Opções de configuração do HDInsight
O HDInsight tem uma ampla variedade de tecnologias de software de código aberto integradas, que podem ser usadas para lidar com cenários de dados de lote e de streaming, que são termos definidos em arquiteturas Lambda. Nesse modelo de arquitetura, há um caminho crítico de dados e um caminho frio de dados. O caminho crítico de dados é gerado em tempo real por dispositivos, sensores ou aplicativos e a análise de dados é executada quase em tempo real, isso geralmente é conhecido como dados de streaming. Um caminho de dados frio é quando os dados são movidos em lotes, normalmente de outros armazenamentos de dados e geralmente são chamados de dados de lote.
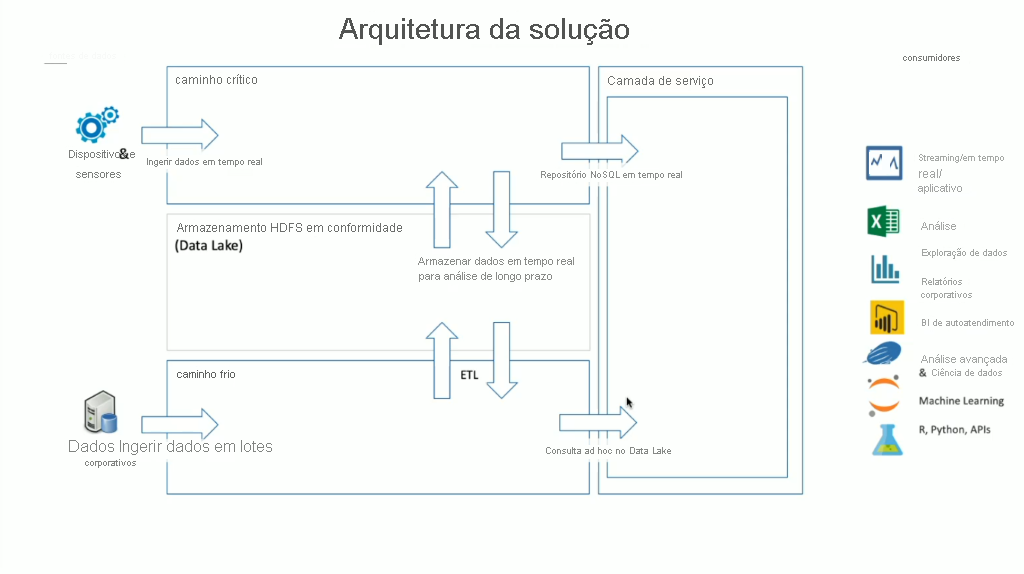
Ao implementar o HDInsight, o armazenamento de dados é mantido em um HDFS (Sistema de Arquivos Distribuído do Hadoop) em conformidade. No Azure, o Data Lake Gen2 normalmente é usado como um armazenamento de dados, pois está em conformidade com o HDFS. Os dados do caminho quente e do caminho frio após o processamento são armazenados em um armazenamento de dados centralizado chamado Data Lake. O Data Lake em si pode ser compartimentalizado para conter os dados em diferentes compartimentos, que podem ser definidos pelo estado dos dados (zona de destino, zona de transformação etc.), pelos requisitos de acesso (morno, quente e frio) e por grupos de negócios. A camada de serviço é o compartimento final no Data Lake que contém os dados em um formato pronto para serem consumidos por vários tipos de consumidores.
O aspecto de computação do HDInsight lida com o processamento de dados de streaming ou de lote e pode variar conforme o tipo de cluster que você seleciona ao provisionar um cluster do HDInsight. O HDInsight oferece os serviços em opções de cluster individuais, conforme mostra a tabela a seguir.
| Tipo de cluster | Descrição |
|---|---|
| Apache Hadoop | Uma estrutura que usa o HDFS e um modelo de programação MapReduce simples para processar e analisar dados em lotes. |
| Apache Spark | uma estrutura de processamento paralelo de software livre que dá suporte ao processamento na memória para melhorar o desempenho dos aplicativos de análise de Big Data. |
| HBase | um banco de dados NoSQL baseado em Hadoop que fornece acesso aleatório e coerência forte para big data não estruturado e semiestruturado (potencialmente, bilhões de linhas vezes milhões de colunas). |
| Consulta Interativa do Apache | Caching na memória para consultas de Hive interativas e mais rápidas. |
| Apache Kafka | uma plataforma de código-fonte aberto usada para criar aplicativos e pipelines de dados de transmissão. O Kafka também fornece funcionalidade de fila de mensagens, o que permite que você publique e assine fluxos de dados. |
Portanto, é importante selecionar o tipo de cluster correto para atender ao caso de negócios que você está tentando resolver. Independentemente do tipo de cluster selecionado, outros componentes de software livre também são adicionados ao cluster para oferecer mais recursos, incluindo:
Gerenciamento do Hadoop
HCatalog – Uma camada de gerenciamento de armazenamento e de tabela para o Hadoop
Apache Ambari – Facilita o gerenciamento e o monitoramento de um cluster do Apache Hadoop
Apache Oozie – Um sistema de agendador de fluxo de trabalho para gerenciar trabalhos do Apache Hadoop
Apache Hadoop YARN – Gerencia o gerenciamento de recursos e o agendamento/monitoramento de trabalhos
Apache ZooKeeper – Um serviço centralizado para manter informações de configuração, nomenclatura e fornecimento de sincronização distribuída e de serviços de grupo.
Processamento de dados
Apache Hadoop MapReduce – Uma estrutura para escrever facilmente aplicativos que processam grandes quantidades de dados
Apache Tez – Uma estrutura de aplicativo para processar dados
Apache Hive – Facilita o gerenciamento de grandes conjuntos de dados que residem no armazenamento distribuído usando SQL
Análise de dados
Apache Pig – Fornece uma camada de abstração no MapReduce para analisar grandes conjuntos de dados
Apache Phoenix – Habilita o OLTP e a análise operacional no Hadoop
Apache Mahout – Uma estrutura de álgebra para criar seus próprios algoritmos
Observação
No momento da redação deste artigo, o Azure Data Lake Gen1 e o Armazenamento de Blobs do Azure eram camadas de armazenamento de dados com suporte para o HDInsight. Procure migrar esses dados para o Azure Data Lake Gen2, que é a plataforma de armazenamento recomendada para Spark e Hadoop, bem como a opção padrão do HBase.