Musings on Software Testing
It was spring 2003, I had just finished a weekend camping in the southern Arizona desert. I was dusty and physically exhausted from hours of playing paintball. For those who have never been in those parts, imagine long straight roads with dry sage brush, painful cactus, and jagged mountains. I needed a book to pass the time during the drive. Fortunately, I had brought along "Extreme Programming Explained" by Kent Beck. After having spent too much time in projects that either completely lacked process or had way too much of it, Beck's position seemed like a revelation. Over the next few months, I became acquainted with test-driven development, design patterns, refactoring and many of the other topics typically associated with agile programming.
Test Driven Development
In the spring, I had a course that ended up just teaching agile programming concepts. One of the things that the professor emphasized was following the test-driven development (TDD) process to the letter.
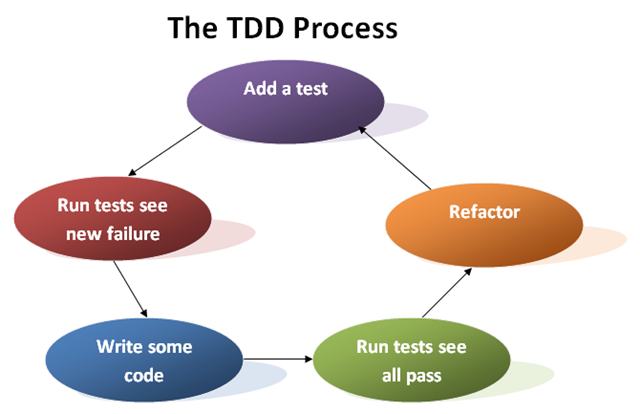
1. Add a test
2. Run all tests and see the new one fail
3. Write some code
4. Run the automated tests and see them succeed
5. Refactor code
Repeat
When I say refactor, I mean it in the strictest sense. I mean changing how a program is arranged internally without changing the semantics of the program at all. This of course ignores the fact that things like timing, working set, or stack size change which can be material to the run-time behavior of the program.
During step three a programmer should remember, "It is important that the code written is only designed to pass the test; no further (and therefore untested) functionality should be predicted and 'allowed for' at any stage".
Machine Learning
I fully bought into this rigorous approach to TDD until one summer day when I was reading through Tom Mitchell's marvelous book "Machine Learning". The book begins by defining machine learning:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
Intuitively, the learning process is trying to learn some unknown concept. The learner has access to its past experiences (the training data) and uses them to generate a hypothesis of the unknown concept. This hypothesis is then evaluated and the new experiences are added to the training data. The learning process then repeats itself as the learner forms a better approximation of the underlying concept.
TDD is a learning process. Where the training experience E is the automated tests, the task T is improving the quality of the program, and the performance measure P is the percentage of tests passed. In this view of TDD, the programmer continues to hack away at his program generating hypotheses, where each hypothesis is a version of the code, until one satisfies the data. Note that unless the tests exhaustively specify the desired behavior of a program, then the tests are not the target concept that needs to be learned but rather a few data points where the target concept is manifest. Furthermore, the program should not only do well against the tests but also against real world scenarios which may not be covered by the tests.
Bias and Learning
A learner is characterized by its hypothesis space and how it searches through that space. Notice that since each learner has a hypothesis space, a given concept may have not be in that space. One solution to this problem is to make a learner's hypothesis space include all hypotheses, but this leads to a fundamental problem: "a learner that makes no a priori assumptions regarding the identity of the target concept has no rational basis for classifying any unseen instances." The only thing that an unbiased learner can do is regurgitate the training data because it has no ability to make the assumptions and logical leaps necessary to deal with unseen data.
For example, suppose that I am trying to learn to classify animals as either mammals or non-mammals and suppose that I make no assumptions whatsoever in the process of learning this task. If I am told that giraffes, lions, mice, bats, and whales are mammals but snakes, butterflies, frogs, lobsters, and penguins are not, then I only have the ability to answer questions regarding those animals for which I already know the answer. I could have done much better by trying to guess at what makes an animal a mammal even if I got it wrong!
Returning to TDD, note that at no time is a programmer supposed to write code that generalizes to the target concept. The programmer should only write either the minimal code to make a test pass or refactor the code and not change the semantics. So according to the pure TDD approach, the program would only learn to regurgitate the training data and do who knows what against new examples. A critic might respond that more test cases are needed. In some cases where the input space is finite and small, this might well help, but in general this is impractical.
Sufficiently Large Projects
A similar situation arises in projects that are sufficiently large. These projects are characterized by the fact that they cannot be held inside any one person's head. This means that when someone is making a change, they cannot know all of the consequences of their change. Often in projects of this size, when people ask if a particular change is good, the response is, "It passed the tests." This leads to a state where the development process as a whole is a learning process that uses the test cases as the training data and generates programs as hypotheses that are evaluated against the training data. Most likely, the target concept is not normally fully determined by the tests.
You know the projects that I am talking about, and chances are that you have seen some code that was added in just to satisfy some test but didn't really capture the essence of what the test was originally trying to make the program do. While tests are invaluable to programmers for debugging purposes, it would be better if programmers returned to the specification in order to understand what they are supposed to develop instead of returning to the tests.
Testing practices like clean-room testing and various forms of white box testing address address the programmer bias deficiency, but it can also be addressed automatically.
Testing an Infinite Space
I had a development lead who liked to say that testing is just sampling. In a sense he is right, since a test is a particular input sequence given to a program from the set of all possible input sequences. Think of a program as a state machine encoded in your favorite process calculus. A test then verifies that a particular path of edges corresponding to the transitions based on the input ends in a particular state. Most interesting programs have an infinite number of possible input sequences because of their recursive nature and so the set of tests must be sampled from an infinite input space.
Testing creates tests by drawing input sequences out of the input sequence space. It is easy to imagine that tests could be generated randomly by selecting random input sequences. Random selection has several advantages. First, it enables statistical measures of quality. For example, if we sample uniformly then the pass/fail rate should be representative of the whole given a large enough sample. We could also keep generating more and more tests to improve our confidence that the program is indeed correct. Second, random tests have the added benefit of not allowing the programmers to just "pass the tests" since the programmers cannot anticipate what tests will be run. This forces the programmers to generate a hypothesis that more closely matches the target concept instead of the training data.
There are however some disadvantages. The first apparent problem is repeatability of the tests. This can be remedied by storing the seed that generates a set of tests. A second more serious problem is that a uniform random sample doesn't necessarily deliver the best results.
On Bugs
Not all bugs are created equal. Practices such as testing the boundary conditions and integration testing are based on that fact. Various testing practices explore parts of the input space that are richer in bugs or are more likely to contain serious bugs.

The cost of a bug can be quantified as the total monetary loss due to the presence of that bug in the software. This includes all sorts of things like lost sales through negative customer perception, cost of software patches, legal action, etc. While this is an accurate measure of cost, it is not very practical because it is very hard to estimate.
A more practical measure for estimating the relative cost of a bug might be the probability that users will find it multiplied by the severity of the bug. The first part of the equation is interesting because it indicates that those bugs that customers never find are not important for testing to find.
Back to Training
The testing ideal is to minimize the total cost of bugs. There are many good methods for writing test cases. In addition to these, we could also select input sequences based upon the probability that a user would select such an input sequence.
Imagine if it were possible to collect all of the input sequences that would ever be given to a program including duplicates. Then our problem would be reduced to uniformly selecting input sequences out of this collection. Obviously, this collection is unavailable but if we use the same machine learning principles which we have been discussing then we could develop a program that could learn to generate test cases according to some distribution by using a representative set of user input sequences as training data.
Markov Chains
One way that this could be done is by returning to the formulation of a computer program as a state machine. The object is to learn the probability that a user would take some transition given a particular state and a sequence of previous states and transitions. This can be formulated as a Markov chain.
Consider generating random test cases for a parser. A straightforward approach is to randomly derive a string in the language from the root non-terminal; however, it will quickly become apparent that the least used parts of your language are getting undue attention. Some more sophisticated tools allow productions in the grammar to be attributed with weights. This works better but forces the tester to learn the proper weights manually and it doesn't accurately describe the weights since the probability that a particular production for a non-terminal will be used is also based on the history of previously expanded productions.
A better approach is to learn weights for the Markov chain corresponding to the pushdown automata. Since a parser for an arbitrary context-free grammar can be expressed by a pushdown automaton, we can instrument the automaton to collect data on the probability of some transition given a state and a history of states and transitions. The instrumented automaton can then be fed a large number of user-written programs. Finally, a generator can be created that uses the data to generate programs that syntactically look like user-written programs.
Another approach might be to instrument branches and event sequences in a program and then train against user input. The learner could then build a Markov chain that can be used to generate input sequences roughly like user input.
Conclusion
Next time you find yourself in a project that is devolving into an unbiased learning process, restore the sanity by using the specification and not the tests to decide what to implement.
Comments
Anonymous
December 07, 2007
Hey Wes, Great post! I'm always interested in learning better ways to test and write software. I think that you've misunderstood the purpose of TDD though. In TDD, the tests you write are definitely not supposed to be the exhaustive set of tests, and in fact, their primary purpose is not to "test" the software. The primary purpose is to drive the design or architecture of the software, based on having real consumers for the APIs that you are writing. For this reason, many people have stopped using the term TDD, and have started using "Emergent Design Development (EDD)" instead. I'd be interested to hear your opinions on the efficacy of unit tests as a methodology for driving design though...Anonymous
December 07, 2007
Lately, I've been begun viewing TDD as a hill-climbing search, or perhaps some other search that hits a local maximum. It seems that if your development is entirely driven by those tests, they can only take you so far, and you'll hit the maximum. What takes talent is to look beyond the test and write something that not only fulfills it but does so in an elegant way. The elegant solution, once found, can guide us in new directions which we hadn't thought of before. This may lead us to add to or alter our tests. In this way, the search can break past the local maximum.Anonymous
December 07, 2007
I agree with you 100%. I believe that unit testing is essential, but that functional testing often devolves into an exercise in unbiased learning. There is certain core functionality to any framework or application that takes a finite set of inputs. An example of that is an implementation of ActiveRecord. The models will have methods that take a quite finite set of inputs. Perfect. However, functional testing involves testing that which is interacted with. Interaction is hard to predict. To properly test a complicated windows or web form would take hundreds of functional tests, and use cases for forms evolve rapidly and often. I know you're a bit of a Haskell buff. To put it in Haskell terms, I don't think that testing monads is nearly as useful as testing functions, and too much effort put into the testing of monads is a waste of time. No one will ever write a bug-free application and putting too much effort into that costs more money than it saves. Great blog, Wes. I'm glad you're finally blogging again. Three in 2 days!Anonymous
December 08, 2007
Kevin: Good to hear from you. I am being pedantic on purpose. I am just taking what TDD is defined to be and following it to the letter, so I am following the letter but not the spirit of what it is saying. Btw, I have seen it practiced this way. Testing is extremely important to me and any of my team mates will vouch for me that I write tests as early and often as possible. I used a brain-dead extreme form of TDD to show how process can degrade into suboptimal forms of machine learning. Tests should inform the design but not determine it.Anonymous
December 19, 2007
This article is nice as it brings forward the concept of TDD. Infact one other thing to stress is this idea that a bug that customers cannot find is not worth finding by test. True, i have held the same idea, but then remeber that a problem postponed is not a problem solved. The bug may never be found by customers, but may catch up with the programmer at a later stage when program upgrades are necessary.Anonymous
December 21, 2007
"While tests are invaluable to programmers for debugging purposes, it would be better if programmers returned to the specification in order to understand what they are supposed to develop instead of returning to the tests." Unless you make that step past TDD into BDD where the tests are specifications..Anonymous
December 21, 2007
Evan: I still stand by my conclusion if the input space is large enough (infinite definitely qualifies). It is impossible to test all of the values and so the problem may always lurk just out of reach of the tests. The specification doesn't suffer the same problem since it can talk in abstract generalizations that can cover infinite spaces. Tests that are generated either automatically or by humans without knowledge of the internals make this less probable but it still remains possible. Don't get me wrong. Programmer written tests help a lot. They are absolutely necessary. But they do not solve all our problems.Anonymous
December 21, 2007
EGESA RONALD LEONARD: You are right that a bug that is not found in this version may adversely affect a future version. But it still is true that a bug that a user never encounters is not important to fix to please the customers. That said, I still want to fix all of the bugs because I take personal pride in my work. Even if no one else in the whole world knows about the bug, I do. I care. In fact, if developers don't take personal pride in their work then I think morale will slip over the long run which can be catastrophic to a project. So this business about users not finding bugs is more about prioritization and making hard decisions than anything else.Anonymous
December 26, 2007
Hey - Interesting! Thanks for your thoughts. I find it interesting that folks talk about following TDD to the letter - if that were the case, you'd never have any production code that didn't have a test written for it 'first'. If there wasn't a test, there would be no need for the code, right? Regards and Happy New Year!!Anonymous
December 29, 2007
The comment has been removedAnonymous
December 29, 2007
With design-by-contract, "tests" (precondition, postcondition, invariant assertions) are based on declarative specifications, and the tests are constantly running, at least for debug builds, so they have a better chance of encountering unforseen situations. You demonstrated clearly that TDD is only an adjunct to specification based design. Considering the cost of maintaining intrusive, fine grained tests created using TDD, design-by-contract has a better return on investment.Anonymous
January 08, 2008
To paraphrase Godel, any sufficiently complex system contains inconsistency.Anonymous
January 14, 2008
If the input space is infinite and EVERY input value generates more than one output value, the E (experiences) would theorethically outgrow the unknown (U) which is imposible because the U is unlimited (infinite). Simply said: Program would know more than what's unknown (based on the fact that E is growing while U is shrinking, as well that there are more E records per U record).Anonymous
January 14, 2008
TJ: The input space is not filled with input values but input sequences. The output space is not filled with output values but output sequences. The size of each space is the same. There is no such contradiction.Anonymous
May 21, 2008
The comment has been removedAnonymous
June 09, 2010
Testertools.com is the largest Software Testing Tools database like Net Testing Tools, Network Management Tools, Oracle Database Test tool, Php Testing Tools, SQL Testing Tools, Open Source Testing Tools, Test Management Tools, Automated Test Tools etc.