Problemas conhecidos - Azure Site Recovery no Azure Stack Hub
Este artigo descreve problemas conhecidos do Azure Site Recovery no Azure Stack Hub. Use as seções a seguir para obter detalhes sobre os problemas e limitações conhecidos atuais no Azure Site Recovery no Azure Stack Hub.
O tamanho máximo de disco suportado é de 1022 GB
Quando você protege uma VM, o Azure Site Recovery precisa adicionar mais 1 GB de dados a um disco existente. Como o Azure Stack Hub tem uma limitação rígida para o tamanho máximo de um disco em 1023 GB, o tamanho máximo de um disco protegido pela Recuperação de Site deve ser igual ou inferior a 1022.
Quando você tenta proteger uma VM com um disco de 1023Gb, ocorre o seguinte comportamento:
A ativação da proteção é bem-sucedida quando um disco de propagação de apenas 1 GB é criado e está pronto para uso. Não há erro nesta etapa.
A replicação é bloqueada em xx% Sincronizada e, depois de um tempo, a integridade da replicação torna-se Crítica com o erro AzStackToAzStackSourceAgentDiskSourceAgentSlowResyncProgressOnPremToAzure. O erro ocorre porque durante a replicação, o Site Recovery tenta redimensionar o disco de propagação para 1024 GB e gravar nele. Esta operação falha, pois o Azure Stack Hub não suporta discos de 1024 GB.
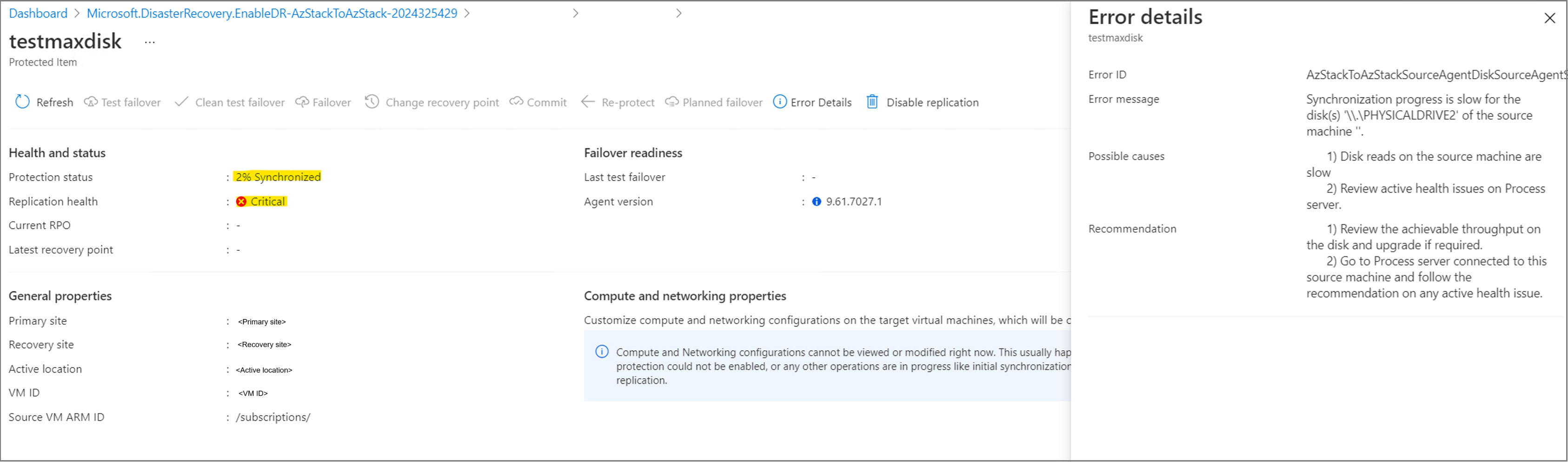
O disco de propagação criado para este disco (na subscrição de destino) ainda tem 1 GB de tamanho e o registo de atividades mostra algumas falhas de disco de escrita com a mensagem de erro O valor '1024' do parâmetro 'disk.diskSizeGb' está fora do intervalo. O valor «1024» deve estar compreendido entre «1» e «1023», inclusive.



A solução alternativa atual para esse problema é criar um novo disco (de 1022 GB ou menos), anexá-lo à sua VM de origem, copiar os dados do disco de 1023 GB para o novo e, em seguida, remover o disco de 1023 GB da VM de origem. Depois que esse procedimento for concluído e a VM tiver todos os discos menores ou iguais a 1022 GB, você poderá habilitar a proteção usando o Azure Site Recovery.
Reproteção: slots de disco de dados disponíveis no dispositivo
Verifique se a VM do dispositivo tem slots de disco de dados suficientes, pois os discos de réplica para reproteção estão conectados ao dispositivo.
O número inicial permitido de discos sendo reprotegidos ao mesmo tempo é 31. O tamanho padrão do appliance criado a partir do item do marketplace é Standard_DS4_v2, que suporta até 32 discos de dados, e o próprio appliance usa um disco de dados.
Se a soma das VMs protegidas for maior que 31, execute uma das seguintes ações:
- Divida as VMs que exigem reproteção em grupos menores para garantir que o número de discos reprotegidos ao mesmo tempo não exceda o número máximo de discos de dados suportados pelo dispositivo.
- Aumente o tamanho da VM do dispositivo Azure Site Recovery.
Nota
Não testamos nem validamos SKUs de VM grandes para a VM do dispositivo.
Se você estiver tentando proteger novamente uma VM, mas não houver slots suficientes no dispositivo para armazenar os discos de replicação, a mensagem de erro Ocorreu um erro interno será exibida. Você pode verificar o número de discos de dados atualmente no dispositivo ou entrar no dispositivo, ir para Visualizador de Eventos e abrir logs para o Azure Site Recovery em Logs de Aplicativos e Serviços:


Encontre o aviso mais recente para identificar o problema.


Versão do kernel da VM Linux não suportada
Verifique a versão do kernel executando o comando
uname -r.
Para obter mais informações sobre as versões suportadas do kernel Linux, consulte Matriz de suporte do Azure para Azure.
Com uma versão do kernel suportada, o failover, que faz com que a VM execute uma reinicialização, pode fazer com que a VM de failover seja atualizada para uma versão mais recente do kernel que pode não ser suportada. Para evitar uma atualização devido a uma reinicialização de VM de failover, execute o comando
sudo apt-mark hold linux-image-azure linux-headers-azurepara que a atualização da versão do kernel possa continuar.Para uma versão do kernel não suportada, verifique se há uma versão mais antiga do kernel para a qual você pode reverter, executando o comando apropriado para sua VM:
- Debian/Ubuntu:
dpkg --list | grep linux-image
A imagem a seguir mostra um exemplo em uma VM do Ubuntu na versão 5.4.0-1103-azure, que não é suportada. Depois que o comando for executado, você poderá ver uma versão suportada, 5.4.0-1077-azure, que já está instalada na VM. Com essas informações, você pode reverter para a versão suportada.

- Debian/Ubuntu:
Reverta para uma versão suportada do kernel usando estas etapas:
Primeiro, faça uma cópia de /etc/default/grub caso haja um erro, por exemplo,
sudo cp /etc/default/grub /etc/default/grub.bak.Em seguida, modifique /etc/default/grub para definir GRUB_DEFAULT para a versão anterior que você deseja usar. Você pode ter algo semelhante a GRUB_DEFAULT="Opções avançadas para Ubuntu>Ubuntu, com Linux 5.4.0-1077-azure".
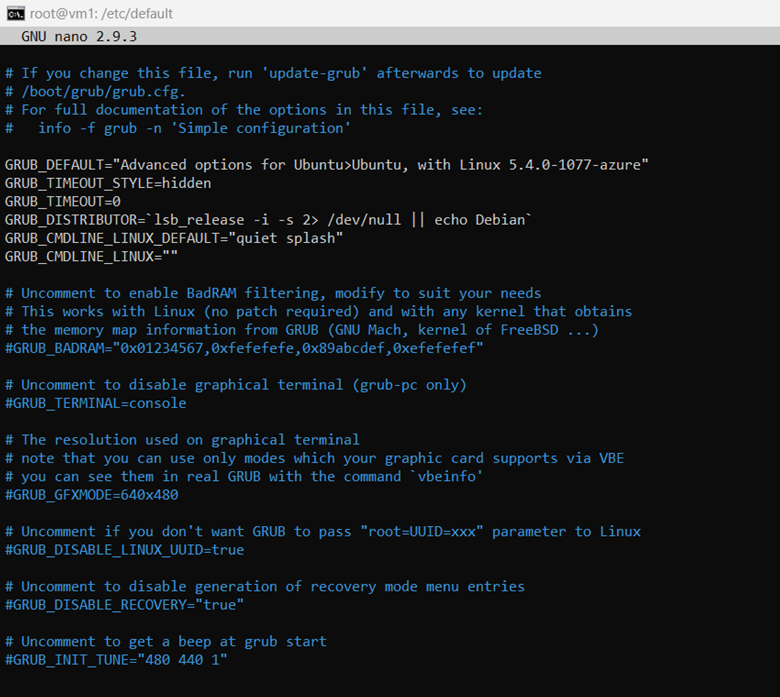
Selecione Guardar para guardar o ficheiro e, em seguida, selecione Sair.
Execute
sudo update-grubpara atualizar o grub.Finalmente, reinicie a VM e continue com a reversão para uma versão do kernel suportada.
Se você não tiver uma versão antiga do kernel para a qual possa reverter, aguarde a atualização do agente de mobilidade para que seu kernel possa ser suportado. A atualização é concluída automaticamente, se estiver pronta, e você pode verificar a versão no portal para confirmar:





A ressincronização manual de reproteção ainda não é suportada
Após a conclusão do trabalho de reproteção, a replicação é iniciada em sequência. Durante a replicação, pode haver casos que exijam uma ressincronização, o que significa que uma nova replicação inicial é acionada para sincronizar todas as alterações.
Existem dois tipos de ressincronização:
Resincronização automática. Não requer nenhuma ação do usuário e é feito automaticamente. Os usuários podem ver alguns eventos mostrados no portal:

Resincronização manual. Requer ação do usuário para acionar a ressincronização manualmente e é necessária nas seguintes instâncias:
A conta de armazenamento escolhida para a reproteção está ausente.
O disco de replicação no dispositivo está ausente.
A gravação de replicação excede a capacidade do disco de replicação no dispositivo.
Gorjeta
Você também pode encontrar os motivos da ressincronização manual na folha de eventos para ajudá-lo a decidir se uma ressincronização manual é necessária.

Problemas conhecidos na automação do PowerShell
Se você sair
$failbackPolicyNamevazio$failbackExtensionNameou nulo, a nova proteção pode falhar. Veja os exemplos seguintes:

Sempre especifique o
$failbackPolicyNamee$failbackExtensionName, conforme mostrado no exemplo a seguir:$failbackPolicyName = "failback-default-replication-policy" $failbackExtensionName = "default-failback-extension" $parameters = @{ "properties" = @{ "customProperties" = @{ "instanceType" = "AzStackToAzStackFailback" "applianceId" = $applianceId "logStorageAccountId" = $LogStorageAccount.Id "policyName" = $failbackPolicyName "replicationExtensionName" = $failbackExtensionName } } } $result = Invoke-AzureRmResourceAction -Action "reprotect" ` -ResourceId $protectedItemId ` -Force -Parameters $parameters


Aviso do agente de serviço de mobilidade
Ao replicar várias VMs, você pode ver a integridade do item protegido alterada para erro de Aviso nos trabalhos de Recuperação de Site.

Essa mensagem de erro deve ser apenas um aviso e não é um problema de bloqueio para os processos reais de replicação ou failover.
Gorjeta
Você pode verificar o estado da respetiva VM para garantir que ela esteja íntegra.
A exclusão da VM do dispositivo (origem) bloqueia a exclusão do cofre (destino)
Para excluir o cofre do Azure Site Recovery no destino, você deve primeiro remover todas as VMs protegidas. Se você excluir a VM do dispositivo primeiro, o cofre do Site Recovery bloqueará a exclusão dos recursos protegidos e a tentativa de excluir o próprio cofre também falhará. A exclusão do grupo de recursos também falha, e a única maneira de remover o cofre é excluindo a assinatura de usuário do Azure Stack Hub na qual o cofre é criado.
Para evitar esse problema, primeiro remova a proteção de todos os itens no cofre antes de excluir a VM do dispositivo. Isso permite que o cofre conclua a limpeza de recursos no dispositivo (lado da origem). Depois que os itens protegidos forem removidos, você poderá excluir o cofre e remover a VM do dispositivo.