A evolução da computação em nuvem
- 12 minutos
O conceito de computação em nuvem apareceu pela primeira vez durante o início da década de 1950, quando vários acadêmicos, incluindo Herb Grosch, John McCarthy e Douglas Parkhill[1], vislumbraram a computação como uma utilidade semelhante à energia elétrica. Nas décadas seguintes, várias tecnologias emergentes estabeleceram as bases para a criação da computação em nuvem (Figura 1.3). Mais recentemente, o rápido crescimento da World Wide Web e o surgimento de grandes gigantes da Internet, como Microsoft, Google e Amazon, finalmente levaram à criação de um ambiente econômico e comercial que permitiu o florescimento do modelo de computação em nuvem.
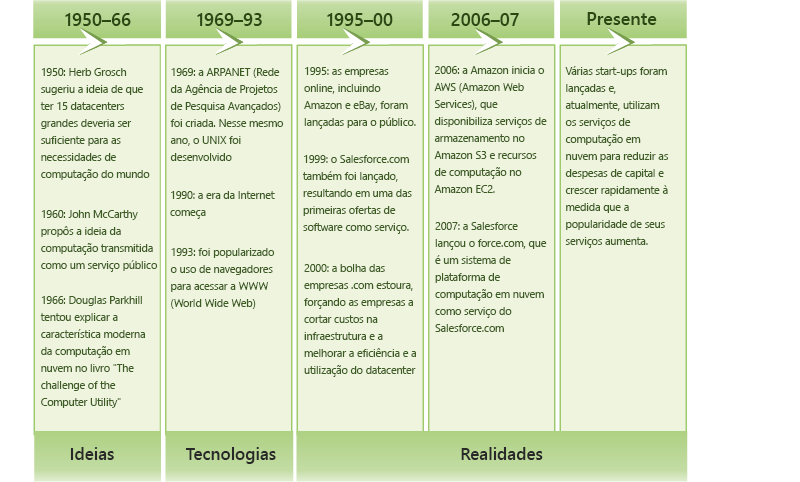
Figura 1.3: Evolução da computação em nuvem.
Evolução da computação
Desde a década de 1960, alguns dos primeiros modelos computacionais usados pelas organizações eram os computadores mainframe. Vários usuários podiam compartilhar e se conectar a mainframes por meio de conexões seriais básicas usando terminais. O mainframe era responsável por toda a lógica, armazenamento e processamento de dados, e os terminais conectados a eles tinham pouca ou nenhuma potência computacional. Esses sistemas continuaram a ter seu uso difundido por mais de 30 anos e, em certa medida, continuam a existir até hoje.
Com o surgimento dos computadores pessoais e de processadores e memória menores, mais baratos e mais potentes, a computação oscilou na direção oposta, na qual os usuários passaram a executar os próprios programas de software e armazenar os dados localmente. Esse cenário, por sua vez, gerou problemas de compartilhamento de dados e relacionados à falta de regras eficazes para manter a ordem no ambiente de TI de uma organização.
Por meio do desenvolvimento de tecnologias de rede de alta velocidade, as LANs (redes locais) foram sendo gradualmente adotadas, permitindo a conexão e a comunicação entre computadores. Os fornecedores passaram a criar sistemas que abrangessem os benefícios dos computadores pessoais e dos mainframes, resultando em aplicativos cliente-servidor que se tornaram populares com as LANs. Os clientes costumavam executar o software cliente (e processar alguns dados) ou um terminal (para aplicativos herdados) que estivesse conectado a um servidor. O servidor, no modelo cliente-servidor, fornecia lógica de dados, de armazenamento e de aplicativo.
Eventualmente, na década de 1990, a Internet passa a ser rapidamente adotada, introduzindo a era da informação global. A largura de banda da rede foi aprimorada de uma maneira sem precedentes, passando do acesso discado comum à conectividade de fibra dedicada que temos atualmente. Além disso, os hardwares passaram a ser mais baratos e mais potentes. A World Wide Web e sites dinâmicos evoluíram tanto que passaram a exigir arquiteturas de várias camadas.
Essas arquiteturas de várias camadas, por sua vez, permitiram a modularização do software, separando as camadas de apresentação, lógica e armazenamento do aplicativo como entidades individuais. Com essa modularização e dissociação, não demorou muito para que entidades de software individuais passassem a ser executadas em servidores físicos distintos (geralmente devido a diferenças nos requisitos de hardware e software). Isso levou a um aumento dos servidores individuais nas organizações. Mas também levou à baixa utilização média de hardware de servidor. Em 2009, a International Data Corporation (IDC) estimou que o servidor x86 médio tinha uma taxa de utilização de aproximadamente 5 a 10%[2].
Nos anos 2000, a tecnologia de máquinas virtuais amadureceu e passou a ser disponibilizada como software comercial. A virtualização permite que um servidor inteiro seja encapsulado em uma imagem, que pode ser executada perfeitamente no hardware e permite que vários servidores virtuais sejam executados simultaneamente em um único servidor físico e compartilhem recursos de hardware. Desse modo, a virtualização permite que os servidores sejam consolidados, o que melhora a utilização do sistema.
Simultaneamente, a computação em grade ganhou força na comunidade científica, em um esforço para resolver problemas em grande escala de maneira distribuída. Com a computação em grade, os recursos computacionais de vários domínios administrativos passaram a trabalhar em conjunto para atingir um objetivo em comum. A computação em grade apresentou muitas ferramentas de gerenciamento de recursos (por exemplo, agendadores e balanceadores de carga) para gerenciar funcionalidades computacionais em grande escala.
À medida que as várias tecnologias de computação evoluíam, isso também ocorria com a economia da computação. Durante os primórdios da computação baseada em mainframe, empresas como a IBM já ofereciam serviços de execução e hospedagem de computadores e softwares para várias organizações, como bancos e companhias aéreas. Na era da Internet, a hospedagem na Web de terceiros também passou a ser bastante popular. Com a virtualização, no entanto, os provedores têm uma flexibilidade incomparável para acomodar vários clientes em um único servidor, compartilhando hardware e recursos entre eles.
O desenvolvimento dessas tecnologias, juntamente com o modelo econômico da computação utilitária, acabou evoluindo para a computação em nuvem.
Tecnologias de capacitação
A computação em nuvem possui várias tecnologias de capacitação (Figura 1.4), que incluem redes, virtualização e gerenciamento de recursos, computação utilitária, modelos de programação, computação paralela e distribuída e tecnologias de armazenamento.
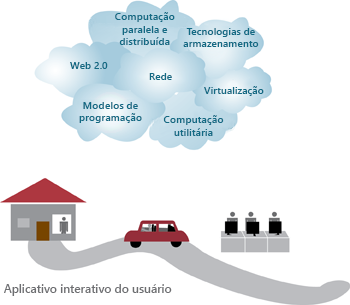
Figura 1.4: as tecnologias de habilitação na computação em nuvem.
O surgimento de tecnologias de rede ubíquas e de alta velocidade contribuiu muito para a computação em nuvem como um paradigma viável. As redes modernas possibilitam que os computadores se comuniquem de maneira rápida e confiável, o que é importante ao usar serviços de um provedor de nuvem. Isso permitiu que a experiência do usuário com o software executado em um data center remoto fosse comparável à experiência do software executado em um computador pessoal. O Webmail é um exemplo disso, assim como o software de produtividade do Office. Além disso, a virtualização é fundamental para habilitar a computação em nuvem. A virtualização permite gerenciar a complexidade da nuvem, abstraindo e compartilhando seus recursos entre os usuários por meio de várias máquinas virtuais. Cada máquina virtual pode executar seu próprio sistema operacional e programas de aplicativo associados.
Tecnologias como sistemas de armazenamento em grande escala, sistemas de arquivos distribuídos e novas arquiteturas de banco de dados são cruciais para gerenciar e armazenar dados em nuvem. A computação utilitária oferece inúmeras estruturas de cobrança para a utilização de recursos de computação. Exemplos incluem pagamento por uso horário do recurso, pagamento por taxa de transferência garantida, pagamento por dados armazenados por mês etc.
A computação paralela e distribuída permite que entidades distribuídas localizadas em computadores em rede se comuniquem e coordenem suas ações para resolver determinados problemas, representados como programas paralelos. Escrever programas paralelos para clusters distribuídos apresenta uma dificuldade inerentemente. Para obter alta eficiência de programação e flexibilidade na nuvem, é necessário um modelo de programação.
Os modelos de programação para nuvens oferecem aos usuários a flexibilidade para expressar programas paralelos como unidades de computação sequenciais (por exemplo, as funções no MapReduce e os vértices no GraphLab). Esses sistemas de runtime dos modelos de programação geralmente paralelizam, distribuem e agendam unidades computacionais, gerenciam a comunicação entre unidades e são tolerantes a falhas.
Referências
Simson L. Garfinkel (1999). Arquitetos da Sociedade da Informação: Thirty-Five Anos do Laboratório de Ciência da Computação do MIT. MIT Press.
Michelle Bailey (2009). A economia da virtualização: movendo-se em direção a um modelo de custo Application-Based. White paper IDC patrocinado pelo VMware.
Verificar seu conhecimento
Comentários
Esta página foi útil?
No
Precisa de ajuda com este tópico?
Quer experimentar o Pergunte e Aprenda para esclarecer ou guiar você neste tópico?