Machine learning e ciclo de vida de ciência de dados
O machine learning faz parte do campo mais amplo da ciência de dados. Essencialmente, é o processo de criar conhecimento com base em dados brutos.
É necessário um trabalho significativo para converter dados brutos em conhecimento. Por exemplo, imagine que você tem uma horta e está tentando cultivar alface. Você quer otimizar a horta para que o máximo de alface cresça no menor tempo. Você pode coletar um grande volume de dados que pode influenciar como você organiza o ambiente mais bem-sucedido para o cultivo de alface.
É possível considerar a exposição ao sol, a temperatura, a umidade do solo e do ar, o tipo de alface e a fonte de semente, a exposição ao ar puro, o tamanho da plantadeira, bem como a qualidade e a quantidade de solo. A lista pode ser ainda mais longa, porque pode haver alguns fatores que afetam o crescimento dos quais você nem esteja ciente, como o nível de ruído ou o tipo de ruído próximo à horta.
Ciclo de vida de ciência de dados
Uma compreensão do ciclo de vida de ciência de dados pode orientar você nos seus esforços para a criação de conhecimento com base em fontes de dados.
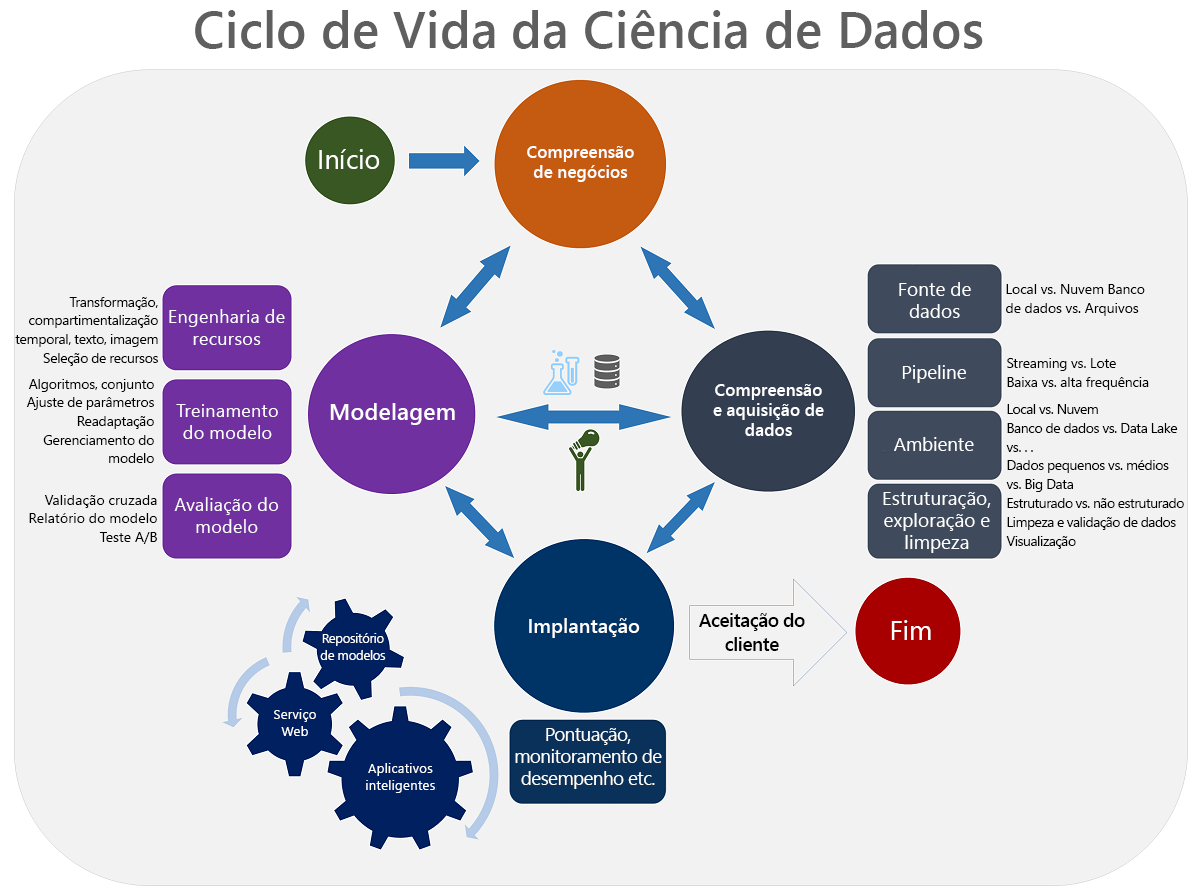
Estas são as quatro etapas do ciclo de vida de ciência de dados:
- Definir uma meta de negócios usando a experiência no assunto.
- Coletar, limpar e manipular os dados.
- Escolher um algoritmo de machine learning, bem como treinar e testar o modelo.
- Implantar o modelo a ser usado com outros aplicativos.
Continue lendo para examinar cada etapa do ciclo de vida de ciência de dados em mais detalhes.