Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Data Factory em Microsoft Fabric é a próxima geração de Azure Data Factory, com uma arquitetura mais simples, IA incorporada e novas funcionalidades. Se és novo na integração de dados, começa pelo Fabric Data Factory. As cargas de trabalho existentes do ADF podem atualizar para o Fabric para aceder a novas capacidades em ciência de dados, análise em tempo real e relatórios.
Os fluxos de dados estão disponíveis tanto nos pipelines do Azure Data Factory como no do Azure Synapse Analytics. Este artigo aplica-se ao mapeamento de fluxos de dados. Se você é novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Gorjeta
Para a transformação equivalente (Ordenar) no Dataflow Gen2, consulte Um guia para Dataflow Gen2 para mapear utilizadores de fluxo de dados.
A transformação de classificação permite classificar as linhas de entrada no fluxo de dados atual. Você pode escolher colunas individuais e classificá-las em ordem crescente ou decrescente.
Nota
Os fluxos de dados de mapeamento são executados em clusters spark que distribuem dados por múltiplos nós e partições. Se optar por reparticionar os seus dados numa transformação subsequente, pode perder a ordenação devido à reorganização dos dados. A melhor maneira de manter a ordem de classificação em seu fluxo de dados é definir uma única partição na guia Otimizar na transformação e manter a transformação Classificar o mais próximo possível do coletor.
Configuração
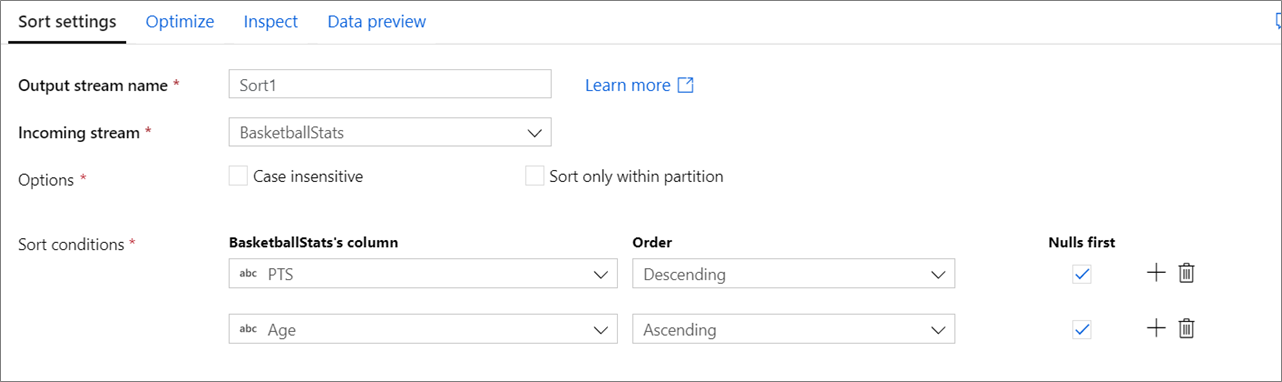
Não diferencia maiúsculas de minúsculas: se você deseja ou não ignorar maiúsculas e minúsculas ao classificar campos de cadeia de caracteres ou de texto
Classificar somente dentro de partições: Como os fluxos de dados são executados no spark, cada fluxo de dados é dividido em partições. Essa configuração classifica os dados somente dentro das partições de entrada, em vez de classificar todo o fluxo de dados.
Condições de classificação: escolha por quais colunas você está classificando e em que ordem a classificação acontece. A ordem determina a prioridade de classificação. Escolha se os nulos aparecem no início ou no fim do fluxo de dados.
Colunas computadas
Para modificar ou extrair um valor de coluna antes de aplicar a classificação, passe o mouse sobre a coluna e selecione "coluna computada". No construtor de expressões, crie uma expressão para a operação de ordenação em vez de usar um valor de coluna.
Script de fluxo de dados
Sintaxe
<incomingStream>
sort(
desc(<sortColumn1>, { true | false }),
asc(<sortColumn2>, { true | false }),
...
) ~> <sortTransformationName<>
Exemplo
O script de fluxo de dados para a configuração de classificação acima está no trecho de código abaixo.
BasketballStats sort(desc(PTS, true),
asc(Age, true)) ~> Sort1
Conteúdos relacionados
Depois de ordenar, pode querer usar a Transformação Agregada