Exercício – Transmitir dados do Kafka para um Jupyter Notebook e definir a janela dos dados
O cluster do Kafka agora está gravando dados em log, que pode ser processado por meio de streaming estruturado do Spark.
Um notebook do Spark está incluído no exemplo clonado, portanto, você precisa carregar esse notebook para o cluster do Spark usá-lo.
Carregar o Python notebook para o cluster do Spark
No portal do Azure, clique em Home > clusters do HDInsight e selecione o cluster do Spark que você acabou de criar (não o cluster do Kafka).
No painel Painéis do cluster, clique em Jupyter Notebook.

Quando solicitado a fornecer credenciais, insira um nome de usuário de administrador e insira a senha que você criou ao criar os clusters. O site do Jupyter é exibido.
Clique em PySpark e, na página PySpark, clique em Carregar.
Navegue até a localização para a qual você baixou o exemplo do GitHub, selecione o arquivo RealTimeStocks.ipynb, clique em Abrir, clique em Carregar e então clique em Atualizar no navegador da Internet.
Depois do upload do notebook para a pasta PySpark, clique em RealTimeStocks.ipynb para abri-lo no navegador.
Execute a primeira célula no notebook colocando o cursor na célula e clicando em Shift+Enter para executá-la.
A célula Configurar bibliotecas e pacotes é concluída com êxito quando exibe a mensagem Iniciando o aplicativo Spark e informações adicionais, conforme mostra a legenda da tela a seguir.
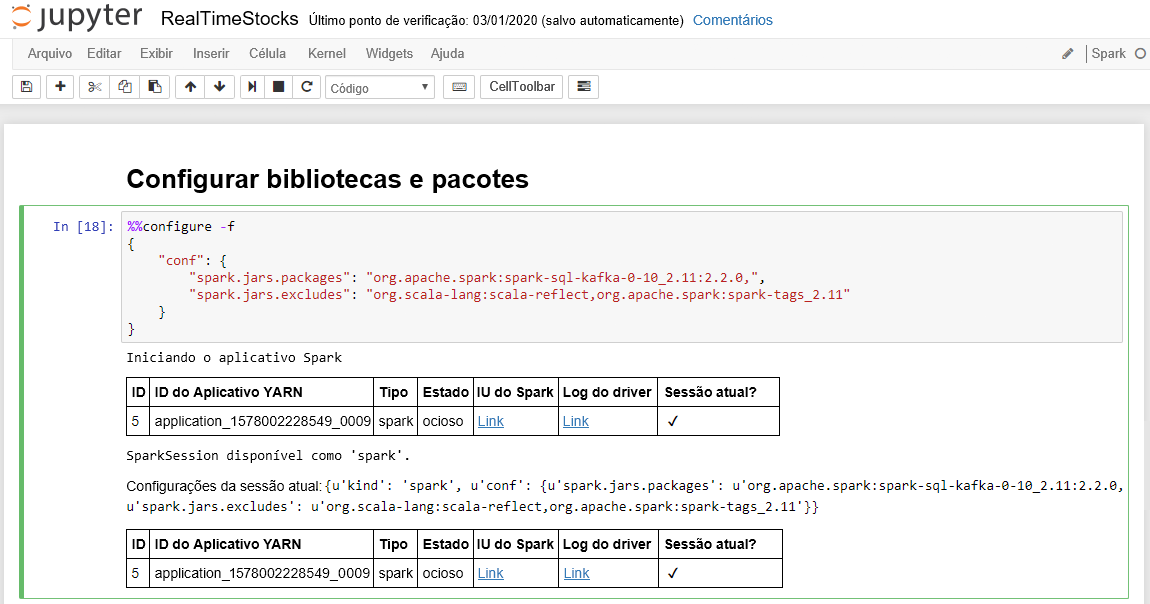
Na célula Configurar Conexão com Kafka, na linha .option("kafka.bootstrap.servers", ""), insira o agente Kafka entre o segundo conjunto de aspas. Por exemplo. .option("kafka.bootstrap.servers", "wn0-kafka.mdlamldganads.gx.internal.cloudapp.net:9092"), depois pressione Shift + Enter para executar a célula.
A conexão de configuração para a célula Kafka é concluída com êxito quando exibe a mensagem inputDf: org.Apache.Spark.Sql.DataFrame = [key: Binary, value: Binary... mais cinco campos]. O Spark usa a API readStream para ler os dados.
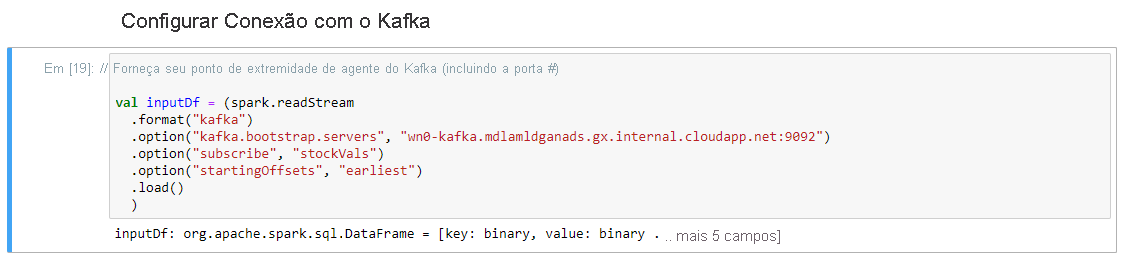
Selecione a célula Ler do Kafka no dataframe de streaming e clique em Shift+Enter para executar a célula.
A célula é concluída com êxito quando exibe a seguinte mensagem: stockDf: org.apache.spark.sql.DataFrame = [symbol: string, time: string ... 2 more fields]
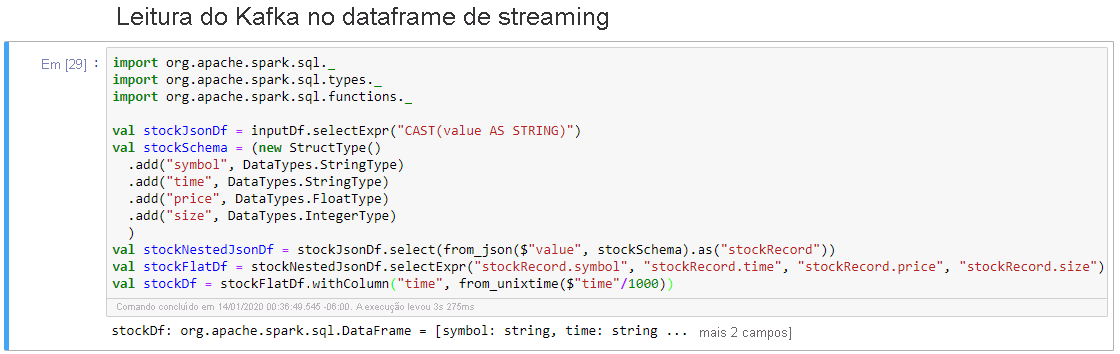
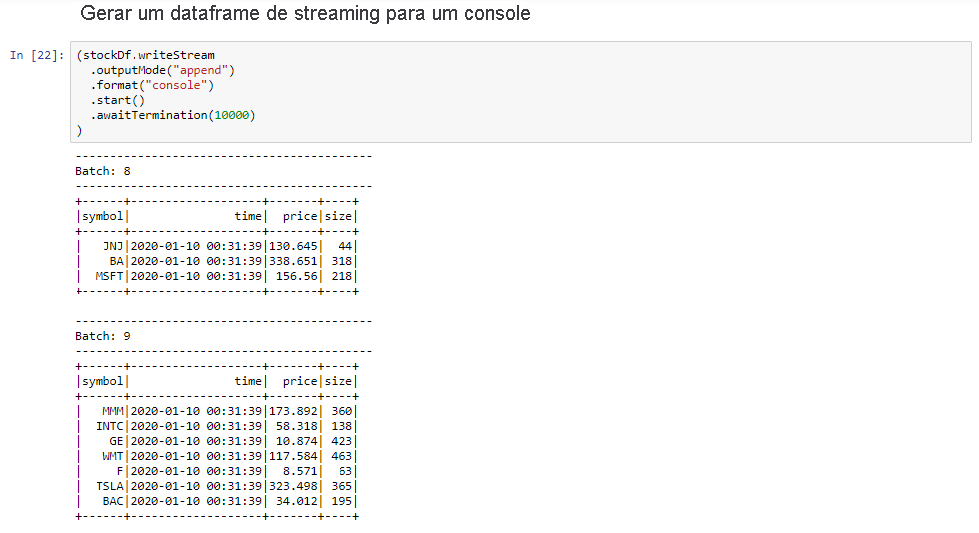
Selecione a célula Dataframe de streaming de saída para o console e clique em Shift+Enter para executá-la.
A célula é concluída com êxito quando mostra informações semelhantes às abaixo. A saída mostra o valor de cada célula como foi passada no microlote, e há um lote por segundo.
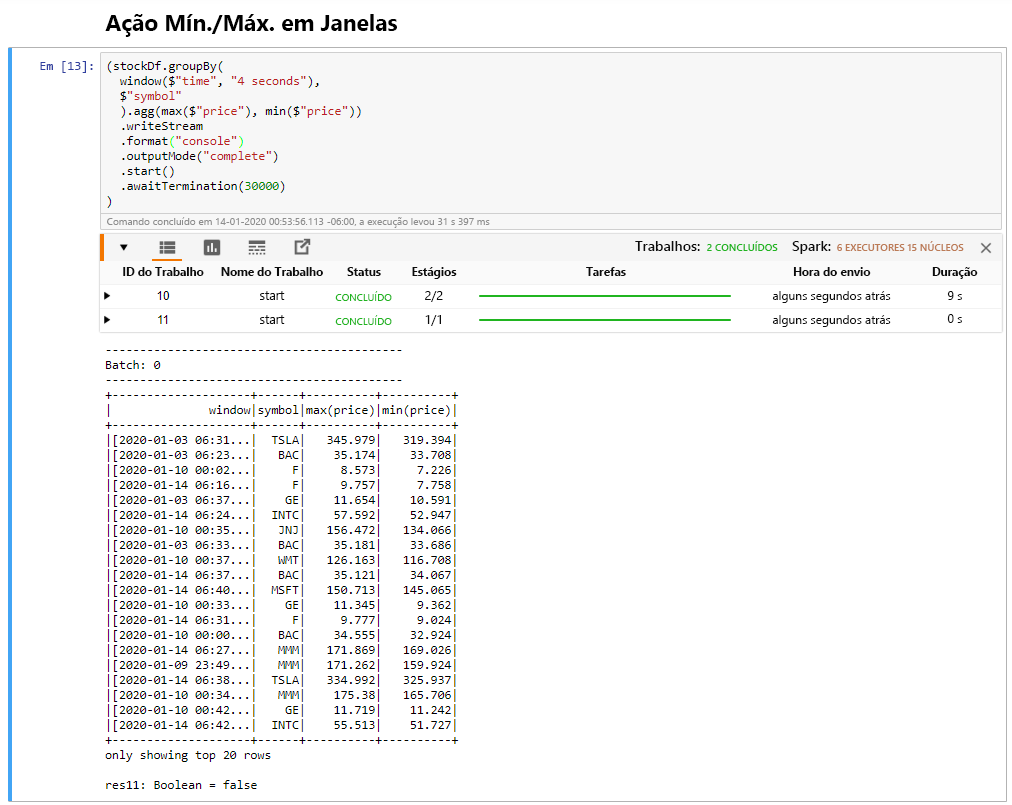
Selecione a célula Ação Mín./Máx. em Janelas e clique em Shift+Enter para executar a célula.
A célula é concluída com êxito quando fornece os preços máximo e mínimo de cada ação na janela de 4 segundos, que é definida na célula. Conforme discutido em uma unidade anterior, fornecer informações sobre janelas específicas é um dos benefícios de usar o Streaming Estruturado do Spark.
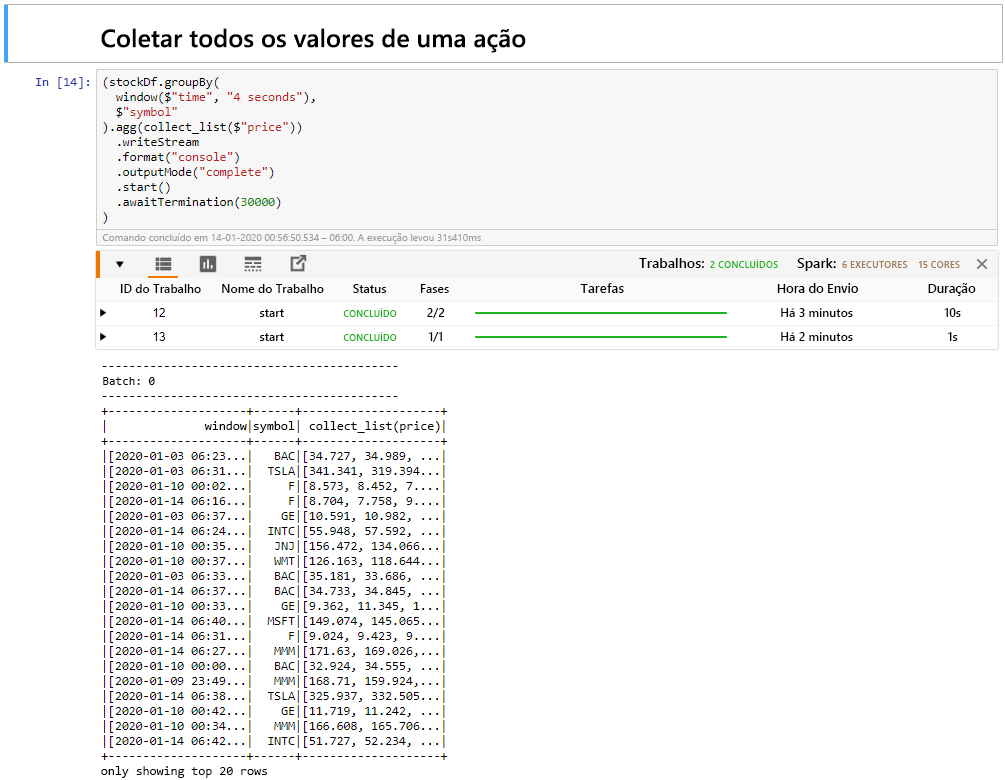
Selecione a célula Coletar todos os valores de ações em uma célula de janela e clique em Shift+Enter para executar a célula.
A célula é concluída com êxito quando fornece uma tabela dos valores para as ações na tabela. O outputMode é concluído, de modo que todos os dados são mostrados.
Nesta unidade, você carregou um Jupyter Notebook em um cluster do Spark, conectou-o ao seu cluster do Kafka, gerou os dados de streaming criados pelo arquivo do produtor do Python para o notebook do Spark, definiu uma janela para os dados de streaming e exibiu os preços de ações altos e baixos nessa janela e exibiu todos os valores de ação na tabela. Parabéns, você realizou com êxito o streaming estruturado usando o Spark e o Kafka!