Introdução ao Namespace do Shell
O namespace Shell organiza o sistema de arquivos e outros objetos gerenciados pelo Shell em uma única hierarquia estruturada em árvore. Conceitualmente, é uma versão maior e mais inclusiva do sistema de arquivos.
Introdução
Uma das principais responsabilidades do Shell é gerenciar e fornecer acesso à ampla variedade de objetos que compõem o sistema. Os mais numerosos e familiares desses objetos são as pastas e os arquivos que residem em unidades de disco do computador. No entanto, o Shell gerencia um número de sistemas não arquivos ou objetos virtuais também. Alguns exemplos incluem:
- Impressoras de rede
- Outros computadores em rede
- Painel de Controle aplicativos
- A Lixeira
Alguns objetos virtuais não envolvem armazenamento físico. O objeto de impressora, por exemplo, contém uma coleção de links para impressoras em rede. Outros objetos virtuais, como a Lixeira, podem conter dados armazenados em uma unidade de disco, mas precisam ser tratados de maneira diferente dos arquivos normais. Por exemplo, um objeto virtual pode ser usado para representar dados armazenados em um banco de dados. Em termos de namespace, os vários itens no banco de dados podem aparecer no Windows Explorer como objetos separados, mesmo que todos estejam armazenados em um único arquivo de disco.
Objetos virtuais podem até estar localizados em computadores remotos. Por exemplo, para facilitar o roaming, os arquivos de documento de um usuário podem ser armazenados em um servidor. Para dar aos usuários acesso aos arquivos de vários computadores desktop, a pasta Meus Documentos no computador desktop que eles estão usando no momento apontará para o servidor, não para o disco rígido do computador desktop. Seu caminho incluirá uma unidade de rede mapeada ou um nome de caminho UNC.
Assim como o sistema de arquivos, o namespace inclui dois tipos básicos de objeto: pastas e arquivos. Os objetos folder são os nós da árvore; são contêineres para objetos de arquivo e outras pastas. Objetos de arquivo são as folhas da árvore; são arquivos de disco normais ou objetos virtuais, como links de impressora. As pastas que não fazem parte do sistema de arquivos às vezes são chamadas de pastas virtuais.
Assim como as pastas do sistema de arquivos, a coleção de pastas virtuais geralmente varia de sistema para sistema. Há três classes de pastas virtuais:
- Pastas virtuais padrão, como a Lixeira, encontradas em todos os sistemas.
- Pastas virtuais opcionais que têm nomes e funcionalidades padrão, mas podem não estar presentes em todos os sistemas.
- Pastas não padrão instaladas pelo usuário.
Ao contrário das pastas do sistema de arquivos, os usuários não podem criar novas pastas virtuais por conta própria. Eles só podem instalar os criados por desenvolvedores que não são da Microsoft. O número de pastas virtuais normalmente é muito menor do que o número de pastas do sistema de arquivos. Para obter uma discussão sobre como implementar pastas virtuais, consulte Extensões de namespace.
Você pode ver uma representação visual de como o namespace é estruturado na Barra de Explorer do Windows Explorer. Por exemplo, a captura de tela a seguir do Windows Explorer mostra um namespace relativamente simples.
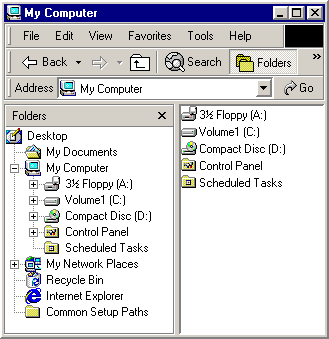
A raiz final da hierarquia de namespace é a área de trabalho. Imediatamente abaixo da raiz estão várias pastas virtuais, como Meu Computador e a Lixeira.
Os sistemas de arquivos das várias unidades de disco podem ser vistos como subconjuntos da hierarquia de namespace maior. As raízes desses sistemas de arquivos são subpastas da pasta Meu Computador. Meu Computador também inclui as raízes de todas as unidades de rede mapeadas. Outros nós na árvore, como Meus Documentos, são pastas virtuais.
Identificando objetos de namespace
Antes de usar um objeto de namespace, primeiro você deve ter uma maneira de identificá-lo. Um objeto no sistema de arquivos pode ter um nome como MyFile.htm. Como pode haver outros arquivos com esse nome em outro lugar no sistema, identificar exclusivamente um arquivo ou pasta requer um caminho totalmente qualificado, como "C:\MyDocs\MyFile.htm". Esse caminho é basicamente uma lista ordenada de todas as pastas em um caminho da raiz do sistema de arquivos, C:\, terminando com o arquivo .
No contexto do namespace, os caminhos ainda são bastante úteis para identificar objetos localizados na parte do sistema de arquivos do namespace. No entanto, eles não podem ser usados para objetos virtuais. Em vez disso, o Shell fornece um meio alternativo de identificação que pode ser usado com qualquer objeto de namespace.
Item IDs
Dentro de uma pasta, cada objeto tem uma ID de item, que é o equivalente funcional de um nome de arquivo ou pasta. A ID do item é, na verdade, uma estrutura SHITEMID :
typedef struct _SHITEMID {
USHORT cb;
BYTE abID[1];
} SHITEMID, * LPSHITEMID;
O membro abID é o identificador do objeto. O comprimento de abID não está definido e seu valor é determinado pela pasta que contém o objeto . Como não há uma definição padrão de como os valores abID são atribuídos por pastas, eles são significativos apenas para o objeto de pasta associado. Os aplicativos devem simplesmente tratá-los como um token que identifica um objeto em uma pasta específica. Como o comprimento de abID varia, o membro cb contém o tamanho da estrutura SHITEMID , em bytes.
Como as IDs de item não são úteis para fins de exibição, a pasta que contém o objeto normalmente atribui a ele um nome de exibição. Esse é o nome usado pelo Windows Explorer quando exibe o conteúdo de uma pasta. Para obter mais informações sobre como os nomes de exibição são tratados, consulte Obtendo informações de uma pasta.
Listas de IDs de Item
A ID do item raramente é usada por si só. Normalmente, ele faz parte de uma lista de IDs de item, que serve à mesma finalidade que um caminho do sistema de arquivos. No entanto, em vez da cadeia de caracteres usada para caminhos, uma lista de IDs de item é uma estrutura ITEMIDLIST . Essa estrutura é uma sequência ordenada de uma ou mais IDs de item, encerradas por um NULL de dois bytes. Cada ID de item na lista de IDs de item corresponde a um objeto de namespace. Sua ordem define um caminho no namespace, assim como um caminho do sistema de arquivos.
A ilustração a seguir mostra uma representação esquematica da estrutura ITEMIDLIST que corresponde a C:\MyDocs\MyFile.htm. O nome de exibição de cada ID de item é mostrado acima dele. As larguras variadas dos membros abID são arbitrárias; ilustram o fato de que o tamanho desse membro pode variar.

Pidls
Para a API do Shell, os objetos de namespace geralmente são identificados por um ponteiro para sua estrutura ITEMIDLIST ou ponteiro para uma PIDL (lista de identificadores de item). Para sua conveniência, o termo PIDL geralmente se referirá nesta documentação à própria estrutura, em vez do ponteiro para ela.
O PIDL mostrado na ilustração anterior é chamado de PIDL completo ou absoluto. Um PIDL completo começa na área de trabalho e contém as IDs de item de todas as pastas intermediárias no caminho. Ele termina com a ID do item do objeto seguida por um NULL de dois bytes de terminação. Um PIDL completo é semelhante a um caminho totalmente qualificado e identifica exclusivamente o objeto no namespace Shell.
PIDLs completos são usados com pouca frequência. Muitas funções e métodos esperam um PIDL relativo. A raiz de um PIDL relativo é uma pasta, não a área de trabalho. Assim como acontece com caminhos relativos, a série de IDs de item que compõem a estrutura define um caminho no namespace entre dois objetos. Embora não identifiquem exclusivamente o objeto, eles geralmente são menores que um PIDL completo e suficientes para muitas finalidades.
As PIDLs relativas mais usadas, PIDLs de nível único, são relativas à pasta pai do objeto. Eles contêm apenas a ID do item do objeto e um NULL de terminação. PIDLs de vários níveis também são usados para muitas finalidades. Elas contêm duas ou mais IDs de item e normalmente definem um caminho de uma pasta pai para um objeto por meio de uma série de uma ou mais subpastas. Observe que um PIDL de nível único ainda pode ser um PIDL totalmente qualificado. Em particular, os objetos da área de trabalho são filhos da área de trabalho, portanto, seus PIDLs totalmente qualificados contêm apenas uma ID de item.
Conforme discutido em Obtendo a ID de uma pasta, a API do Shell fornece várias maneiras de recuperar o PIDL de um objeto. Depois de tê-lo, você geralmente apenas o usa para identificar o objeto quando você chama outras funções e métodos da API do Shell. Nesse contexto, o conteúdo interno de um PIDL é opaco e irrelevante. Para fins dessa discussão, pense em PIDLs como tokens que representam objetos de namespace específicos e concentre-se em como usá-los para tarefas comuns.
Alocando PIDLs
Embora os PIDLs tenham alguma semelhança com caminhos, usá-los requer uma abordagem um pouco diferente. A principal diferença é como alocar e desalocar memória para eles.
Como a cadeia de caracteres usada para um caminho, a memória deve ser alocada para um PIDL. Se um aplicativo criar um PIDL, ele deverá alocar memória suficiente para a estrutura ITEMIDLIST . Para a maioria dos casos discutidos aqui, o Shell cria o PIDL e lida com a alocação de memória. Independentemente do que alocou o PIDL, o aplicativo geralmente é responsável por desalocar o PIDL quando ele não é mais necessário.
Use a função CoTaskMemAlloc para alocar o PIDL e a função CoTaskMemFree para desalocá-la.