Transformar dados na Rede Virtual do Azure usando a atividade do Hive no Azure Data Factory usando o portal do Azure
APLICA-SE A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Neste tutorial, vai utilizar o portal do Azure para criar um pipeline do Data Factory que transforma os dados com a Atividade do Hive num cluster HDInsight que se encontra numa Rede Virtual do Azure (VNet). Vai executar os seguintes passos neste tutorial:
- Criar uma fábrica de dados.
- Criar um integration runtime autoalojado
- Criar os serviços ligados Armazenamento do Azure e Azure HDInsight
- Criar um pipeline com a atividade Hive.
- Acionar uma execução de pipeline.
- Monitorizar a execução do pipeline.
- Verificar a saída
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Nota
Recomendamos que utilize o módulo Azure Az do PowerShell para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo do Az PowerShell, veja Migrar o Azure PowerShell do AzureRM para o Az.
Conta do Armazenamento do Azure. Tem de criar um script do Hive e carregá-lo para o armazenamento do Azure. A saída do script do Hive é armazenada nesta conta de armazenamento. Neste exemplo, o cluster HDInsight utiliza esta conta de Armazenamento do Azure como armazenamento primário.
Rede virtual do Azure. Se não tiver uma rede virtual do Azure, crie-a seguindo estas instruções. Neste exemplo, o HDInsight está numa Rede Virtual do Azure. Eis um exemplo de configuração da Rede Virtual do Azure.
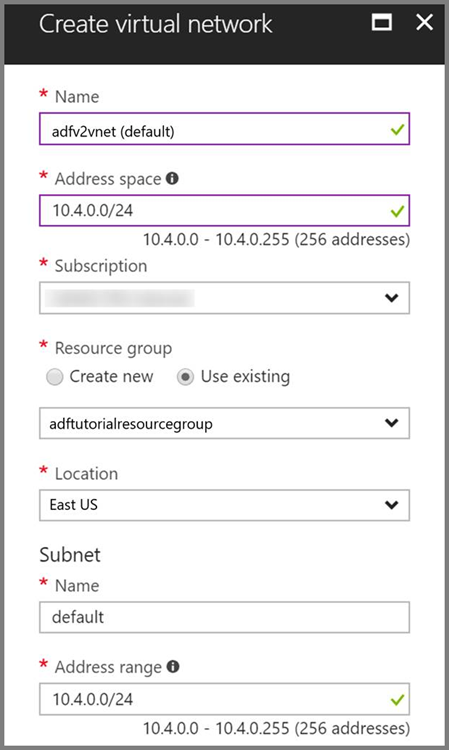
Cluster HDInsight. Crie um cluster HDInsight e associe-o à rede virtual que criou no passo anterior, seguindo este artigo: Extend Azure HDInsight using an Azure Virtual Network (Expandir o Azure HDInsight com uma Rede Virtual do Azure). Eis um exemplo de configuração do HDInsight numa rede virtual.
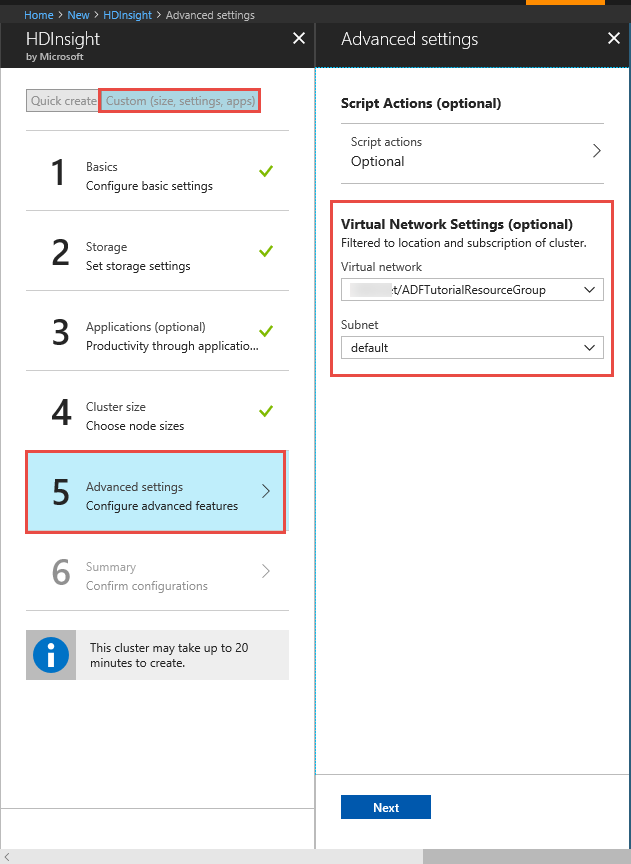
Azure PowerShell. Siga as instruções em How to install and configure Azure PowerShell (Como instalar e configurar o Azure PowerShell).
Uma máquina virtual. Crie uma máquina virtual do Azure e associe-a à mesma rede virtual que contém o cluster HDInsight. Para obter mais detalhes, veja Como criar máquinas virtuais.
Carregar o script do Hive para uma conta de Armazenamento de Blobs
Crie um ficheiro SQL do Hive com o nome hivescript.hql com o seguinte conteúdo:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableNo Armazenamento de Blobs do Azure, crie um contentor com o nome adftutorial, caso ainda não exista.
Crie uma pasta com o nome hiverscripts.
Carregue o ficheiro hivescript.hql para a sub-pasta hivescripts.
Criar uma fábrica de dados
Se você ainda não criou sua fábrica de dados, siga as etapas em Guia de início rápido: criar uma fábrica de dados usando o portal do Azure e o Azure Data Factory Studio para criar uma. Depois de criá-lo, navegue até o data factory no portal do Azure.
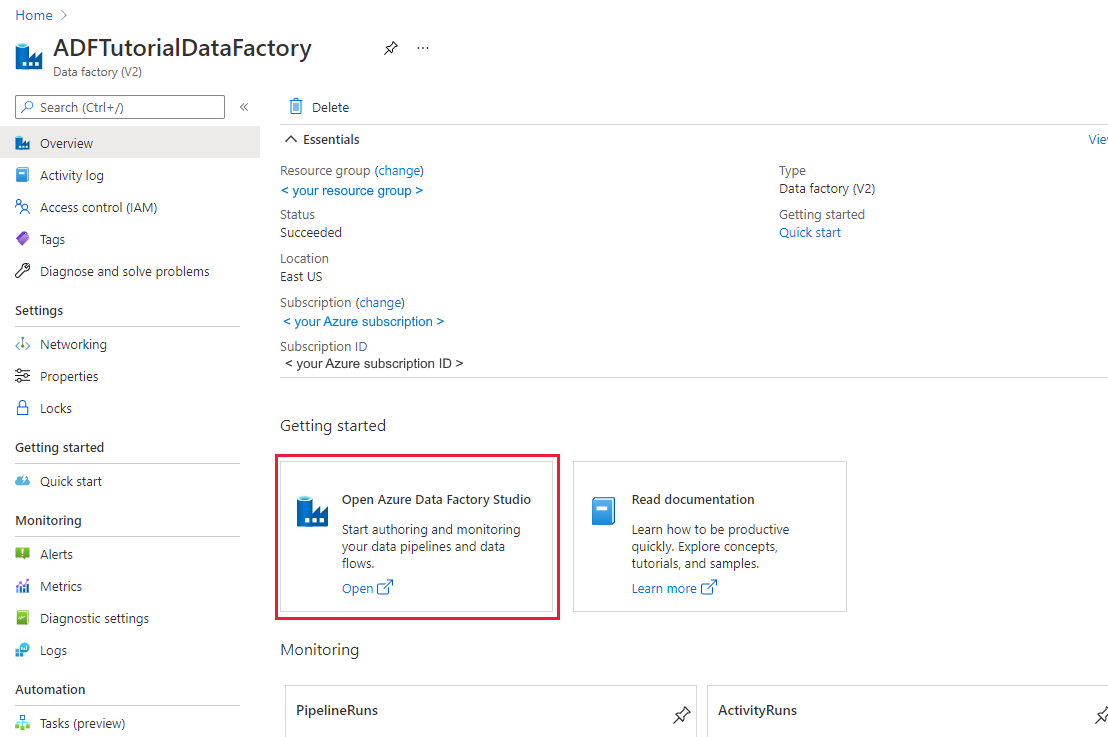
Selecione Abrir no bloco Abrir o Azure Data Factory Studio para iniciar o aplicativo Integração de Dados em uma guia separada.
Criar um integration runtime autoalojado
Uma vez que o cluster do Hadoop está dentro de uma rede virtual, tem de instalar um runtime de integração (IR) autoalojado nessa rede virtual. Nesta secção, vai criar uma VM nova, associá-la à mesma rede virtual e instalar o IR autoalojado nesta. O IR autoalojado permite ao serviço Data Factory enviar pedidos de processamento para um serviço de computação, como o HDInsight, dentro de uma rede virtual. Também lhe permite mover dados de e para os arquivos de dados que estejam dentro de uma rede virtual do Azure. Utilize um IR autoalojado quando o arquivo de dados ou a computação também está num ambiente no local.
Na IU do Azure Data Factory, clique em Ligações, na parte inferior da janela, mude para o separador Runtimes de Integração e clique no botão + Novo, na barra de ferramentas.
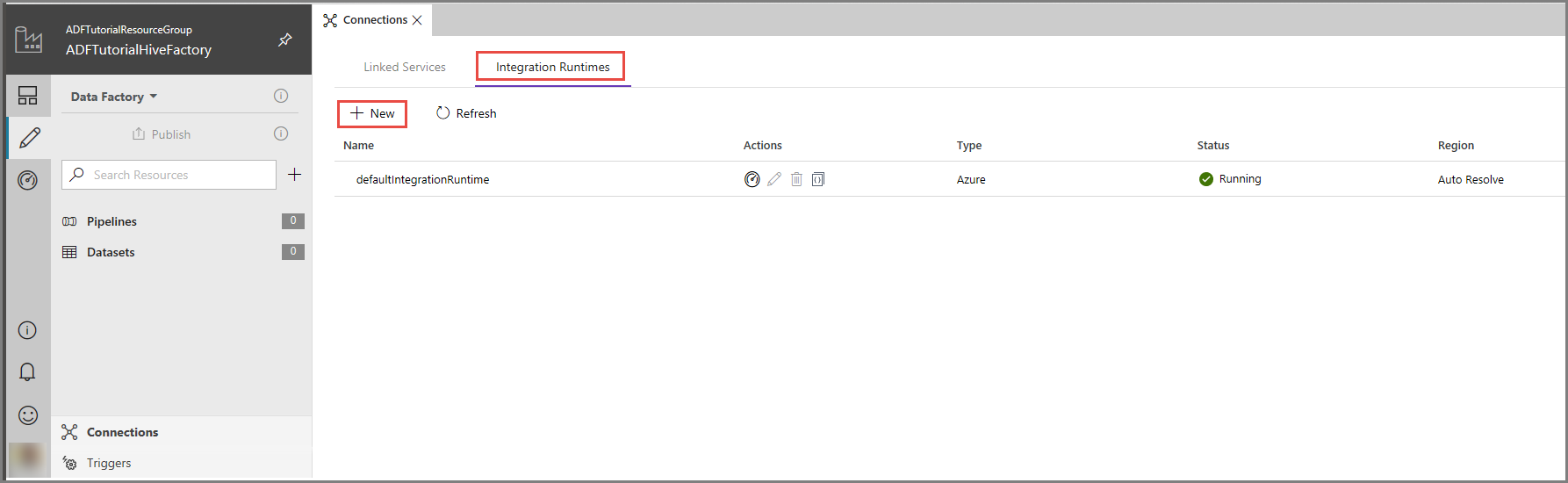
Na janela Configuração do Runtime de Integração, selecione a opção Realizar movimento de dados e enviar atividades para computações externas e clique em Seguinte.
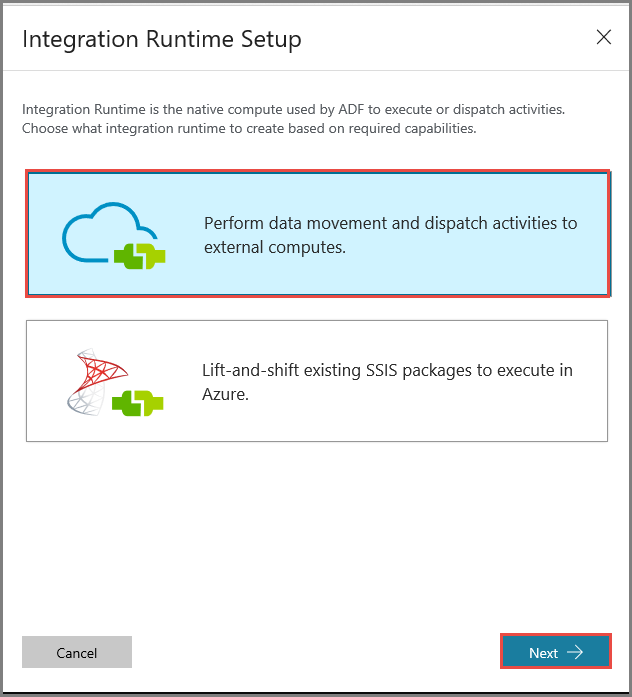
Selecione Rede Privada e clique em Seguinte.
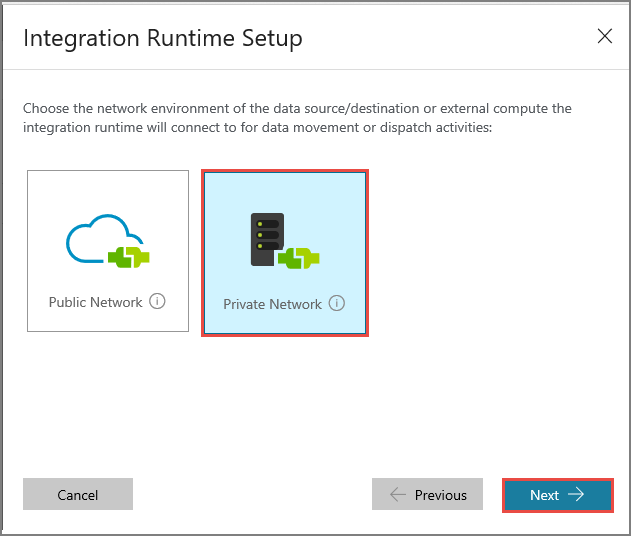
Introduza MySelfHostedIR em Nome e clique em Seguinte.
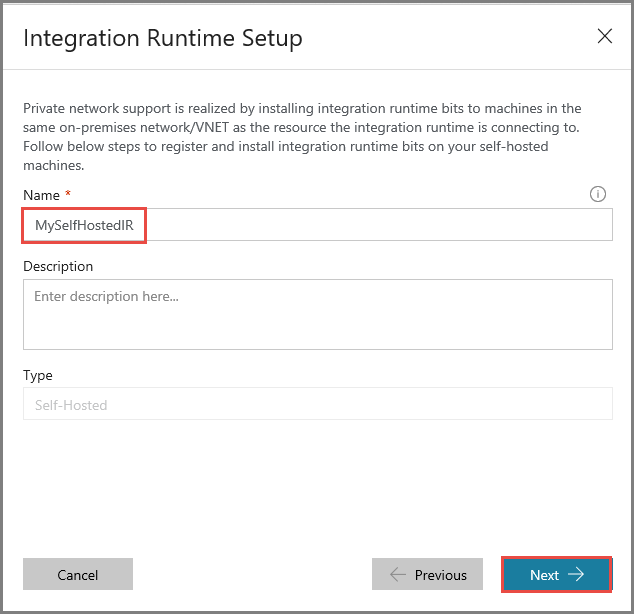
Copie a chave de autenticação do runtime de integração, clicando no botão para copiar, e guarde-a. Mantenha a janela aberta. Esta chave vai ser utilizada para registar o IR instalado numa máquina virtual.
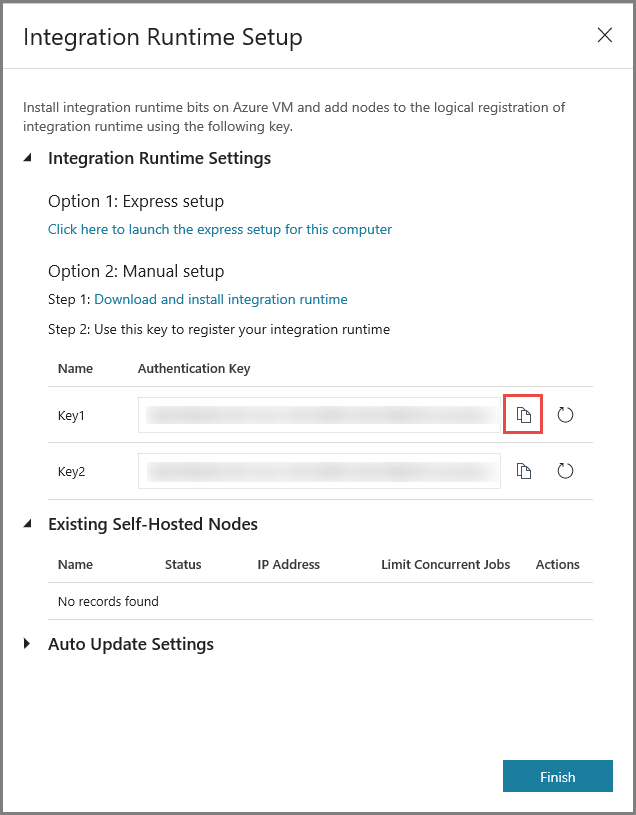
Instalar o IR numa máquina virtual
Na VM do Azure, transfira o integration runtime autoalojado. Utilize a chave de Autenticação que obteve no passo anterior para registar manualmente o runtime de integração autoalojado.
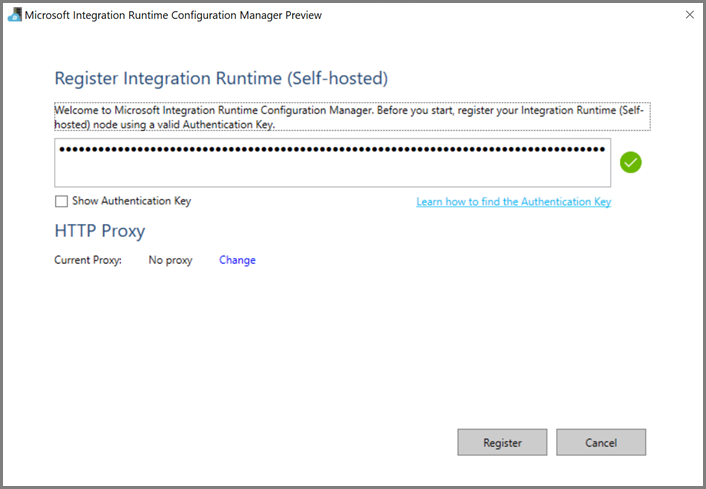
Quando o integration runtime autoalojado for registado com êxito, verá a mensagem seguinte.
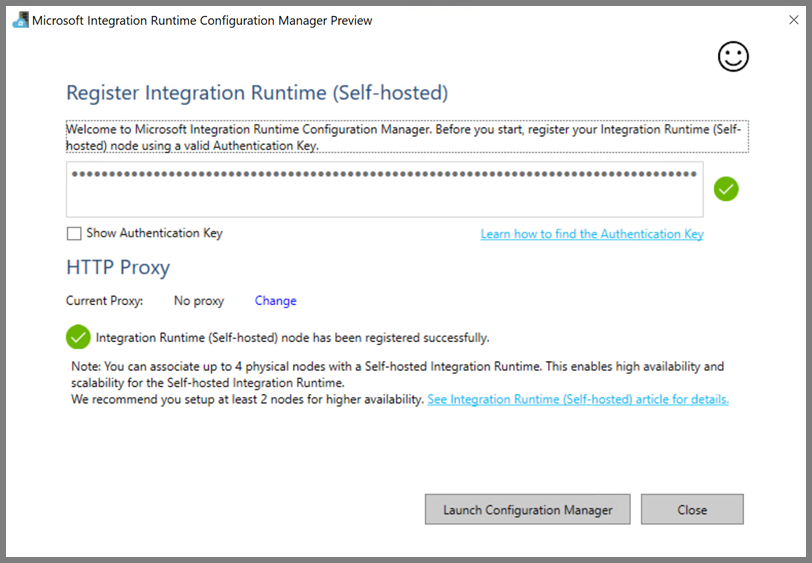
Clique em Iniciar Configuration Manager. Quando o nó for ligado ao serviço cloud, verá a página seguinte:
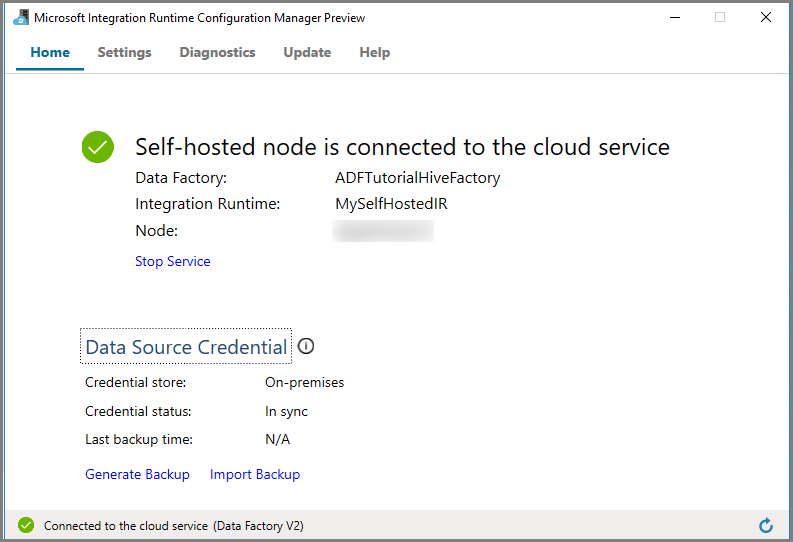
IR autoalojado na IU do Azure Data Factory
Na IU do Azure Data Factory, deverá ver o nome da VM autoalojada e o respetivo estado.
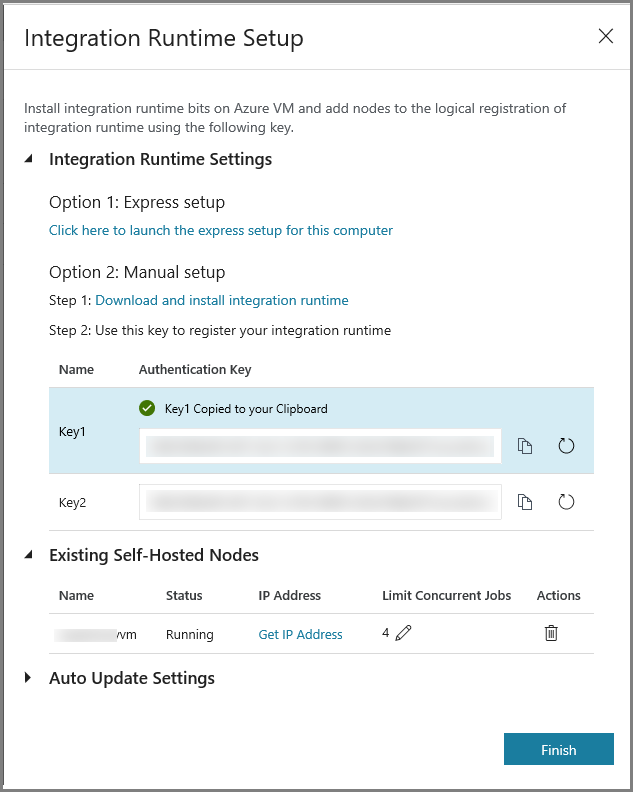
Clique em Concluir para fechar a janela Configuração do Runtime de Integração. Verá o IR autoalojado na lista de runtimes de integração.

Criar serviços ligados
Nesta secção, vai criar e implementar dois Serviços Ligados:
- Um Serviço Ligado do Armazenamento do Azure que liga uma conta de Armazenamento do Azure à fábrica de dados. Este armazenamento é o armazenamento primário utilizado pelo cluster HDInsight. Neste caso, vai utilizar esta conta de Armazenamento do Azure para guardar o script do Hive e a saída do script.
- Um Serviço Ligado do HDInsight. O Azure Data Factory envia o script do Hive a este cluster HDInsight para execução.
Criar o serviço ligado do Storage do Azure
Mude para o separador Serviços Ligados e clique em Novo.
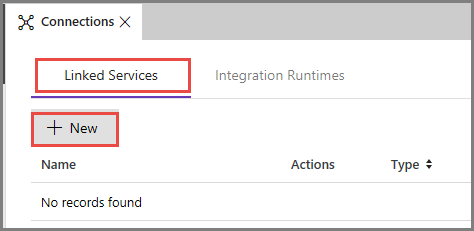
Na janela Novo Serviço Ligado, selecione Armazenamento de Blobs do Azure e clique em Continuar.
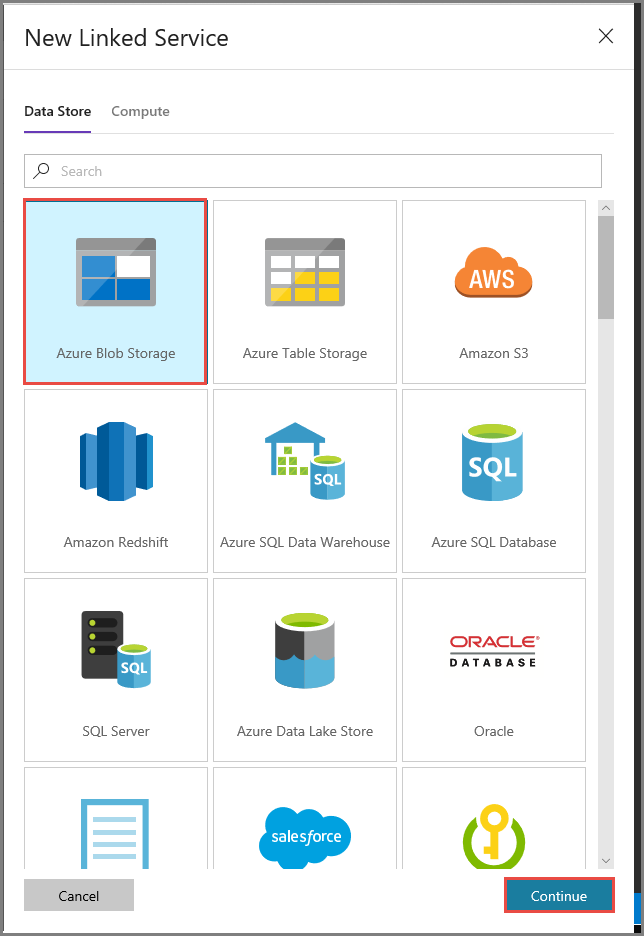
Na janela Novo Serviço Ligado, siga os passos abaixo:
Introduza AzureStorageLinkedService em Nome.
Selecione MySelfHostedIR em Ligar através do runtime de integração.
Selecione a sua conta de Armazenamento do Azure em Nome da conta de armazenamento.
Para testar a ligação à conta de armazenamento, clique em Testar ligação.
Clique em Guardar.
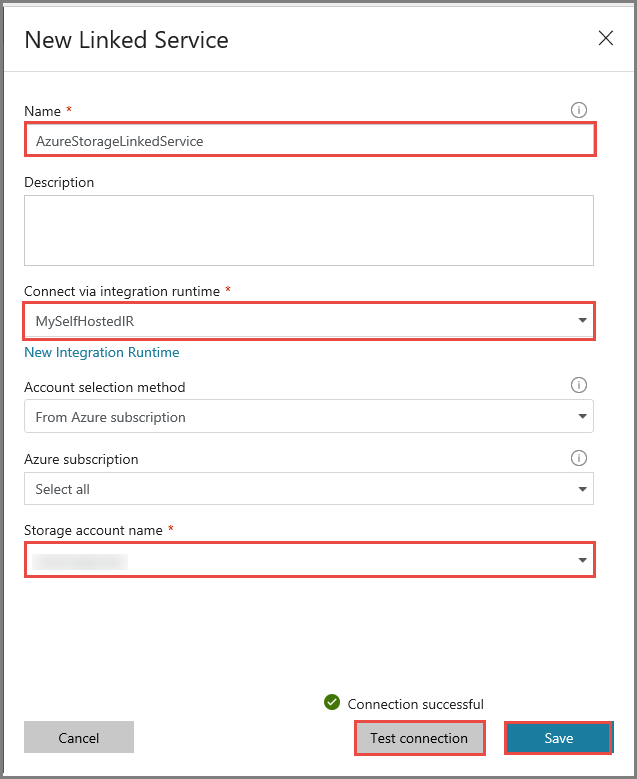
Criar serviço ligado do HDInsight
Clique novamente em novo para criar outro serviço ligado.
Mude para o separador Computação, selecione Azure HDInsight e clique em Continuar.
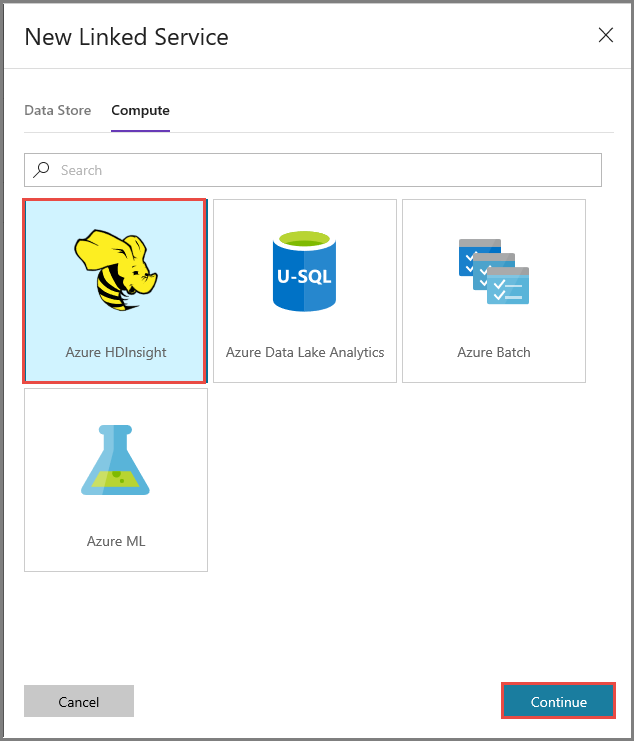
Na janela Novo Serviço Ligado, siga os passos abaixo:
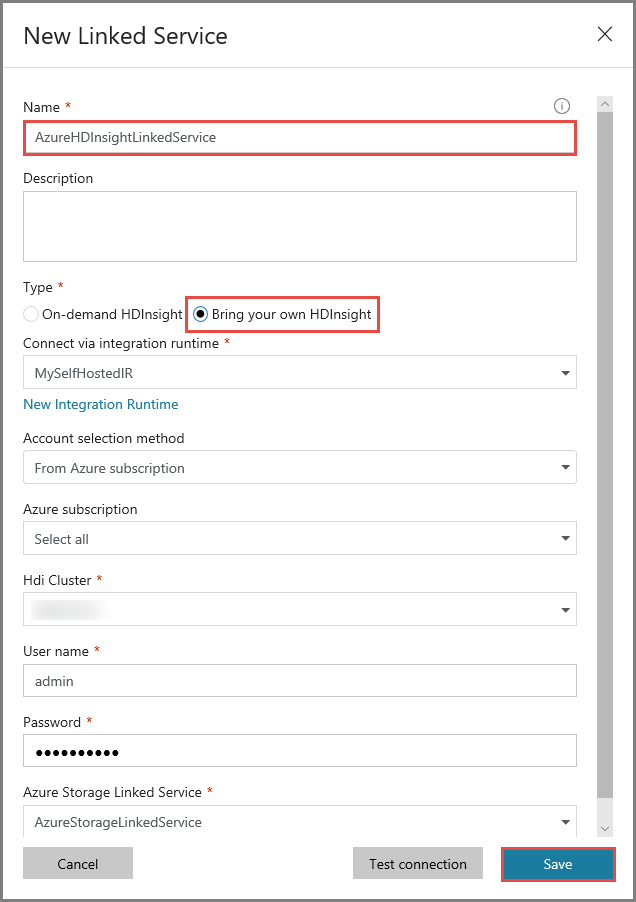
Introduza AzureHDInsightLinkedService em Nome.
Selecione Trazer o seu próprio HDInsight.
Selecione o cluster do HDInsight em Cluster do Hdi.
Introduza o nome de utilizador do cluster do HDInsight.
Introduza a palavra-passe do utilizador.
Este artigo pressupõe que tem acesso ao cluster através da Internet. Por exemplo, que pode ligar ao cluster em https://clustername.azurehdinsight.net. Este endereço utiliza o gateway público, que não está disponível se tiver utilizado grupos de segurança de rede (NSGs) ou rotas definidas pelo utilizador (UDRs) para restringir o acesso a partir da Internet. Para que o Data Factory consiga submeter tarefas ao cluster HDInsight na Rede Virtual do Azure, precisa de configurar a Rede Virtual do Azure de forma a que o URL possa ser resolvido para o endereço IP privado do gateway utilizado pelo HDInsight.
A partir do portal do Azure, abra a Rede Virtual onde o HDInsight se encontra. Abra a interface de rede com o nome começado por
nic-gateway-0. Tome nota do endereço IP privado. Por exemplo, 10.6.0.15.Se a sua Rede Virtual do Azure tiver um servidor DNS, atualize o registo DNS de forma a que o URL do cluster HDInsight
https://<clustername>.azurehdinsight.netpossa ser resolvido para10.6.0.15. Se não tiver um servidor DNS na sua Rede Virtual do Azure, pode solucionar temporariamente este problema ao editar o ficheiro de anfitriões (C:\Windows\System32\drivers\etc) de todas as VMs registadas como nós de runtime de integração autoalojado, adicionando uma entrada semelhante a:10.6.0.15 myHDIClusterName.azurehdinsight.net
Criar um pipeline
Neste passo, vai criar um novo pipeline com uma atividade do Hive. A atividade executa o script do Hive para devolver dados de uma tabela de exemplo e guardá-los no caminho que definiu.
Tenha em conta os seguintes pontos:
- scriptPath aponta para o caminho do script do Hive na Conta de Armazenamento do Azure que utilizou para MyStorageLinkedService. O caminho é sensível a maiúsculas e minúsculas.
- Output é um argumento utilizado no script do Hive. Utilize o formato
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/para apontá-lo para uma pasta existente no seu Armazenamento do Azure. O caminho é sensível a maiúsculas e minúsculas.
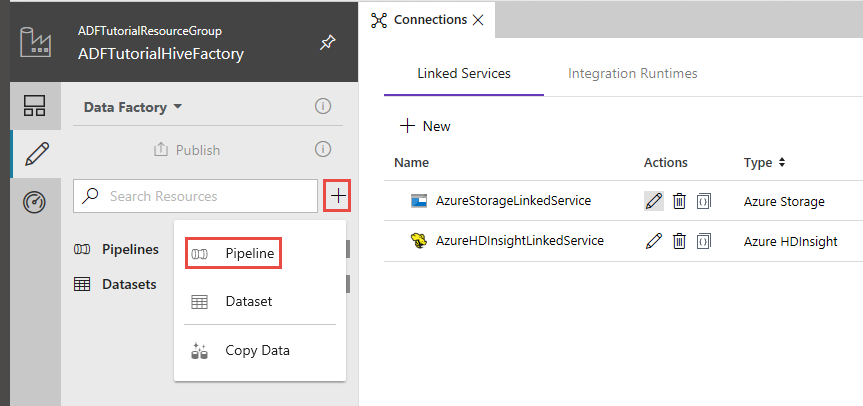
Na IU do Data Factory, clique em + (mais), no painel do lado esquerdo, e clique em Pipeline.
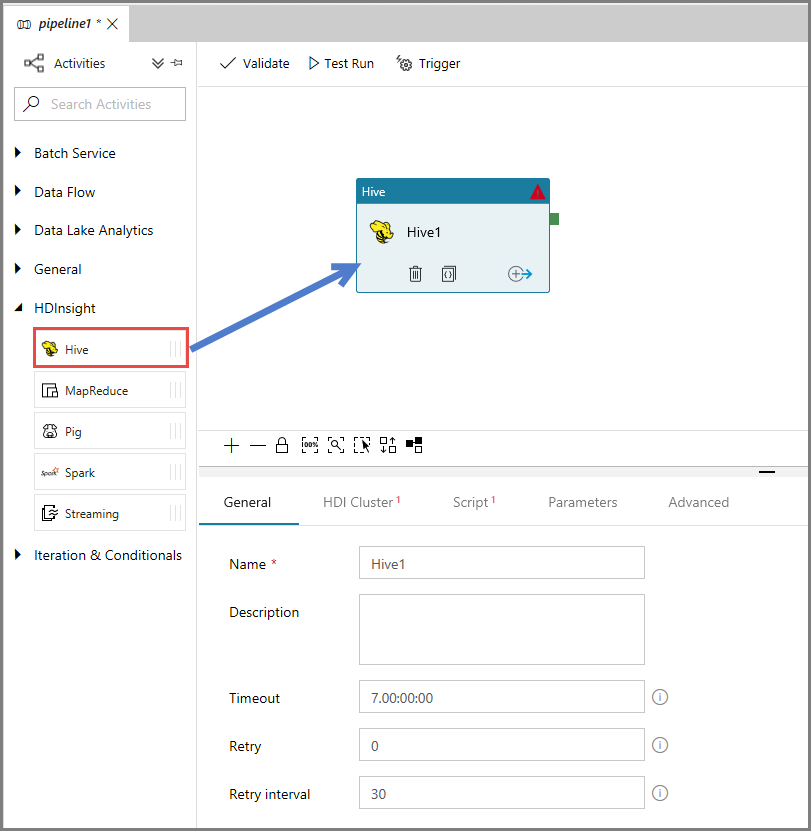
Na caixa de ferramentas Atividades, expanda HDInsight e arraste e largue a atividade Hive na superfície de desenho do pipeline.
Na janela de propriedades, mude para o separador Cluster do HDI e selecione AzureHDInsightLinkedService em Serviço Ligado do HDInsight.

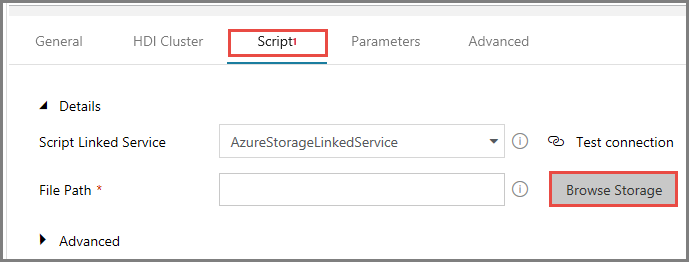
Mude para o separador Scripts e siga os passos abaixo:
Selecione AzureStorageLinkedService em Serviço Ligado de Script.
Em Caminho do Ficheiro, clique em Procurar no Armazenamento.
Na janela Escolher um ficheiro ou pasta, navegue para a pasta hivescripts do contentor adftutorial, selecione hivescript.hql e clique em Concluir.
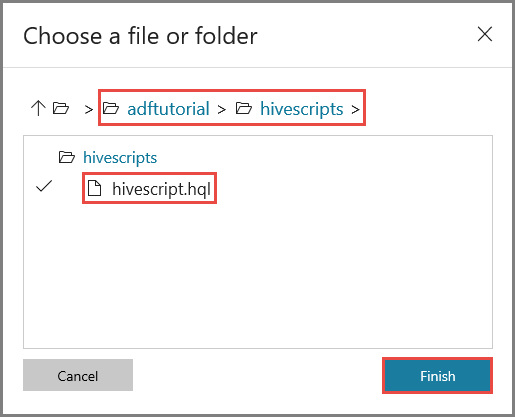
Confirme que vê adftutorial/hivescripts/hivescript.hql em Caminho do Ficheiro.
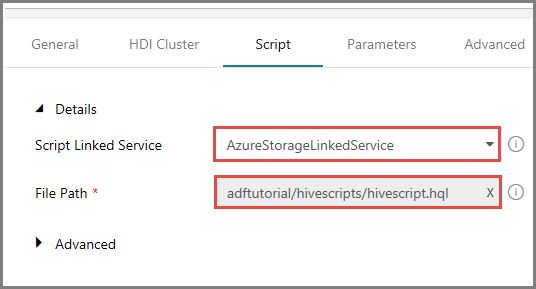
No separador Script, expanda a secção Avançadas.
Clique em Preencher automaticamente a partir do script em Parâmetros.
Introduza o valor para o parâmetro Saída no formato
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Por exemplo:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.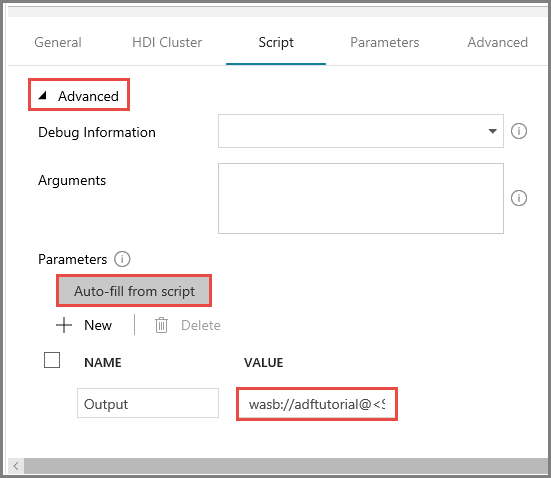
Para publicar os artefactos no Data Factory, clique em Publicar.
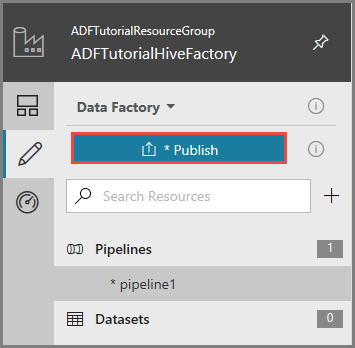
Acionar uma execução de pipeline
Em primeiro lugar, clique no botão Validar, na barra de ferramentas, para validar o pipeline. Feche a janela Saída de Validação de Pipeline clicando na seta para a direita (>>).
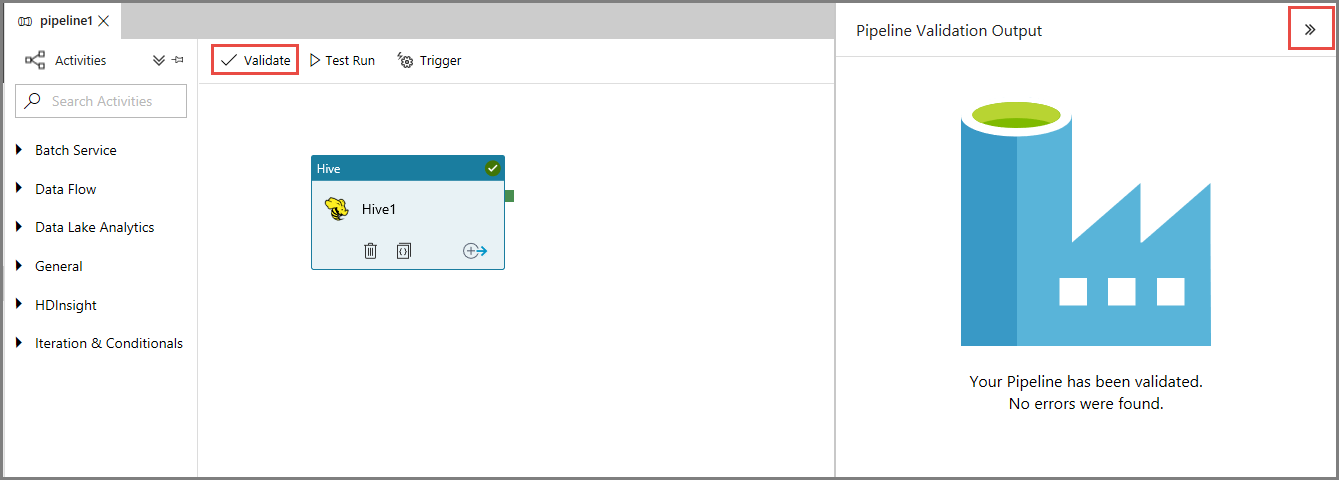
Para acionar uma execução de pipeline, clique em Acionar, na barra de ferramentas, e clique em Acionar Agora.
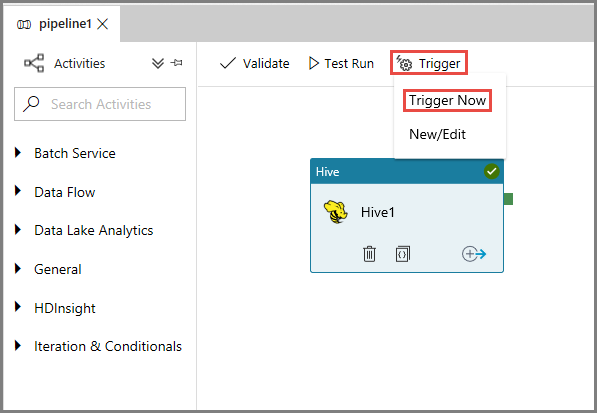
Monitorizar a execução do pipeline.
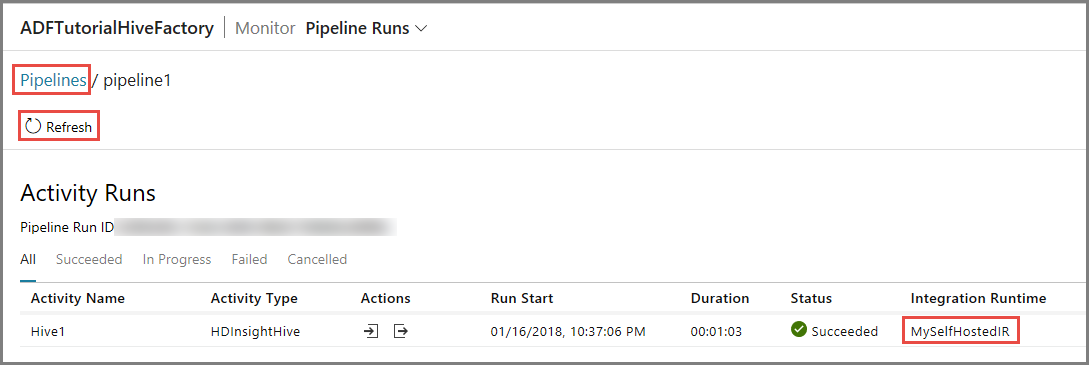
Mude para o separador Monitorizar, no lado esquerdo. Verá uma execução de pipeline na lista Execuções de Pipeline.
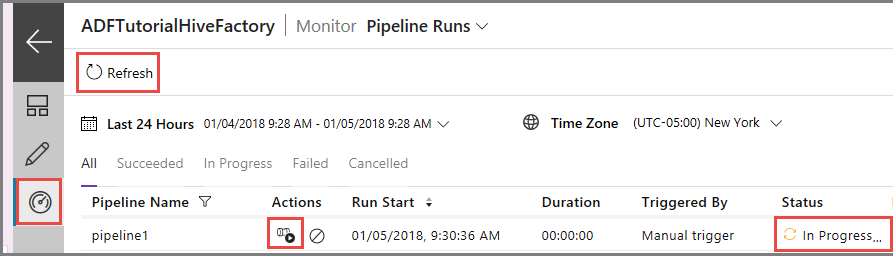
Para atualizar a lista, clique em Atualizar.
Para ver as execuções de atividades associadas às execução de pipeline, clique em Ver Execuções de Atividades, na coluna Ação. As outras ligações de ação servem para parar/voltar a executar o pipeline.
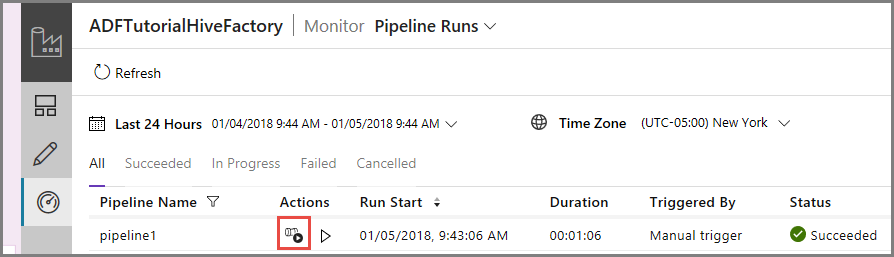
Vai ver apenas uma execução de atividade, porque só existe uma atividade no pipeline do tipo HDInsightHive. Para regressar à vista anterior, clique na ligação Pipelines, na parte superior.
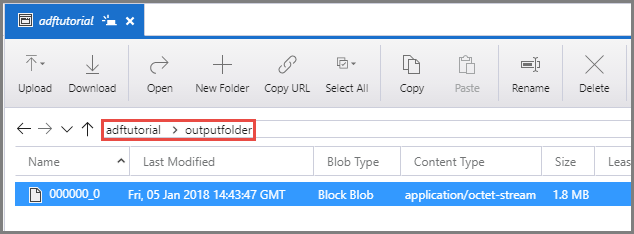
Confirme que vê um ficheiro de saída em outputfolder do contentor adftutorial.
Conteúdos relacionados
Neste tutorial, executou os passos seguintes:
- Criar uma fábrica de dados.
- Criar um integration runtime autoalojado
- Criar os serviços ligados Armazenamento do Azure e Azure HDInsight
- Criar um pipeline com a atividade Hive.
- Acionar uma execução de pipeline.
- Monitorizar a execução do pipeline.
- Verificar a saída
Avance para o tutorial seguinte para saber como transformar dados através de um cluster do Spark no Azure:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários