Redes neurais convolucionais
Embora você possa usar modelos de aprendizado profundo para qualquer tipo de aprendizado de máquina, eles são particularmente úteis para lidar com dados que consistem em grandes matrizes de valores numéricos, como imagens. Os modelos de aprendizado de máquina que trabalham com imagens são a base para uma área da inteligência artificial chamada Pesquisa Visual Computacional, e técnicas de aprendizado profundo têm sido responsáveis por conduzir avanços surpreendentes nessa área nos últimos anos.
O motivo do sucesso do aprendizado profundo nessa área é um tipo de modelo chamado rede neural convolucional, ou CNN. Uma CNN normalmente funciona extraindo atributos de imagens e, em seguida, colocando-os em uma rede neural totalmente conectada para gerar uma previsão. As camadas de extração de atributos na rede reduzem o número de atributos da gigantesca gama possível de valores de pixel individuais para um conjunto de atributos menor que suporta a previsão de rótulos.
Camadas em uma CNN
As CNNs consistem em várias camadas que executam tarefas individuais específicas para a extração de atributos ou a previsão de rótulos.
Camadas de convolução
Um dos principais tipos de camadas é a convolucional, que extrai atributos importantes de imagens. A função de uma camada convolucional é aplicar um filtro às imagens. Esse filtro é definido por um kernel, que consiste em uma matriz de valores de peso.
Por exemplo, um filtro de 3x3 pode ser definido da seguinte maneira:
1 -1 1
-1 0 -1
1 -1 1
Uma imagem também é apenas uma matriz de valores de pixel. Para aplicar o filtro, você o "sobrepõe" em uma imagem e calcula uma soma ponderada dos valores de pixel da imagem correspondente no kernel de filtro. O resultado é atribuído em seguida à célula central de um patch de 3x3 equivalente em uma nova matriz de valores que tem o mesmo tamanho da imagem. Por exemplo, suponha que uma imagem 6x6 tenha os seguintes valores de pixel:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
A aplicação do filtro no patch de 3x3 na parte superior esquerda da imagem funcionaria desta forma:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
O resultado é atribuído ao valor de pixel correspondente na nova matriz, como a seguir:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Agora, o filtro é movido (convolucionado), normalmente com um tamanho de etapa de 1 (portanto, movendo-se um pixel para a direita), e o valor do próximo pixel é calculado
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Agora, é possível preencher o próximo valor da nova matriz.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
O processo se repete até que o filtro tenha sido aplicado em todos os patches de 3x3 da imagem para produzir uma nova matriz de valores, como a seguir:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Devido ao tamanho do kernel de filtro, não é possível calcular valores para os pixels na borda. Por isso, é normalmente aplicado um valor de preenchimento (geralmente 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
A saída da convolução é normalmente passada para uma função de ativação, que geralmente é uma função ReLU (unidade linear corrigida) e que garante que valores negativos sejam definidos como 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
A matriz resultante é um mapa de atributos de valores de atributo que podem ser usados para treinar um modelo de aprendizado de máquina.
Observação: os valores no mapa de atributos podem ser maiores que o valor máximo de um pixel (255), portanto, para visualizá-lo como uma imagem, é preciso normalizar os valores de atributo entre 0 e 255.
O processo de convolução é mostrado na animação abaixo.

- Uma imagem é passada para a camada convolucional. Nesse caso, uma forma geométrica simples.
- A imagem é composta de uma matriz de pixels com valores entre 0 e 255 (para imagens coloridas, é geralmente uma matriz tridimensional com valores para canais vermelho, verde e azul).
- Um kernel de filtro geralmente é inicializado com pesos aleatórios (neste exemplo, foram escolhidos valores para realçar o efeito possível de um filtro em valores de pixel; mas em uma CNN real, os pesos iniciais normalmente seriam gerados por uma distribuição gaussiana aleatória). Esse filtro será usado para extrair um mapa de atributos dos dados da imagem.
- O filtro é convolucionado pela imagem, calculando valores de atributo através da aplicação de uma soma dos pesos multiplicados por seus valores de pixel correspondentes em cada posição. Uma função de ativação ReLU (unidade linear corrigida) é aplicada para garantir que os valores negativos sejam definidos como 0.
- Após a convolução, o mapa de atributos contém os valores de atributo extraídos, que geralmente enfatizam os principais atributos visuais da imagem. Nesse caso, o mapa de atributos realça as bordas e os cantos do triângulo na imagem.
Normalmente, uma camada convolucional aplica diversos kernels de filtro. Cada filtro produz um mapa de atributos diferente e todos os mapas são passados para a próxima camada da rede.
Camadas de pooling
Depois de extrair os valores de atributo das imagens, as camadas de pooling (ou de redução) são usadas para reduzir seu número, mantendo os principais atributos de diferenciação extraídos.
Um dos tipos mais comuns de pooling é o pooling máximo, em que um filtro é aplicado à imagem e apenas o valor máximo de pixel na área do filtro é mantido. Portanto, a aplicação de um kernel de pooling de 2x2 no seguinte patch de uma imagem produziria, por exemplo, o resultado 155.
0 0
0 155
Observe que o filtro de pooling de 2x2 reduz o número de valores de 4 para 1.
Como nas camadas convolucionais, a função das camadas de pooling é aplicar o filtro a todo o mapa de atributos. A animação abaixo mostra um exemplo de pooling máximo para um mapa de imagem.

- O mapa de atributos extraído por um filtro em uma camada convolucional contém uma matriz de valores de atributo.
- Um kernel de pooling é usado para reduzir o número desses valores. Nesse caso, o tamanho do kernel é de 2x2, portanto, ele produzirá uma matriz com um quarto do número de valores de atributo.
- O kernel de pooling é convolucionado pelo mapa de atributos e mantém apenas o valor de pixel mais alto em cada posição.
Camadas de remoção
Um dos desafios mais difíceis em uma CNN é evitar o sobreajuste, em que o modelo resultante funciona bem com os dados de treinamento, mas não é bem generalizado para novos dados nos quais não foi treinado. Uma técnica possível para reduzir o sobreajuste é a inclusão de camadas nas quais o processo de treinamento elimina (ou "remove") aleatoriamente mapas de atributos. Isso pode parecer contraintuitivo, mas é uma maneira eficaz de garantir que o modelo não aprenda a depender excessivamente das imagens de treinamento.
Outras técnicas possíveis para reduzir o sobreajuste incluem o giro aleatório, o espelhamento ou a distorção das imagens de treinamento para gerar dados que variam entre as épocas de treinamento.
Camadas de mesclagem
Depois de usar camadas convolucionais e de pooling para extrair os principais atributos das imagens, os mapas de atributos resultantes são matrizes multidimensionais de valores de pixel. Uma camada de mesclagem é usada para mesclar os mapas de atributos em um vetor de valores que pode ser usado como entrada para uma camada totalmente conectada.
Camadas totalmente conectadas
Normalmente, o resultado de uma CNN é uma rede totalmente conectada na qual os valores de atributos são passados para uma camada de entrada através de uma ou mais camadas ocultas e geram valores previstos em uma camada de saída.
Uma arquitetura básica de CNN pode ser semelhante a esta:
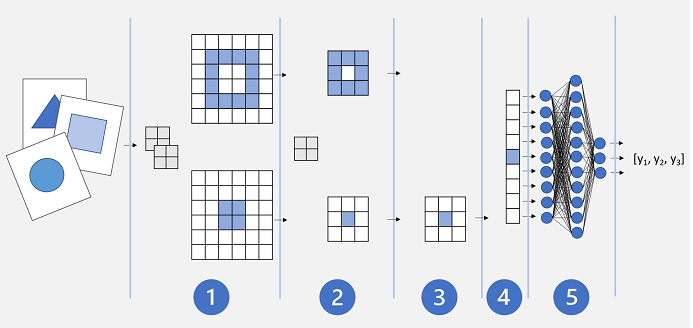
- As imagens são colocadas em uma camada convolucional. Nesse caso, há dois filtros, de modo que cada imagem produz dois mapas de atributos.
- Os mapas de atributos são passados para uma camada de pooling para que seu tamanho seja reduzido por um kernel de pooling de 2x2.
- Uma camada de remoção remove aleatoriamente alguns dos mapas de atributos para ajudar a evitar o sobreajuste.
- Uma camada de mesclagem mescla as matrizes restantes do mapa de atributos em um vetor.
- Os elementos do vetor são colocados em uma rede totalmente conectada, o que gera as previsões. Nesse caso, a rede é um modelo de classificação que prevê probabilidades para três classes de imagem possíveis (triângulo, quadrado e círculo).
Treinando um modelo de CNN
Como em qualquer rede neural profunda, uma CNN é treinada passando lotes de dados de treinamento por ela durante várias épocas e ajustando os valores de peso e desvio com base na perda calculada para cada época. No caso de uma CNN, a retropropagação de pesos ajustados inclui os pesos do kernel de filtro usados nas camadas convolucionais e os pesos usados nas camadas totalmente conectadas.