Introdução ao Visão de IA do Azure
A capacidade dos sistemas de computação de processar textos escritos e impressos é uma área da IA em que a pesquisa visual computacional se cruza com o processamento de linguagem natural. As funcionalidades do Visão são necessárias para "leitura" do texto e, em seguida, as funcionalidades de processamento de linguagem natural dão sentido a ele.
O OCR é a base do processamento de textos em imagens e usa modelos de machine learning treinados para reconhecer formas individuais como letras, numerais, sinais de pontuação ou outros elementos de texto. Grande parte do trabalho inicial na implementação desse tipo de funcionalidade foi realizada pelos serviços de correios para dar ajudar na classificação automática de correspondências com base em CEPs. Desde então, a tecnologia de última geração para a leitura de texto avançou e já temos modelos que detectam textos impressos ou manuscritos em uma imagem e leem-nos linha por linha e palavra por palavra.

Mecanismo OCR da Visão de IA do Azure
O serviço Visão de IA do Azure tem a capacidade de extrair textos legíveis por computador de imagens. A API de Leitura da Visão de IA do Azure é o mecanismo OCR por trás da extração de texto de imagens, PDFs e arquivos TIFF. O OCR para imagens é otimizado para imagens gerais e não documentais que facilitam a inserção do OCR nos seus cenários de experiência do usuário.
A API de Leitura, também conhecida como mecanismo OCR de Leitura, usa os modelos de reconhecimento mais recentes e é otimizada para imagens que têm uma quantidade significativa de texto ou um ruído visual considerável. Ela pode determinar automaticamente o modelo de reconhecimento adequado a ser usado levando em consideração o número de linhas de texto, imagens que incluem texto e manuscrito.
O mecanismo OCR usa um arquivo de imagem e identifica as caixas delimitadoras, ou coordenadas, em que os itens estão localizados em uma imagem. No OCR, o modelo identifica as caixas delimitadoras em torno de qualquer coisa que pareça ser um texto na imagem.
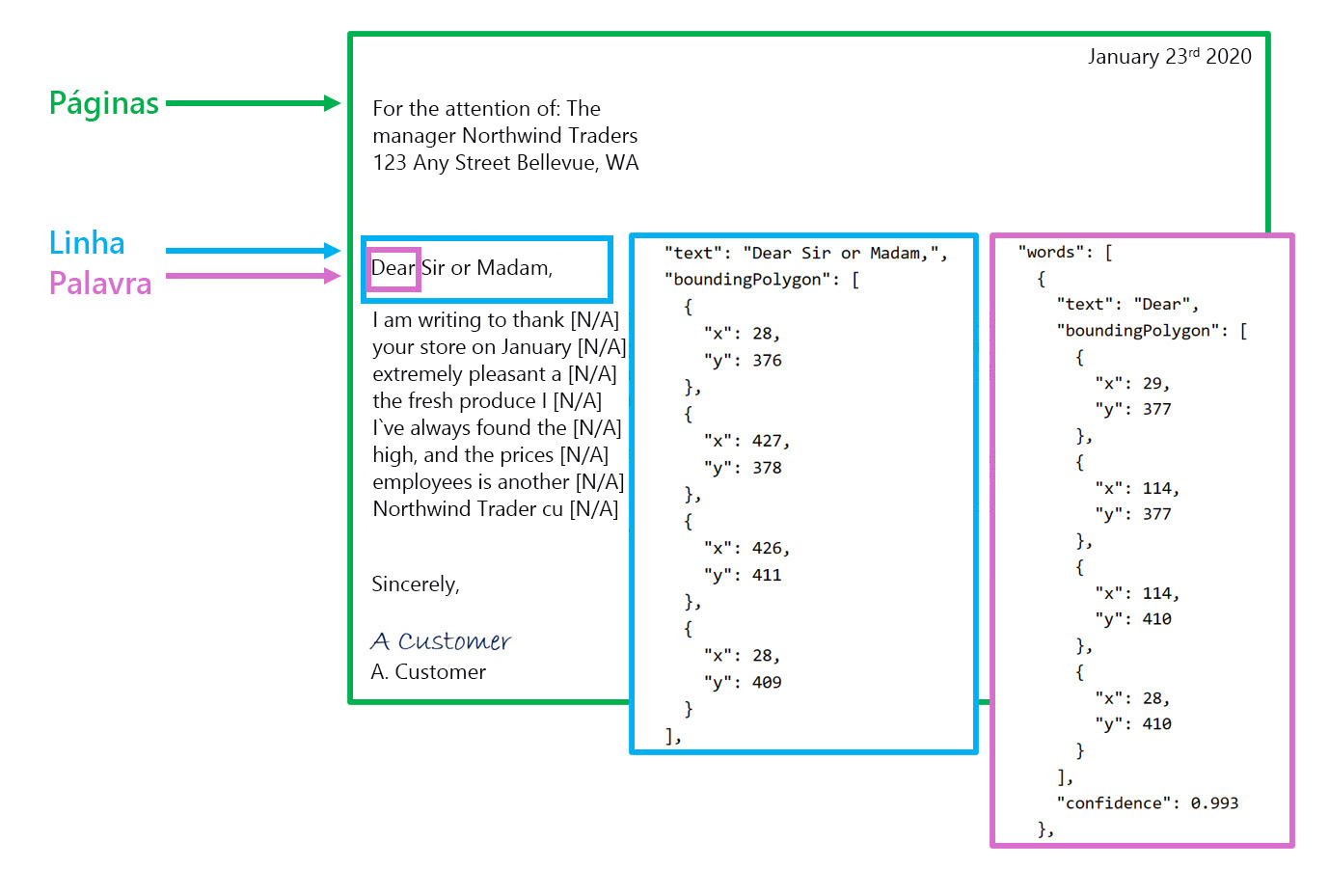
Chamar a API de Leitura retorna os resultados organizados na seguinte hierarquia:
- Páginas: uma para cada página de texto, incluindo informações sobre o tamanho e a orientação da página.
- Linhas: as linhas de texto em uma página.
- Palavras - As palavras em uma linha de texto, incluindo as coordenadas da caixa delimitadora e o próprio texto.
Cada linha e palavra inclui coordenadas de caixa delimitadora indicando sua posição na página.