Consultas interativas do HDInsight
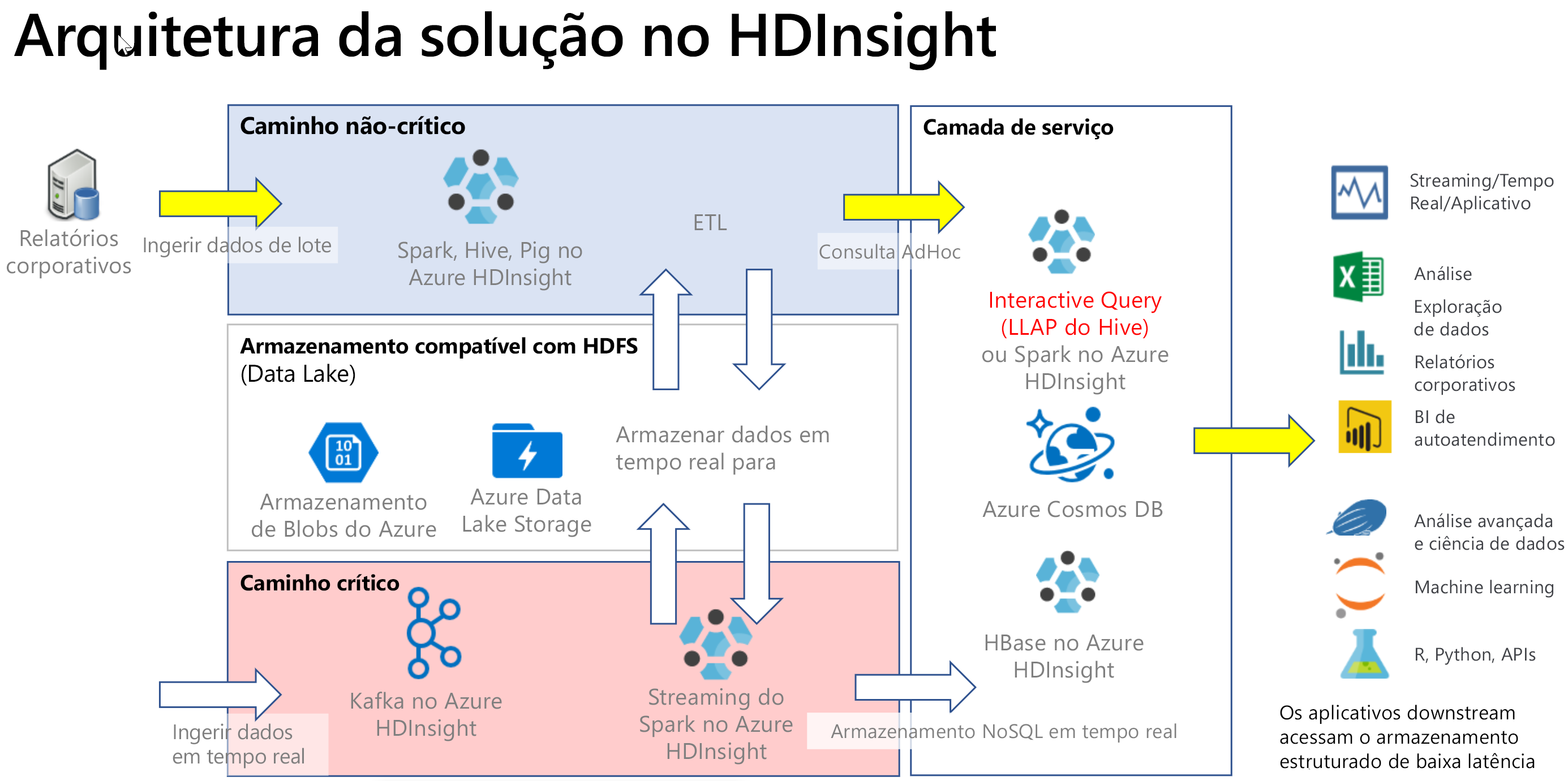
As consultas interativas normalmente são implementadas em um cenário de caminho frio, em que você tem dados em formato tabular e deseja fazer perguntas rapidamente e obter uma resposta interativa usando a sintaxe SQL. O diagrama a seguir mostra a arquitetura da solução para todas as soluções de caminho frio e caminho crítico do HDInsight e chama como as consultas interativas são tratadas por meio do LLAP do Hive na camada de serviço. Os dados podem ser ingeridos por meio do Hive, as consultas interativas são processadas por meio do LLAP do Hive e a saída colocada pode ser servida para aplicativos downstream, como o Power BI.
Arquitetura da Interactive Query
Agora vamos nos aprofundar na arquitetura da Interactive Query.
Os usuários da Interactive Query podem escolher entre uma variedade de clientes ODBC ou JDBC para executar consultas em dados corporativos, como Data Analytics Studio, Notebooks Zeppelin e Visual Studio Code. Depois que um cliente envia uma consulta HiveQL, a consulta chega ao HiveServer, que é responsável pelo planejamento de consultas, pela otimização e pela remoção de segurança. O Hive funciona dividindo as tarefas de análise entre nós distribuídos no cluster. As consultas são divididas em subtarefas e enviadas a nós que processam cada uma das subtarefas, que, por sua vez, são divididas ainda mais. Cada uma dessas tarefas lê os dados da camada de armazenamento de dados de negócios subjacente. A arquitetura é otimizada com o uso de daemons LLAP "sempre ativados", que evitam tempos de inicialização, bem como o cache na memória compartilhado, que armazena os dados recuperados do armazenamento e os compartilha entre todos os nós.
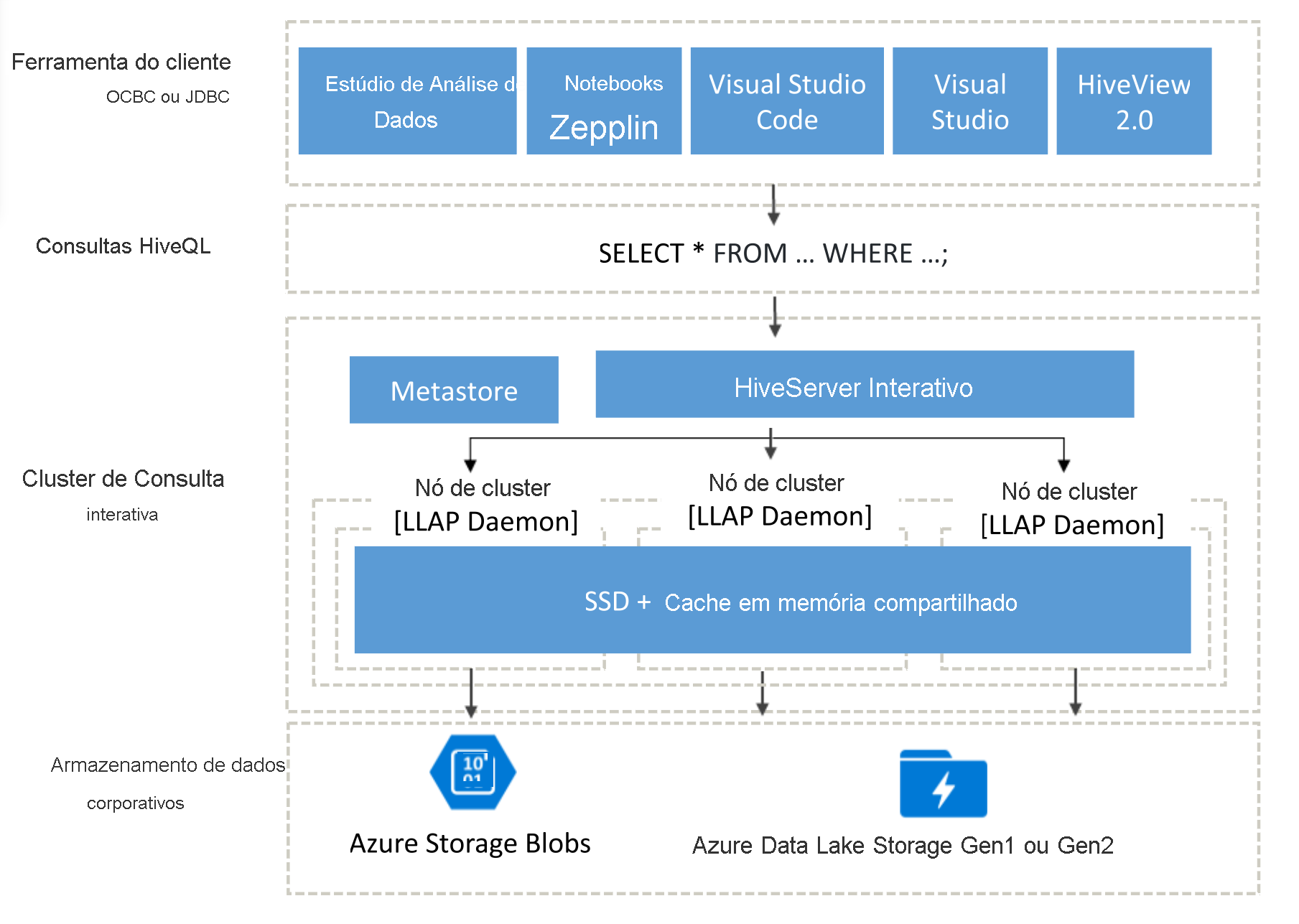
As SSD (unidades de estado sólido) utilizadas por clusters de Interactive Query combinam RAM e SSD em um pool gigante de memória usado pelo cache. Com essa combinação de recursos, um perfil de servidor típico pode armazenar em cache quatro vezes mais dados, permitindo que você processe conjuntos de dados maiores e dê suporte a mais usuários. O cache de Interactive Query reconhece as alterações de dados subjacentes no armazenamento remoto (Armazenamento do Azure), portanto, se os dados subjacentes forem alterados e o usuário emitir uma consulta, os dados atualizados serão carregados na memória sem a necessidade de nenhuma etapa adicional do usuário.