Selecionar a biblioteca MPI correta
Os SKUs HB120_v2, HB60 e HC44 dão suporte a interconexões de rede InfiniBand. Como a virtualização do PCI express é feita por meio de SR-IOV (virtualização de E/S de raiz única), todas as bibliotecas de MPI populares (HPCX, OpenMPI, Intel MPI, MVAPICH e MPICH) estão disponíveis nessas VMs de HPC.
A limitação atual de um cluster de HPC que pode se comunicar por InfiniBand é de 300 VMs. A seguinte tabela lista o número máximo de processos paralelos que têm suporte em aplicativos de MPI firmemente acoplados que estão se comunicando por InfiniBand.
| SKU | Máximo de processos paralelos |
|---|---|
| HB120_v2 | 36.000 processos |
| HC44 | 13.200 processos |
| HB60 | 18.000 processos |
Observação
Esses limites podem mudar no futuro. Se você tem um trabalho de MPI firmemente acoplado que exige um limite mais alto, envie uma solicitação de suporte. Dependendo da sua situação, seus limites poderão ser aumentados.
Se um aplicativo de HPC recomendar uma biblioteca de MPI específica, tente essa versão primeiro. Se você tem flexibilidade em relação a qual MPI escolher e deseja ter um melhor desempenho, experimente a HPCX. Em geral, a MPI HPCX tem um desempenho melhor ao usar a estrutura UCX para a interface InfiniBand e aproveita todos os recursos de hardware e software Mellanox InfiniBand.
A ilustração a seguir compara as arquiteturas de biblioteca MPI populares.
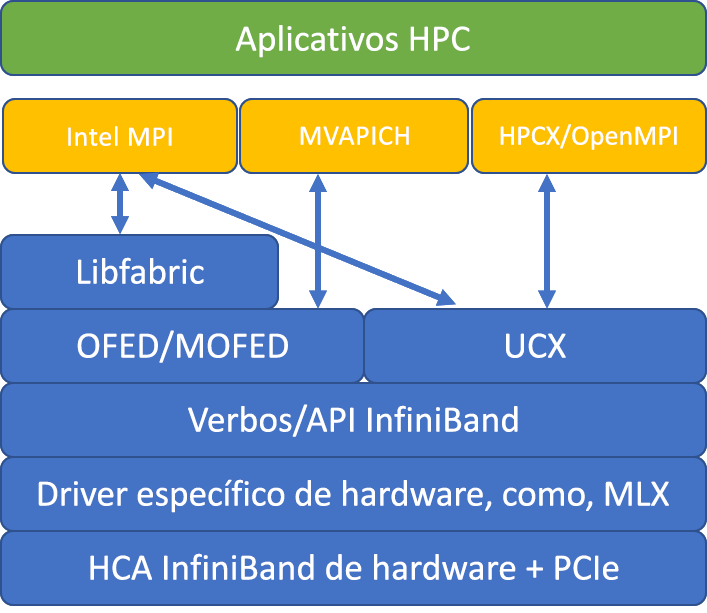
HPCX e OpenMP são compatíveis com ABI, para que você possa executar dinamicamente um aplicativo de HPC com a HPCX criada com a OpenMPI. Da mesma forma, Intel MPI, MVAPICH e MPICH são compatíveis com ABI.
A fim de evitar qualquer vulnerabilidade de segurança por meio do acesso de hardware de baixo nível, o par de filas 0 não ficará acessível para a VM convidada. Isso não deve ter nenhum efeito sobre os aplicativos de HPC do usuário final, mas pode impedir que algumas ferramentas de baixo nível funcionem corretamente.
Argumentos mpirun de HPCX e OpenMPI
O seguinte comando ilustra alguns argumentos mpirun recomendados para HPCX e OpenMPI:
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
Nesse comando:
| Parâmetro | Descrição |
|---|---|
$NPROCS |
Especifica o número de processos de MPI. Por exemplo: -n 16. |
$HOSTFILE |
Especifica um arquivo que contém o nome do host ou endereço IP, para indicar o local onde os processos de MPI serão executados. Por exemplo: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Especifica o número de processos MPI que serão executados em cada domínio NUMA. Por exemplo, para especificar quatro processos MPI por NUMA, use --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Especifica o número de threads por processo de MPI. Por exemplo, para especificar um processo de MPI e quatro threads por NUMA, use --map-by ppr:1:numa:pe=4. |
-report-bindings |
Imprime o mapeamento de processos de MPI para núcleos, o que é útil para verificar se a fixação de processos de MPI está correta. |
$MPI_EXECUTABLE |
Especifica a vinculação criada no executável de MPI em bibliotecas MPI. Wrappers do compilador de MPI fazem isso automaticamente. Por exemplo: mpicc ou mpif90. |
Se você suspeita que seu aplicativo de MPI firmemente acoplado está fazendo uma quantidade excessiva de comunicação coletiva, experimente habilitar os coletivos hierárquicos (HCOLL). Para habilitar esses recursos, use os seguintes parâmetros:
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Argumentos mpirun de Intel MPI
A versão Intel MPI 2019 mudou da estrutura OFA (Open Fabrics Alliance) para a estrutura OFI (Open Fabrics Interfaces) e atualmente dá suporte a libfabric. Há dois provedores de suporte a InfiniBand: mlx e verbs. O provedor mlx é o provedor preferencial em VMs HB e HC.
Confira abaixo alguns argumentos mpirun sugeridos para a atualização 5+ da Intel MPI 2019:
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Nesses argumentos:
| Parâmetros | Descrição |
|---|---|
FI_PROVIDER |
Especifica qual provedor de libfabric usar, qual afetará a API, o protocolo e a rede usados. verbs é outra opção, mas geralmente mlx oferece um melhor desempenho. |
I_MPI_DEBUG |
Especifica o nível de saída de depuração extra, que pode fornecer detalhes sobre onde os processos são fixados e qual protocolo e rede são usados. |
I_MPI_PIN_DOMAIN |
Especifica como você deseja fixar seus processos. Por exemplo, você pode fixar em núcleos, soquetes ou domínios NUMA. Nesse exemplo, a variável de ambiente, como numa, é definida, o que significa que os processos serão fixados em domínios de nó NUMA. |
Há algumas outras opções que você pode experimentar, especialmente se as operações coletivas estiverem consumindo uma quantidade significativa de tempo. A Intel MPI 2019, atualização 5+, dá suporte a mlx e usa a estrutura UCX para se comunicar com InfiniBand. Também dá suporte a HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Argumentos mpirun de MVAPICH
A seguinte lista contém vários argumentos mpirun recomendados:
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
Nesses argumentos:
| Parâmetros | Descrição |
|---|---|
MV2_CPU_BINDING_POLICY |
Especifica qual política de associação usar, o que afetará como os processos são fixados em IDs de núcleo. Nesse caso, especificamos scatter. Portanto, os processos serão dispersos de maneira uniforme entre os domínios NUMA. |
MV2_CPU_BINDING_LEVEL |
Especifica onde fixar os processos. Nesse caso, isso é definido como numanode, o que significa que os processos são fixados em unidades de domínios NUMA. |
MV2_SHOW_CPU_BINDING |
Especifica se você deseja obter informações de depuração sobre onde os processos são fixados. |
MV2_SHOW_HCA_BINDING |
Especifica se você deseja obter informações de depuração sobre qual adaptador de canal de host cada processo está usando. |