Replicar dados para um cluster secundário
O Kafka geralmente é implantado em vários ambientes para recuperação de desastres, alta disponibilidade e cenários híbridos de nuvem local. Esses cenários exigem a replicação dos dados de uma instância do Kafka para outra usando o recurso de espelhamento do Apache Kafka. O espelhamento pode ser executado como um processo contínuo ou usado de modo intermitente como um método de migração de dados de um cluster para outro.
O espelhamento não deve ser considerado um meio de obter tolerância a falhas. O deslocamento para itens em um tópico é diferente entre os clusters de origem e de destino. Assim, os clientes não podem usar os dois de modo intercambiável.
Como o espelhamento funciona?
O espelhamento funciona usando a ferramenta MirrorMaker (parte do Apache Kafka) para consumir registros de tópicos no cluster primário e criar uma cópia local no cluster secundário. O MirrorMaker usa um ou mais consumidores que leem do cluster primário e um produtor que grava no cluster secundário local.
A configuração de espelhamento mais útil para a recuperação de desastre utiliza clusters do Kafka em diferentes regiões do Azure. Para conseguir isso, as redes virtuais nas quais os clusters residem são emparelhadas.
O seguinte diagrama ilustra o processo de espelhamento e como a comunicação flui entre os clusters:
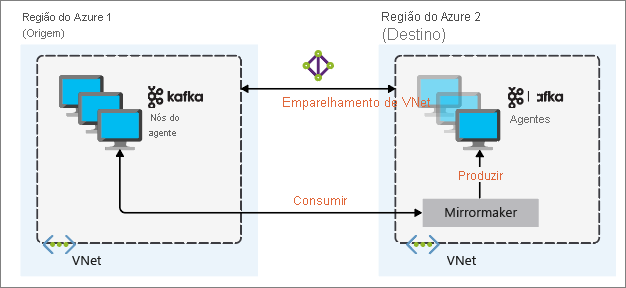
Os clusters primário e secundário podem ser diferentes no número de nós e partições, e os deslocamentos nos tópicos também são diferentes. O espelhamento mantém o valor de chave que é usado para particionamento. Assim, a ordem de registros é preservada por chave.
Espelhamento entre limites de rede
Se você precisa de espelhamento entre clusters Kafka em redes diferentes, há as seguintes considerações adicionais:
- Gateways: as redes devem ser capazes de se comunicar no nível de TCP/IP.
- Endereçamento de servidor: você pode optar por endereçar os nós de cluster usando seus endereços IP ou nomes de domínio totalmente qualificados.
- Endereços IP: se você configurar seus clusters Kafka para usar publicidade de endereço IP, poderá prosseguir com a configuração de espelhamento usando os endereços IP dos nós do agente e nós do ZooKeeper.
- Nomes de domínio: se você não configurar os clusters Kafka para publicidade de endereço IP, os clusters deverão ser capazes de se conectar entre si usando FQDNs (nomes de domínio totalmente qualificados). Isso exige um servidor DNS (Sistema de Nomes de Domínio) em cada rede configurado para encaminhar solicitações para outras redes. Ao criar uma Rede Virtual do Azure, em vez de usar o DNS automático fornecido com a rede, você deve especificar um servidor DNS personalizado e o endereço IP do servidor. Depois que a Rede Virtual for criada, você deverá criar uma Máquina Virtual do Azure que use esse endereço IP e instalar e configurar o software DNS nela.
Aviso
Crie e configure o servidor DNS personalizado antes de instalar o HDInsight na Rede Virtual. Não é necessária configuração adicional para que o HDInsight use o servidor DNS configurado para a Rede Virtual.