Visualizar dados
Um dos modos mais intuitivos de analisar os resultados das consultas de dados é visualizá-los como gráficos. Os notebooks no Azure Databricks fornecem recursos de gráfico na interface do usuário e, quando essa funcionalidade não fornece o que você precisa, você pode usar uma das muitas bibliotecas gráficas do Python para criar e exibir visualizações de dados no notebook.
Como usar gráficos integrados em notebooks
Quando você exibe um dataframe ou executa uma consulta SQL em um notebook Spark no Azure Databricks, os resultados são exibidos na célula de código. Por padrão, os resultados são renderizados como uma tabela, mas você também pode exibir os resultados como uma visualização e personalizar como o gráfico exibe os dados, conforme mostrado aqui:
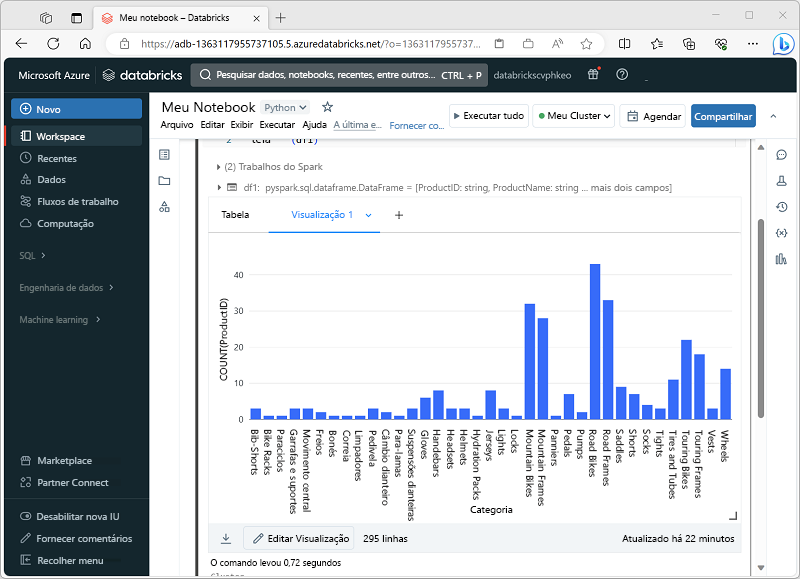
Tipos de visualização
Esses são os diferentes tipos de visualizações que você pode fazer no Databricks, cada uma boa para determinados tipos de insights de dados. Pontos principais:
Gráficos de barras/ Gráficos de linhas/Gráficos de área: para mostrar tendências ao longo do tempo, comparações categóricas ou ambas. Útil para ver como as métricas evoluem.
Gráficos de Pizza: bom para mostrar as partes proporcionais de um todo (mas não para série temporal).
Histograma: para ver a distribuição de dados numéricos (como os valores são distribuídos, clusterizados).
Mapa de calor: útil para visualizar dois eixos categóricos e colorir por um valor numérico, ajuda a identificar padrões através de grupos.
Gráficos de dispersão/bolha: mostrar relação entre duas (ou mais) variáveis numéricas; as bolhas permitem usar o tamanho ou a cor como uma terceira dimensão.
Diagrama de caixa: para comparar as distribuições (dispersão, quartis, valores atípicos) entre categorias.
Gráfico de combinação: combinação de linhas e barras no mesmo gráfico, útil em que você deseja comparar diferentes métricas com escalas diferentes.
Tabela dinâmica: permite remodelar e agregar dados no formato de tabela (como SQL PIVOT/GROUP BY), útil para análises cruzadas.
Tipos especiais: análise de coorte (grupos de acompanhamento ao longo do tempo), exibição de contador (realçando uma única métrica de resumo, talvez em relação ao destino), funil, visualizações de mapa (coroplético, marcador), nuvem de palavras, etc. Esses são mais especializados.
A funcionalidade de visualização interna em notebooks é útil quando você deseja resumir rapidamente os dados visualmente. Quando você quiser ter mais controle sobre como os dados são formatados ou exibir valores que você já agregaram em uma consulta, considere usar um pacote gráfico para criar suas próprias visualizações.
Usando pacotes gráficos no código
Há muitos pacotes gráficos que você pode usar para criar visualizações de dados no código. Em particular, o Python dá suporte a uma grande seleção de pacotes; a maioria criada na biblioteca base Matplotlib. A saída de uma biblioteca de gráficos pode ser renderizada em um notebook, facilitando a combinação de código para ingerir e manipular dados com visualizações de dados embutidas e células de markdown para fornecer comentários.
Por exemplo, você pode usar o código PySpark a seguir para agregar dados dos dados de produtos hipotéticos explorados anteriormente neste módulo e usar Matplotlib para criar um gráfico com base nos dados agregados.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
A biblioteca Matplotlib requer que os dados estejam em um dataframe do Pandas, em vez de um dataframe do Spark, de modo que o método toPandas é usado para conversão. Em seguida, o código cria uma figura com um tamanho especificado e plota um gráfico de barras com alguma configuração de propriedade personalizada antes de mostrar o gráfico resultante.
O gráfico produzido pelo código seria semelhante à seguinte imagem:
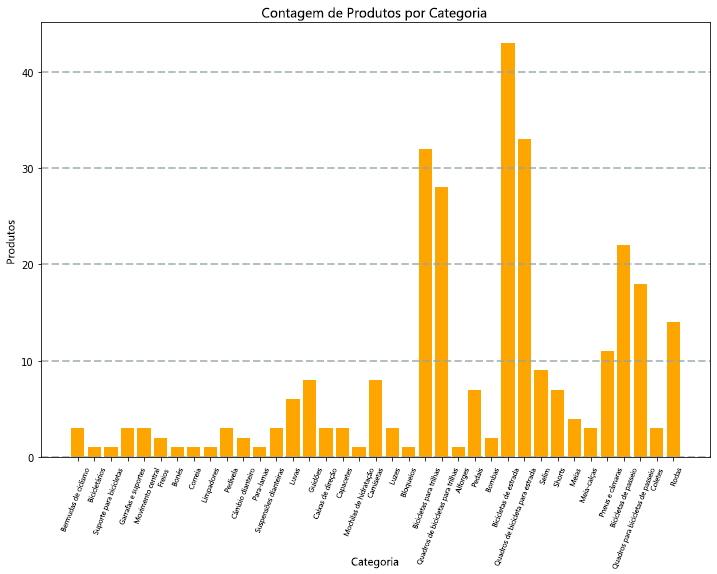
Você pode usar a biblioteca Matplotlib para criar muitos tipos de gráfico; se preferir, você pode usar outras bibliotecas, como Seaborn, para criar gráficos altamente personalizados.
Observação
As bibliotecas Matplotlib e Seaborn já podem estar instaladas em clusters do Databricks, dependendo do Databricks Runtime para o cluster. Caso contrário, ou se você quiser usar uma biblioteca diferente que ainda não esteja instalada, poderá adicioná-la ao cluster. Consulte bibliotecas de cluster na documentação do Azure Databricks para obter detalhes.