Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
por Scott Mitchell
Saiba como permitir que os usuários carreguem arquivos binários (como documentos Word ou PDF) para seu site, onde podem ser armazenados no sistema de arquivos do servidor ou no banco de dados.
Introdução
Todos os tutoriais que examinamos até agora trabalharam exclusivamente com dados de texto. No entanto, muitos aplicativos têm modelos de dados que capturam texto e dados binários. Um site de namoro online pode permitir que os usuários carreguem uma foto para associar ao seu perfil. Um site de recrutamento pode permitir que os usuários carreguem seus currículos como um documento do Microsoft Word ou PDF.
Trabalhar com dados binários adiciona um novo conjunto de desafios. Devemos decidir como os dados binários são armazenados no aplicativo. A interface utilizada para inserir novos registos tem de ser atualizada para permitir que o utilizador carregue um ficheiro a partir do seu computador e devem ser tomadas medidas adicionais para apresentar ou fornecer um meio para descarregar os dados binários associados a um registo. Neste tutorial e nos próximos três, exploraremos como superar esses desafios. No final destes tutoriais teremos construído uma aplicação totalmente funcional que associa uma imagem e brochura PDF a cada categoria. Neste tutorial em particular, veremos diferentes técnicas para armazenar dados binários e exploraremos como permitir que os usuários carreguem um arquivo de seu computador e o salvem no sistema de arquivos do servidor web.
Observação
Os dados binários que fazem parte do modelo de dados de um aplicativo às vezes são chamados de BLOB, um acrônimo para Binary Large OBject. Nestes tutoriais optei por usar a terminologia dados binários, embora o termo BLOB seja sinónimo.
Etapa 1: Criando o trabalho com páginas da Web de dados binários
Antes de começarmos a explorar os desafios associados à adição de suporte para dados binários, vamos primeiro reservar um momento para criar as páginas ASP.NET em nosso projeto de site que precisaremos para este tutorial e os próximos três. Comece adicionando uma nova pasta chamada BinaryData. Em seguida, adicione as seguintes páginas ASP.NET a essa pasta, certificando-se de associar cada página à Site.master página mestra:
Default.aspxFileUpload.aspxDisplayOrDownloadData.aspxUploadInDetailsView.aspxUpdatingAndDeleting.aspx
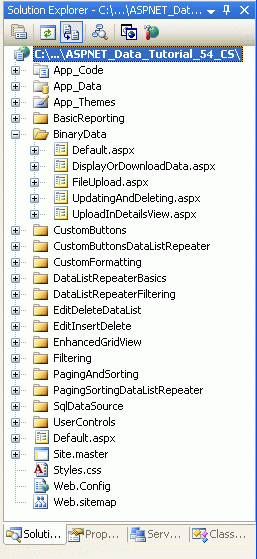
Figura 1: Adicionar as páginas de ASP.NET para os tutoriais binários Data-Related
Como nas outras pastas, Default.aspx na BinaryData pasta irá listar os tutoriais em sua seção. Lembre-se de que o SectionLevelTutorialListing.ascx Controle de Usuário fornece essa funcionalidade. Portanto, adicione este Controlo do Utilizador a Default.aspx arrastando-o do Gerenciador de Soluções para a vista de Design da página.

Figura 2: Adicionar o controle de usuário a SectionLevelTutorialListing.ascx (Default.aspx imagem em tamanho real)
{kind=link}
Por fim, adicione essas páginas como entradas ao Web.sitemap arquivo. Especificamente, adicione a seguinte marcação após o Aprimorando o GridView <siteMapNode>:
<siteMapNode
title="Working with Binary Data"
url="~/BinaryData/Default.aspx"
description="Extend the data model to include collecting binary data.">
<siteMapNode
title="Uploading Files"
url="~/BinaryData/FileUpload.aspx"
description="Examine the different ways to store binary data on the
web server and see how to accept uploaded files from users
with the FileUpload control." />
<siteMapNode
title="Display or Download Binary Data"
url="~/BinaryData/DisplayOrDownloadData.aspx"
description="Let users view or download the captured binary data." />
<siteMapNode
title="Adding New Binary Data"
url="~/BinaryData/UploadInDetailsView.aspx"
description="Learn how to augment the inserting interface to
include a FileUpload control." />
<siteMapNode
title="Updating and Deleting Existing Binary Data"
url="~/BinaryData/UpdatingAndDeleting.aspx"
description="Learn how to update and delete existing binary data." />
</siteMapNode>
Após a atualização Web.sitemap, reserve um momento para visualizar o site de tutoriais através de um navegador. O menu à esquerda agora inclui itens para os tutoriais Trabalhando com dados binários.
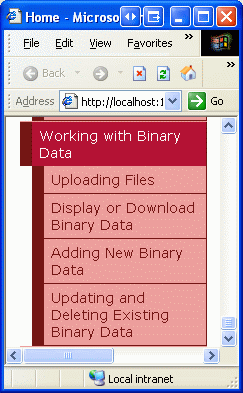
Figura 3: O mapa do site agora inclui entradas para os tutoriais de trabalho com dados binários
Etapa 2: Decidindo onde armazenar os dados binários
Os dados binários associados ao modelo de dados do aplicativo podem ser armazenados em um de dois lugares: no sistema de arquivos do servidor Web com uma referência ao arquivo armazenado no banco de dados; ou diretamente no próprio banco de dados (ver Figura 4). Cada abordagem tem o seu próprio conjunto de prós e contras e merece uma discussão mais detalhada.

Figura 4: Dados binários podem ser armazenados no sistema de arquivos ou diretamente no banco de dados (Clique para visualizar a imagem em tamanho real)
{kind=link}
Imagine que queríamos estender o banco de dados Northwind para associar uma imagem a cada produto. Uma opção seria armazenar esses arquivos de imagem no sistema de arquivos do servidor web e registrar o caminho na Products tabela. Com essa abordagem, adicionamos uma ImagePath coluna à Products tabela do tipo varchar(200), talvez. Quando um usuário carrega uma imagem para Chai, essa imagem pode ser armazenada no sistema de arquivos do servidor Web em ~/Images/Tea.jpg, onde ~ representa o caminho físico do aplicativo. Ou seja, se o site está enraizado no caminho C:\Websites\Northwind\físico, ~/Images/Tea.jpg seria equivalente a C:\Websites\Northwind\Images\Tea.jpg. Depois de carregar o ficheiro de imagem, iremos atualizar o registo Chai na tabela Products para que a coluna ImagePath faça referência ao caminho da nova imagem. Poderíamos usar ~/Images/Tea.jpg ou apenas Tea.jpg se decidíssemos que todas as imagens do produto seriam colocadas na pasta do Images aplicativo.
As principais vantagens de armazenar os dados binários no sistema de arquivos são:
- Facilidade de implementação Como veremos em breve, armazenar e recuperar dados binários armazenados diretamente no banco de dados envolve um pouco mais de código do que quando se trabalha com dados através do sistema de arquivos. Além disso, para que um usuário visualize ou baixe dados binários, eles devem receber uma URL para esses dados. Se os dados residirem no sistema de arquivos do servidor Web, a URL é simples. No entanto, se os dados estiverem armazenados no banco de dados, será necessário criar uma página da Web que recuperará e retornará os dados do banco de dados.
- Acesso mais amplo aos dados binários Os dados binários podem precisar ser acessíveis a outros serviços ou aplicativos, aqueles que não podem extrair os dados do banco de dados. Por exemplo, as imagens associadas a cada produto também podem precisar estar disponíveis para os usuários através do FTP, caso em que queremos armazenar os dados binários no sistema de arquivos.
- Desempenho se os dados binários forem armazenados no sistema de arquivos, a demanda e o congestionamento de rede entre o servidor de banco de dados e o servidor Web serão menores do que se os dados binários forem armazenados diretamente no banco de dados.
A principal desvantagem de armazenar dados binários no sistema de arquivos é que ele separa os dados do banco de dados. Se um registro for excluído da Products tabela, o arquivo associado no sistema de arquivos do servidor Web não será excluído automaticamente. Devemos escrever código extra para excluir o arquivo ou o sistema de arquivos ficará abarrotado de arquivos órfãos não utilizados. Além disso, ao fazer backup do banco de dados, devemos nos certificar de fazer backups dos dados binários associados no sistema de arquivos também. Mover o banco de dados para outro site ou servidor representa desafios semelhantes.
Como alternativa, os dados binários podem ser armazenados diretamente em um banco de dados do Microsoft SQL Server 2005 criando uma coluna do tipo varbinary. Como com outros tipos de dados de comprimento variável, você pode especificar um comprimento máximo dos dados binários que podem ser mantidos nesta coluna. Por exemplo, para reservar no máximo 5.000 bytes, use varbinary(5000); varbinary(MAX) permite o tamanho máximo de armazenamento, cerca de 2 GB.
A principal vantagem de armazenar dados binários diretamente no banco de dados é o acoplamento estreito entre os dados binários e o registro do banco de dados. Isso simplifica muito as tarefas de administração do banco de dados, como backups ou mover o banco de dados para um site ou servidor diferente. Além disso, excluir um registro exclui automaticamente os dados binários correspondentes. Há também benefícios mais sutis de armazenar os dados binários no banco de dados.
Observação
No Microsoft SQL Server 2000 e versões anteriores, o varbinary tipo de dados tinha um limite máximo de 8.000 bytes. Para armazenar até 2 GB de dados binários, o image tipo de dados precisa ser usado. No entanto, com a adição de MAX no SQL Server 2005, o tipo de dados image foi preterido. Ele ainda é suportado para compatibilidade com versões anteriores, mas a Microsoft anunciou que o image tipo de dados será removido em uma versão futura do SQL Server.
Se estiver a trabalhar com um modelo de dados mais antigo, poderá ver o tipo de image dados. A tabela Categories do banco de dados Northwind tem uma coluna Picture que pode ser usada para armazenar os dados binários de uma imagem de uma categoria. Como o banco de dados Northwind tem suas raízes no Microsoft Access e em versões anteriores do SQL Server, esta coluna é do tipo image.
Para este tutorial e os próximos três, usaremos ambas as abordagens. A Categories tabela já tem uma Picture coluna para armazenar o conteúdo binário de uma imagem para a categoria. Adicionaremos uma coluna adicional, BrochurePath, para armazenar um caminho para um PDF no sistema de arquivos do servidor Web que pode ser usado para fornecer uma visão geral polida e com qualidade de impressão da categoria.
Etapa 3: Adicionando aBrochurePathcoluna àCategoriestabela
Atualmente, a tabela Categorias tem apenas quatro colunas: CategoryID, CategoryName, Descriptione Picture. Além desses campos, precisamos adicionar um novo que apontará para o folheto da categoria (se houver). Para adicionar essa coluna, vá para o Gerenciador de Servidores, faça uma busca detalhada nas Tabelas, clique com o botão direito do mouse na tabela e escolha Abrir Definição de Tabela (consulte a Categories Figura 5). Se você não vir o Gerenciador de Servidores, abra-o selecionando a opção Gerenciador de Servidores no menu Exibir ou pressione Ctrl+Alt+S.
Adicione uma nova varchar(200) coluna à tabela Categories chamada BrochurePath e que permita NULLs e clique no ícone Salve (ou pressione Ctrl+S).

Figura 5: Adicionar uma BrochurePath coluna à tabela (Categories imagem em tamanho real)
{kind=link}
Etapa 4: Atualizando a arquitetura para usar as Picture e BrochurePath colunas
O CategoriesDataTable na camada de acesso a dados (DAL) atualmente tem quatro DataColumn s definidos: CategoryID, CategoryName, Description, e NumberOfProducts. Quando originalmente projetámos esta DataTable no tutorial Criando uma camada de acesso a dados, ela inicialmente tinha apenas as três primeiras colunas; a CategoriesDataTable coluna foi adicionada no tutorial NumberOfProducts.
Como discutido em Criando uma camada de acesso a dados, as Tabelas de Dados no Conjunto de Dados tipado compõem os objetos de negócios. Os TableAdapters são responsáveis por se comunicar com o banco de dados e preencher os objetos de negócios com os resultados da consulta. O CategoriesDataTable é preenchido pelo CategoriesTableAdapter, que tem três métodos de recuperação de dados.
-
GetCategories()executa a consulta principal do TableAdapter e retorna osCategoryIDcampos ,CategoryNameeDescriptionde todos os registros naCategoriestabela. A consulta principal é o que é usado pelos métodosInserteUpdategerados automaticamente. -
GetCategoryByCategoryID(categoryID)retorna osCategoryIDcampos ,CategoryNameeDescriptionda categoria cujoCategoryIDé igual a categoryID. -
GetCategoriesAndNumberOfProducts()- devolve os camposCategoryID,CategoryNameeDescriptionpara todos os registos na tabelaCategories. Também usa uma subconsulta para retornar o número de produtos associados a cada categoria.
Observe que nenhuma dessas consultas retorna as Categories tabelas Picture ou BrochurePath colunas; nem o CategoriesDataTable fornece DataColumn s para esses campos. Para trabalhar com as propriedades de Imagem e BrochurePath, precisamos primeiro adicioná-las ao CategoriesDataTable e depois atualizar a classe CategoriesTableAdapter para retornar essas colunas.
Adicionando os Picture e BrochurePath``DataColumns
Comece adicionando estas duas colunas ao CategoriesDataTable. Clique com o botão direito do mouse no cabeçalho CategoriesDataTable, selecione Adicionar no menu de contexto e escolha a opção Coluna. Isso criará um novo DataColumn na DataTable chamado Column1. Renomeie esta coluna para Picture. Na janela de propriedades, defina a propriedade DataColumnDataType como System.Byte[] (esta não é uma opção na lista suspensa; terá de digitá-la).
![Crie uma DataColumn chamada Picture cujo DataType é System.Byte[]](uploading-files-vb/_static/image7.png)
Figura 6: Crie um DataColumn chamado Picture cuja DataType seja System.Byte[] (Clique para visualizar a imagem em tamanho real)
{kind=link}
Adicione outro DataColumn ao DataTable, nomeando-o BrochurePath usando o valor padrão DataType (System.String).
Retornando osPicturevalores eBrochurePathdo TableAdapter
Com estes dois DataColumn s adicionados ao CategoriesDataTable, estamos prontos para atualizar o CategoriesTableAdapter. Poderíamos ter ambos os valores de coluna retornados na consulta TableAdapter principal, mas isso traria de volta os dados binários toda vez que o GetCategories() método fosse invocado. Em vez disso, vamos atualizar a consulta principal do TableAdapter para trazer de volta BrochurePath e criar um método adicional de recuperação de dados que retorne a coluna Picture de uma categoria específica.
Para atualizar a consulta principal do TableAdapter, clique com o botão direito no CategoriesTableAdapter cabeçalho e escolha a opção Configurar no menu de contexto. Isso traz o Assistente de Configuração do Adaptador de Tabela, que vimos em vários tutoriais anteriores. Atualize a consulta para trazer de volta BrochurePath e clique em Concluir.

Figura 7: Atualize a lista de colunas na instrução para também retornar SELECT (BrochurePath imagem em tamanho real)
{kind=link}
Ao usar instruções SQL ad-hoc para o TableAdapter, atualizar a lista de colunas na consulta principal atualiza a lista de colunas para todos os SELECT métodos de consulta no TableAdapter. Isso significa que o método GetCategoryByCategoryID(categoryID) foi atualizado para retornar a coluna BrochurePath, o que pode ser o que pretendíamos. Contudo, também atualizou a lista de colunas no método GetCategoriesAndNumberOfProducts(), removendo a subconsulta que retorna o número de produtos para cada categoria! Portanto, precisamos atualizar a consulta deste SELECT método. Clique com o botão direito no método GetCategoriesAndNumberOfProducts(), escolha Configurar e reverta a consulta SELECT ao seu valor original.
SELECT CategoryID, CategoryName, Description,
(SELECT COUNT(*)
FROM Products p
WHERE p.CategoryID = c.CategoryID)
as NumberOfProducts
FROM Categories c
Em seguida, crie um novo método TableAdapter que retorna o valor da coluna Picture de uma categoria específica. Clique com o botão direito do CategoriesTableAdapter mouse no cabeçalho e escolha a opção Adicionar uma consulta para iniciar o Assistente de configuração de consulta do TableAdapter. A primeira etapa deste assistente nos pergunta se queremos consultar dados usando uma instrução SQL ad-hoc, um novo procedimento armazenado ou um existente. Selecione Usar instruções SQL e clique em Avançar. Como retornaremos uma linha, escolha a opção SELECT que retorna linhas na segunda etapa.

Figura 8: Selecione a opção Usar instruções SQL (Clique para visualizar a imagem em tamanho real)
{kind=link}

Figura 9: Como a consulta retornará um registro da tabela de categorias, escolha SELECT que retorna linhas (Clique para visualizar a imagem em tamanho real)
{kind=link}
Na terceira etapa, insira a seguinte consulta SQL e clique em Avançar:
SELECT CategoryID, CategoryName, Description, BrochurePath, Picture
FROM Categories
WHERE CategoryID = @CategoryID
O último passo é escolher o nome para o novo método. Use FillCategoryWithBinaryDataByCategoryID e GetCategoryWithBinaryDataByCategoryID para os padrões Fill a DataTable e Return a DataTable, respectivamente. Clique em Concluir para finalizar o assistente.

Figura 10: Escolha os nomes para os métodos do TableAdapter (Clique para visualizar a imagem em tamanho real)
{kind=link}
Observação
Depois de concluir o Assistente de Configuração de Consulta do Adaptador de Tabela, você poderá ver uma caixa de diálogo informando que o novo texto do comando retorna dados com esquema diferente do esquema da consulta principal. Em resumo, o assistente está observando que a consulta GetCategories() principal do TableAdapter retorna um esquema diferente daquele que acabamos de criar. Mas é isso que queremos, para que possam ignorar esta mensagem.
Além disso, lembre-se de que, se você estiver usando instruções SQL ad-hoc e usar o assistente para alterar a consulta principal do TableAdapter em algum momento posterior, ele modificará a GetCategoryWithBinaryDataByCategoryID lista de colunas da instrução do método para SELECT incluir apenas essas colunas da consulta principal (ou seja, removerá a Picture coluna da consulta). Você terá que atualizar manualmente a lista de colunas para retornar a Picture coluna, semelhante ao que fizemos com o GetCategoriesAndNumberOfProducts() método anteriormente nesta etapa.
Depois de adicionar os dois DataColumn ao CategoriesDataTable e o método GetCategoryWithBinaryDataByCategoryID ao CategoriesTableAdapter, essas classes no Typed DataSet Designer devem parecer-se com a captura de ecrã na Figura 11.
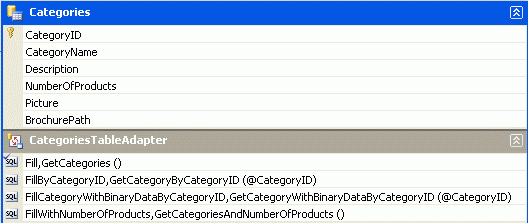
Figura 11: O DataSet Designer inclui as novas colunas e o método
Atualizando a camada de lógica de negócios (BLL)
Com a DAL atualizada, tudo o que resta é aumentar a camada de lógica de negócios (BLL) para incluir um método para o novo CategoriesTableAdapter método. Adicione o seguinte método à classe CategoriesBLL:
<System.ComponentModel.DataObjectMethodAttribute _
(System.ComponentModel.DataObjectMethodType.Select, False)> _
Public Function GetCategoryWithBinaryDataByCategoryID(categoryID As Integer) _
As Northwind.CategoriesDataTable
Return Adapter.GetCategoryWithBinaryDataByCategoryID(categoryID)
End Function
Etapa 5: Carregando um arquivo do cliente para o servidor Web
Ao coletar dados binários, muitas vezes esses dados são fornecidos por um usuário final. Para capturar essas informações, o usuário precisa ser capaz de carregar um arquivo de seu computador para o servidor web. Os dados carregados precisam ser integrados com o modelo de dados, o que pode significar salvar o arquivo no sistema de arquivos do servidor da Web e adicionar um caminho ao arquivo no banco de dados ou gravar o conteúdo binário diretamente no banco de dados. Nesta etapa, veremos como permitir que um usuário carregue arquivos de seu computador para o servidor. No próximo tutorial, voltaremos nossa atenção para a integração do arquivo carregado com o modelo de dados.
ASP.NET 2.0 s novo FileUpload Web controle fornece um mecanismo para os usuários para enviar um arquivo de seu computador para o servidor web. O controle FileUpload é renderizado como um <input> elemento cujo type atributo é definido como arquivo, que os navegadores exibem como uma caixa de texto com um botão Procurar. Clicar no botão Procurar abre uma caixa de diálogo a partir da qual o usuário pode selecionar um arquivo. Quando o formulário é postado de volta, o conteúdo do arquivo selecionado é enviado junto com o postback. No lado do servidor, as informações sobre o arquivo carregado podem ser acessadas por meio das propriedades do controle FileUpload.
Para demonstrar o carregamento de arquivos, abra a página na pasta FileUpload.aspxBinaryData, arraste um controlo FileUpload da Caixa de Ferramentas para o Designer e defina a propriedade ID do controlo como UploadTest. Em seguida, adicione um controlo de botão da Web definindo as suas propriedades ID e Text para UploadButton e Carregar ficheiro selecionado, respectivamente. Finalmente, coloque um controle Label Web abaixo do Button, limpe sua Text propriedade e defina sua ID propriedade como UploadDetails.

Figura 12: Adicionar um controle FileUpload à página ASP.NET (Clique para visualizar a imagem em tamanho real)
{kind=link}
A Figura 13 mostra essa página quando visualizada através de um navegador. Observe que clicar no botão Procurar abre uma caixa de diálogo de seleção de arquivo, permitindo que o usuário escolha um arquivo de seu computador. Depois que um arquivo for selecionado, clicar no botão Carregar arquivo selecionado causa um postback que envia o conteúdo binário do arquivo selecionado para o servidor Web.

Figura 13: O usuário pode selecionar um arquivo para carregar de seu computador para o servidor (Clique para visualizar a imagem em tamanho real)
{kind=link}
No postback, o arquivo carregado pode ser salvo no sistema de arquivos ou seus dados binários podem ser trabalhados diretamente através de um fluxo. Para este exemplo, vamos criar uma ~/Brochures pasta e salvar o arquivo carregado lá. Comece adicionando a Brochures pasta ao site como uma subpasta do diretório raiz. Em seguida, crie um manipulador de eventos para o UploadButton evento s Click e adicione o seguinte código:
Protected Sub UploadButton_Click(sender As Object, e As EventArgs) _
Handles UploadButton.Click
If UploadTest.HasFile = False Then
' No file uploaded!
UploadDetails.Text = "Please first select a file to upload..."
Else
' Display the uploaded file's details
UploadDetails.Text = String.Format( _
"Uploaded file: {0}<br />" & _
"File size (in bytes): {1:N0}<br />" & _
"Content-type: {2}", _
UploadTest.FileName, _
UploadTest.FileBytes.Length, _
UploadTest.PostedFile.ContentType)
' Save the file
Dim filePath As String = _
Server.MapPath("~/Brochures/" & UploadTest.FileName)
UploadTest.SaveAs(filePath)
End If
End Sub
O controle FileUpload fornece uma variedade de propriedades para trabalhar com os dados carregados. Por exemplo, a HasFile propriedade indica se um arquivo foi carregado pelo usuário, enquanto a FileBytes propriedade fornece acesso aos dados binários carregados como uma matriz de bytes. O Click manipulador de eventos começa garantindo que um arquivo tenha sido carregado. Se um arquivo tiver sido carregado, o Rótulo mostrará o nome do arquivo carregado, seu tamanho em bytes e seu tipo de conteúdo.
Observação
Para garantir que o usuário carregue um arquivo, você pode verificar a HasFile propriedade e exibir um aviso se for False, ou você pode usar o controle RequiredFieldValidator em vez disso.
O FileUpload s SaveAs(filePath) salva o arquivo carregado no filePath especificado.
filePath deve ser um caminho físico (C:\Websites\Brochures\SomeFile.pdf) em vez de um caminho virtual (/Brochures/SomeFile.pdf). O Server.MapPath(virtPath) método usa um caminho virtual e retorna seu caminho físico correspondente. Aqui, o caminho virtual é ~/Brochures/fileName, onde fileName é o nome do arquivo carregado. Consulte Server.MapPath Methos para obter mais informações sobre caminhos virtuais e físicos e como usar Server.MapPatho .
Depois de concluir o manipulador de Click eventos, reserve um momento para testar a página em um navegador. Clique no botão Procurar e selecione um arquivo do seu disco rígido e, em seguida, clique no botão Carregar arquivo selecionado. O postback enviará o conteúdo do arquivo selecionado para o servidor web, que exibirá informações sobre o arquivo antes de salvá-lo na ~/Brochures pasta. Depois de carregar o arquivo, retorne ao Visual Studio e clique no botão Atualizar no Gerenciador de Soluções. Deverá ver o ficheiro que acabou de carregar na pasta ~/Brochuras!

Figura 14: O arquivo EvolutionValley.jpg foi carregado para o servidor Web (Clique para visualizar a imagem em tamanho real)
{kind=link}
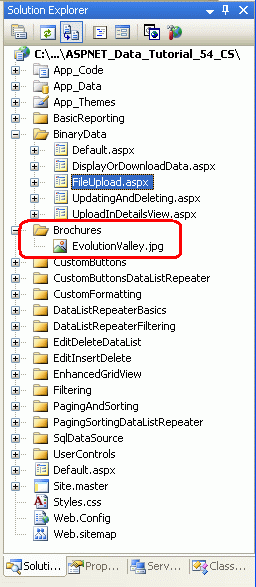
Figura 15: EvolutionValley.jpg Foi salvo na ~/Brochures pasta
Subtilezas ao guardar ficheiros carregados no sistema de ficheiros
Existem várias sutilezas que devem ser abordadas ao salvar o upload de arquivos no sistema de arquivos do servidor web. Em primeiro lugar, há a questão da segurança. Para salvar um arquivo no sistema de arquivos, o contexto de segurança sob o qual a página ASP.NET está sendo executada deve ter permissões de Gravação. O ASP.NET Development Web Server é executado no contexto da sua conta de usuário atual. Se você estiver usando o Microsoft Internet Information Services (IIS) como o servidor Web, o contexto de segurança dependerá da versão do IIS e sua configuração.
Outro desafio de salvar arquivos no sistema de arquivos gira em torno de nomear os arquivos. Atualmente, nossa página salva todos os arquivos carregados no ~/Brochures diretório usando o mesmo nome do arquivo no computador do cliente. Se o Utilizador A carregar uma brochura com o nome Brochure.pdf, o ficheiro será guardado como ~/Brochure/Brochure.pdf. Mas e se, algum tempo depois, o usuário B carregar um arquivo de brochura diferente que tenha o mesmo nome de arquivo (Brochure.pdf)? Com o código atual, o arquivo do usuário A será substituído pelo carregamento do usuário B.
Há várias técnicas para resolver conflitos de nome de arquivo. Uma opção é proibir o upload de um arquivo se já existir um com o mesmo nome. Com essa abordagem, quando o usuário B tenta carregar um arquivo chamado Brochure.pdf, o sistema não salva seu arquivo e, em vez disso, exibe uma mensagem informando o usuário B para renomear o arquivo e tentar novamente. Outra abordagem é salvar o arquivo usando um nome de arquivo exclusivo, que pode ser um identificador global exclusivo (GUID) ou o valor da(s) coluna(s) de chave primária do registro de banco de dados correspondente (supondo que o upload esteja associado a uma linha específica no modelo de dados). No próximo tutorial, exploraremos essas opções com mais detalhes.
Desafios envolvidos com grandes quantidades de dados binários
Estes tutoriais assumem que os dados binários capturados são modestos em tamanho. Trabalhar com grandes quantidades de arquivos de dados binários com vários megabytes ou mais introduz novos desafios que estão além do escopo desses tutoriais. Por exemplo, por padrão, ASP.NET rejeitará uploads de mais de 4 MB, embora isso possa ser configurado por meio do <httpRuntime> elemento em Web.config. O IIS também impõe suas próprias limitações de tamanho de carregamento de arquivos. Além disso, o tempo necessário para carregar arquivos grandes pode exceder os 110 segundos padrão ASP.NET aguardará por uma solicitação. Há também problemas de memória e desempenho que surgem ao trabalhar com arquivos grandes.
O controle FileUpload é impraticável para uploads de arquivos grandes. Como o conteúdo do arquivo está sendo postado no servidor, o usuário final deve esperar pacientemente sem qualquer confirmação de que seu upload está progredindo. Isso não é tanto um problema ao lidar com arquivos menores que podem ser carregados em poucos segundos, mas pode ser um problema ao lidar com arquivos maiores que podem levar minutos para serem carregados. Há uma variedade de controles de upload de arquivos de terceiros que são mais adequados para lidar com grandes uploads e muitos desses fornecedores fornecem indicadores de progresso e gerenciadores de upload ActiveX que apresentam uma experiência de usuário muito mais polida.
Se o seu aplicativo precisa lidar com arquivos grandes, você precisará investigar cuidadosamente os desafios e encontrar soluções adequadas para suas necessidades específicas.
Resumo
A criação de um aplicativo que precisa capturar dados binários apresenta uma série de desafios. Neste tutorial, exploramos os dois primeiros: decidir onde armazenar os dados binários e permitir que um usuário carregue conteúdo binário através de uma página da web. Nos próximos três tutoriais, veremos como associar os dados carregados a um registro no banco de dados, bem como exibir os dados binários ao lado de seus campos de dados de texto.
Feliz Programação!
Leitura adicional
Para obter mais informações sobre os tópicos discutidos neste tutorial, consulte os seguintes recursos:
- Utilizar tipos de dados Large-Value
- Controlos QuickStarts de Carregamento de Ficheiros
- O controle de servidor FileUpload ASP.NET 2.0
- O lado obscuro dos uploads de arquivos
Sobre o Autor
Scott Mitchell, autor de sete livros sobre ASP/ASP.NET e fundador da 4GuysFromRolla.com, trabalha com tecnologias Web da Microsoft desde 1998. Scott trabalha como consultor, formador e escritor independente. Seu último livro é Sams Teach Yourself ASP.NET 2.0 in 24 Hours. Ele pode ser contatado em mitchell@4GuysFromRolla.com.
Um agradecimento especial a
Esta série de tutoriais foi revisada por muitos revisores úteis. Os principais revisores deste tutorial foram Teresa Murphy e Bernadette Leigh. Interessado em rever meus próximos artigos do MSDN? Se for o caso, envie-me uma mensagem para mitchell@4GuysFromRolla.com.