Guia do desenvolvedor de Copilot+ PCs
Os Copilot+ PCs são uma nova classe de hardware do Windows 11 alimentada por uma Unidade de Processamento Neural (NPU) de alto desempenho — um chip de computador especializado para processos intensivos em IA, como traduções em tempo real e geração de imagens — que pode executar mais de 40 trilhões de operações por segundo (TOPS). Os Copilot+ PCs fornecem duração da bateria para um dia inteiro e acesso aos recursos e modelos de IA mais avançados. Saiba mais em Introdução aos Copilot+ PCs – O Blog Oficial da Microsoft.
A seguinte Orientação para Desenvolvedores do Copilot+ PC abrange:
- Pré-requisitos do dispositivo
- O que é o chip Snapdragon Elite X+ baseado em Arm?
- Recursos exclusivos de IA suportados por Copilot+ PCs com processador NPU
- Como acessar a NPU em um Copilot+ PC
- Como usar o ONNX Runtime para acessar programaticamente a NPU em um Copilot+ PC
- Como medir o desempenho de modelos de IA executados localmente na NPU do dispositivo
Esta orientação é específica para Copilot+ PCs.
Muitos dos novos recursos de IA do Windows exigem uma NPU com a capacidade de executar 40+ TOPS, incluindo, entre outros:
- Dispositivos Qualcomm Snapdragon X Elite baseados em Arm
- Dispositivos Intel Lunar Lake -- Em breve
- Dispositivos AMD STRIX (Ryzen AI 9) -- Em breve
O novo chip Snapdragon X Elite baseado em Arm construído pela Qualcomm enfatiza a integração de IA por meio de sua Unidade de Processamento Neural (NPU) líder do setor. Essa NPU é capaz de processar grandes quantidades de dados em paralelo, realizando trilhões de operações por segundo, usando energia em tarefas de IA de forma mais eficiente do que uma CPU ou GPU, o que resulta em uma maior duração da bateria do dispositivo. A NPU funciona em alinhamento com a CPU e GPU. O Windows 11 atribui tarefas de processamento ao local mais apropriado para oferecer um desempenho rápido e eficiente. A NPU permite experiências inteligentes de IA no dispositivo com segurança de nível empresarial para proteção aprimorada do chip à nuvem.
- Saiba mais sobre o Qualcomm Snapdragon X Elite.
- Saiba mais sobre como usar e desenvolver para o Windows on Arm.
Os Copilot+ PCs oferecem experiências únicas de IA fornecidas com as versões modernas do Windows 11. Esses recursos de IA, projetados para serem executados na NPU do dispositivo, incluem:
Windows Studio Effects: um conjunto de efeitos de IA acelerados por NPU de áudio e vídeo da Microsoft, incluindo Filtro Criativo, Desfoque de Plano de Fundo, Contato Visual, Enquadramento Automático, Foco de Voz. Os desenvolvedores também podem adicionar alternâncias ao aplicativo para controles no nível do sistema. Lista de aprimoramentos de IA do Windows Studio Effects.
Recall: a API UserActivity com suporte a IA que permite que os usuários pesquisem interações anteriores usando linguagem natural e continuem de onde pararam. Disponível para Copilot+ PCs através do Programa Windows Insider (WIP). Saiba mais: Refaça suas etapas com o Recall
Phi Silica: o pequeno modelo de linguagem (SLM) Phi que permite que seu aplicativo se conecte ao modelo no dispositivo para tarefas de processamento de linguagem natural (chat, matemática, código, dissertação) usando uma versão futura do SDK do Aplicativo Windows.
Reconhecimento de Texto: a API de Reconhecimento Óptico de Caracteres (OCR) que permite a extração de texto de imagens e documentos. Imagine tarefas como converter um PDF, documento em papel ou imagem de um quadro branco da sala de aula em texto digital editável.
Cocriador com o Paint , um novo recurso no Microsoft Paint que transforma imagens em arte de IA.
Super Resolução: uma tecnologia de IA líder do setor que usa a NPU para fazer os jogos rodarem mais rápido e parecerem melhores.
*Nem todos os recursos podem estar disponíveis inicialmente em todos os Copilot+ PCs.
Importante
Os modelos de IA enviados nas versões mais recentes do Windows estarão disponíveis por meio de APIs no Windows Copilot Runtime anunciado na Compilação 2024. APIs para novos recursos de IA, como Phi Silica, são compatíveis com modelos otimizados para execução (inferência) na NPU e serão fornecidas em uma futura versão do SDK do Aplicativo Windows.
A Unidade de Processamento Neural (NPU) é um novo recurso de hardware. Assim como outros recursos de hardware em um PC, a NPU precisa que o software seja especificamente programado para aproveitar os benefícios que oferece. As NPUs são projetadas especificamente para executar as operações matemáticas de aprendizado profundo que compõem os modelos de IA.
Os recursos de IA do Windows 11 Copilot+ mencionados acima foram projetados especificamente para usufruir da NPU. Os usuários observarão uma maior duração da bateria e tempo de execução de inferência mais rápido para modelos de IA voltados para a NPU. O suporte do Windows 11 a NPUs incluirá dispositivos Qualcomm baseados em Arm, bem como dispositivos Intel e AMD (em breve).
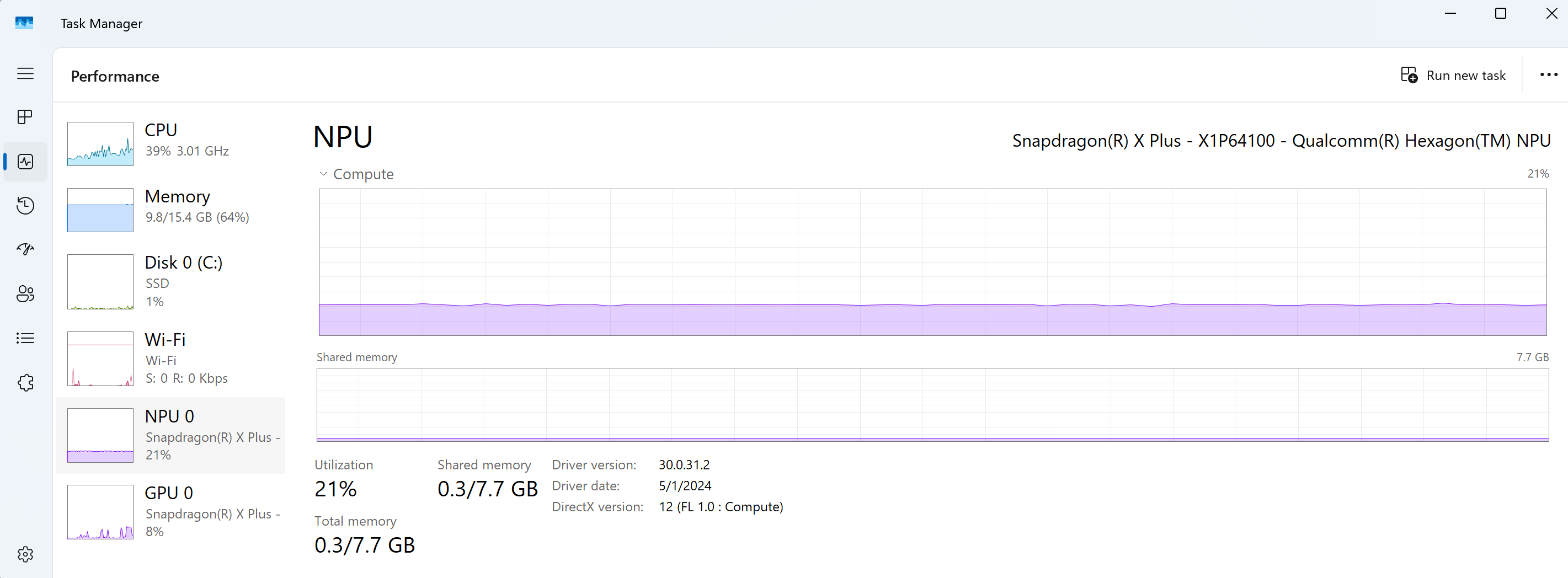
Para dispositivos com NPUs, o Gerenciador de Tarefas agora pode ser usado para exibir o uso de recursos da NPU.
A maneira recomendada de inferir (executar tarefas de IA) na NPU do dispositivo é usar o ONNX Runtime. O ONNX Runtime é uma pilha flexível e eficiente de programação para a NPU, bem como a GPU e a CPU, permitindo que você traga seus próprios modelos de IA ou use modelos de IA de código aberto encontrados na Web. Saiba mais sobre como usar o ONNX Runtime para acessar a NPU abaixo ou saiba mais sobre como usar modelos de machine learning em seu aplicativo do Windows.
Observação
Que tal usar outros runtimes para PyTorch ou Tensorflow? Outros runtimes para PyTorch, Tensorflow e outros tipos de SDK fornecidos pelo fornecedor do processador também são aceitos no Windows. No momento, é possível executar PyTorch, TensorFlow e outros tipos de modelo mediante a conversão para o formato ONNX flexível, mas o suporte nativo está chegando em breve.
A Microsoft fornece uma estrutura completa de inferência e treinamento de software livre chamada ONNX Runtime. O ONNX Runtime é a solução de código aberto recomendada da Microsoft para executar modelos de IA em uma NPU. Como o ONNX Runtime é flexível e oferece suporte a muitas opções diferentes para executar modelos de IA, as escolhas podem ser confusas. Este guia irá ajudar você a selecionar opções específicas para Windows Copilot+ PCs.
- Qualcomm Snapdragon X: no momento, os desenvolvedores devem ter como objetivo o Qualcomm QNN Execution Provider (EP), que usa o SDK Qualcomm AI Engine Direct (QNN). Pacotes pré-compilados com suporte ao QNN estão disponíveis para download. Esta é a mesma pilha usada atualmente pelo Windows Copilot Runtime e experiências em dispositivos Copilot+ PC Qualcomm. O suporte a DirectML e WebNN para NPUs Qualcomm Snapdragon X Elite foi anunciado na Compilação 2024 e estará disponível em breve.
- Dispositivos NPU Intel e AMD: dispositivos NPU adicionais estarão disponíveis no final de 2024. O DirectML é o método recomendado para esses dispositivos.
Os modelos de IA são frequentemente treinados e disponíveis em grandes formatos de dados, como FP32. Muitos dispositivos NPU, no entanto, só oferecem suporte à matemática de inteiros em formato de bit inferior, como INT8, para maior desempenho e eficiência energética. Portanto, os modelos de IA precisam ser convertidos (ou "quantizados") para serem executados na NPU. Existem muitos modelos disponíveis que já foram convertidos em um formato pronto para uso. Você também pode trazer seu próprio modelo (BYOM) para converter ou otimizar.
- Qualcomm AI Hub (Compute): a Qualcomm fornece modelos de IA que já foram validados para uso em Copilot+ PCs com Snapdragon X Elite com os modelos disponíveis especificamente otimizados para rodar de forma eficiente nesta NPU. Saiba mais: Acelerar a implantação de modelos com o Qualcomm AI Hub | Compilação 2024 da Microsoft.
- ONNX Model Zoo: este repositório de código aberto oferece uma coleção curada de modelos pré-treinados e de última geração no formato ONNX. Esses modelos são recomendados para uso com NPUs em todos os Copilot+ PCs, incluindo dispositivos Intel e AMD (em breve).
Para aqueles que querem trazer seu próprio modelo, recomendamos usar a ferramenta de otimização de modelo com reconhecimento de hardware, Olive. O Olive pode ajudar com compactação, otimização e compilação de modelos para trabalhar com o ONNX Runtime como uma solução de otimização de desempenho de NPU. Saiba mais: IA facilitada: como o ONNX Runtime e a cadeia de ferramentas Olive ajudarão você a fazer perguntas e respostas | Compilação 2023.
Para medir o desempenho da integração de recursos de IA em seu aplicativo e os tempos de execução do modelo de IA associado:
Registrar um rastreamento: o registro da atividade do dispositivo durante um período de tempo é conhecido como rastreamento do sistema. O rastreamento do sistema produz um "arquivo de rastreamento" que pode ser usado para gerar um relatório e ajudar você a identificar como melhorar o desempenho do aplicativo. Saiba mais: Capturar um rastreamento do sistema para analisar o uso de memória.
Exibir o uso da NPU: examine quais processos estão usando a NPU e as pilhas de chamadas que enviam trabalhos.
Exibir trabalho e pilhas de chamadas na CPU: examine os resultados dos modelos de IA de alimentação pré-trabalho e modelos de IA de processamento pós-trabalho.
Load and Runtime: examine o período de tempo para carregar um modelo de IA e criar uma sessão do ONNX Runtime.
Parâmetros de tempo de execução: examine a configuração do ONNX Runtime e os parâmetros do Provedor de Execução (EP) que afetam o desempenho e a otimização do tempo de execução do modelo.
Tempos de inferência individuais: acompanhe os tempos por inferência e os subdetalhes da NPU.
Profiler: operações de modelo de IA de perfil para ver quanto tempo cada operador levou para contribuir para o tempo total de inferência.
Específico da NPU: examine os subdetalhes da NPU, como métricas de sub-HW, largura de banda da memória e muito mais.
Para realizar essas medições, recomendamos as seguintes ferramentas de diagnóstico e rastreamento:
- Gerenciador de Tarefas: permite que um usuário exiba o desempenho do Sistema Operacional Windows instalado em seu dispositivo, incluindo Processos, Desempenho, Histórico de aplicativos, Aplicativos de inicialização, Usuários, Detalhes e Serviços. Os dados de desempenho em tempo real serão mostrados para a CPU, memória, disco de armazenamento, Wi-Fi, GPU... e agora NPU do seu dispositivo. Os dados incluem a porcentagem de utilização, memória disponível, memória compartilhada, versão do driver, localização física e muito mais.
- Windows Performance Recorder (WPR): o WPR agora é fornecido com um perfil de Processamento Neural para registrar a atividade da NPU. Ele registra as interações do Microsoft Compute Driver Model (MCDM) com a NPU. Os desenvolvedores agora podem ver o uso da NPU, quais processos estão usando a NPU e as pilhas de chamadas que enviam trabalhos.
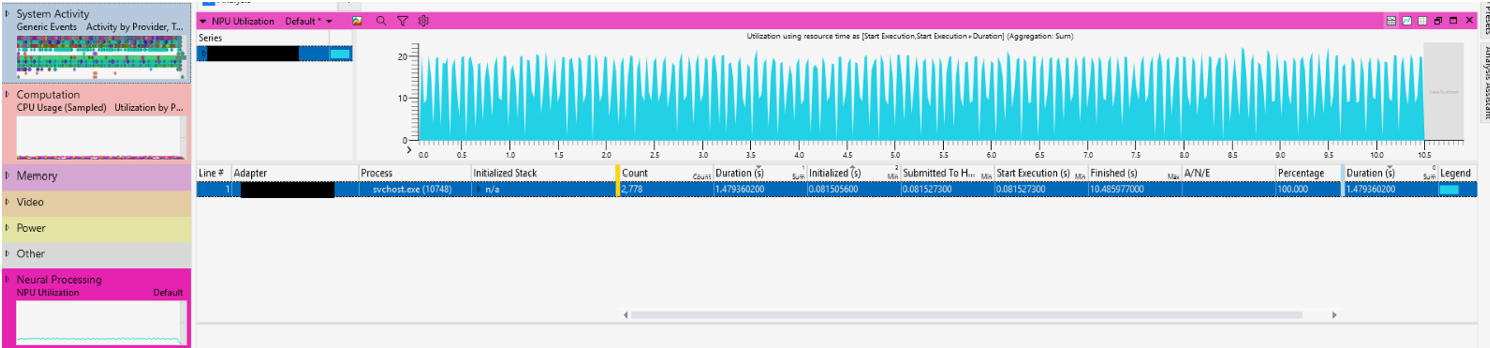
- Windows Performance Analyzer (WPA): o WPA cria gráficos e tabelas de dados de eventos do ETW (Rastreamento de Eventos para Windows) que são registrados pelo WPR (Windows Performance Recorder), Xperf ou uma avaliação executada na Plataforma de Avaliação. Ele fornece pontos de acesso convenientes para analisar a CPU, Disco, Rede, Eventos do ONNX Runtime... e uma nova tabela para análise de NPU, tudo em uma única linha do tempo. O WPA agora pode exibir o trabalho e as pilhas de chamadas na CPU relacionados ao pré-trabalho alimentando os modelos de IA e pós-trabalho processando os resultados do modelo de IA. Baixe o Windows Performance Analyzer na Microsoft Store.
- GPUView: o GPUView é uma ferramenta de desenvolvimento que lê os eventos de vídeo e kernel registrados em um arquivo de log de rastreamento de eventos (.etl) e apresenta os dados graficamente para o usuário. Essa ferramenta agora inclui operações de GPU e NPU, bem como suporte à exibição de eventos DirectX para dispositivos MCDM, como a NPU.
- Eventos do ONNX Runtime no Windows Performance Analyzer: a partir do ONNX Runtime 1.17 (e aprimorado no 1.18.1), os seguintes casos de uso estão disponíveis com eventos emitidos no Runtime:
- Veja quanto tempo foi necessário para carregar um modelo de IA e criar uma sessão do ONNX Runtime.
- Verifique a configuração do ONNX Runtime e os parâmetros do Provedor de Execução (EP) que afetam o desempenho e a otimização do tempo de execução do modelo.
- Acompanhe os tempos por inferência e os subdetalhes da NPU (QNN).
- Crie perfils das operações de modelo de IA para ver quanto tempo cada operador levou para contribuir para o tempo total de inferência.
- Saiba mais sobre a Criação de perfiis do Provedor de Execução (EP) do ONNX Runtime.
Observação
A WPR UI (a interface do usuário disponível para oferecer suporte ao WPR baseado em linha de comando incluído no Windows), WPA e GPUView fazem parte do Windows Performance Toolkit (WPT), versão de maio de 2024+. Para usar o WPT, você precisará: Baixar o Kit de Ferramentas do Windows ADK.
Para obter um início rápido sobre a exibição de eventos do ONNX Runtime com o Windows Performance Analyzer (WPA), execute estas etapas:
Baixe os arquivos ort.wprp e etw_provider.wprp.
Abra sua linha de comando e insira:
wpr -start ort.wprp -start etw_provider.wprp -start NeuralProcessing -start CPU echo Repro the issue allowing ONNX to run wpr -stop onnx_NPU.etl -compressCombine os perfis do Windows Performance Recorder (WPR) com outros perfis de gravação internos, como CPU, disco, etc.
Baixe o Windows Performance Analyzer (WPA) da Microsoft Store.
Abra o arquivo
onnx_NPU.etlno WPA. Clique duas vezes para abrir estes gráficos:- "Processamento Neural -> Utilização da NPU
- Eventos genéricos para eventos do ONNX
Outras ferramentas de medição de desempenho a serem consideradas além das ferramentas do Microsoft Windows listadas acima incluem:
- Qualcomm Snapdragon Profiler (qprof): uma ferramenta de criação de perfis de desempenho com GUI que abrange todo o sistema e foi desenvolvida para exibir o desempenho do sistema, bem como identificar oportunidades de melhoria de otimização e dimensionamento de aplicativos em CPUs SoC Qualcomm, GPUs, DSPs e outros blocos de IP. O Snapdragon Profiler permite exibir subdetalhes da NPU, como métricas sub-HW, largura de banda de memória e muito mais.