Tipos de aprendizado de máquina
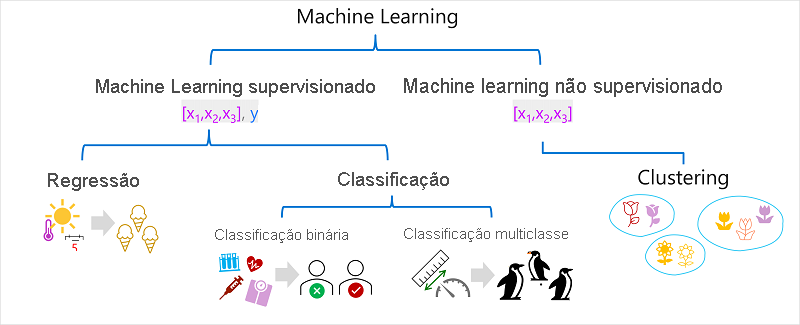
Existem vários tipos de aprendizado de máquina, e você deve aplicar o tipo apropriado dependendo do que está tentando prever. Um detalhamento dos tipos comuns de aprendizado de máquina será mostrado no diagrama a seguir.
Machine Learning supervisionado
O aprendizado de máquina Supervisionado é um termo geral para algoritmos de aprendizado de máquina em que os dados de treinamento incluem valores de recursos e valores conhecidos de rótulo. O aprendizado de máquina supervisionado é utilizado para treinar modelos determinando um relacionamento entre os recursos e os rótulos em observações passadas, de modo que rótulos desconhecidos possam ser previstos para recursos em casos futuros.
Regressão
Regressão é uma forma de aprendizado de máquina supervisionado em que o rótulo previsto pelo modelo é um valor numérico. Por exemplo:
- O número de sorvetes vendidos em um determinado dia, com base na temperatura, na chuva e na velocidade do vento.
- O preço de venda de um imóvel com base no seu tamanho em pés quadrados, no número de quartos que contém e nas métricas socioeconômicas da sua localização.
- A eficiência de combustível (em milhas por galão) de um carro com base no tamanho do motor, peso, largura, altura e comprimento.
Classificação
Classificação é uma forma de aprendizado de máquina supervisionado em que o rótulo representa uma categorização, ou classe. Existem dois cenários comuns de classificação.
Classificação binária
Na classificação binária, o rótulo determina se o item observado é (ou não é) uma instância de uma classe específica. Em outras palavras, os modelos de classificação binária preveem um de dois resultados mutuamente exclusivos. Por exemplo:
- Se um paciente está em risco de diabetes com base em métricas clínicas como peso, idade, nível de glicose no sangue e assim por diante.
- Se um cliente do banco ficará inadimplente em um empréstimo com base na renda, no histórico de crédito, na idade e em outros fatores.
- Se um cliente da lista de emails responderá positivamente a uma oferta de marketing com base nos atributos demográficos e nas compras anteriores.
Em todos esses exemplos, o modelo prevê uma previsão binária verdadeira/falsa ou positiva/negativa para uma única classe possível.
Classificação multiclasse
A classificação multiclasse amplia a classificação binária para prever um rótulo que representa uma das várias classes possíveis. Por exemplo,
- A espécie de um pinguim (Adélia, Gentoo ou Chinstrap) com base em suas medidas físicas.
- O gênero de um filme (comédia, terror, romance, aventura ou ficção científica) com base na equipe de elenco, no diretor e no orçamento.
Na maioria dos cenários que envolvem um conjunto conhecido de várias classes, a classificação multiclasse é utilizada para prever rótulos mutuamente exclusivos. Por exemplo, um pinguim não pode ser um Gentoo e um Adélia. Entretanto, há também alguns algoritmos que você pode utilizar para treinar os modelos de classificação com vários rótulos, nos quais pode existir mais de um rótulo válido para uma única observação. Por exemplo, um filme poderia ser potencialmente categorizado como ficção científica e comédia.
Aprendizado de máquina não supervisionado
O aprendizado de máquina não supervisionado envolve o treinamento de modelos usando dados que consistem apenas em valores de recursos sem rótulos conhecidos. Os algoritmos de aprendizado de máquina não supervisionados determinam relacionamentos entre os recursos das observações nos dados de treinamento.
Clustering
A forma mais comum de aprendizado de máquina não supervisionado é o clustering. Um algoritmo de clustering identifica semelhanças entre observações com base nos seus recursos e as agrupa em clusters discretos. Por exemplo:
- Agrupe flores semelhantes com base no tamanho, no número de folhas e no número de pétalas.
- Identificar os grupos de clientes semelhantes com base nos atributos demográficos e no comportamento de compra.
Em alguns aspectos, o clustering é semelhante à classificação multiclasse, pois categoriza as observações em grupos discretos. A diferença é que, ao usar a classificação, você já conhece as classes às quais pertencem as observações nos dados de treinamento; portanto, o algoritmo funciona determinando o relacionamento entre os recursos e o rótulo de classificação conhecido. No clustering, não existe um rótulo de cluster previamente conhecido e o algoritmo agrupa as observações de dados com base puramente na similaridade dos recursos.
Em alguns casos, o clustering é utilizado para determinar o conjunto de classes existentes antes de treinar um modelo de classificação. Por exemplo, você deve usar o clustering para segmentar seus clientes em grupos e, em seguida, analisar esses grupos para identificar e categorizar diferentes classes de clientes (alto valor - baixo volume, pequenos compradores frequentes e assim por diante). Em seguida, você pode usar suas categorizações para rotular as observações nos resultados do clustering e usar os dados rotulados para treinar um modelo de classificação que preveja a qual categoria de cliente um novo cliente pode pertencer.