Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Aplica-se a:![]() SQL Server
SQL Server
A partir do SQL Server 2016, a opção de monitorização de integridade ao nível da base de dados (DB_FAILOVER) está disponível ao configurar um grupo de disponibilidade "Always On". A verificação de integridade ao nível da base de dados detecta quando uma base de dados já não está no estado online, quando ocorre um problema, e ativa o failover automático do grupo de disponibilidade. Exemplos que podem desencadear a deteção de saúde incluem base de dados em modo suspeito, base de dados offline, base de dados em recuperação (não recuperou). Para mais informações, consulte a coluna Estado em sys.databases.
A deteção de saúde ao nível da base de dados está ativada para o grupo de disponibilidade como um todo, pelo que a deteção de saúde ao nível da base de dados monitoriza todas as bases de dados do grupo de disponibilidade. Não pode ser ativado seletivamente para bases de dados específicas no grupo de disponibilidade.
Vantagens da opção de deteção de saúde ao nível da base de dados
A opção de deteção de saúde ao nível da base de dados do grupo de disponibilidade é amplamente recomendada como uma boa opção para ajudar a garantir a elevada disponibilidade das suas bases de dados. Deves considerar ativá-lo para todos os grupos de disponibilidade. Se a sua aplicação depende de várias bases de dados para estar altamente disponível, agrupe-as num grupo de disponibilidade com a opção de saúde da base de dados ativada.
Por exemplo, com a opção de deteção de saúde ao nível da base de dados ativada, se o SQL Server não conseguisse escrever no ficheiro de registo de transações de uma das bases de dados, o estado dessa base de dados mudaria para indicar falha, e o grupo de disponibilidade em breve falharia, e a sua aplicação poderia reconectar-se e continuar a funcionar com interrupções mínimas assim que as bases de dados estivessem novamente online.
Possibilitação da deteção de saúde ao nível da base de dados
Embora seja geralmente recomendada, a opção Saúde da Base de Dados está desativada por defeito, para manter a compatibilidade retroativa com as definições predefinidas das versões anteriores.
Existem várias formas simples de ativar a definição de deteção de saúde ao nível da base de dados:
No SQL Server Management Studio, ligue-se ao seu motor de base de dados SQL Server. Usando a janela do Explorador de Objetos, clique com o botão direito no nó Sempre Ativo de Alta Disponibilidade e execute o Assistente de Grupo de Nova Disponibilidade. Assinale a caixa de seleção Deteção de Saúde a Nível de Base de Dados na página Especificar Nome. Depois completa o resto das páginas no feiticeiro.
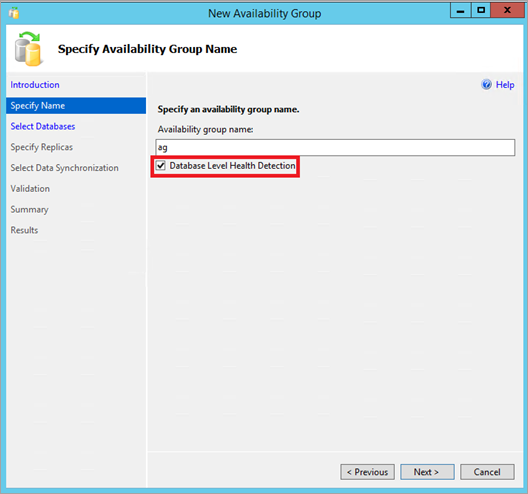
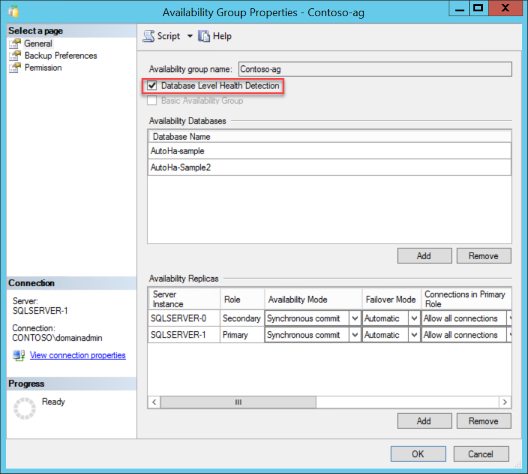
Veja as propriedades de um grupo de disponibilidade existente no SQL Server Management Studio. Liga-te ao teu SQL Server. Usando a janela do Explorador de Objetos, expanda o nó Sempre Em Alta Disponibilidade. Expandir os Grupos de Disponibilidade. Clique com o botão direito no grupo de disponibilidade e escolha Propriedades. Assinale a opção Deteção de Saúde do Nível da Base de Dados, depois clique em "OK" ou crie um script para a alteração.
Transact-SQL Sintaxe para CRIAR GRUPO DE DISPONIBILIDADE. O parâmetro DB_FAILOVER aceita valores LIGADO ou DESLIGADO.
CREATE AVAILABILITY GROUP [Contoso-ag] WITH (DB_FAILOVER=ON) FOR DATABASE [AutoHa-Sample] REPLICA ON N'SQLSERVER-0' WITH (ENDPOINT_URL = N'TCP://SQLSERVER-0.DOMAIN.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), N'SQLSERVER-1' WITH (ENDPOINT_URL = N'TCP://SQLSERVER-1.DOMAIN.COM:5022', FAILOVER_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Transact-SQL Sintaxe de ALTERAR GRUPO DE DISPONIBILIDADE. O parâmetro DB_FAILOVER aceita os valores ON ou OFF.
ALTER AVAILABILITY GROUP [Contoso-ag] SET (DB_FAILOVER = ON); ALTER AVAILABILITY GROUP [Contoso-ag] SET (DB_FAILOVER = OFF);
Advertências
É importante notar que a opção de Deteção de Integridade ao Nível da Base de Dados atualmente não leva o SQL Server a monitorizar o tempo de atividade do disco, e o SQL Server não monitoriza diretamente a disponibilidade de ficheiros da base de dados. Se uma unidade de disco falhar ou ficar indisponível, isso por si só não fará necessariamente com que o grupo de disponibilidade faça failover automaticamente.
Por exemplo, quando uma base de dados está inativa sem transações ativas, e sem escritas físicas a ocorrer, caso alguns ficheiros da base de dados se tornem inacessíveis, o SQL Server pode não fazer qualquer leitura ou escrita de E/S nos ficheiros, e pode não alterar imediatamente o estado dessa base de dados, pelo que não será acionado o failover. Mais tarde, quando ocorre um checkpoint de base de dados, ou uma leitura ou escrita física para satisfazer uma consulta, o SQL Server pode então detetar o problema no ficheiro e reagir alterando o estado da base de dados, e subsequentemente o grupo de disponibilidade com detecção de integridade ao nível da base de dados ativada iniciaria um failover devido à alteração na integridade da base de dados.
Como outro exemplo, quando o motor de base de dados SQL Server precisa de ler uma página de dados para satisfazer uma consulta, se a página de dados estiver armazenada em cache na memória do buffer pool, então não poderá ser necessário ler disco com acesso físico para cumprir o pedido de consulta. Portanto, um ficheiro de dados em falta ou indisponível pode não desencadear imediatamente um failover automático mesmo quando a opção de saúde da base de dados está ativada, uma vez que o estado da base de dados não é atualizado imediatamente.
O failover da base de dados é independente da política flexível de failover
A verificação de integridade ao nível da base de dados implementa uma política de failover flexível, configurando os limiares de saúde do processo do SQL Server conforme essa política. A deteção de integridade ao nível da base de dados é configurada usando o parâmetro DB_FAILOVER, enquanto a opção de grupo de disponibilidade FAILURE_CONDITION_LEVEL é utilizada separadamente para configurar a deteção de integridade do processo do SQL Server. As duas opções são independentes.
Gerir e monitorizar a deteção de saúde ao nível da base de dados
Visões de Gestão Dinâmica
A DMV sys.availability_groups do sistema mostra uma coluna db_failover que indica se a opção de detecção de saúde a nível da base de dados está desativada (0) ou ativada (1).
select name, db_failover from sys.availability_groups
Exemplo de saída do DMV:
| nome | db_failover |
|---|---|
| Contoso-ag | 1 |
Registo de Erros
O Registo de Erros do SQL Server (ou texto de sp_readerrorlog) mostrará a mensagem de erro 41653 quando um grupo de disponibilidade tiver falhado, devido às verificações de deteção de saúde ao nível da base de dados.
Por exemplo, este excerto do registo de erros mostra que a escrita de um registo de transações falhou devido a uma falha no disco e, subsequentemente, a base de dados chamada AutoHa-Sample foi desligada, o que levou ao failover do grupo de disponibilidade após a verificação de integridade ao nível da base de dados.
2016-04-25 12:20:21.08 spid1s Erro: 17053, Gravidade: 16, Estado: 1.
2016-04-25 12:20:21.08 spid1s SQLServerLogMgr::LogWriter: Erro do sistema operativo 21 (O dispositivo não está pronto.) encontrado. 2016-04-25 12:20:21.08 spid1s Erro de escrita durante o esvaziamento do log.
2016-04-25 12:20:21.08 spid79 Erro: 9001, Gravidade: 21, Estado: 4.
2016-04-25 12:20:21.08 spid79 O registo da base de dados 'AutoHa-Sample' não está disponível. Verifique se há mensagens de erro relacionadas no log de eventos. Resolva quaisquer erros e reinicie a base de dados.
2016-04-25 12:20:21.15 spid79 Erro: 41653, Gravidade: 21, Estado: 1.
2016-04-25 12:20:21.15 spid79 Base de dados 'AutoHa-Sample' encontrou um erro (tipo de erro: 2 'DB_SHUTDOWN') causando a falha do grupo de disponibilidade 'Contoso-ag'. Consulte o log de erros do SQL Server para obter informações sobre os erros encontrados. Se essa condição persistir, entre em contato com o administrador do sistema.
2016-04-25 12:20:21.17 spid79 Informação de estado para a base de dados 'AutoHa-Sample' - LSN reforçado: '(34:664:1)' Commit LSN: '(34:656:1)' Hora de Commit: '25 Abril 2016 12:19 PM'
2016-04-25 12:20:21.19 spid15s A conexão do Always On Availability Groups com a base de dados secundária foi terminada para a base de dados primária 'AutoHa-Sample' na réplica de disponibilidade 'SQLServer-0' com o ID de réplica: {c4ad5ea4-8a99-41fa-893e-189154c24b49}. Esta é apenas uma mensagem informativa. Nenhuma ação do usuário é necessária.
2016-04-25 12:20:21.21 spid75 Sempre Ligado: A réplica local do grupo de disponibilidade 'Contoso-ag' está a preparar-se para a transição para o papel de resolução em resposta a um pedido do cluster Windows Server Failover Clustering (WSFC). Esta é apenas uma mensagem informativa. Nenhuma ação do usuário é necessária.
2016-04-25 12:20:21.21 spid75 O estado da réplica de disponibilidade local no grupo de disponibilidade 'ag' mudou de 'PRIMARY_NORMAL' para 'RESOLVING_NORMAL'. O estado mudou porque o grupo de disponibilidade vai ficar offline. A réplica está a ficar offline porque o grupo de disponibilidade associado foi eliminado, ou porque o utilizador desligou o grupo de disponibilidade associado na consola de gestão do Windows Server Failover Clustering (WSFC), ou porque o grupo de disponibilidade está a fazer failover para outra instância SQL Server. Para obter mais informações, consulte o log de erros do SQL Server, o console de gerenciamento do WSFC (Cluster de Failover do Windows Server) ou o log do WSFC.
Evento Estendido sqlserver.availability_replica_database_fault_reporting
Existe um novo Evento Estendido definido a partir do SQL Server 2016 que é ativado pela monitorização de integridade ao nível da base de dados. O nome do evento é sqlserver.availability_replica_database_fault_reporting
Este XEvent é ativado apenas na réplica principal. Este XEvent é ativado quando é detetado um problema de saúde ao nível da base de dados numa base de dados alojada num grupo de disponibilidade.
Aqui está um exemplo para criar uma sessão XEvent que capte este evento. Como não é especificado o caminho, o ficheiro de saída do XEvent deve estar localizado no caminho padrão do registo de erros do SQL Server. Execute isto na réplica principal do seu grupo de disponibilidade:
Exemplo de Script de Sessão de Eventos Estendido
CREATE EVENT SESSION [AlwaysOn_dbfault] ON SERVER
ADD EVENT sqlserver.availability_replica_database_fault_reporting
ADD TARGET package0.event_file(SET filename=N'dbfault.xel',max_file_size=(5),max_rollover_files=(4))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO
ALTER EVENT SESSION AlwaysOn_dbfault ON SERVER STATE=START
GO
** Saída de Eventos Extensados
Usando o SQL Server Management Studio, ligue-se ao SQL Server primário e expanda o nó de Gestão, depois expanda os Eventos Estendidos. Localiza a sessão (AlwaysOn_dbfault era o nome no exemplo acima) e expande-a para ver os ficheiros de saída. Selecione o ficheiro de saída e o ficheiro de eventos abrir-se-á numa nova aba.
Explicação dos campos:
| Dados da coluna | Description |
|---|---|
| availability_group_id | O ID do grupo de disponibilidade. |
| nome_grupo_disponibilidade | O nome do grupo de disponibilidade. |
| disponibilidade_réplica_id | ID da réplica de disponibilidade. |
| availability_replica_name | O nome da réplica disponível. |
| nome_da_base_de_dados | O nome da base de dados que reporta a falha. |
| database_replica_id | O ID da base de dados de réplicas de disponibilidade. |
| réplicas_prontas_para_failover | O número de réplicas secundárias automáticas de failover que são sincronizadas. |
| tipo_de_falha | O ID da falha reportado. Valores possíveis: 0 - NENHUM 1 - Desconhecido 2 - Encerramento |
| is_critical | Este valor deve sempre devolver verdadeiro para o XEvent a partir do SQL Server 2016. |
Neste exemplo de saída, o fault_type mostra que ocorreu um evento crítico nos grupos de disponibilidade Contoso-ag, na réplica nomeada SQLSERVER-1, devido ao nome da base de dados AutoHa-Sample2, com o tipo de falha 2 - Desligamento.
| Campo | Valor |
|---|---|
| availability_group_id | 24E6FE58-5EE8-4C4E-9746-491CFBB208C1 |
| availability_group_name | Contoso-ag |
| identificador_de_réplica_de_disponibilidade | 3EAE74D1-A22F-4D9F-8E9A-DEFF99B1F4D1 |
| availability_replica_name | SQLSERVER-1 |
| nome_da_base_de_dados | AutoHa-Sample2 |
| database_replica_id | 39971379-8161-4607-82E7-098590E5AE00 |
| réplicas_prontas_para_redundância | 1 |
| tipo_de_falha | 2 |
| é_crítico | Verdade |