Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Para obter uma introdução ao WebNN, incluindo informações sobre suporte ao sistema operacional, suporte a modelos e muito mais, visite a Visão geral da WebNN.
Este tutorial mostrará como usar o WebNN com o ONNX Runtime Web para criar um sistema de classificação de imagens na Web que seja acelerado por hardware usando a GPU no dispositivo. Aproveitaremos o modelo MobileNetV2 , que é um modelo de software livre no Hugging Face usado para classificar imagens.
Se você quiser exibir e executar o código final deste tutorial, poderá encontrá-lo em nosso GitHub de Visualização do Desenvolvedor da WebNN.
Observação
A API WebNN é uma Recomendação de Candidato do W3C e está em estágios iniciais de uma versão prévia do desenvolvedor. Algumas funcionalidades são limitadas. Temos uma lista do status atual de suporte e implementação.
Requisitos e configuração:
Configurando o Windows
Verifique se você tem as versões corretas do Edge, do Windows e dos drivers de hardware, conforme detalhado na seção Requisitos da WebNN.
Configurando o Edge
Baixe e instale o Microsoft Edge Dev.
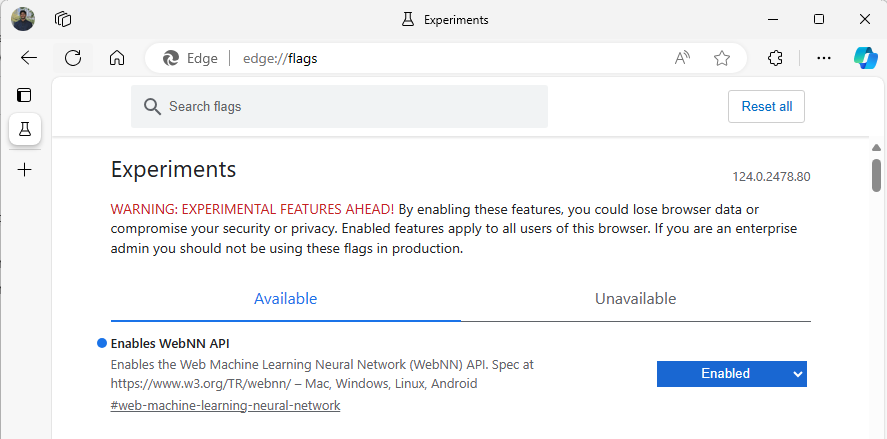
Inicie o Edge Beta e, na barra de endereços, navegue até
about:flags.Pesquise por "API WebNN", clique na lista suspensa e defina como "Habilitado".
Reinicie o Edge, conforme solicitado.
Configurando o ambiente do desenvolvedor
Baixe e instale o VSCode (Visual Studio Code).
Inicie o VSCode.
Baixe e instale a extensão do Live Server para VSCode no VSCode.
Selecione
File --> Open Foldere crie uma pasta em branco no local desejado.
Etapa 1: inicializar o aplicativo Web
- Para começar, crie uma nova
index.htmlpágina. Adicione o seguinte código clichê à nova página:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Verifique se o código clichê e a configuração do desenvolvedor funcionaram selecionando o botão Go Live no lado inferior direito do VSCode. Isso deve iniciar um servidor local no Edge Beta executando o código clichê.
- Agora, crie um novo arquivo chamado
main.js. Isso conterá o código javascript para seu aplicativo. - Em seguida, crie uma subpasta do diretório raiz chamada
images. Baixe e salve qualquer imagem dentro da pasta. Para essa demonstração, usaremos o nome padrão deimage.jpg. - Baixe o modelo de mobilenet do ONNX Model Zoo. Para este tutorial, você usará o arquivo mobilenet2-10.onnx . Salve esse modelo na pasta raiz do aplicativo Web.
- Por fim, baixe e salve este arquivo de classes de imagem.
imagenetClasses.jsIsso fornece 1.000 classificações comuns de imagens para seu modelo usar.
Etapa 2: Adicionar elementos da interface do usuário (UI) e função parente
- Dentro do corpo das
<main>marcas html que você adicionou na etapa anterior, substitua o código existente pelos seguintes elementos. Eles criarão um botão e exibirão uma imagem padrão.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- Agora, você adicionará o ONNX Runtime Web à sua página, que é uma biblioteca JavaScript que você usará para acessar a API WebNN. Dentro do corpo das
<head>etiquetas html, adicione os seguintes links de origem do javascript.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
- Abra o
main.jsarquivo e adicione o snippet de código a seguir.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Etapa 3: Pré-processar dados
- A função que você acabou de adicionar chama
getImageTensorFromPath, outra função que você precisa implementar. Você a adicionará abaixo, bem como outra função assíncrona que ele chama para recuperar a imagem em si.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- Você também precisa adicionar a
imageDataToTensorfunção referenciada acima, que renderizará a imagem carregada em um formato tensor que funcionará com nosso modelo ONNX. Essa é uma função mais envolvida, embora possa parecer familiar se você já trabalhou com aplicativos de classificação de imagem semelhantes antes. Para obter uma explicação estendida, você pode exibir este tutorial do ONNX.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Etapa 4: Chamar o ONNX Runtime Web
- Agora você adicionou todas as funções necessárias para recuperar sua imagem e renderizá-la como um tensor. Agora, usando a biblioteca Web do ONNX Runtime que você carregou acima, você executará seu modelo. Observe que, para usar o WebNN aqui, basta especificar
executionProvider = "webnn": o suporte do ONNX Runtime torna muito simples habilitar o WebNN.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
// Uncomment for additional information in debug builds:
// ort.env.wasm.proxy = true;
// ort.env.logLevel = "verbose";
// ort.env.debug = true;
// Configure WebNN.
const modelPath = "./mobilenetv2-10.onnx";
const devicePreference = "gpu"; // Other options include "npu" and "cpu".
const options = {
executionProviders: [{ name: "webnn", deviceType: devicePreference, powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
// The key names in freeDimensionOverrides should map to the real input dim names in the model.
// For example, if a model's only key is batch_size, you only need to set
// freeDimensionOverrides: {"batch_size": 1}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Etapa 5: Dados pós-processo
- Por fim, você adicionará uma função
softmaxe adicionará sua função final para retornar a classificação de imagem mais provável. Transformasoftmaxseus valores entre 0 e 1, que é a forma de probabilidade necessária para essa classificação final.
Primeiro, adicione os seguintes arquivos de origem para bibliotecas auxiliares Jimp e Lodash na marca de anotação de main.js.
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
Agora, adicione essas funções a seguir a main.js.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- Agora você adicionou todos os scripts necessários para executar a classificação de imagens com WebNN em seu aplicativo Web básico. Usando a extensão do Live Server para VS Code, agora você pode iniciar sua página da Web básica no aplicativo para ver os resultados da classificação por conta própria.