Exercício – Limpar e preparar os dados
Antes de poder preparar um conjunto de dados, você precisa entender seu conteúdo e sua estrutura. No laboratório anterior, você importou um conjunto de dados que contém informações de chegada no horário previsto para uma grande empresa aérea dos EUA. Esses dados incluíam 26 colunas e milhares de linhas, em que cada linha representava um voo e continha informações como origem, destino e hora de partida agendada do voo. Você carregou os dados em um Jupyter Notebook e usou um script Python simples para criar um DataFrame Pandas com base nele.
Um DataFrame é uma estrutura de dados rotulada bidimensional. As colunas em um DataFrame podem ser de tipos diferentes, assim como colunas em uma planilha ou tabela de banco de dados. Esse é o objeto mais comumente usado no Pandas. Neste exercício, você examinará mais de perto o DataFrame e os dados contidos nele.
Mude de volta para o Azure Notebook que você criou na seção anterior. Se você fechou o bloco de anotações, poderá entrar novamente no portal do Microsoft Azure Notebooks, abrir seu bloco de anotações e usar a Célula ->Executar Tudo para executar novamente todas as células no notebook depois de abri-lo.
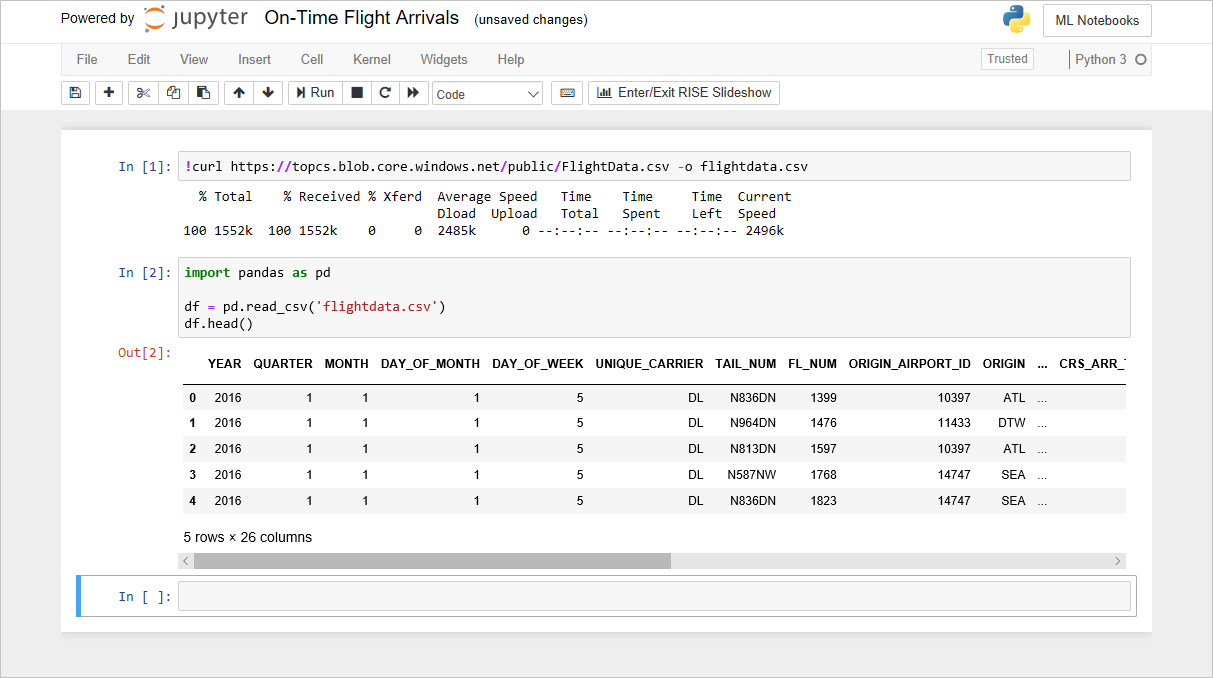
O notebook FlightData
O código que você adicionou ao notebook no laboratório anterior cria um DataFrame de flightdata.csv e chama DataFrame.head nele para exibir as cinco primeiras linhas. Uma das primeiras coisas que você geralmente deseja saber sobre um conjunto de dados é o número de linhas que ele contém. Para obter uma contagem, digite a seguinte instrução em uma célula vazia no final do notebook e execute-o:
df.shapeConfirme que o DataFrame contém 11.231 linhas e 26 colunas:

Obter uma contagem de linhas e de colunas
Agora reserve um tempo para examinar as 26 colunas no conjunto de dados. Elas contêm informações importantes, tais como a data em que o voo ocorreu (YEAR, MONTH e DAY_OF_MONTH), a origem e o destino (ORIGIN e DEST), as horas de partida e de chegada agendadas (CRS_DEP_TIME e CRS_ARR_TIME), a diferença entre a hora de chegada agendada e a hora de chegada real em minutos (ARR_DELAY), e se o voo foi atrasado por 15 minutos ou mais (ARR_DEL15).
Aqui está uma lista completa das colunas no conjunto de dados. Os horários são expressos em formato de 24 horas. Por exemplo, 1130 é igual a 11h30 e 1500 é igual a 3h.
Coluna Descrição ANO O ano em que o voo foi realizado QUARTER O trimestre em que o voo foi realizado (1-4) MÊS O mês em que o voo foi realizado (1-12) DAY_OF_MONTH O dia do mês em que o voo foi realizado (1-31) DIA_DA_SEMANA Dia da semana em que o voo ocorreu (1=segunda-feira, 2=terça-feira, etc.) UNIQUE_CARRIER Código da operadora de companhia aérea (por exemplo, DL) TAIL_NUM Número da cauda da aeronave FL_NUM Número do voo ORIGIN_AIRPORT_ID ID do aeroporto de origem ORIGEM Código do aeroporto de origem (ATL, DFW, SEA, etc.) DEST_AIRPORT_ID ID do aeroporto de destino DEST Código do aeroporto de destino (ATL, DFW, SEA, etc.) CRS_DEP_TIME Hora de partida agendada DEP_TIME Hora de partida real DEP_DELAY Número de minutos em que a partida foi atrasada DEP_DEL15 0=Partida atrasada em menos de 15 minutos, 1=Partida atrasada em 15 minutos ou mais CRS_ARR_TIME Hora de chegada agendada ARR_TIME Hora de chegada real ARR_DELAY Número de minutos em que a chegada do voo atrasou ARR_DEL15 0=Chegou com menos de 15 minutos de atraso, 1=Chegou com 15 minutos de atraso ou mais CANCELADO 0=O voo não foi cancelado, 1=O voo foi cancelado DESVIADO 0=O voo não foi desviado, 1=O voo foi desviado CRS_ELAPSED_TIME Tempo de voo agendado em minutos ACTUAL_ELAPSED_TIME Tempo de voo real em minutos DISTÂNCIA Distância percorrida em milhas
O conjunto de dados inclui uma distribuição aproximadamente uniforme de datas ao longo do ano, o que é importante porque um voo saindo de Minneapolis tem menos probabilidade de atrasar devido a tempestades de inverno em julho do que em janeiro. Mas esse conjunto de dados está longe de ser "limpo" e pronto para uso. Vamos escrever um código de Pandas para limpá-lo.
Um dos aspectos mais importantes da preparação de um conjunto de dados para uso no aprendizado de máquina é selecionar as colunas de "recurso" relevantes para o resultado que você está tentando prever ao filtrar colunas que não afetam o resultado, podem ser tendenciosas de forma negativa ou podem produzir multicollinearidade. Outra tarefa importante é eliminar valores ausentes, excluindo as linhas ou colunas que os contêm ou substituindo-os com valores significativos. Neste exercício, você elimina colunas estranhas e substituir valores ausentes nas colunas restantes.
Valores ausentes são uma das primeiras coisas que os cientistas de dados normalmente procuram em um conjunto de dados. Há uma maneira fácil de verificar se há valores ausentes no Pandas. Para demonstrar, execute o seguinte código em uma célula no final do notebook:
df.isnull().values.any()Confirme que a saída é "True", o que indica que há pelo menos um valor ausente em algum lugar no conjunto de dados.

Verificando se há valores ausentes
A próxima etapa é descobrir onde estão os valores ausentes. Para fazer isso, execute o seguinte código:
df.isnull().sum()Confirme que você vê a seguinte saída listando uma contagem de valores ausentes em cada coluna:
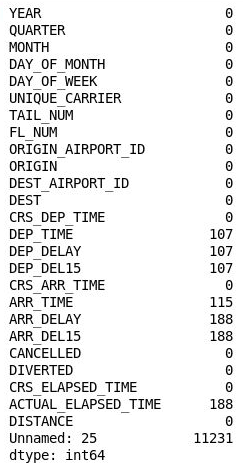
Número de valores ausentes em cada coluna
Curiosamente, a 26ª coluna (“Sem nome: 25”) contém 11.231 valores ausentes, o que equivale ao número de linhas no conjunto de dados. Esta coluna foi criada por engano, porque o arquivo CSV que você importou contém uma vírgula no final de cada linha. Para eliminar essa coluna, adicione o seguinte código ao notebook e execute-o:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Inspecione a saída e confirme que essa coluna 26 desapareceu do DataFrame:
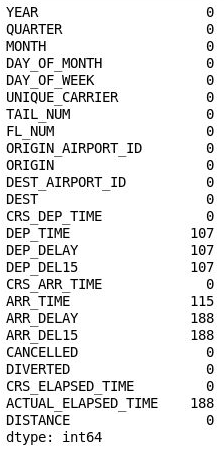
O DataFrame com a coluna 26 removida
O DataFrame ainda contém muitos valores ausentes, mas alguns deles não são úteis porque as colunas que os contêm não são relevantes para o modelo que você está criando. O objetivo desse modelo é prever se um voo que você está pensando em reservar provavelmente chegará no horário. Se você sabe que o voo provavelmente se atrasará, você pode optar por reservar outro voo.
Portanto, é a próxima etapa filtrar o conjunto de dados para eliminar as colunas que não são relevantes para um modelo preditivo. Por exemplo, o número da cauda da aeronave provavelmente tem pouca influência na pontualidade de um voo e, no momento em que reserva uma passagem, você não tem como saber se um voo será cancelado, desviado ou atrasado. Por outro lado, a hora de partida agendada pode ter muita influência sobre a pontualidade da chegada. Por causa do sistema de hub e spoke usado pela maioria das companhias aéreas, os voos matinais tendem a chegar no horário mais frequentemente do que aqueles vespertinos ou noturnos. E em alguns dos principais aeroportos, o tráfego se acumula durante o dia, aumentando a probabilidade de que voos em horários mais próximos do fim do dia se atrasem.
O Pandas fornece uma maneira fácil de filtrar as colunas que você não deseja. Execute o seguinte código em uma nova célula no final do notebook:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()A saída mostra que o DataFrame agora inclui apenas as colunas que são relevantes para o modelo e o número de valores ausentes é bastante reduzido:
O DataFrame filtrado.
O DataFrame filtrado
A única coluna que agora contém valores ausentes é a coluna ARR_DEL15, que usa 0s para identificar os voos pontuais e 1s para os voos atrasados. Use o código a seguir para mostrar as primeiras cinco linhas com valores ausentes:
df[df.isnull().values.any(axis=1)].head()O Pandas representa valores ausentes com
NaN, o que significa Não um Número. A saída mostra que há de fato valores ausentes nessas linhas, na coluna ARR_DEL15: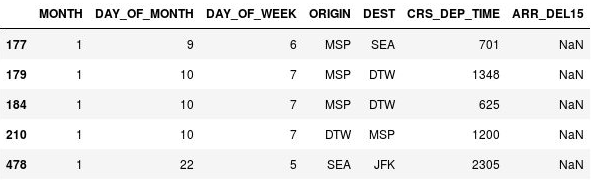
Linhas com valores ausentes
O motivo pelo qual há valores ARR_DEL15 ausentes nessas linhas é que todos eles correspondem aos voos que foram cancelados ou cujos itinerários foram alterados. Você pode chamar dropna no DataFrame para remover essas linhas. Mas já que um voo que é cancelado ou desviado para outro aeroporto pode ser considerado "atrasado", usaremos o método fillna para substituir os valores ausentes por 1s.
Use o código a seguir para substituir valores ausentes na coluna ARR_DEL15 por 1s e exibir as linhas 177-184:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Confirme se os
NaNs nas linhas 177, 179 e 184 foram substituídos por 1s, indicando que os voos chegaram atrasados: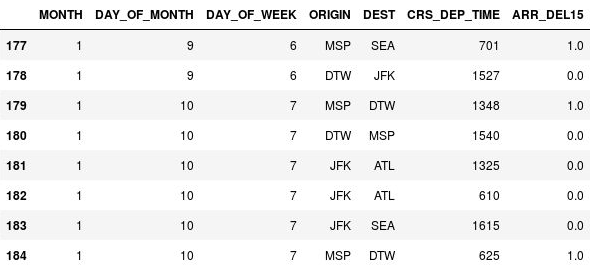
NaNs substituídos por 1s
O conjunto de dados agora está "limpo", no sentido de que os valores ausentes foram substituídos e a lista de colunas foi reduzida para aquelas mais relevantes para o modelo. Mas você não ainda terminou. Há mais o que fazer para preparar o conjunto de dados para uso no aprendizado de máquina.
A coluna CRS_DEP_TIME do conjunto de dados que você está usando representa horários de partida agendados. A granularidade dos números nessa coluna (que contém mais de 500 valores exclusivos) pode ter um impacto negativo na precisão em um modelo de machine learning. Isso pode ser resolvido com uma técnica chamada compartimentalização. E se você dividir cada número nesta coluna por 100 e arredondar para baixo até o inteiro mais próximo? 1030 se tornará 10, 1925 se tornará 19 e assim por diante e você ficará com um máximo de 24 valores discretos nesta coluna. Intuitivamente faz sentido, pois provavelmente não importa muito se um voo sai às 10h30 ou 10h40. Importa muito se ele sai às 10h30 ou às 17h30.
Além disso, as colunas ORIGIN e DEST do conjunto de dados contêm códigos de aeroporto que representam valores categóricos do aprendizado de máquina. Essas colunas precisam ser convertidas em colunas discretas que contém variáveis de indicador, às vezes conhecidas como variáveis "fictícias". Em outras palavras, a coluna ORIGIN, que contém cinco códigos de aeroporto, precisa ser convertida em cinco colunas, uma por aeroporto, com cada coluna contendo 0s e 1s que indicam se um voo teve origem no aeroporto que a coluna representa. A coluna DEST precisa ser tratada de maneira semelhante.
Neste exercício, você "agrupará" os horários de partida na coluna CRS_DEP_TIME e usará o método get_dummies do Pandas para criar colunas indicadoras a partir das colunas ORIGIN e DEST.
Use o seguinte comando para exibir as primeiras cinco linhas do DataFrame:
df.head()Observe que a coluna CRS_DEP_TIME contém valores de 0 a 2359 representando horários em formato de 24 horas.
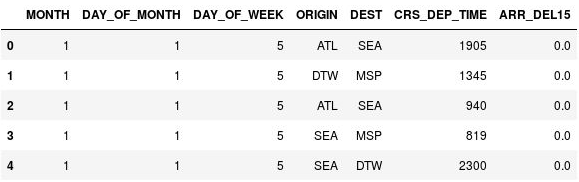
O DataFrame com horários de partida não compartimentalizados
Use as seguintes instruções para compartimentalizar os horários de partida:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Confirme que os números na coluna CRS_DEP_TIME agora estão no intervalo 0 a 23:
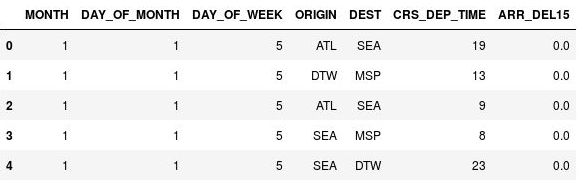
O DataFrame com horários de partida compartimentalizados
Agora, use as seguintes instruções para gerar colunas de indicador com base nas colunas ORIGIN e DEST, removendo as próprias colunas ORIGIN e DEST:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Examine o DataFrame resultante e observe que as colunas ORIGIN e DEST foram substituídas por colunas correspondentes para os códigos de aeroporto presentes nas colunas originais. As novas colunas têm 1s e 0s que indicam se um determinado voo teve origem no ou foi destinado ao aeroporto correspondente.
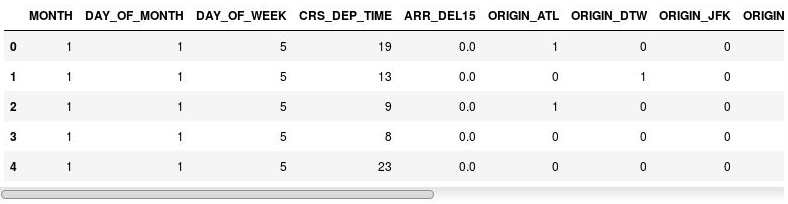
O DataFrame com colunas de indicador
Use o comando Arquivo ->Salvar e Ponto de Verificação para salvar o notebook.
O conjunto de dados tem uma aparência muito diferente do que tinha inicialmente, mas agora ele está otimizado para uso no aprendizado de máquina.