Aprendizado profundo
Observação
Consulte a guia Texto e imagens para obter mais detalhes!
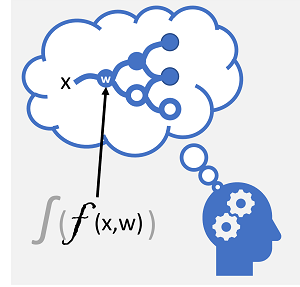
O aprendizado profundo é uma forma avançada de aprendizado de máquina que tenta emular a maneira como o cérebro humano aprende. A chave para o aprendizado profundo é a criação de uma rede neural artificial que simula a atividade eletroquímica em neurônios biológicos usando funções matemáticas, conforme mostrado aqui.
| Rede neural biológica | Rede neural artificial |
|---|---|

|
|
| Neurônios disparam em resposta a estímulos eletroquímicos. Quando acionado, o sinal é passado para neurônios conectados. | Cada neurônio é uma função que opera em um valor de entrada (x) e um peso (w). A função é encapsulada em uma função de ativação que determina se a saída deve ser passada adiante. |
Redes neurais artificiais são compostas por várias camadas de neurônios - essencialmente definindo uma função profundamente aninhada. Essa arquitetura é a razão pela qual a técnica é conhecida como aprendizado profundo e os modelos produzidos por ela são frequentemente chamados de DNNs ( redes neurais profundas ). Você pode usar redes neurais profundas para muitos tipos de problema de aprendizado de máquina, incluindo regressão e classificação, bem como modelos mais especializados para processamento de linguagem natural e pesquisa visual computacional.
Assim como outras técnicas de machine learning discutidas neste módulo, o aprendizado profundo envolve a montagem de dados de treinamento a uma função que pode prever um rótulo (y) com base no valor de um ou mais recursos (x). A função (f(x)) é a camada externa de uma função aninhada na qual cada camada da rede neural encapsula funções que operam em x e os valores de peso (w) associados a elas. O algoritmo utilizado para treinar o modelo envolve a alimentação iterativa dos valores dos recursos (x) nos dados de treinamento por meio das camadas para calcular as saídas para ŷ, validando o modelo para avaliar a distância entre os valores calculados ŷ e os valores conhecidos y (que quantifica o nível de erro, ou perda, no modelo) e, em seguida, modificando os pesos (w) para reduzir a perda. O modelo treinado inclui os valores de peso final que resultam nas previsões mais precisas.
Exemplo – Usando o aprendizado profundo para classificação
Para entender melhor como funciona um modelo de rede neural profunda, vamos explorar um exemplo no qual uma rede neural é usada para definir um modelo de classificação para espécies de pinguins.
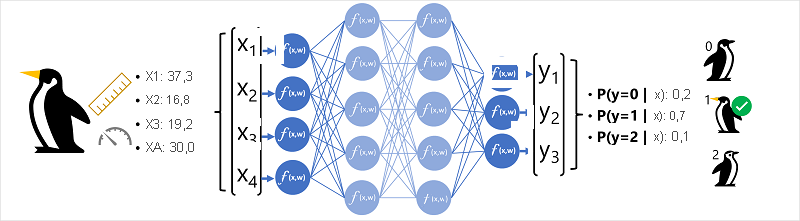
Os dados de características (x) consistem em algumas medições de um pinguim. Especificamente, as medidas são:
- O comprimento do bico do pinguim.
- A profundidade do bico do pinguim.
- O comprimento das nadadeiras do pinguim.
- O peso do pinguim.
Nesse caso, x é um vetor de quatro valores ou matematicamente, x=[x1,x2,x3,x4].
O rótulo que estamos tentando prever (y) é a espécie do pinguim, e existem três espécies possíveis:
- Adélia
- Gentoo
- Chinstrap
Este é um exemplo de um problema de classificação, no qual o modelo de machine learning deve prever a classe mais provável à qual uma observação pertence. Um modelo de classificação faz isso prevendo um rótulo que consiste na probabilidade de cada classe. Em outras palavras, y é um vetor de três valores de probabilidade; uma para cada uma das classes possíveis: [P(y=0|x), P(y=1|x), P(y=2|x)].
O processo para inferência de uma classe de pinguim prevista usando essa rede é:
- O vetor de características para uma observação de um pinguim é passado para a camada de entrada da rede neural, que consiste em um neurônio para cada valor x. Neste exemplo, o seguinte vetor x é usado como entrada: [37.3, 16.8, 19.2, 30.0]
- As funções da primeira camada de neurônios calculam cada uma uma soma ponderada combinando o valor x e o peso w , e passam-na para uma função de ativação que determina se ela atende ao limite a ser passado para a próxima camada.
- Cada neurônio em uma camada está conectado a todos os neurônios na próxima camada (uma arquitetura às vezes chamada de rede totalmente conectada) para que os resultados de cada camada sejam alimentados pela rede até atingirem a camada de saída.
- A camada de saída produz um vetor de valores; nesse caso, usando uma função softmax ou semelhante para calcular a distribuição de probabilidade para as três classes possíveis de pinguim. Neste exemplo, o vetor de saída é: [0.2, 0.7, 0.1]
- Os elementos do vetor representam as probabilidades para as classes 0, 1 e 2. O segundo valor é o mais alto, portanto, o modelo prevê que a espécie do pinguim é 1 (Gentoo).
Como uma rede neural aprende?
Os pesos em uma rede neural são fundamentais para o cálculo dos valores previstos dos rótulos. Durante o processo de treinamento, o modelo aprende os pesos que resultarão nas previsões mais precisas. Vamos explorar o processo de treinamento com um pouco mais de detalhes para entender como esse aprendizado ocorre.
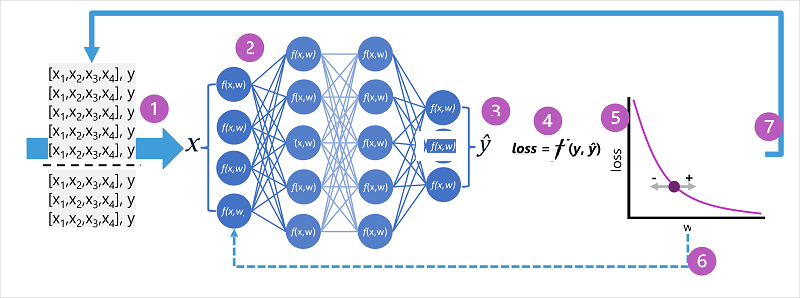
- Os conjuntos de dados de treinamento e validação são definidos e os recursos de treinamento são alimentados na camada de entrada.
- Os neurônios em cada camada da rede aplicam seus pesos (que são inicialmente atribuídos aleatoriamente) e alimentam os dados por meio da rede.
- A camada de saída produz um vetor que contém os valores calculados para ŷ. Por exemplo, uma saída para uma previsão de classe de pinguim pode ser [0,3. 0.1. 0.6].
- Uma função de perda é usada para comparar os valores previstos com os valores conhecidos y e agregar a diferença (que é conhecida como perda). Por exemplo, se a classe conhecida para o caso que retornou a saída na etapa anterior for Chinstrap, o valor y deverá ser [0.0, 0.0, 1.0]. A diferença absoluta entre este vetor e o vetor ŷ é [0.3, 0.1, 0.4]. Na realidade, a função de perda calcula a variação de agregação para vários casos e a resume como um único valor de perda .
- Como toda a rede é essencialmente uma função aninhada grande, uma função de otimização pode usar cálculo diferencial para avaliar a influência de cada peso na rede na perda e determinar como elas podem ser ajustadas (para cima ou para baixo) para reduzir a quantidade de perda geral. A técnica de otimização específica pode variar, mas geralmente envolve uma abordagem de descida de gradiente, em que cada peso é aumentado ou diminuído para minimizar a perda.
- As alterações nos pesos são retropropagadas para as camadas da rede, substituindo os valores usados anteriormente.
- O processo é repetido em várias iterações ( conhecidas como épocas) até que a perda seja minimizada e o modelo preveja com precisão.
Observação
Embora seja mais fácil pensar em cada caso dos dados de treinamento sendo passado pela rede um de cada vez, na realidade os dados são colocados em lote em matrizes e processados utilizando cálculos algébricos lineares. Por esse motivo, o treinamento de rede neural é melhor executado em computadores com GPUs (unidades de processamento gráfico) otimizadas para manipulação de vetores e matrizes.