Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Este guia é uma introdução ao desenvolvimento do Azure Functions usando Python. O artigo pressupõe que você já tenha lido o guia de desenvolvedores do Azure Functions.
Importante
Este artigo dá suporte ao modelo de programação v1 e v2 para Python no Azure Functions. O modelo Python v1 usa um arquivo functions.json para definir funções, e o novo modelo v2 permite que você use uma abordagem baseada em decorador. Essa nova abordagem resulta em uma estrutura de arquivos mais simples e mais centrada em código. Escolha o seletor v2 na parte superior do artigo para saber mais sobre este novo modelo de programação.
Como desenvolvedor Python, você também pode estar interessado nestes artigos:
- Visual Studio Code: Crie seu primeiro aplicativo Python usando o Visual Studio Code.
- Terminal ou linha de comandos: crie a sua primeira aplicação Python a partir da linha de comandos usando as Ferramentas Core do Azure Functions.
- Exemplos: analise alguns aplicativos Python existentes no navegador de exemplos do Learn.
- Visual Studio Code: Crie seu primeiro aplicativo Python usando o Visual Studio Code.
- Terminal ou linha de comandos: crie a sua primeira aplicação Python a partir da linha de comandos usando as Ferramentas Core do Azure Functions.
- Exemplos: analise alguns aplicativos Python existentes no navegador de exemplos do Learn.
Opções de desenvolvimento
Ambos os modelos de programação Python Functions suportam o desenvolvimento local em um dos seguintes ambientes:
Modelo de programação Python v2:
Modelo de programação Python v1:
Você também pode criar funções Python no portal do Azure.
Gorjeta
Embora você possa desenvolver suas funções do Azure baseadas em Python localmente no Windows, o Python é suportado apenas em um plano de hospedagem baseado em Linux quando está sendo executado no Azure. Para obter mais informações, consulte a lista de combinações de sistema operacional/tempo de execução suportadas.
Modelo de programação
O Azure Functions espera que uma função seja um método sem estado em seu script Python que processa a entrada e produz a saída. Por padrão, o tempo de execução espera que o método seja implementado como um método global chamado main() no arquivo __init__.py . Você também pode especificar um ponto de entrada alternativo.
Você liga os dados à função a partir de gatilhos e associações usando atributos de método que utilizam a propriedade name definida no arquivo function.json. Por exemplo, o seguinte arquivo function.json descreve uma função simples que é acionada por uma solicitação HTTP chamada req:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Com base nessa definição, o arquivo de __init__.py que contém o código da função pode se parecer com o exemplo a seguir:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
Você também pode declarar explicitamente os tipos de atributo e o tipo de retorno na função usando anotações de tipo Python. Isso ajuda você a usar o IntelliSense e os recursos de preenchimento automático fornecidos por muitos editores de código Python.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Use as anotações Python incluídas no pacote azure.functions.* para vincular as entradas e saídas aos seus métodos.
O Azure Functions espera que uma função seja um método sem estado em seu script Python que processa a entrada e produz a saída. Por padrão, o tempo de execução espera que o método seja implementado como um método global no arquivo function_app.py .
Gatilhos e ligações podem ser declarados e usados numa função numa abordagem baseada no decorador. Eles são definidos no mesmo arquivo, function_app.py, como as funções. Como exemplo, o seguinte arquivo function_app.py representa um disparador de função por uma solicitação HTTP.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
Você também pode declarar explicitamente os tipos de atributo e o tipo de retorno na função usando anotações de tipo Python. Isso ajuda você a usar os recursos do IntelliSense e de preenchimento automático fornecidos por muitos editores de código Python.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
Para saber mais sobre limitações conhecidas com o modelo v2 e suas soluções alternativas, consulte Solucionar erros de Python no Azure Functions.
Ponto de entrada alternativo
Você pode alterar o comportamento padrão de uma função especificando opcionalmente as scriptFile propriedades e entryPoint no arquivo function.json . Por exemplo, o seguinte function.json informa o runtime para usar o método customentry() como o ponto de entrada para a sua função Azure.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
O ponto de entrada está apenas no arquivo function_app.py . No entanto, você pode fazer referência a funções dentro do projeto em function_app.py usando esquemas ou importando.
Estrutura de pastas
A estrutura de pastas recomendada para um projeto de funções Python se parece com o exemplo a seguir:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
A pasta principal do projeto, <project_root>, pode conter os seguintes arquivos:
- local.settings.json: Usado para armazenar configurações de aplicativos e cadeias de conexão quando executado localmente. Este ficheiro não é publicado no Azure. Para saber mais, consulte local.settings.file.
- requirements.txt: Contém a lista de pacotes Python que o sistema instala ao publicar no Azure.
- host.json: Contém opções de configuração que afetam todas as funções em uma instância de aplicativo de função. Esse arquivo é publicado no Azure. Nem todas as opções são suportadas quando executadas localmente. Para saber mais, consulte host.json.
- .vscode/: (Opcional) Contém a configuração armazenada do Visual Studio Code. Para saber mais, consulte Configurações de código do Visual Studio.
- .venv/: (Opcional) Contém um ambiente virtual Python usado pelo desenvolvimento local.
- Dockerfile: (Opcional) Usado ao publicar seu projeto em um contêiner personalizado.
- tests/: (Opcional) Contém os casos de teste do seu aplicativo de função.
- .funcignore: (Opcional) Declara arquivos que não devem ser publicados no Azure. Normalmente, esse arquivo contém .vscode/ para ignorar a configuração do editor, .venv/ para ignorar o ambiente virtual Python local, testes/ para ignorar casos de teste e local.settings.json para impedir que as configurações do aplicativo local sejam publicadas.
Cada função tem seu próprio arquivo de código e arquivo de configuração de ligação, function.json.
A estrutura de pastas recomendada para um projeto de funções Python se parece com o exemplo a seguir:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
A pasta principal do projeto, <project_root>, pode conter os seguintes arquivos:
- .venv/: (Opcional) Contém um ambiente virtual Python usado pelo desenvolvimento local.
- .vscode/: (Opcional) Contém a configuração armazenada do Visual Studio Code. Para saber mais, consulte Configurações de código do Visual Studio.
- function_app.py: O local padrão para todas as funções e seus gatilhos e ligações relacionados.
- additional_functions.py: (Opcional) Quaisquer outros arquivos Python que contenham funções (geralmente para agrupamento lógico) que são referenciados em function_app.py através de blueprints.
- tests/: (Opcional) Contém os casos de teste do seu aplicativo de função.
- .funcignore: (Opcional) Declara arquivos que não devem ser publicados no Azure. Normalmente, esse arquivo contém .vscode/ para ignorar a configuração do editor, .venv/ para ignorar o ambiente virtual Python local, testes/ para ignorar casos de teste e local.settings.json para impedir que as configurações do aplicativo local sejam publicadas.
- host.json: Contém opções de configuração que afetam todas as funções em uma instância de aplicativo de função. Esse arquivo é publicado no Azure. Nem todas as opções são suportadas quando executadas localmente. Para saber mais, consulte host.json.
- local.settings.json: Usado para armazenar configurações de aplicativos e cadeias de conexão quando ele está sendo executado localmente. Este ficheiro não é publicado no Azure. Para saber mais, consulte local.settings.file.
- requirements.txt: Contém a lista de pacotes Python que o sistema instala quando publica no Azure.
- Dockerfile: (Opcional) Usado ao publicar seu projeto em um contêiner personalizado.
Quando você implanta seu projeto em um aplicativo de função no Azure, todo o conteúdo da pasta principal do projeto, <project_root>, deve ser incluído no pacote, mas não a pasta em si, o que significa que host.json deve estar na raiz do pacote. Recomendamos que você mantenha seus testes em uma pasta junto com outras funções (neste exemplo, tests/). Para obter mais informações, consulte Teste de unidade.
Ligar a uma base de dados
O Azure Functions integra-se bem com o Azure Cosmos DB para muitos casos de uso, incluindo IoT, comércio eletrônico, jogos, etc.
Por exemplo, para armazenamento de eventos, os dois serviços são integrados para alimentar arquiteturas orientadas a eventos usando a funcionalidade de fluxo de alterações do Azure Cosmos DB. O feed de alterações fornece aos microsserviços downstream a capacidade de ler inserções e atualizações de forma confiável e incremental (por exemplo, eventos de pedido). Essa funcionalidade pode ser usada para fornecer um armazenamento de eventos persistente como um agente de mensagens para eventos que alteram o estado e direcionam o fluxo de trabalho de processamento de pedidos entre muitos microsserviços (que podem ser implementados como Azure Functions sem servidor).
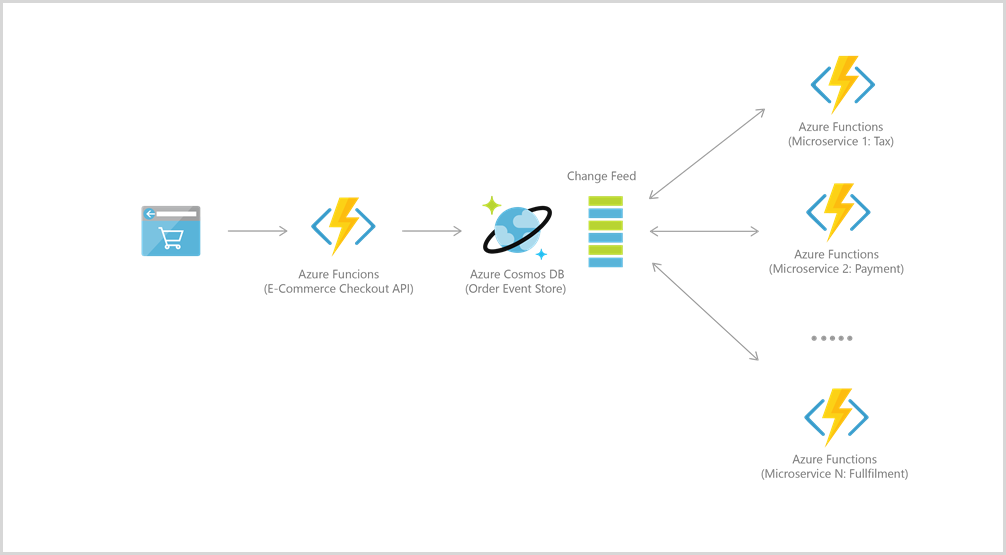
Para se conectar ao Azure Cosmos DB, primeiro crie uma conta, um banco de dados e um contêiner. Em seguida, você pode conectar seu código de função ao Azure Cosmos DB usando gatilho e associações, como este exemplo.
Para implementar uma lógica de aplicativo mais complexa, você também pode usar a biblioteca Python para o Cosmos DB. Uma implementação de E/S assíncrona tem esta aparência:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Plantas técnicas
O modelo de programação Python v2 introduz o conceito de blueprints. Um blueprint é uma nova classe que é instanciada para registar funções fora da aplicação núcleo. As funções registradas em instâncias do blueprint não são indexadas diretamente pelo tempo de execução da função. Para indexar essas funções do blueprint, o aplicativo de função precisa registrar as funções das instâncias do blueprint.
O uso de planos oferece os seguintes benefícios:
- Permite dividir o aplicativo de função em componentes modulares, o que permite definir funções em vários arquivos Python e dividi-los em diferentes componentes por arquivo.
- Fornece interfaces de aplicativo de função pública extensíveis para criar e reutilizar suas próprias APIs.
O exemplo a seguir mostra como usar planos:
Primeiro, em um arquivo http_blueprint.py , uma função acionada por HTTP é primeiro definida e adicionada a um objeto blueprint.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
Em seguida, no arquivo function_app.py , o objeto blueprint é importado e suas funções são registradas no aplicativo de função.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Nota
Durable Functions também suporta esquemas. Para criar planos para aplicativos Durable Functions, registre seus gatilhos de orquestração, de atividade, de entidade e associações de cliente usando a azure-functions-durableBlueprint classe, como mostrado aqui. O plano resultante pode então ser registado normalmente. Veja o nosso exemplo para um exemplo.
Comportamento de importação
Você pode importar módulos em seu código de função usando referências absolutas e relativas. Com base na estrutura de pastas descrita anteriormente, as seguintes importações funcionam de dentro do arquivo <de função project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Nota
Quando você estiver usando a sintaxe de importação absoluta, a pasta shared_code/ precisa conter um arquivo __init__.py para marcá-la como um pacote Python.
As seguintes importações de __app__ e a importação relativa a partir do nível superior foram preteridas, porque não são suportadas pelo verificador de tipos estático e não são suportadas pelas estruturas de teste do Python:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Gatilhos e entradas
As entradas são divididas em duas categorias no Azure Functions: entrada de gatilho e outra entrada. Embora eles sejam diferentes no arquivo function.json , seu uso é idêntico no código Python. As strings de conexão ou segredos para fontes de acionamento e entrada correspondem a valores no ficheiro local.settings.json quando estão a ser executados localmente, e às configurações da aplicação quando estão a ser executados no Azure.
Por exemplo, o código a seguir demonstra a diferença entre as duas entradas:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Quando a função é invocada, a solicitação HTTP é passada para a função como req. Uma entrada é recuperada da conta de Armazenamento de Blobs do Azure com base na ID na URL de rota e disponibilizada como obj no corpo da função. Aqui, a conta de armazenamento especificada é a cadeia de conexão encontrada na configuração do <*_CONNECTION_STRING> aplicativo. Para obter mais informações, consulte Para obter mais informações, consulte Conexões.
As entradas são divididas em duas categorias no Azure Functions: entrada de gatilho e outra entrada. Embora eles sejam definidos usando decoradores diferentes, seu uso é semelhante no código Python. As strings de conexão ou segredos para fontes de acionamento e entrada correspondem a valores no ficheiro local.settings.json quando estão a ser executados localmente, e às configurações da aplicação quando estão a ser executados no Azure.
Como exemplo, o código a seguir demonstra como definir uma ligação de entrada de armazenamento de Blob:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.blob_input(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Quando a função é invocada, a solicitação HTTP é passada para a função como req. Uma entrada é recuperada da conta de Armazenamento de Blobs do Azure com base na ID na URL de rota e disponibilizada como obj no corpo da função. Aqui, a conta de armazenamento especificada é a cadeia de conexão encontrada na configuração do <*_CONNECTION_STRING> aplicativo. Para obter mais informações, consulte Para obter mais informações, consulte Conexões.
Para operações de vinculação com uso intensivo de dados, convém usar uma conta de armazenamento separada. Para obter mais informações, consulte Diretrizes de conta de armazenamento.
Ligações de tipo SDK
Para selecionar gatilhos e associações, você pode trabalhar com tipos de dados implementados pelos SDKs e estruturas subjacentes do Azure. Essas associações de tipo SDK permitem que você interaja com dados de vinculação como se estivesse usando o SDK de serviço subjacente.
'> [! IMPORTANTE]
Usar associações de tipo SDK requer o modelo de programação Python v2.
Importante
O suporte a ligações de tipo SDK para Python só é suportado no modelo de programação Python v2.
Pré-requisitos
- Versão de tempo de execução do Azure Functions versão 4.34 ou uma versão posterior.
- Python versão 3.10 ou uma versão posterior suportada.
Tipos de SDK
| Serviço | Acionador | Vinculação de entrada | Vinculação de saída | Exemplos |
|---|---|---|---|---|
| Azure Blobs | Disponível ao público em geral | Disponível ao público em geral | Tipos de SDK não recomendados.1 |
Guia de início rápido,BlobClient,ContainerClient,StorageStreamDownloader |
| Azure Cosmos DB | Tipos de SDK não utilizados2 | Previsualizar | Tipos de SDK não recomendados.1 |
Guia de início rápido, ContainerProxy,CosmosClient,DatabaseProxy |
| Hubs de Eventos do Azure | Previsualizar | A vinculação de entrada não existe | Tipos de SDK não recomendados.1 |
Guia de início rápido, EventData |
| Barramento de Serviço do Azure | Previsualizar | A vinculação de entrada não existe | Tipos de SDK não recomendados.1 |
Guia de início rápido, ServiceBusReceivedMessage |
1 Para cenários de saída nos quais você usaria um tipo de SDK, você deve criar e trabalhar com clientes SDK diretamente em vez de usar uma associação de saída. 2 O gatilho do Cosmos DB usa o feed de alterações do Azure Cosmos DB e expõe itens de feed de alteração como tipos serializáveis por JSON. A ausência de tipos de SDK é por design para este cenário.
Fluxos HTTP
Fluxos HTTP é um recurso que permite aceitar e retornar dados de seus pontos de extremidade HTTP usando APIs de solicitação e resposta FastAPI habilitadas em suas funções. Essas APIs permitem que o host processe grandes dados em mensagens HTTP como partes, em vez de ler uma mensagem inteira na memória.
Esse recurso torna possível lidar com grandes fluxos de dados, integrações OpenAI, fornecer conteúdo dinâmico e suportar outros cenários HTTP principais que exigem interações em tempo real por HTTP. Você também pode usar tipos de resposta FastAPI com fluxos HTTP. Sem fluxos HTTP, o tamanho de suas solicitações e respostas HTTP é limitado por restrições de memória que podem ser encontradas ao processar cargas úteis de mensagens inteiras na memória.
Para saber mais, incluindo como habilitar fluxos HTTP em seu projeto, consulte Fluxos HTTP.
Importante
O suporte para fluxos HTTP requer o modelo de programação Python v2.
Importante
O suporte a fluxos HTTP para Python está geralmente disponível e requer que você use o modelo de programação Python v2.
Saídas
A saída pode ser expressa em valor de retorno e parâmetros de saída. Se houver apenas uma saída, recomendamos usar o valor de retorno. Para várias saídas, você deve usar parâmetros de saída.
Para usar o valor de retorno de uma função como o valor de uma ligação de saída, a name propriedade da associação deve ser definida como $return no arquivo function.json .
Para produzir várias saídas, use o set() método fornecido pela azure.functions.Out interface para atribuir um valor à ligação. Por exemplo, a função a seguir pode enviar uma mensagem para uma fila e também retornar uma resposta HTTP.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
A saída pode ser expressa em valor de retorno e parâmetros de saída. Se houver apenas uma saída, recomendamos usar o valor de retorno. Para várias saídas, você terá que usar parâmetros de saída.
Para produzir várias saídas, use o set() método fornecido pela azure.functions.Out interface para atribuir um valor à ligação. Por exemplo, a função a seguir pode enviar uma mensagem para uma fila e também retornar uma resposta HTTP.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Registo
O acesso ao logger de tempo de execução do Azure Functions está disponível por meio de um manipulador raiz logging em seu aplicativo de função. Esse registrador está vinculado ao Application Insights e permite sinalizar avisos e erros que ocorrem durante a execução da função.
O exemplo a seguir registra uma mensagem info quando a função é invocada por meio de um gatilho HTTP.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
Estão disponíveis mais métodos de registo que permitem escrever na consola em diferentes níveis de rastreio:
| Método | Descrição |
|---|---|
critical(_message_) |
Escreve uma mensagem com o nível CRÍTICO no registrador raiz. |
error(_message_) |
Grava uma mensagem com nível ERROR no registrador raiz. |
warning(_message_) |
Escreve uma mensagem com nível WARNING no registrador raiz. |
info(_message_) |
Grava uma mensagem com nível INFO no registrador raiz. |
debug(_message_) |
Escreve uma mensagem com o nível DEBUG no registrador raiz. |
Para saber mais sobre logging, consulte Monitorizar Azure Functions.
Registro em log de threads criados
Para ver os logs provenientes dos threads criados, inclua o context argumento na assinatura da função. Este argumento contém um atributo thread_local_storage que armazena um local invocation_id. Isso pode ser ajustado para o valor atual da função invocation_id para garantir que o contexto seja alterado.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Registar telemetria personalizada
Por padrão, o tempo de execução do Functions coleta logs e outros dados de telemetria que são gerados por suas funções. Esta telemetria resulta em rastreios no Application Insights. A telemetria de solicitação e dependência para determinados serviços do Azure também é coletada por padrão por gatilhos e associações.
Para coletar solicitação personalizada e telemetria de dependência personalizada fora das associações, você pode usar as extensões Python do OpenCensus. Essa extensão envia dados de telemetria personalizados para sua instância do Application Insights. Você pode encontrar uma lista de extensões suportadas no repositório OpenCensus.
Nota
Para usar as extensões OpenCensus Python, você precisa habilitar as extensões de trabalho Python em seu aplicativo de função definindo PYTHON_ENABLE_WORKER_EXTENSIONS como 1. Você também precisa trocar para usar a cadeia de conexão do Application Insights, adicionando a APPLICATIONINSIGHTS_CONNECTION_STRING configuração às definições da aplicação, se ela ainda não estiver lá.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
Acionador HTTP
O gatilho HTTP é definido no arquivo function.json . O name da ligação deve corresponder ao parâmetro nomeado na função.
Nos exemplos anteriores, um nome req de ligação é usado. Esse parâmetro é um objeto HttpRequest e um objeto HttpResponse é retornado.
No objeto HttpRequest, você pode obter cabeçalhos de solicitação, parâmetros de consulta, parâmetros de rota e o corpo da mensagem.
O exemplo a seguir é do modelo de gatilho HTTP para Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
Nesta função, obtém-se o valor do parâmetro de consulta name a partir do parâmetro params do objeto HttpRequest. Você lê o corpo da mensagem codificada em JSON usando o get_json método.
Da mesma forma, você pode definir o status_code e headers para a mensagem de resposta no objeto HttpResponse retornado.
O gatilho HTTP é definido como um método que usa um parâmetro de vinculação nomeado, que é um objeto HttpRequest , e retorna um objeto HttpResponse . Você aplica o function_name decorador ao método para definir o nome da função, enquanto o ponto de extremidade HTTP é definido aplicando o route decorador.
Este exemplo é do modelo de gatilho HTTP para o modelo de programação Python v2, onde o nome do parâmetro de vinculação é req. É o código de exemplo fornecido quando você cria uma função usando as Ferramentas Principais do Azure Functions ou o Visual Studio Code.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
No objeto HttpRequest, você pode obter cabeçalhos de solicitação, parâmetros de consulta, parâmetros de rota e o corpo da mensagem. Nesta função, obtém-se o valor do parâmetro de consulta name a partir do parâmetro params do objeto HttpRequest. Você lê o corpo da mensagem codificada em JSON usando o get_json método.
Da mesma forma, você pode definir o status_code e headers para a mensagem de resposta no objeto HttpResponse retornado.
Para passar um nome neste exemplo, cole a URL fornecida quando você está executando a função e acrescente-a com "?name={name}".
Estruturas Web
Você pode usar estruturas compatíveis com WSGI (Web Server Gateway Interface) e ASGI (Asynchronous Server Gateway Interface), como Flask e FastAPI, com suas funções Python acionadas por HTTP. Esta seção mostra como modificar suas funções para dar suporte a essas estruturas.
Primeiro, o arquivo function.json deve ser atualizado para incluir um route no gatilho HTTP, conforme mostrado no exemplo a seguir:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
O arquivo host.json também deve ser atualizado para incluir um HTTP routePrefix, conforme mostrado no exemplo a seguir:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[4.*, 5.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Atualize o arquivo de código Python init.py, dependendo da interface usada pela sua estrutura. O exemplo a seguir mostra uma abordagem de manipulador ASGI ou uma abordagem de wrapper WSGI para Flask:
Você pode usar estruturas compatíveis com ASGI (Asynchronous Server Gateway Interface) e WSGI (Web Server Gateway Interface), como Flask e FastAPI, com suas funções Python acionadas por HTTP. Você deve primeiro atualizar o arquivo host.json para incluir um HTTP routePrefix, conforme mostrado no exemplo a seguir:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[4.*, 5.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
O código da estrutura se parece com o exemplo a seguir:
AsgiFunctionApp é a classe de aplicativo de função de nível superior para construir funções HTTP ASGI.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Dimensionamento e desempenho
Para obter informações sobre as práticas recomendadas de dimensionamento e desempenho para aplicativos de função Python, consulte o artigo Dimensionamento e desempenho do Python.
Contexto
Para obter o contexto de invocação de uma função quando ela estiver em execução, inclua o context argumento em sua assinatura.
Por exemplo:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
A Context classe tem os seguintes atributos de cadeia de caracteres:
| Atributo | Descrição |
|---|---|
function_directory |
O diretório no qual a função está sendo executada. |
function_name |
O nome da função. |
invocation_id |
A ID da invocação da função atual. |
thread_local_storage |
O armazenamento local de thread da função. Contém um local invocation_id para registro em log de threads criados. |
trace_context |
O contexto para o rastreamento distribuído. Para obter mais informações, veja Trace Context. |
retry_context |
O contexto para tentativas de repetição da função. Para obter mais informações, veja retry-policies. |
Variáveis globais
Não é garantido que o estado do seu aplicativo será preservado para execuções futuras. No entanto, o tempo de execução do Azure Functions geralmente reutiliza o mesmo processo para várias execuções do mesmo aplicativo. Para armazenar em cache os resultados de um cálculo caro, declare-o como uma variável global.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Variáveis de ambiente
No Azure Functions, as configurações do aplicativo, como cadeias de conexão de serviço, são expostas como variáveis de ambiente quando estão em execução. Há duas maneiras principais de acessar essas configurações em seu código.
| Método | Descrição |
|---|---|
os.environ["myAppSetting"] |
Tenta obter a configuração do aplicativo pelo nome da chave e gera um erro quando ele não é bem-sucedido. |
os.getenv("myAppSetting") |
Tenta obter a configuração do aplicativo pelo nome da chave e retorna None quando ela não é bem-sucedida. |
Ambas as maneiras exigem que você declare import os.
O exemplo a seguir usa os.environ["myAppSetting"] para obter a configuração do aplicativo, com a chave chamada myAppSetting:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Para o desenvolvimento local, as configurações do aplicativo são mantidas no arquivo local.settings.json.
No Azure Functions, as configurações do aplicativo, como cadeias de conexão de serviço, são expostas como variáveis de ambiente quando estão em execução. Há duas maneiras principais de acessar essas configurações em seu código.
| Método | Descrição |
|---|---|
os.environ["myAppSetting"] |
Tenta obter a configuração do aplicativo pelo nome da chave e gera um erro quando ele não é bem-sucedido. |
os.getenv("myAppSetting") |
Tenta obter a configuração do aplicativo pelo nome da chave e retorna None quando ela não é bem-sucedida. |
Ambas as maneiras exigem que você declare import os.
O exemplo a seguir usa os.environ["myAppSetting"] para obter a configuração do aplicativo, com a chave chamada myAppSetting:
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Para o desenvolvimento local, as configurações do aplicativo são mantidas no arquivo local.settings.json.
Versão de Python
O Azure Functions suporta as seguintes versões do Python:
| Versões do Python1 | Nível de suporte |
|---|---|
| 3.13 | Geralmente disponível (GA)2 |
| 3.12 | disponibilidade geral |
| 3.11 | disponibilidade geral |
| 3,10 | disponibilidade geral |
- Distribuições oficiais Python
- Python 3.13 não é suportado quando seu aplicativo é executado no plano de consumo.
Importante
O suporte ao Python 3.13 introduz algumas melhorias e algumas alterações de rutura. Para obter mais informações, consulte Python 3.13+ no Azure Functions.
Para solicitar uma versão específica do Python ao criar seu aplicativo de função no Azure, use a --runtime-version opção do az functionapp create comando. A versão de tempo de execução do --functions-version Functions é definida pela opção. A versão Python é definida quando o aplicativo de função é criado e não pode ser alterada para aplicativos executados em um plano de consumo.
O tempo de execução usa a versão disponível do Python quando você o executa localmente.
Alterando a versão do Python
Para definir um aplicativo de função Python para uma versão de idioma específica, você precisa especificar o idioma e a versão do idioma no LinuxFxVersion campo na configuração do site. Por exemplo, para alterar o aplicativo Python para usar Python 3.12, defina linuxFxVersion como python|3.12.
Para saber como visualizar e alterar a configuração do linuxFxVersion site, consulte Como direcionar as versões do runtime do Azure Functions.
Para obter mais informações gerais, consulte a política de suporte de tempo de execução do Azure Functions e Idiomas suportados no Azure Functions.
Gestão de pacotes
Quando você estiver desenvolvendo localmente usando Core Tools ou Visual Studio Code, adicione os nomes e versões dos pacotes necessários ao arquivo requirements.txt e instale-os usando pip.
Por exemplo, pode-se usar o seguinte arquivo requirements.txt e o pip comando para instalar o pacote do requests PyPI.
requests==2.19.1
pip install -r requirements.txt
Ao executar suas funções em um plano do Serviço de Aplicativo, as dependências definidas em requirements.txt têm precedência sobre os módulos Python internos, como logging. Essa precedência pode causar conflitos quando os módulos internos têm os mesmos nomes que os diretórios em seu código. Ao usar um plano de Consumo ou um plano de Elastic Premium, os conflitos são menos prováveis porque as suas dependências não são priorizadas por padrão.
Para evitar problemas em execução em um plano do Serviço de Aplicativo, não nomeie seus diretórios da mesma forma que qualquer módulo nativo do Python e não inclua bibliotecas nativas do Python no arquivo requirements.txt do seu projeto.
Publicar no Azure
Quando estiver pronto para publicar, certifique-se de que todas as suas dependências disponíveis publicamente estão listadas no arquivo requirements.txt . Você pode localizar esse arquivo na raiz do diretório do projeto.
Você pode encontrar os arquivos e pastas do projeto que são excluídos da publicação, incluindo a pasta do ambiente virtual, no diretório raiz do seu projeto.
Há três ações de compilação com suporte para publicar seu projeto Python no Azure: compilação remota, compilação local e compilações usando dependências personalizadas.
Você também pode usar o Azure Pipelines para criar suas dependências e publicar usando a entrega contínua (CD). Para saber mais, consulte Entrega contínua com o Azure Pipelines.
Compilação remota
Quando você usa a compilação remota, as dependências restauradas no servidor e as dependências nativas correspondem ao ambiente de produção. o que resulta num pacote de implementação mais pequeno para carregar. Use a compilação remota quando estiver desenvolvendo aplicativos Python no Windows. Se o seu projeto tiver dependências personalizadas, você poderá usar a compilação remota com URL de índice extra.
As dependências são obtidas remotamente com base no conteúdo do ficheiro requirements.txt.
A compilação remota é o método de compilação recomendado. Por padrão, as Ferramentas Principais solicitam uma compilação remota quando você usa o comando a seguir func azure functionapp publish para publicar seu projeto Python no Azure.
func azure functionapp publish <APP_NAME>
Lembre-se de substituir <APP_NAME> pelo nome do seu aplicativo de função no Azure.
A Extensão do Azure Functions para Visual Studio Code também solicita uma compilação remota por padrão.
Construção local
As dependências são obtidas localmente com base no conteúdo do ficheiro requirements.txt. Você pode impedir que você faça uma compilação remota usando o seguinte func azure functionapp publish comando para publicar com uma compilação local:
func azure functionapp publish <APP_NAME> --build local
Lembre-se de substituir <APP_NAME> pelo nome do seu aplicativo de função no Azure.
Quando você usa a --build local opção, as dependências do projeto são lidas do arquivo requirements.txt e esses pacotes dependentes são baixados e instalados localmente. Os arquivos de projeto e as dependências são implantados do seu computador local no Azure. Isso resulta em um pacote de implantação maior sendo carregado no Azure. Se, por algum motivo, não for possível obter o arquivo requirements.txt usando as Ferramentas Principais, use a opção de dependências personalizadas para publicação.
Não recomendamos o uso de compilações locais quando você estiver desenvolvendo localmente no Windows.
Dependências personalizadas
Quando seu projeto tem dependências que não são encontradas no Python Package Index, há duas maneiras de criar o projeto. A primeira maneira, o método de construção , depende de como você constrói o projeto.
Compilação remota com URL de índice extra
Quando seus pacotes estiverem disponíveis a partir de um índice de pacotes personalizado acessível, use uma compilação remota. Antes de publicar, crie uma configuração de aplicativo chamada PIP_EXTRA_INDEX_URL. O valor desta configuração é a URL do índice do seu pacote personalizado. O uso desta configuração informa à compilação remota que execute pip install utilizando a opção --extra-index-url. Para saber mais, consulte a documentaçãopip installPython.
Você também pode usar credenciais de autenticação básicas com as suas URLs de índice de pacote extra. Para saber mais, consulte Credenciais básicas de autenticação na documentação do Python.
Instalar pacotes locais
Se seu projeto usa pacotes que não estão disponíveis publicamente para nossas ferramentas, você pode disponibilizá-los para seu aplicativo colocando-os no diretório __app__/.python_packages . Antes de publicar, execute o seguinte comando para instalar as dependências localmente:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
Quando estiver usando dependências personalizadas, você deve usar a --no-build opção de publicação, porque você já instalou as dependências na pasta do projeto.
func azure functionapp publish <APP_NAME> --no-build
Lembre-se de substituir <APP_NAME> pelo nome do seu aplicativo de função no Azure.
Teste de unidades
Teste unitário através de pytest
As funções que são escritas em Python podem ser testadas como outros códigos Python usando estruturas de teste padrão. Para a maioria das associações, é possível criar um objeto de entrada simulado criando uma instância de uma classe apropriada a partir do azure.functions pacote. Como o azure.functions pacote não está disponível imediatamente, certifique-se de instalá-lo através do seu arquivo requirements.txt, conforme descrito na seção de gerenciamento de pacotes acima.
Com my_second_function como exemplo, o seguinte é um teste simulado de uma função acionada por HTTP:
Primeiro, crie um <arquivo project_root>/my_second_function/function.json e, em seguida, defina essa função como um gatilho HTTP.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Em seguida, você pode implementar my_second_function e shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Você pode começar a escrever casos de teste para seu gatilho HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
Dentro de sua .venv pasta de ambiente virtual Python, instale sua estrutura de teste Python favorita, como pip install pytest. Em seguida, execute pytest tests para verificar o resultado do teste.
Primeiro, crie o <arquivo project_root>/function_app.py e implemente a my_second_function função como o gatilho HTTP e shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Você pode começar a escrever casos de teste para seu gatilho HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
Dentro de sua pasta de ambiente virtual .venv Python, instale sua estrutura de teste Python favorita, como pip install pytest. Em seguida, execute pytest tests para verificar o resultado do teste.
Teste de unidade invocando a função diretamente
Com azure-functions >= 1.21.0, as funções também podem ser chamadas diretamente usando o interpretador Python. Este exemplo mostra como testar um gatilho HTTP usando o modelo de programação v2:
# <project_root>/function_app.py
import azure.functions as func
import logging
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.route(route="http_trigger")
def http_trigger(req: func.HttpRequest) -> func.HttpResponse:
return "Hello, World!"
print(http_trigger(None))
Com essa abordagem, pacotes e configurações extras não são necessários. A função pode ser testada chamando python function_app.py, e resulta em Hello, World! saída no terminal.
Nota
Funções duráveis requerem sintaxe especial para testes de unidade. Para obter mais informações, consulte Unit Testing Durable Functions in Python
Ficheiros temporários
O tempfile.gettempdir() método retorna uma pasta temporária, que no Linux é /tmp. Seu aplicativo pode usar esse diretório para armazenar arquivos temporários que são gerados e usados por suas funções quando eles estão em execução.
Importante
Não é garantido que os arquivos gravados no diretório temporário persistam nas invocações. Durante a expansão, os arquivos temporários não são compartilhados entre instâncias.
O exemplo a seguir cria um arquivo temporário nomeado no diretório temporário (/tmp):
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
Recomendamos que você mantenha seus testes em uma pasta separada da pasta do projeto. Essa ação impede que você implante o código de teste com seu aplicativo.
Bibliotecas pré-instaladas
Algumas bibliotecas vêm com o tempo de execução das funções Python.
A biblioteca padrão Python
A biblioteca padrão Python contém uma lista de módulos Python integrados que são fornecidos com cada distribuição Python. A maioria dessas bibliotecas ajuda você a acessar a funcionalidade do sistema, como entrada/saída de arquivos (E/S). Em sistemas Windows, essas bibliotecas são instaladas com Python. Em sistemas baseados em Unix, eles são fornecidos por coleções de pacotes.
Para visualizar a biblioteca da sua versão do Python, vá para:
- Biblioteca padrão Python 3.10
- Biblioteca padrão Python 3.11
- Biblioteca padrão Python 3.12
- Biblioteca padrão Python 3.13
Dependências do componente de execução em Python do Azure Functions
O trabalhador Python do Azure Functions requer um conjunto específico de bibliotecas. Você também pode usar essas bibliotecas em suas funções, mas elas não fazem parte do padrão Python. Se suas funções dependerem de qualquer uma dessas bibliotecas, elas poderão não estar disponíveis para seu código quando ele estiver sendo executado fora do Azure Functions.
Nota
Se o arquivo requirements.txt do seu aplicativo de função contiver azure-functions-worker entrada, remova-a. O trabalhador de funções é gerenciado automaticamente pela plataforma Azure Functions e o atualizamos regularmente com novos recursos e correções de bugs. A instalação manual de uma versão antiga do worker no arquivo requirements.txt pode causar problemas inesperados.
Nota
Se o pacote contiver determinadas bibliotecas que possam colidir com as dependências do trabalhador (por exemplo, protobuf, TensorFlow ou grpcio), configure PYTHON_ISOLATE_WORKER_DEPENDENCIES as configurações do aplicativo para 1 impedir que seu aplicativo se refira às dependências do trabalhador.
A biblioteca Python do Azure Functions
Cada atualização de trabalho Python inclui uma nova versão da biblioteca Python do Azure Functions (azure.functions). Essa abordagem facilita a atualização contínua de seus aplicativos de função Python, porque cada atualização é compatível com versões anteriores. Para obter uma lista de versões desta biblioteca, vá para azure-functions PyPi.
A versão da biblioteca de tempo de execução é definida pelo Azure e não pode ser substituída porrequirements.txt. A azure-functions entrada no requirements.txt é apenas para verificação de código e conhecimento do cliente.
Use o código a seguir para controlar a versão real da biblioteca de funções Python em seu tempo de execução:
getattr(azure.functions, '__version__', '< 1.2.1')
Bibliotecas do sistema de tempo de execução
Para obter uma lista de bibliotecas de sistema pré-instaladas em imagens do Python worker Docker, consulte o seguinte:
| Tempo de execução das funções | Versão Debian | Versões Python |
|---|---|---|
| Versão 3.x | Buster | Python 3,7 Python 3.8 Python 3,9 |
Extensões de trabalho Python
O processo de trabalho Python executado no Azure Functions permite integrar bibliotecas de terceiros em seu aplicativo de função. Essas bibliotecas de extensão atuam como middleware que pode injetar operações específicas durante o ciclo de vida da execução da sua função.
As extensões são importadas em seu código de função como um módulo de biblioteca Python padrão. As extensões são executadas com base nos seguintes escopos:
| Âmbito de aplicação | Descrição |
|---|---|
| Nível de aplicação | Quando importada para qualquer gatilho de função, a extensão se aplica a cada execução de função no aplicativo. |
| Nível de função | A execução é limitada apenas ao gatilho de função específico para o qual é importada. |
Analise as informações de cada extensão para saber mais sobre o escopo no qual a extensão é executada.
As extensões implementam uma interface de extensão de trabalho Python. Essa ação permite que o processo de trabalho Python chame o código de extensão durante o ciclo de vida de execução da função. Para saber mais, consulte Criar extensões.
Usando extensões
Você pode usar uma biblioteca de extensão de trabalho Python em suas funções Python fazendo o seguinte:
- Adicione o pacote de extensão no arquivo de requirements.txt para seu projeto.
- Instale a biblioteca em seu aplicativo.
- Adicione as seguintes configurações do aplicativo:
- Localmente: insira
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"naValuessecção do seu arquivo local.settings.json. - Azure: insira
PYTHON_ENABLE_WORKER_EXTENSIONS=1nas definições da aplicação.
- Localmente: insira
- Importe o módulo de extensão para o gatilho de função.
- Configure a instância de extensão, se necessário. Os requisitos de configuração devem ser destacados na documentação da extensão.
Importante
Bibliotecas de extensão de trabalho Python de terceiros não são suportadas ou garantidas pela Microsoft. Você deve certificar-se de que todas as extensões que você usa em seu aplicativo de função é confiável, e você assume o risco total de usar uma extensão maliciosa ou mal escrita.
Terceiros devem fornecer documentação específica sobre como instalar e consumir suas extensões em seu aplicativo de função. Para obter um exemplo básico de como consumir uma extensão, consulte Consumindo sua extensão.
Aqui estão exemplos de uso de extensões em um aplicativo de função, por escopo:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Criação de extensões
As extensões são criadas por desenvolvedores de bibliotecas de terceiros que criaram funcionalidades que podem ser integradas ao Azure Functions. Um desenvolvedor de extensão projeta, implementa e libera pacotes Python que contêm lógica personalizada projetada especificamente para ser executada no contexto da execução de funções. Essas extensões podem ser publicadas no registro PyPI ou nos repositórios GitHub.
Para saber como criar, empacotar, publicar e consumir um pacote de extensão de trabalho Python, consulte Desenvolver extensões de trabalho Python para o Azure Functions.
Extensões no nível do aplicativo
Uma extensão herdada de execuções em um escopo de AppExtensionBase aplicativo.
AppExtensionBase Expõe os seguintes métodos de classe abstrata para você implementar:
| Método | Descrição |
|---|---|
init |
Chamado depois que a extensão é importada. |
configure |
Chamado a partir do código de função quando é necessário para configurar a extensão. |
post_function_load_app_level |
Chamado logo após a função ser carregada. O nome da função e o diretório da função são passados para a extensão. Lembre-se de que o diretório associado à função é somente de leitura, e qualquer tentativa de gravar um arquivo local nesse diretório irá falhar. |
pre_invocation_app_level |
Chamado logo antes de a função ser acionada. O contexto da função e os argumentos de invocação da função são passados para a extensão. Normalmente, você pode passar outros atributos no objeto de contexto para que o código da função seja consumido. |
post_invocation_app_level |
Chamado logo após o término da execução da função. O contexto da função, os argumentos de invocação da função e o objeto de retorno da invocação são passados para a extensão. Essa implementação é um bom lugar para validar se a execução dos ganchos do ciclo de vida foi bem-sucedida. |
Extensões de nível de função
Uma extensão que herda de FuncExtensionBase é executada num gatilho de função específico.
FuncExtensionBase Expõe os seguintes métodos de classe abstrata para implementações:
| Método | Descrição |
|---|---|
__init__ |
O construtor da extensão. É chamado quando uma instância de extensão é inicializada em uma função específica. Ao implementar este método abstrato, poderá querer aceitar um filename parâmetro e passá-lo para o método do pai super().__init__(filename) para o registo adequado de extensão. |
post_function_load |
Chamado logo após a função ser carregada. O nome da função e o diretório da função são passados para a extensão. Lembre-se de que o diretório associado à função é somente de leitura, e qualquer tentativa de gravar um arquivo local nesse diretório irá falhar. |
pre_invocation |
Chamado logo antes de a função ser acionada. O contexto da função e os argumentos de invocação da função são passados para a extensão. Normalmente, você pode passar outros atributos no objeto de contexto para que o código da função seja consumido. |
post_invocation |
Chamado logo após o término da execução da função. O contexto da função, os argumentos de invocação da função e o objeto de retorno da invocação são passados para a extensão. Essa implementação é um bom lugar para validar se a execução dos ganchos do ciclo de vida foi bem-sucedida. |
Partilha de recursos de várias origens
O Azure Functions dá suporte ao compartilhamento de recursos entre origens (CORS). O CORS é configurado no portal e por meio da CLI do Azure. A lista de origens permitidas do CORS aplica-se ao nível da função app. Com o CORS ativado, as respostas incluem o Access-Control-Allow-Origin cabeçalho. Para obter mais informações, consulte Partilha de recursos de várias origens.
O compartilhamento de recursos entre origens (CORS) é totalmente suportado para aplicativos de função Python.
Assíncrono
Por padrão, uma instância de host para Python pode processar apenas uma invocação de função de cada vez. Isso ocorre porque Python é um tempo de execução de único segmento. Para um aplicativo de função que processa um grande número de eventos de E/S ou está sendo vinculado a E/S, você pode melhorar significativamente o desempenho executando funções de forma assíncrona. Para obter mais informações, consulte Melhorar o desempenho de aplicativos Python no Azure Functions.
Memória partilhada (pré-visualização)
Para melhorar a taxa de transferência, o Azure Functions permite que seu trabalhador de linguagem Python fora do processo compartilhe memória com o processo de host do Functions. Quando seu aplicativo de função está enfrentando gargalos, você pode habilitar a memória compartilhada adicionando uma configuração de aplicativo chamada FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED com um valor de 1. Com a memória compartilhada habilitada, você pode usar a configuração DOCKER_SHM_SIZE para definir a memória compartilhada como algo como 268435456, que equivale a 256 MB.
Por exemplo, você pode habilitar a memória compartilhada para reduzir gargalos quando estiver usando ligações de armazenamento de Blob para transferir cargas úteis maiores que 1 MB.
Essa funcionalidade está disponível apenas para aplicativos de função que estão sendo executados nos planos Premium e Dedicado (Serviço de Aplicativo do Azure). Para saber mais, consulte Memória compartilhada.
Problemas conhecidos e perguntas frequentes
Aqui estão dois guias de solução de problemas comuns:
Aqui estão dois guias de solução de problemas conhecidos com o modelo de programação v2:
- Não foi possível carregar arquivo ou assembly
- Não é possível resolver a conexão de Armazenamento do Azure chamada Armazenamento
Todos os problemas conhecidos e solicitações de recursos são rastreados em uma lista de problemas do GitHub. Se você tiver um problema e não conseguir encontrá-lo no GitHub, abra um novo problema e inclua uma descrição detalhada do problema.
Próximos passos
Para obter mais informações, consulte os seguintes recursos:
- Documentação da API do pacote do Azure Functions
- Best Practices for Azure Functions (Melhores Práticas para as Funções do Azure)
- Gatilhos e associações do Azure Functions
- Vinculações de Armazenamento de Blobs
- Ligações HTTP e webhook
- Ligações para armazenamento de filas
- Gatilhos de temporizador
Está tendo problemas com o uso do Python? Diga-nos o que está acontecendo.