Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Experimente Data Factory no Microsoft Fabric, uma solução de análise completa para empresas. Microsoft Fabric abrange tudo, desde a movimentação de dados até à ciência de dados, análises em tempo real, inteligência empresarial e relatórios. Saiba como iniciar um novo teste gratuitamente!
Os fluxos de dados estão disponíveis nos pipelines do Azure Data Factory e no Azure Synapse Analytics. Este artigo aplica-se ao mapeamento de fluxos de dados. Se você é novo em transformações, consulte o artigo introdutório Transformar dados usando fluxos de dados de mapeamento.
Uma transformação de fonte configura a sua fonte de dados para o fluxo de dados. Quando desenha fluxos de dados, o primeiro passo é sempre configurar uma transformação de fonte. Para adicionar uma fonte, selecione a caixa Adicionar Fonte na tela do fluxo de dados.
Cada fluxo de dados requer pelo menos uma transformação de fonte, mas pode adicionar tantas fontes quanto necessário para completar as suas transformações de dados. Pode juntar essas fontes através de uma junção, pesquisa ou transformação sindical.
Cada transformação de fonte está associada a exatamente um conjunto de dados ou serviço ligado. O conjunto de dados define a forma e a localização dos dados nos quais pretende escrever ou ler. Se usar um conjunto de dados baseado em ficheiros, pode usar caracteres curinga e listas de ficheiros na sua fonte para trabalhar com mais do que um ficheiro simultaneamente.
Conjuntos de dados embutidos
A primeira decisão que toma ao criar uma transformação de fonte é se a sua informação de fonte está definida dentro de um objeto de conjunto de dados ou dentro da transformação de fonte. A maioria dos formatos está disponível em apenas um ou outro. Para saber como usar um conector específico, consulte o documento do conector apropriado.
Quando um formato é suportado tanto em linha como num objeto de conjunto de dados, há benefícios para cada um. Os objetos de conjunto de dados são entidades reutilizáveis que podem ser usadas em outros fluxos de dados e atividades, como Copiar. Essas entidades reutilizáveis são especialmente úteis quando você usa um esquema protegido. Os conjuntos de dados não são baseados no Spark. Ocasionalmente, pode ser necessário sobrescrever certas definições ou projeção de esquema na transformação de código-fonte.
Conjuntos de dados inline são recomendados quando se utilizam esquemas flexíveis, instâncias de fonte única ou fontes parametrizadas. Se a sua fonte for fortemente parametrizada, os conjuntos de dados inline permitem não criar um objeto "fictício". Os conjuntos de dados embutidos são baseados no Spark e suas propriedades são nativas do fluxo de dados.
Para usar um conjunto de dados inline, selecione o formato que pretende no seletor de tipos de Fonte . Em vez de selecionar um conjunto de dados de origem, seleciona o serviço ligado ao qual quer ligar-se.
Opções de esquema
Como um conjunto de dados inline é definido dentro do fluxo de dados, não existe um esquema definido associado ao conjunto de dados inline. No separador Projeção, podes importar o esquema de dados de origem e armazenar esse esquema como a tua projeção de origem. Neste separador, encontras um botão "Opções de esquema" que te permite definir o comportamento do serviço de descoberta de esquemas do ADF.
- Utilizar o esquema projetado: Esta opção é útil quando tiver um grande número de ficheiros de origem que o ADF verifica como a sua fonte. O comportamento padrão do ADF é descobrir o esquema de cada ficheiro fonte. Mas se já tiveres uma projeção pré-definida armazenada na transformação da fonte, podes definir isto para true e o ADF evita a descoberta automática de todos os esquemas. Com esta opção ativada, a transformação de origem pode ler todos os ficheiros de forma muito mais rápida, aplicando o esquema pré-definido a cada ficheiro.
- Permitir desvio de esquema: Ative o desvio de esquema para que o seu fluxo de dados permita novas colunas que ainda não estejam definidas no esquema de origem.
- Validar esquema: Definir esta opção faz com que o fluxo de dados falhe se qualquer coluna e tipo definidos na projeção não corresponderem ao esquema descoberto dos dados de origem.
- Inferir tipos de colunas com desvio: Quando novas colunas com desvio são identificadas pelo ADF, essas novas colunas são convertidas para o tipo de dados apropriado usando a inferência automática de tipos do ADF.
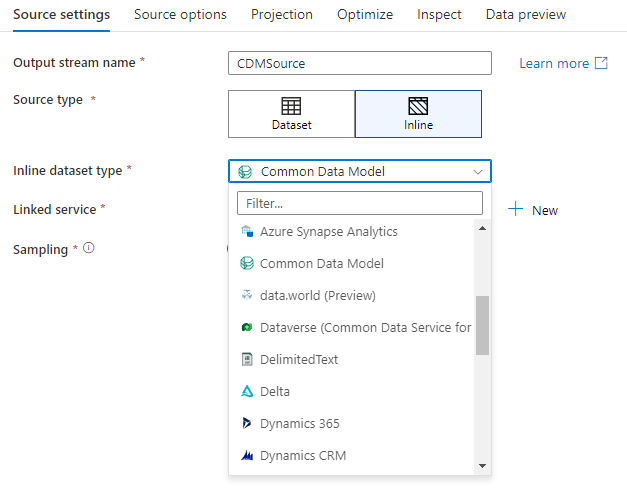
Base de dados do espaço de trabalho (apenas para espaços de trabalho Synapse)
Nos espaços de trabalho Azure Synapse, existe uma opção adicional nas transformações da fonte de fluxo de dados chamada Workspace DB. Isto permite-lhe escolher diretamente uma base de dados de workspace de qualquer tipo disponível como dados de origem, sem necessidade de serviços ou conjuntos de dados ligados adicionais. Os bancos de dados criados por meio dos modelos de banco de dados do Azure Synapse também são acessíveis quando você seleciona Banco de Dados de Espaço de Trabalho.
Tipos de fonte suportados
O fluxo de dados de mapeamento segue uma abordagem ELT (extração, carga e transformação) e funciona com conjuntos de dados de preparo que estão todos no Azure. Atualmente, os seguintes conjuntos de dados podem ser usados numa transformação de fonte.
As definições específicas destes conectores encontram-se no separador de opções de origem . Exemplos de scripts de informação e fluxo de dados nestas definições encontram-se na documentação do conector.
Os pipelines Azure Data Factory e Synapse têm acesso a mais de 90 conectores nativos. Para incluir dados dessas outras fontes no fluxo de dados, use a atividade de cópia para carregar esses dados numa das áreas de preparo suportadas.
Definições de origem
Depois de adicionares uma fonte, configura através do separador de definições de Fonte . Aqui pode escolher ou criar o conjunto de dados para onde a sua fonte aponta. Também pode selecionar opções de esquema e amostragem para os seus dados.
Os valores de desenvolvimento dos parâmetros do conjunto de dados podem ser configurados em definições de depuração. (O modo de depuração deve estar ativado.)
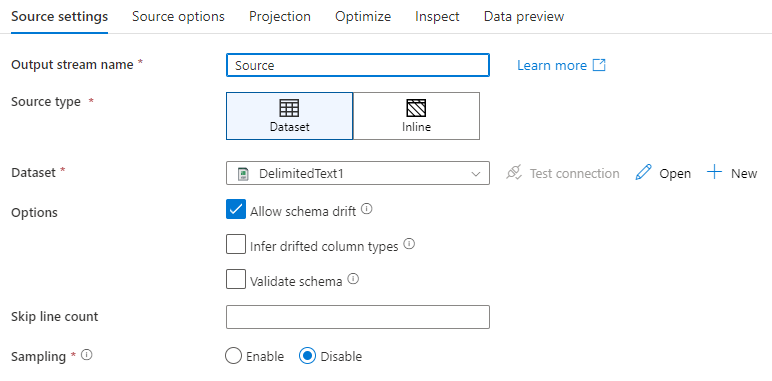
Nome do fluxo de saída: O nome da transformação de origem.
Tipo de fonte: Escolha se quer usar um conjunto de dados inline ou um objeto de conjunto de dados existente.
Teste a ligação: Teste se o serviço Spark do fluxo de dados consegue ligar com sucesso ao serviço ligado usado no seu conjunto de dados de origem. O modo de depuração deve estar ativado para que esta funcionalidade esteja ativada.
Desvio de esquema: desvio de esquema é a capacidade do serviço de lidar nativamente com esquemas flexíveis em seus fluxos de dados sem a necessidade de definir explicitamente as alterações de coluna.
Selecione a caixa Permitir desvio de esquema se as colunas de origem mudarem frequentemente. Esta configuração permite que todos os campos fonte de entrada fluam através das transformações até ao sumidouro.
Selecionar Inferir tipos de colunas derivadas instrui o serviço a detetar e definir tipos de dados para cada nova coluna descoberta. Com esta funcionalidade desligada, todas as colunas desviadas são de tipo string.
Validar esquema: Se for selecionado o esquema Validar , o fluxo de dados falha em correr se os dados fonte recebidos não corresponderem ao esquema definido do conjunto de dados.
Saltar contagem de linhas: O campo Saltar contagem de linhas especifica quantas linhas ignorar no início do conjunto de dados.
Amostragem: Ative a Amostragem para limitar o número de linhas da sua fonte. Use esta definição quando testar ou amostrar dados da sua fonte para fins de depuração. Isto é muito útil quando se executam fluxos de dados a partir de um pipeline em modo de depuração.
Para validar que a sua fonte está configurada corretamente, ative o modo de depuração e obtenha uma pré-visualização de dados. Para mais informações, veja Modo Debug.
Nota
Quando o modo de depuração está ativado, a configuração do limite de linhas nas definições de depuração sobrescreve a definição de amostragem na fonte durante a pré-visualização dos dados.
Opções de origem
O separador Opções de Origem contém definições específicas para o conector e formato escolhidos. Para mais informações e exemplos, consulte a documentação relevante do conector. Isto inclui detalhes como o nível de isolamento das fontes de dados que o suportam (como SQL Servers localizados, Bases de Dados SQL do Azure e instâncias geridas por Azure SQL), e outras configurações específicas de fontes de dados.
Projeção
Tal como os esquemas em conjuntos de dados, a projeção numa fonte define as colunas, tipos e formatos de dados a partir dos dados fonte. Para a maioria dos tipos de conjuntos de dados, como SQL e Parquet, a projeção numa fonte é fixa para refletir o esquema definido num conjunto de dados, que variará consoante a fonte. Quando os seus ficheiros de origem não são fortemente tipados (por exemplo, ficheiros simples .csv em vez de ficheiros Parquet), pode definir os tipos de dados para cada campo na transformação de origem. A imagem seguinte mostra uma projeção de exemplo:
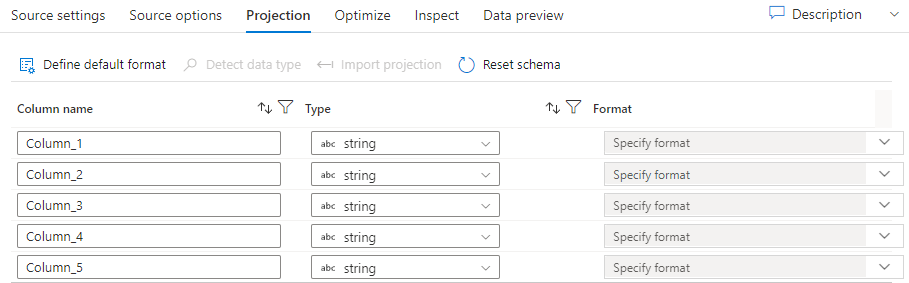
Se o seu ficheiro de texto não tiver um esquema definido, selecione Detetar tipo de dado para que o serviço amostre e infira os tipos de dados. Selecione Definir formato predefinido para detetar automaticamente os formatos de dados predefinidos.
O esquema de reset reinicia a projeção para o que está definido no conjunto de dados referenciado.
Sobrescrever esquema permite modificar os tipos de dados projetados aqui na fonte, sobrescrevendo os tipos de dados definidos pelo esquema. Alternativamente, pode modificar os tipos de dados das colunas numa transformação de colunas derivadas a jusante. Use uma transformação select para modificar os nomes das colunas.
Esquema de importação
Selecione o botão Importar esquema no separador Projeção para usar um cluster de depuração ativo para criar uma projeção de esquema. Está disponível em todos os tipos de fonte. Importar o esquema aqui sobrepõe-se à projeção definida no conjunto de dados. O objeto do conjunto de dados não será alterado.
Importar esquemas é útil em conjuntos de dados como o Avro e o Azure Cosmos DB, que suportam estruturas de dados complexas que não exigem definições de esquema no conjunto de dados. Para conjuntos de dados inline, importar o esquema é a única forma de referenciar metadados das colunas sem desvio do esquema.
Otimizar a transformação da fonte
O separador Otimizar permite editar informação de partição em cada etapa de transformação. Na maioria dos casos, Use current partitioning otimiza para a estrutura de partição ideal para uma fonte.
Se estiveres a ler a partir de uma base de dados Azure SQL, a particionação personalizada de fontes provavelmente lê os dados mais rapidamente. O serviço lê consultas grandes ao fazer ligações paralelas à sua base de dados. Esta partição de origem pode ser feita numa coluna ou através de uma consulta.
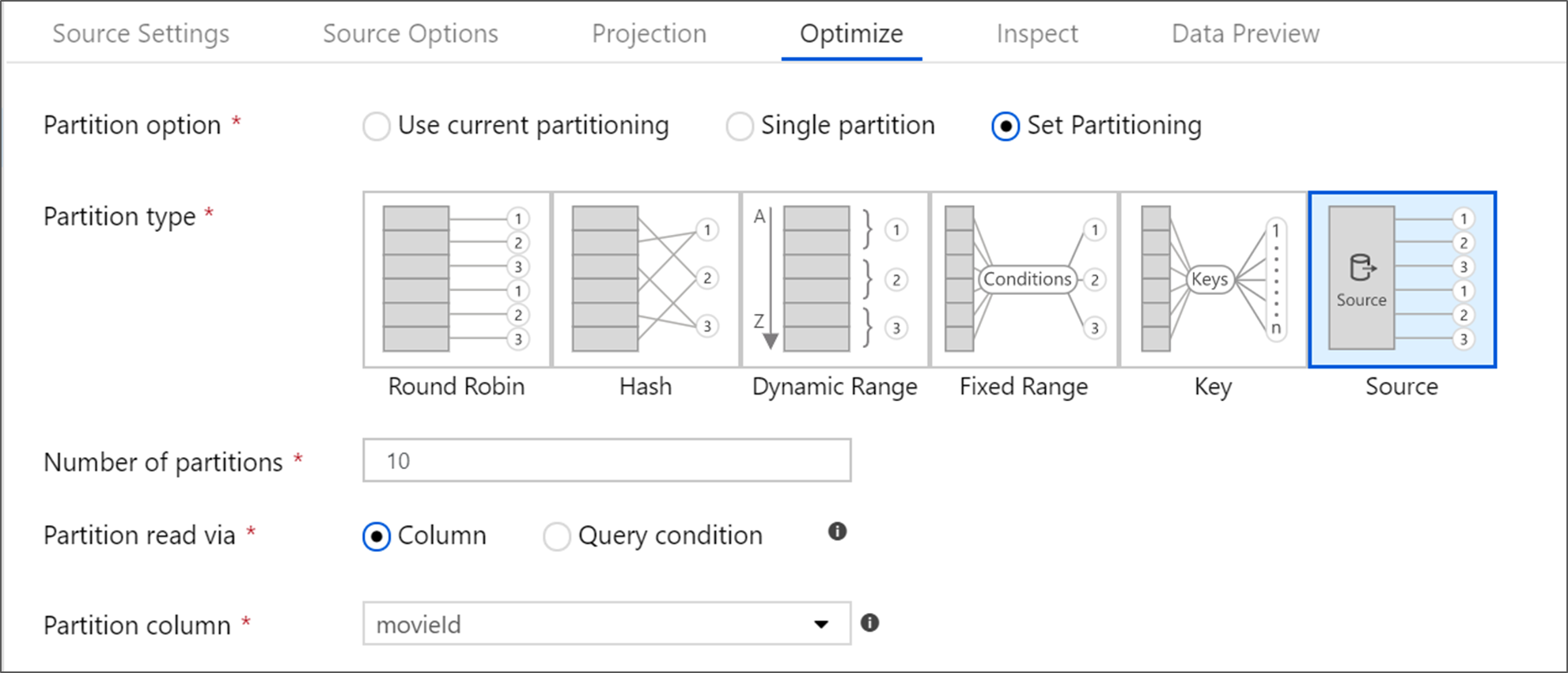
Para mais informações sobre otimização dentro do mapeamento do fluxo de dados, consulte a Aba Otimizar.
Conteúdo relacionado
Comece a construir o seu fluxo de dados com uma transformação de coluna derivada e uma transformação de seleção.