CPUSets para desenvolvimento de jogos
Introdução
A Plataforma Universal do Windows (UWP) está no centro de uma ampla variedade de dispositivos eletrônicos de consumo. Como tal, requer uma API de uso geral para atender às necessidades de todos os tipos de aplicativos, de jogos a aplicativos incorporados e software corporativo executado em servidores. Ao aproveitar as informações corretas fornecidas pela API, você pode garantir que seu jogo funcione da melhor maneira possível em qualquer hardware.
CPUSets API
A API CPUSets fornece controle sobre quais conjuntos de CPU estão disponíveis para que os threads sejam agendados. Duas funções estão disponíveis para controlar onde os threads são agendados:
- SetProcessDefaultCpuSets – Essa função pode ser usada para especificar em quais conjuntos de CPU novos threads podem ser executados se não forem atribuídos a conjuntos de CPU específicos.
- SetThreadSelectedCpuSets – Esta função permite limitar os conjuntos de CPU em que um thread específico pode ser executado.
Se a função SetProcessDefaultCpuSets nunca for usada, os threads recém-criados poderão ser agendados em qualquer conjunto de CPU disponível para o processo. Esta seção aborda os conceitos básicos da API CPUSets.
GetSystemCpuSetInformation
A primeira API usada para coletar informações é a função GetSystemCpuSetInformation . Essa função preenche informações em uma matriz de objetos SYSTEM_CPU_SET_INFORMATION fornecidos pelo código de título. A memória para o destino deve ser alocada pelo código do jogo, cujo tamanho é determinado chamando o próprio GetSystemCpuSetInformation . Isso requer duas chamadas para GetSystemCpuSetInformation , conforme demonstrado no exemplo a seguir.
unsigned long size;
HANDLE curProc = GetCurrentProcess();
GetSystemCpuSetInformation(nullptr, 0, &size, curProc, 0);
std::unique_ptr<uint8_t[]> buffer(new uint8_t[size]);
PSYSTEM_CPU_SET_INFORMATION cpuSets = reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(buffer.get());
GetSystemCpuSetInformation(cpuSets, size, &size, curProc, 0);
Cada instância de SYSTEM_CPU_SET_INFORMATION retornada contém informações sobre uma unidade de processamento exclusiva, também conhecida como conjunto de CPU. Isso não significa necessariamente que ele represente uma peça física única de hardware. As CPUs que utilizam hyperthreading terão vários núcleos lógicos em execução em um único núcleo de processamento físico. O agendamento de vários threads em diferentes núcleos lógicos que residem no mesmo núcleo físico permite a otimização de recursos no nível do hardware que, de outra forma, exigiria trabalho extra no nível do kernel. Dois threads agendados em núcleos lógicos separados no mesmo núcleo físico devem compartilhar o tempo de CPU, mas seriam executados com mais eficiência do que se fossem agendados para o mesmo núcleo lógico.
SYSTEM_CPU_SET_INFORMATION
As informações em cada instância dessa estrutura de dados retornada de GetSystemCpuSetInformation contêm informações sobre uma unidade de processamento exclusiva na qual os threads podem ser agendados. Dada a possível variedade de dispositivos de destino, muitas das informações na estrutura de dados SYSTEM_CPU_SET_INFORMATION podem não ser aplicáveis ao desenvolvimento de jogos. A Tabela 1 fornece uma explicação dos membros de dados que são úteis para o desenvolvimento de jogos.
Tabela 1. Membros de dados úteis para o desenvolvimento de jogos.
| Nome do membro | Tipo de dados | Descrição |
|---|---|---|
| Type | CPU_SET_INFORMATION_TYPE | O tipo de informação na estrutura. Se o valor de this não for CpuSetInformation, ele deverá ser ignorado. |
| ID | unsigned long | A ID do conjunto de CPU especificado. Essa é a ID que deve ser usada com funções de conjunto de CPU, como SetThreadSelectedCpuSets. |
| Grupo | unsigned short | Especifica o "grupo de processadores" do conjunto de CPUs. Os grupos de processadores permitem que um PC tenha mais de 64 núcleos lógicos e permitem a troca a quente de CPUs enquanto o sistema está em execução. É incomum ver um PC que não seja um servidor com mais de um grupo. A menos que você esteja escrevendo aplicativos destinados a serem executados em servidores grandes ou farms de servidores, é melhor usar conjuntos de CPU em um único grupo, pois a maioria dos PCs de consumo terá apenas um grupo de processadores. Todos os outros valores nessa estrutura são relativos ao Grupo. |
| LogicalProcessorIndex | unsigned char | Índice relativo do grupo do conjunto de CPUs |
| Índice de núcleo | unsigned char | Índice relativo do grupo do núcleo físico da CPU em que o conjunto de CPU está localizado |
| LastLevelCacheIndex | unsigned char | Índice relativo de grupo do último cache associado a este conjunto de CPU. Esse é o cache mais lento, a menos que o sistema utilize nós NUMA, geralmente o cache L2 ou L3. |
Os outros membros de dados fornecem informações que provavelmente não descreverão CPUs em PCs de consumo ou outros dispositivos de consumo e provavelmente não serão úteis. As informações fornecidas pelos dados retornados podem ser usadas para organizar threads de várias maneiras. A seção Considerações para o desenvolvimento de jogos deste white paper detalha algumas maneiras de aproveitar esses dados para otimizar a alocação de threads.
Veja a seguir alguns exemplos do tipo de informação coletada de aplicativos UWP em execução em vários tipos de hardware.
Tabela 2. Informações retornadas de um aplicativo UWP em execução em um Microsoft Lumia 950. Este é um exemplo de um sistema que tem vários caches de último nível. O Lumia 950 possui um processo Qualcomm 808 Snapdragon que contém CPUs Arm Cortex A57 dual core e Arm Cortex A53 quad core.

Tabela 3. Informações retornadas de um aplicativo UWP em execução em um computador típico. Este é um exemplo de um sistema que usa hyperthreading; Cada núcleo físico tem dois núcleos lógicos nos quais os threads podem ser agendados. Nesse caso, o sistema continha uma CPU Intel Xenon E5-2620.

Tabela 4. Informações retornadas de um aplicativo UWP em execução em um Microsoft Surface Pro 4 quad core. Este sistema tinha uma CPU Intel Core i5-6300.

SetThreadSelectedCpuSets
Agora que as informações sobre os conjuntos de CPU estão disponíveis, elas podem ser usadas para organizar threads. O identificador de um thread criado com CreateThread é passado para essa função junto com uma matriz de IDs dos conjuntos de CPU nos quais o thread pode ser agendado. Um exemplo de seu uso é demonstrado no código a seguir.
HANDLE audioHandle = CreateThread(nullptr, 0, AudioThread, nullptr, 0, nullptr);
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation( nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data( new uint8_t[retsize] );
if ( !GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>( data.get() ),
retsize, &retsize, GetCurrentProcess(), 0) )
{
// Error!
}
std::vector<DWORD> cores;
uint8_t const * ptr = data.get();
for( DWORD size = 0; size < retsize; ) {
auto info = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>( ptr );
if ( info->Type == CpuSetInformation ) {
cores.push_back( info->CpuSet.Id );
}
ptr += info->Size;
size += info->Size;
}
if ( cores.size() >= 2 ) {
SetThreadSelectedCpuSets(audioHandle, cores.data(), 2);
}
Neste exemplo, um thread é criado com base em uma função declarada como AudioThread. Esse thread pode ser agendado em um dos dois conjuntos de CPU. A propriedade do thread do conjunto de CPU não é exclusiva. Os threads criados sem serem bloqueados em um conjunto de CPU específico podem levar tempo do AudioThread. Da mesma forma, outros threads criados também podem ser bloqueados para um ou ambos os conjuntos de CPU posteriormente.
SetProcessDefaultCpuSets
O inverso para SetThreadSelectedCpuSets é SetProcessDefaultCpuSets. Quando os threads são criados, eles não precisam ser bloqueados em determinados conjuntos de CPU. Se você não quiser que esses threads sejam executados em conjuntos de CPU específicos (aqueles usados pelo thread de renderização ou thread de áudio, por exemplo), você pode usar essa função para especificar em quais núcleos esses threads podem ser agendados.
Considerações para o desenvolvimento de jogos
Como vimos, a API CPUSets fornece muitas informações e flexibilidade quando se trata de agendar threads. Em vez de adotar a abordagem de baixo para cima de tentar encontrar usos para esses dados, é mais eficaz adotar a abordagem de cima para baixo para descobrir como os dados podem ser usados para acomodar cenários comuns.
Trabalhando com threads críticos de tempo e hyperthreading
Esse método é eficaz se o jogo tiver alguns threads que devem ser executados em tempo real junto com outros threads de trabalho que exigem relativamente pouco tempo de CPU. Algumas tarefas, como música de fundo contínua, devem ser executadas sem interrupção para uma experiência de jogo ideal. Mesmo um único quadro de fome para um thread de áudio pode causar estalos ou falhas, por isso é fundamental que ele receba a quantidade necessária de tempo de CPU a cada quadro.
O uso de SetThreadSelectedCpuSets em conjunto com SetProcessDefaultCpuSets pode garantir que seus threads pesados permaneçam ininterruptos por qualquer thread de trabalho. SetThreadSelectedCpuSets pode ser usado para atribuir seus threads pesados a conjuntos de CPU específicos. SetProcessDefaultCpuSets pode ser usado para garantir que todos os threads não atribuídos criados sejam colocados em outros conjuntos de CPU. No caso de CPUs que utilizam hyperthreading, também é importante levar em conta os núcleos lógicos no mesmo núcleo físico. Os threads de trabalho não devem ter permissão para serem executados em núcleos lógicos que compartilham o mesmo núcleo físico que um thread que você deseja executar com capacidade de resposta em tempo real. O código a seguir demonstra como determinar se um computador usa hyperthreading.
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation( nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data( new uint8_t[retsize] );
if ( !GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>( data.get() ),
retsize, &retsize, GetCurrentProcess(), 0) )
{
// Error!
}
std::set<DWORD> cores;
std::vector<DWORD> processors;
uint8_t const * ptr = data.get();
for( DWORD size = 0; size < retsize; ) {
auto info = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>( ptr );
if ( info->Type == CpuSetInformation ) {
processors.push_back( info->CpuSet.Id );
cores.insert( info->CpuSet.CoreIndex );
}
ptr += info->Size;
size += info->Size;
}
bool hyperthreaded = processors.size() != cores.size();
Se o sistema utilizar hyperthreading, é importante que o conjunto de conjuntos de CPU padrão não inclua nenhum núcleo lógico no mesmo núcleo físico que qualquer thread em tempo real. Se o sistema não estiver hyperthreading, será necessário apenas certificar-se de que os conjuntos de CPU padrão não incluam o mesmo núcleo que o conjunto de CPU que executa o thread de áudio.
Um exemplo de organização de threads com base em núcleos físicos pode ser encontrado no exemplo CPUSets disponível no repositório GitHub vinculado na seção Recursos adicionais.
Reduzindo o custo da coerência do cache com o cache de último nível
A coerência de cache é o conceito de que a memória em cache é a mesma em vários recursos de hardware que atuam nos mesmos dados. Se os threads estiverem agendados em núcleos diferentes, mas trabalharem nos mesmos dados, eles poderão estar trabalhando em cópias separadas desses dados em caches diferentes. Para obter resultados corretos, esses caches devem ser mantidos coerentes entre si. Manter a coerência entre vários caches é relativamente caro, mas necessário para qualquer sistema multi-core operar. Além disso, está completamente fora do controle do código do cliente; O sistema subjacente funciona de forma independente para manter os caches atualizados, acessando recursos de memória compartilhada entre os núcleos.
Se o seu jogo tiver vários threads que compartilham uma quantidade especialmente grande de dados, você poderá minimizar o custo da coerência do cache garantindo que eles sejam agendados em conjuntos de CPU que compartilham um cache de último nível. O cache de último nível é o cache mais lento disponível para um núcleo em sistemas que não utilizam nós NUMA. É extremamente raro que um PC para jogos utilize nós NUMA. Se os núcleos não compartilharem um cache de último nível, manter a coerência exigiria o acesso a recursos de memória de nível superior e, portanto, mais lentos. Bloquear dois threads para separar conjuntos de CPU que compartilham um cache e um núcleo físico pode fornecer um desempenho ainda melhor do que agendá-los em núcleos físicos separados se eles não exigirem mais de 50% do tempo em um determinado quadro.
Este exemplo de código mostra como determinar se os threads que se comunicam com frequência podem compartilhar um cache de último nível.
unsigned long retsize = 0;
(void)GetSystemCpuSetInformation(nullptr, 0, &retsize,
GetCurrentProcess(), 0);
std::unique_ptr<uint8_t[]> data(new uint8_t[retsize]);
if (!GetSystemCpuSetInformation(
reinterpret_cast<PSYSTEM_CPU_SET_INFORMATION>(data.get()),
retsize, &retsize, GetCurrentProcess(), 0))
{
// Error!
}
bool sharedcache = false;
std::map<unsigned char, std::vector<const SYSTEM_CPU_SET_INFORMATION*>> cachemap;
uint8_t const * ptr = data.get();
for(DWORD size = 0; size < retsize;)
{
auto cpuset = reinterpret_cast<const SYSTEM_CPU_SET_INFORMATION*>(ptr);
if (cpuset->Type == CpuSetInformation)
{
if (cachemap.find(cpuset->CpuSet.LastLevelCacheIndex) == cachemap.end())
{
std::pair<unsigned char, std::vector<const SYSTEM_CPU_SET_INFORMATION*>> newvalue;
newvalue.first = cpuset->CpuSet.LastLevelCacheIndex;
newvalue.second.push_back(cpuset);
cachemap.insert(newvalue);
}
else
{
sharedcache = true;
cachemap[cpuset->CpuSet.LastLevelCacheIndex].push_back(cpuset);
}
}
ptr += cpuset->Size;
size += cpuset->Size;
}
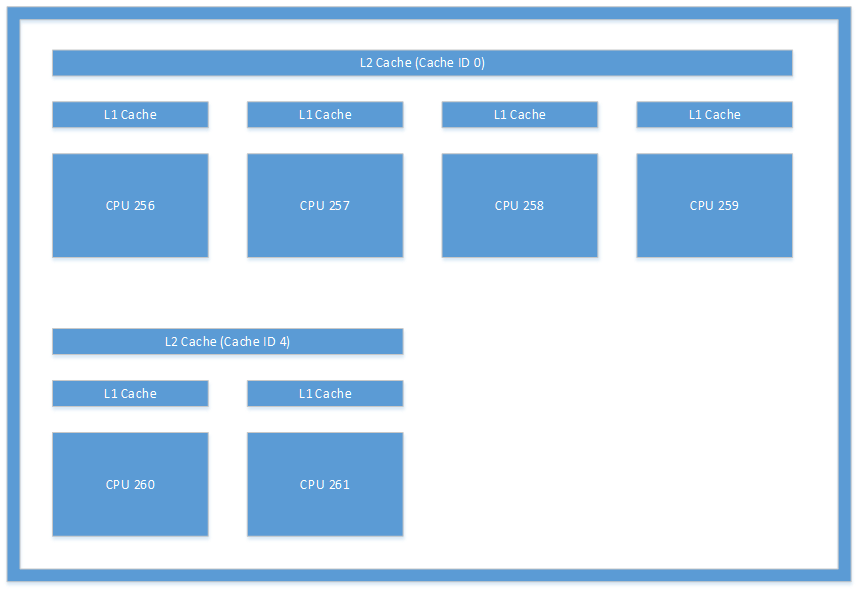
O layout de cache ilustrado na Figura 1 é um exemplo do tipo de layout que você pode ver em um sistema. Esta figura é uma ilustração dos caches encontrados em um Microsoft Lumia 950. A comunicação entre threads que ocorre entre a CPU 256 e a CPU 260 incorreria em sobrecarga significativa porque exigiria que o sistema mantivesse seus caches L2 coerentes.
Figura 1. Arquitetura de cache encontrada em um dispositivo Microsoft Lumia 950.
Resumo
A API CPUSets disponível para desenvolvimento UWP fornece uma quantidade considerável de informações e controle sobre suas opções de multithreading. As complexidades adicionais em comparação com as APIs multithreaded anteriores para desenvolvimento do Windows têm alguma curva de aprendizado, mas a maior flexibilidade permite um melhor desempenho em uma variedade de PCs de consumo e outros destinos de hardware.