial: a computação comercial frequentemente envolve o uso de sistemas de informações de gerenciamento que impulsionam a logística e as operações, o ERP (planejamento de recursos empresariais), o CRM (gerenciamento de relacionamento com o cliente), a produtividade do Office e o BI (business intelligence). Essas ferramentas permitiam processos mais simplificados que levaram à uma produtividade aprimorada e ao custo reduzido em diversas empresas.
Por exemplo, o software CRM permite que as empresas coletem, armazenem, gerenciem e interpretem uma variedade de dados sobre clientes anteriores, atuais e potenciais futuros. O software CRM oferece uma visão integrada (em tempo real ou quase em tempo real) de todas as interações organizacionais com os clientes. Para uma empresa de manufatura, o software CRM pode ser usado por uma equipe de vendas para agendar reuniões, tarefas e acompanhamentos com clientes. Uma equipe de marketing pode direcionar clientes com campanhas com base em padrões específicos. As equipes de cobrança podem acompanhar cotações e faturas. Como tal, é um repositório centralizado para armazenar essas informações. Para habilitar essa funcionalidade, uma variedade de tecnologias de hardware e software são utilizados pela organização e pelas equipes de vendas para coletar os dados que precisam ser armazenados e analisados usando vários sistemas de banco de dados e de análise.
Computação científica: a computação científica usa modelos matemáticos e técnicas de análise implementadas em computadores para tentar resolver problemas científicos. Um exemplo popular é a simulação de computador de fenômenos físicos, por exemplo, usando modelos climáticos para prever o clima. Esse campo interrompeu o uso de métodos tradicionais teóricos e experimentais laboratoriais, o que permitiu que cientistas e engenheiros reconstruíssem eventos conhecidos ou previssem situações futuras desenvolvendo programas para simular e estudar diferentes sistemas em diferentes circunstâncias. Essas simulações normalmente exigem um número muito grande de cálculos, que geralmente são executados em supercomputadores caros ou plataformas de computação distribuídas.
Computação pessoal: na computação pessoal, um usuário executa vários aplicativos em um computador pessoal de uso geral (PC). Exemplos desses aplicativos incluem processadores de texto e outros softwares de produtividade do escritório, aplicativos de comunicação como clientes de email e software de entretenimento, como videogames e players de mídia. Um usuário de computador normalmente possui, instala e mantém o software e o hardware utilizados para realizar essas tarefas.
Escala de endereçamento
Um dos desafios permanentes em TI é o dimensionamento dos recursos de computação para atender à demanda, por exemplo, para aumentar a capacidade de um site para atender às necessidades de uma base de clientes cada vez maior ou para lidar com cargas de "intermitência" durante o horário comercial de pico ou eventos especiais que atraem um público enorme.
Aumentar a escala na computação tem sido um processo contínuo, seja aumentando o número de clientes e eventos para capturar, monitorar e analisar no CRM ou aumentar a precisão de simulações numéricas na computação científica ou o realismo nos aplicativos de videogames. Além disso, a necessidade de uma escala maior foi impulsionada pelo aumento da adoção de tecnologia por vários domínios ou pela expansão de negócios e mercados, bem como pelo aumento contínuo no número de usuários e suas necessidades. As organizações devem considerar o aumento na escala à medida que planejam e preparam o orçamento da implantação de suas soluções.
As organizações normalmente planejam sua infraestrutura de TI em um processo chamado planejamento de capacidade. Durante o processo de planejamento de capacidade, o crescimento no uso de vários serviços de TI é avaliado e usado como um parâmetro de comparação para a expansão futura. As organizações precisam planejar com antecedência a aquisição, a configuração e a manutenção de servidores, dispositivos de armazenamento e equipamentos de rede mais recentes e melhores. Às vezes, as organizações estão limitadas por software, pois elas podem ter adquirido um conjunto limitado de licenças e pode ser necessário mais para expandir a infraestrutura para cobrir um conjunto maior de usuários.
A forma mais básica de dimensionamento é conhecida como dimensionamento vertical, no qual os sistemas antigos são substituídos por sistemas mais recentes com melhor desempenho, com CPUs mais rápidas e mais espaço em disco e memória. Em muitos casos, o dimensionamento vertical consiste em atualizar ou substituir servidores e adicionar capacidade às matrizes de armazenamento. Esse processo pode levar meses para ser planejado e executado e, muitas vezes, requer breves períodos de inatividade à medida que as atualizações são implantadas.
O dimensionamento também pode ser feito horizontalmente aumentando ou diminuindo o número de recursos dedicados ao sistema. Um exemplo disso é a computação de alto desempenho, na qual servidores e capacidade de armazenamento adicionais podem ser adicionados aos clusters existentes, aumentando assim o número de cálculos que podem ser executados por segundo. Outro exemplo envolve os Web farms, clusters de servidores que hospedam sites e aplicativos Web, em que servidores adicionais podem ser colocados online para lidar com o aumento de tráfego. Assim como o dimensionamento vertical, esse processo pode levar meses para ser planejado e executado, com a possibilidade de tempos de inatividade.
Como as empresas possuíam e mantinham seus equipamentos de TI, à medida que o custo da escala de endereçamento continuava aumentando, as empresas identificaram outros métodos para reduzir os custos. As grandes empresas consolidaram as necessidades de computação de diferentes departamentos em um único grande data center no qual eles consolidaram imóveis, energia, resfriamento e rede para reduzir o custo. Por outro lado, as empresas de pequeno e médio porte podiam arrendar o imóvel, rede, energia, resfriamento e segurança física colocando seus equipamentos de TI em um data center compartilhado. Isso é normalmente chamado de serviço de colocalização que foi adotado por empresas de pequeno a médio porte que não desejavam criar seus próprios data centers internamente. Os serviços de colocalização continuam a ser adotados em vários domínios como uma abordagem econômica para reduzir as despesas operacionais.
A computação comercial abordou a escala por meio do dimensionamento vertical e horizontal, bem como a consolidação de recursos de TI para data centers e colocalização. Na computação científica, sistemas paralelos e distribuídos foram adotados para aumentar o tamanho dos problemas e a precisão de suas simulações numéricas. Uma definição de processamento paralelo é o uso de vários computadores homogêneos que compartilham estado e função como um único computador grande para executar cálculos de grande escala ou de alta precisão. A computação distribuída é o uso de vários sistemas de computação autônomos conectados por uma rede para particionar um grande problema em subtarefas que são executadas simultaneamente e se comunicam via mensagens pela rede. A comunidade científica continuou a inovar nesses domínios para lidar com o dimensionamento. Na computação pessoal, o dimensionamento teve um impacto devido ao aumento das demandas provocadas por conteúdo mais rico e aplicativos que exigem muita memória. Os usuários substituem seus PCs por modelos mais novos e mais rápidos ou atualizam os modelos existentes para acompanhar essas demandas.
Aumento dos serviços de Internet
O fim da década de 1990 marcou um aumento constante na adoção desses aplicativos e plataformas de computação entre domínios. Logo, era esperado que o software não fosse apenas funcional, mas também capaz de produzir valor e insight para os requisitos comerciais e pessoais. O uso desses aplicativos tornou-se colaborativo; os aplicativos foram misturados e combinados para fornecer informações entre si. O TI não era mais apenas um centro de custo de uma empresa, mas uma fonte de inovação e eficiência.
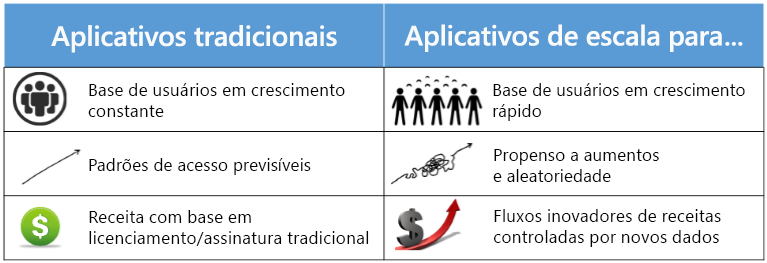
Figura 1.2: comparação entre a computação tradicional e dimensionada na Internet.
O século XXI foi marcado por uma explosão no volume e na capacidade de comunicações sem fio, na World Wide Web e na Internet. Essas alterações levaram a uma sociedade orientada para dados e rede, onde a produção, a disseminação e o acesso às informações digitalizadas são simplificadas. A Internet criou um mercado global com mais de 4 bilhões de usuários. Esse aumento nos dados e conexões é valioso para as empresas. Os dados criam valor de várias maneiras, inclusive permitindo a experimentação, segmentando populações e apoiando a tomada de decisões com automação1. Ao adotar tecnologias digitais, espera-se que as 10 principais economias do mundo aumentem sua produção em mais de um trilhão de dólares entre 2015 e 2020.
O número crescente de conexões habilitadas pela Internet também impulsionou seu valor. Os pesquisadores levantaram a hipótese de que o valor de uma rede varia de forma muito linear como uma função do número de usuários. Assim, na escala da Internet, conquistar e reter os clientes é uma prioridade, e isso é feito com a criação de serviços confiáveis e responsivos, e a realização de alterações com base nos padrões de dados observados.
Alguns exemplos de sistemas de dimensionamento da Internet incluem:
- Mecanismos de pesquisa que rastreiam, armazenam, indexam e pesquisam grandes conjuntos de dados (cujo tamanho chega a petabytes). Por exemplo, o Google começou como um gigantesco índice da Web que rastreava e analisava o tráfego da Web uma vez a cada poucos dias e correspondia esses índices às palavras-chave. Agora ele atualiza seus índices em tempo quase real e é uma das maneiras mais populares de acessar informações na Internet. Seu índice tem trilhões de páginas com um tamanho de milhares de terabytes3.
- Redes sociais, como o Facebook e o LinkedIn, que permitem aos usuários criar relações pessoais e profissionais e construir comunidades com base em interesses semelhantes. O Facebook, por exemplo, agora tem mais de 2 bilhões de usuários ativos por mês.
- Os serviços de varejo online, como a Amazon, mantêm um estoque de milhões de produtos e atendem a uma base de usuários global. Em 2017, as operações online de varejo da Amazon atingiram vendas líquidas de US$ 178 bilhões, alta 31% em relação ao ano anterior.
- Aplicativos multimídia avançados de streaming permitem que as pessoas assistam e compartilhem vídeos e outras formas de conteúdo avançado. Um exemplo, o YouTube, veicula cinco bilhões de vídeos por dia e recebe 300 minutos de vídeo a cada segundo.
- Sistemas de comunicação em tempo real para áudio, vídeo e bate-papo de texto, como o Skype, que registra mais de 50 bilhões de minutos de chamadas por mês.
- Pacotes de produtividade e colaboração que servem milhões de documentos a muitos usuários simultâneos, permitindo atualizações persistentes em tempo real. Por exemplo, o Microsoft 365 atende a cerca de 60 milhões usuários ativos por mês.
- Aplicativos de CRM de provedores como o SalesForce são implantados em mais de cem mil organizações. Agora os grandes CRMs fornecem painéis intuitivos para acompanhar status, análises para encontrar clientes que geram mais previsões de negócios e previsões de receita para o crescimento futuro.
- Aplicativos de mineração de dados e business intelligence que analisam o uso de outros serviços (como aqueles acima) para encontrar ineficiências e oportunidades para monetização.
Obviamente, esses sistemas devem lidar com um alto volume de usuários simultâneos. Isso requer uma infraestrutura com capacidade para lidar com grandes quantidades de tráfego de rede, gerar e armazenar dados com segurança, tudo sem atrasos perceptíveis. Esses serviços obtêm seu valor, fornecendo um padrão de qualidade constante e confiável. Eles também fornecem interfaces de usuário avançadas para dispositivos móveis e navegadores da Web, tornando-os fáceis de usar, mas mais difíceis de criar e manter.
Resumimos aqui alguns dos requisitos dos sistemas de escala da Internet:
- Onipresença – ser acessível de qualquer lugar a qualquer momento, de uma variedade de dispositivos. Por exemplo, um vendedor espera que o serviço CRM forneça atualizações oportunas em um dispositivo móvel para tornar as visitas aos clientes mais curtas, rápidas e eficientes. O serviço deve funcionar sem problemas em várias conexões de rede.
- Alta disponibilidade -- o serviço deve estar "sempre ativo". Os tempos de atividade são medidos em termos de número de noves. Três noves, ou 99,9%, implicam que um serviço ficará indisponível durante 9 horas por ano. Cinco noves (cerca de 6 minutos por ano) é um limite típico para um serviço de alta disponibilidade. Mesmo alguns minutos de inatividade em aplicativos de varejo online podem afetar milhões de dólares de vendas.
- Baixa latência – tempos de acesso rápidos e responsivos. Foi demonstrado que tempos de carregamento de página um pouco mais lentos reduzem significativamente o uso da página da web afetada. Por exemplo, aumentar a latência de pesquisa de 100 milissegundos para 400 milissegundos diminui o número de pesquisas por usuário de 0,8% para 0,6% e a alteração persiste mesmo após a latência ser restaurada aos níveis originais.
- Escalabilidade – a capacidade de lidar com cargas variáveis resultantes de sazonalidade e viralidade, o que causa picos e ciclos no tráfego por longos e curtos períodos de tempo. Em dias como "Black Friday" e "Cyber Monday", varejistas como Amazon e Walmart recebem um tráfego de rede várias vezes maior do que em média.
- Economia de custos – um serviço de escala da Internet requer uma infraestrutura significativamente maior do que um aplicativo tradicional, bem como melhor gerenciamento[4]. Uma maneira de simplificar os custos é facilitando o gerenciamento dos serviços e reduzindo o número de administradores que lidam com um serviço. Os serviços menores podem ter uma baixa taxa de serviço para administrador (por exemplo, 2:1, o que significa que um único administrador deve manter dois serviços). No entanto, para manter a lucratividade, os serviços como o Microsoft Bing devem ter alta taxa de serviço para administrador (por exemplo, 2500:1, o que significa que um único administrador mantém os 2.500 serviços).
- Interoperabilidade – muitos desses serviços são frequentemente usados juntos e, portanto, devem fornecer uma interface fácil para reutilizar e oferecer suporte a mecanismos padronizados para importação e exportação de dados. Por exemplo, serviços como o Uber podem integrar o Google Maps em seus produtos para fornecer informações simplificadas de local e navegação aos usuários.
Agora vamos explorar algumas das primeiras soluções para os vários problemas acima. O primeiro desafio a ser resolvido foi o grande tempo de ida e volta dos primeiros serviços Web, localizados principalmente nos Estados Unidos. Os primeiros mecanismos para lidar com os problemas de baixa latência (devido a servidores distantes) e falha do servidor simplesmente dependiam da redundância. Uma técnica para alcançar isso era o "espelhamento" de conteúdo, no qual cópias de páginas populares da Web eram armazenadas em locais diferentes em todo o mundo. Isso minimizava a quantidade de carga no servidor central, reduzia a latência dos usuários finais e permitia que o tráfego fosse alternado para outro servidor em caso de falhas. A desvantagem era um aumento na complexidade para lidar com inconsistências, se apenas uma cópia dos dados fosse modificada. Portanto, essa técnica é mais útil para cargas de trabalho estáticas e de leitura pesada, como a manutenção de imagens, vídeos ou músicas. Devido à eficácia dessa técnica, a maioria dos serviços de escala da Internet usa CDNs (redes de entrega de conteúdo) para armazenar caches globais distribuídos de conteúdo popular. Por exemplo, a CNN (Cable News Network) agora mantém réplicas de seus vídeos em vários servidores de "borda" em diferentes locais em todo o mundo, com publicidade personalizada por local.
É claro que nem sempre fazia sentido para empresas individuais comprarem dezenas de servidores em todo o mundo. As reduções de custos geralmente eram obtidas usando serviços de hospedagem compartilhados. Aqui, os compartilhamentos de um único servidor Web eram arrendados a vários locatários, amortizando o custo da manutenção do servidor. Os serviços de hospedagem compartilhados podem ser altamente eficientes em termos de recursos, pois os mesmos podem ser excessivamente provisionados sob a suposição de que nem todos os serviços seriam operados na capacidade máxima ao mesmo tempo. (Um servidor físico excessivamente provisionado é aquele em que a capacidade de agregação de todos os locatários é maior do que a capacidade real do servidor). A desvantagem foi que era quase impossível isolar os serviços dos locatários dos de seus vizinhos. Assim, um único serviço sobrecarregado ou propenso a erros poderia afetar negativamente todos os seus vizinhos. Outro problema surgiu porque os locatários podiam estar mal-intencionados e tentar aproveitar essa vantagem de colocalização para roubar dados ou negar serviço a outros usuários.
Para combater isso, servidores privados virtuais foram desenvolvidos como variantes do modelo de hospedagem compartilhado. Era fornecido a um locatário uma VM (máquina virtual) em um servidor compartilhado. Essas VMs geralmente eram alocadas estaticamente e vinculadas a uma única máquina física, o que significava que elas eram difíceis de dimensionar e, muitas vezes, precisavam de recuperação manual para qualquer falha. Embora não pudessem mais ser excessivamente provisionados, elas tinham melhor desempenho e isolamento de segurança entre os serviços colocalizados do que no compartilhamento simples de recursos.
Outro problema de compartilhar recursos públicos era que isso exigia o armazenamento de dados privados em uma infraestrutura de terceiros. Alguns dos serviços de escala da Internet descritos acima não podiam perder o controle do armazenamento de dados, já que qualquer divulgação dos dados confidenciais de clientes teria consequências desastrosas. Portanto, essas empresas precisavam criar sua própria infraestrutura global. Antes do advento da nuvem pública, esses serviços só podiam ser implantados por grandes corporações, como Google e Amazon. Cada uma dessas empresas criava grandes data centers homogêneos em todo o mundo usando componentes prontos para uso, nos quais um data center poderia ser considerado um WSC (computador de escala de warehouse) gigante e único. Um WSC forneceu uma abstração fácil para distribuir globalmente aplicativos e dados, mantendo a propriedade.
Devido à economia de escala, a utilização de um data center pode ser otimizada para reduzir os custos. Embora isso ainda não seja tão eficiente quanto o compartilhamento de recursos publicamente (a nuvem), esses computadores de escala de warehouse tinham muitas propriedades desejáveis que serviram como bases para a criação de serviços de escala da Internet. A escala dos aplicativos de computação progrediu do atendimento de uma base de usuários fixa para uma população global dinâmica. Os WSCs padronizados permitiram que grandes empresas atendessem a grandes públicos. Uma infraestrutura ideal combinaria o desempenho e a confiabilidade de um WSC com o modelo de hospedagem de compartilhamento. Isso permitiria que até mesmo uma pequena empresa desenvolvesse e iniciasse um aplicativo competitivo globalmente, sem a alta sobrecarga de criar grandes data centers.
Outra abordagem para compartilhar recursos era a computação em grade, que habilitaria o compartilhamento de sistemas de computação autônomos entre instituições e locais geográficos. Várias instituições acadêmicas e científicas colaborariam e agrupariam seus recursos na busca de uma meta comum. Cada instituição seria então unida a uma "organização virtual", dedicando um conjunto específico de recursos por meio de regras de compartilhamento bem definidas. Os recursos geralmente seriam heterogêneos e acoplados livremente, exigindo construções de programação complexas para uni-los. As grades foram voltadas para dar suporte a projetos acadêmicos e de pesquisa não comercial e basearam-se em tecnologias de software livre existentes.
A nuvem foi um sucessor lógico que combinava muitos dos recursos das soluções acima. Por exemplo, em vez de as universidades contribuírem e compartilharem o acesso a um conjunto de recursos usando uma grade, a nuvem permite que eles arrendem a infraestrutura de computação que é administrada centralmente por um provedor de serviços de nuvem. Como o provedor central manteve um grande conjunto de recursos para atender a todos os clientes, a nuvem facilitou o processo de escalar e reduzir dinamicamente em função da demanda em um curto período de tempo. No entanto, em vez de padrões abertos como a grade, a computação em nuvem depende de protocolos proprietários e exige que o usuário coloque um certo nível de confiança no CSP.
Referências
- IBM (2017). What is big data?https://www.ibm.com/analytics/hadoop/big-data-analytics
- Google Inc. (2015). How Search Works. https://www.google.com/insidesearch/howsearchworks/thestory/
- Hamilton, James R e outros (2007). On Designing and Deploying Internet-Scale Services