Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Constrói um agente de IA e implementa-o usando as aplicações Databricks. O Databricks Apps dá-lhe controlo total sobre o código do agente, configuração do servidor e fluxo de trabalho de implementação. Esta abordagem é ideal quando se precisa de comportamento personalizado de servidores, versionamento baseado em git ou desenvolvimento local de IDE.
Requerimentos
Ative as aplicações Databricks no seu espaço de trabalho. Consulte Configurar seu espaço de trabalho e ambiente de desenvolvimento do Databricks Apps.
Passo 1. Clonar o modelo de aplicação do agente
Comece por usar um modelo de agente pré-construído do repositório de templates da aplicação Databricks.
Este tutorial utiliza o agent-openai-agents-sdk modelo, que inclui:
- Um agente criado usando OpenAI Agent SDK
- Código inicial para uma aplicação agente com uma API REST conversacional e uma interface de chat interativa
- Código para avaliar o agente usando MLflow
Escolha um dos seguintes caminhos para configurar o modelo:
Interface do usuário do espaço de trabalho
Instala o modelo da aplicação usando a interface do Workspace. Isto instala a aplicação e implementa-a num recurso de computação no seu espaço de trabalho. Pode então sincronizar os ficheiros da aplicação para o seu ambiente local para desenvolvimento futuro.
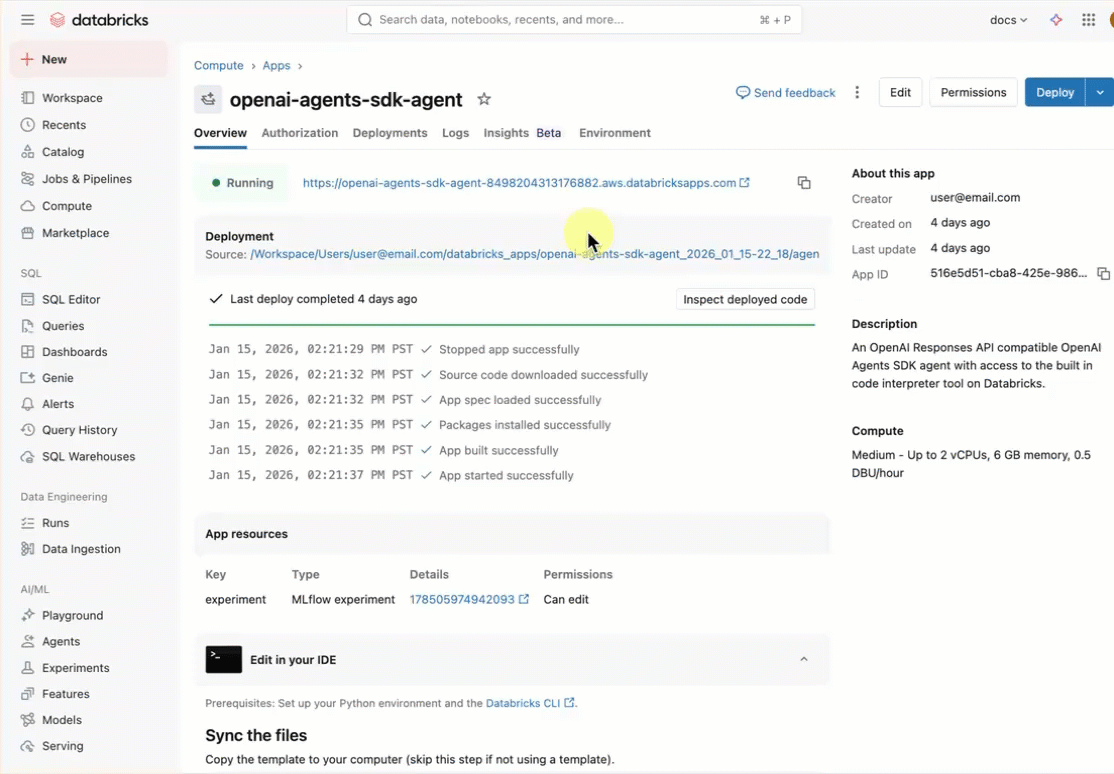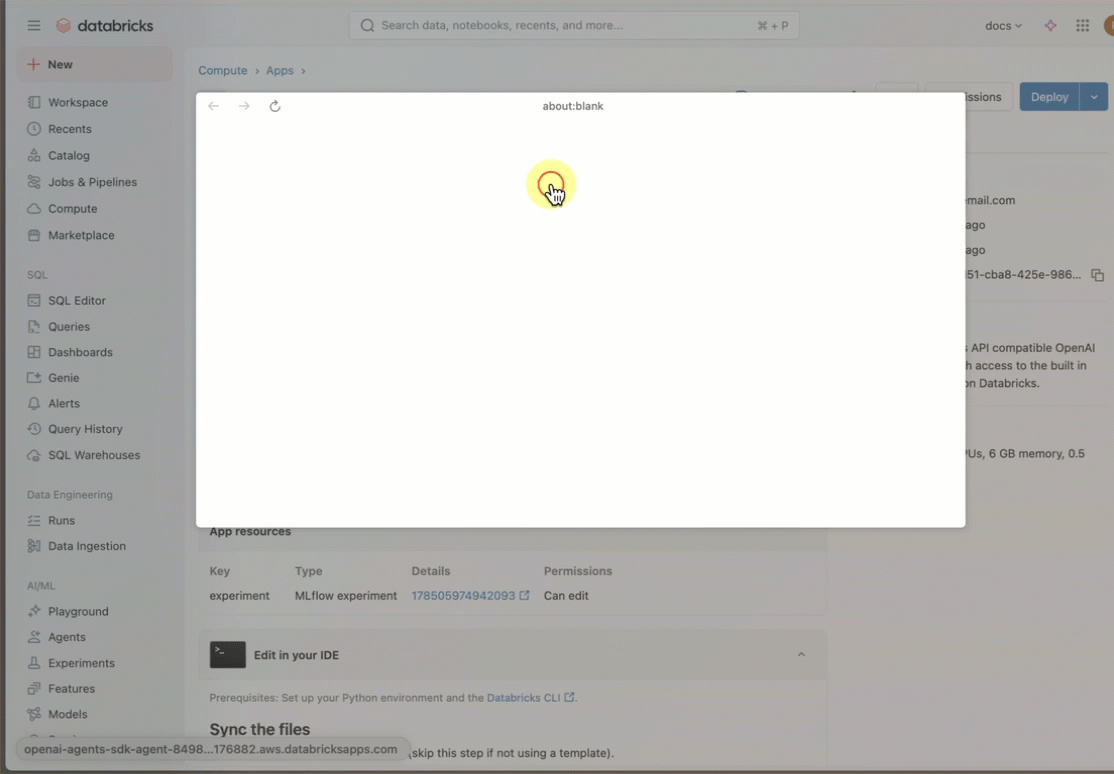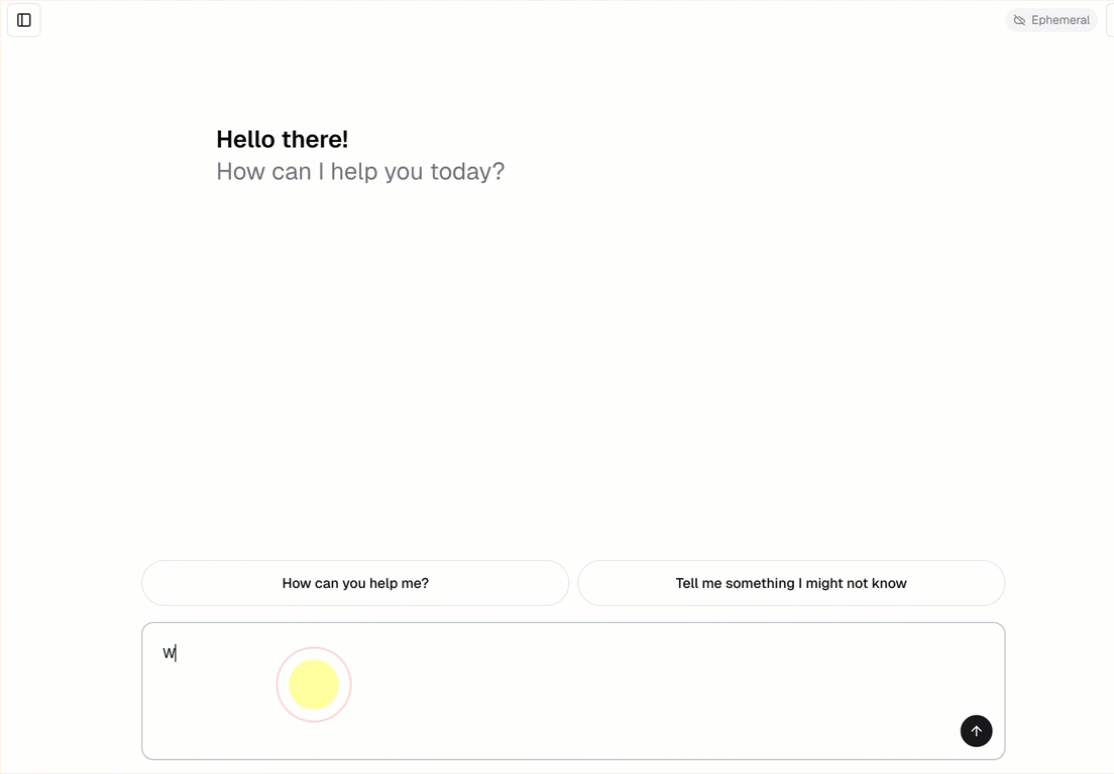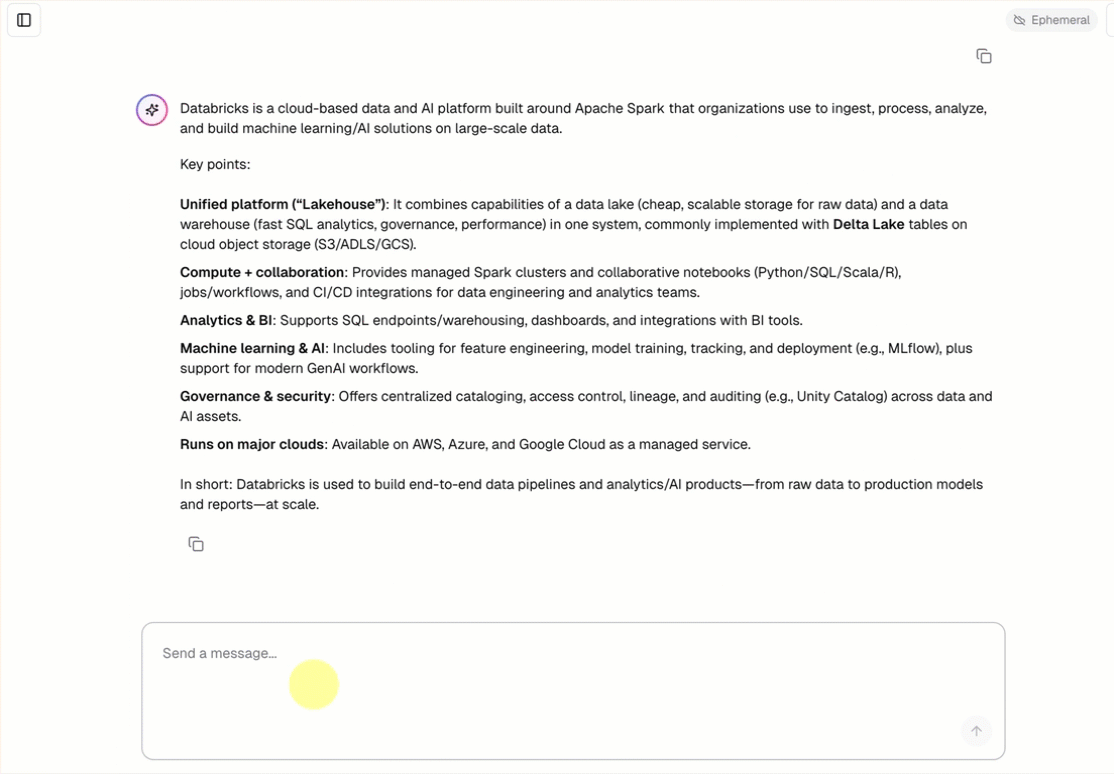
No seu espaço de trabalho Databricks, clique em + Nova>Aplicação.
Clique Agents>Agent - OpenAI Agents SDK.
Crie um novo experimento MLflow com o nome
openai-agents-templatee complete o resto da configuração para instalar o modelo.Depois de criares a aplicação, clica no URL da aplicação para abrir a interface do chat.
Depois de criar a aplicação, descarregue o código-fonte para a sua máquina local para a personalizar:
Copie o primeiro comando em Sincronizar os ficheiros
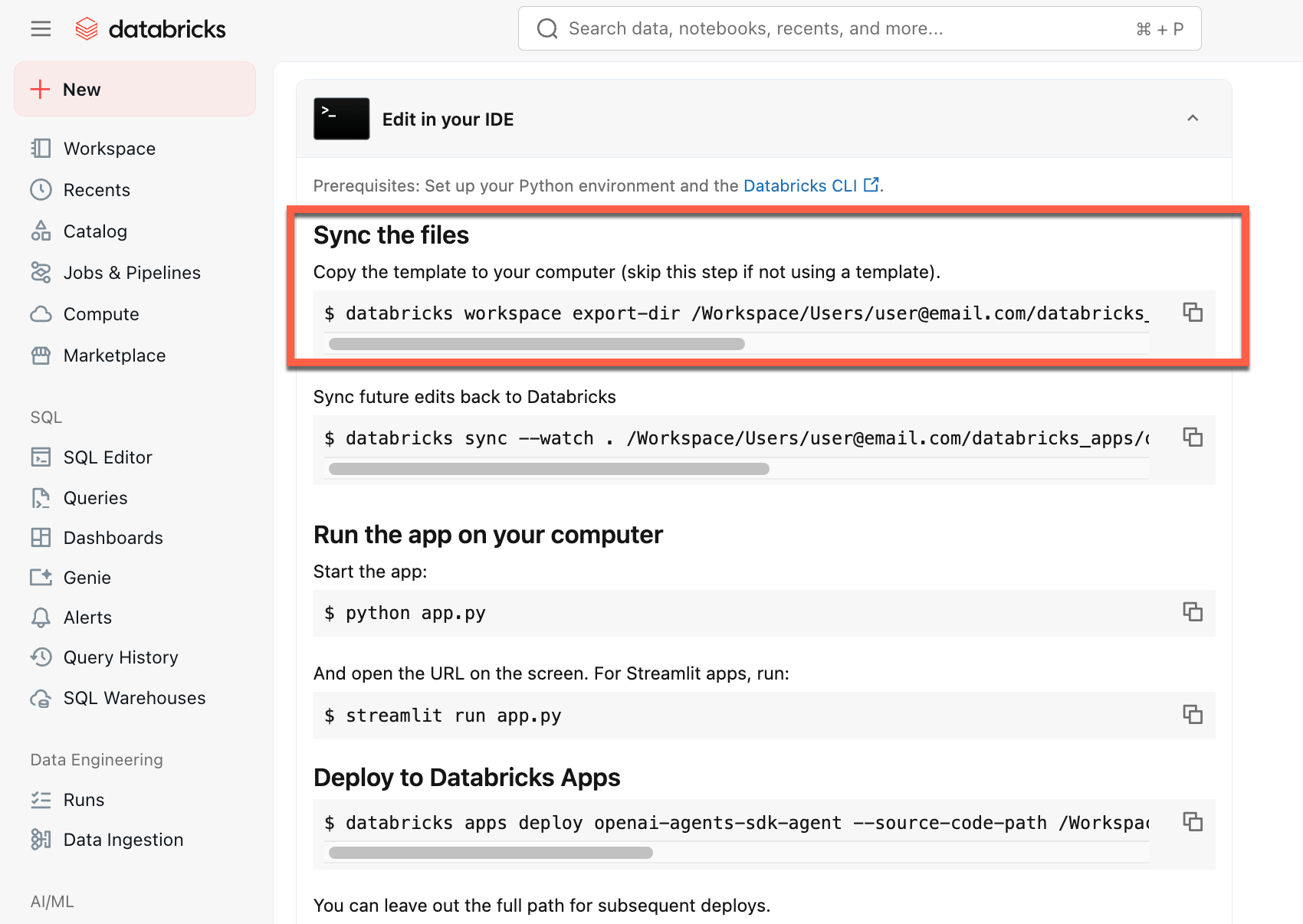
Num terminal local, executa o comando copiado.
Clonar do GitHub
Para começar a partir de um ambiente local, clone o repositório de modelos de agente e abra o agent-openai-agents-sdk diretório:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Passo 2. Compreenda a candidatura do agente
O modelo de agente demonstra uma arquitetura pronta para produção com estes componentes-chave. Abra as secções seguintes para mais detalhes sobre cada componente:

Abra as secções seguintes para mais detalhes sobre cada componente:
 MLflow AgentServer
MLflow AgentServer
Um servidor FastAPI assíncrono que gere pedidos de agente com rastreamento e observabilidade incorporados. O AgentServer fornece o /invocations endpoint para consultar o seu agente e gere automaticamente o encaminhamento dos pedidos, o registo e o tratamento de erros.

ResponsesAgent Interface
O Databricks recomenda o MLflow ResponsesAgent para construir agentes.
ResponsesAgent permite criar agentes com qualquer estrutura de terceiros e, em seguida, integrá-la aos recursos de IA do Databricks para recursos robustos de registro, rastreamento, avaliação, implantação e monitoramento.

Para aprender a criar um ResponsesAgent, veja os exemplos na documentação do MLflow - ResponsesAgent for Model Serving.
ResponsesAgent oferece os seguintes benefícios:
Recursos avançados do agente
- Suporte a vários agentes
- Saída de streaming: transmita a saída em partes menores.
- Histórico abrangente de mensagens de chamada de ferramentas: Devolve várias mensagens, incluindo mensagens intermediárias de chamada de ferramentas, para aperfeiçoar a qualidade e o gerenciamento das conversas.
- Suporte de confirmação de invocação de ferramenta
- Suporte para ferramentas operacionais de longa duração
Desenvolvimento, implantação e monitoramento simplificados
-
Crie agentes usando qualquer estrutura: envolva qualquer agente existente usando a interface para obter compatibilidade imediata com o AI Playground, a Avaliação de Agentes e o
ResponsesAgentMonitoramento de Agentes. - Interfaces de criação tipadas: Escreva código de agente usando classes Python tipadas, beneficiando-se do IDE e do preenchimento automático do notebook.
- Rastreamento automático: O MLflow agrega automaticamente as respostas em fluxo em traços para facilitar a avaliação e visualização.
-
Compatível com o esquema OpenAI
Responses: Veja OpenAI: Respostas vs. ChatCompletion.
-
Crie agentes usando qualquer estrutura: envolva qualquer agente existente usando a interface para obter compatibilidade imediata com o AI Playground, a Avaliação de Agentes e o
 SDK de Agentes OpenAI
SDK de Agentes OpenAI
O modelo utiliza o OpenAI Agents SDK como framework de agentes para gestão de conversas e orquestração de ferramentas. Podes criar agentes usando qualquer framework. A chave é envolver o seu agente com a interface MLflow ResponsesAgent.
 Servidores MCP (Model Context Protocol)
Servidores MCP (Model Context Protocol)
O template liga-se aos servidores MCP do Databricks para dar aos agentes acesso a ferramentas e fontes de dados. Consulte Protocolo de contexto de modelo (MCP) em Databricks.
Agentes que criam usando assistentes de codificação com IA
A Databricks recomenda a utilização de assistentes de programação de IA como Claude, Cursor e Copilot para criar agentes. Use as competências de agente fornecidas, em /.claude/skills, e o AGENTS.md ficheiro para ajudar os assistentes de IA a compreender a estrutura do projeto, as ferramentas disponíveis e as melhores práticas. Os agentes podem ler automaticamente esses ficheiros para desenvolver e implementar as aplicações Databricks.
Tópicos avançados de autoria
Respostas em streaming
Respostas em streaming
O streaming permite que os agentes enviem respostas em partes em tempo real, em vez de esperar pela resposta completa. Para implementar o streaming com o ResponsesAgent, emita uma série de eventos delta seguidos por um evento de conclusão final:
-
Emitir eventos delta: envie vários
output_text.deltaeventos com o mesmoitem_idpara transmitir blocos de texto em tempo real. -
Terminar com evento concluído: envie um evento final
response.output_item.donecom o mesmoitem_idque os eventos delta contendo o texto de saída final completo.
Cada evento delta transmite um pedaço de texto para o cliente. O evento final concluído contém o texto de resposta completo e sinaliza o Databricks para fazer o seguinte:
- Rastreie a saída do seu agente com o rastreamento MLflow
- Agregar respostas transmitidas em fluxo nas tabelas de inferência do AI Gateway
- Mostrar a saída completa na interface do usuário do AI Playground
Propagação de erros de streaming
O Mosaic AI propaga quaisquer erros que sejam encontrados durante o streaming sob o último token em databricks_output.error. Cabe ao cliente que faz a chamada lidar adequadamente e tratar esse erro.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Entradas e saídas personalizadas
Entradas e saídas personalizadas
Alguns cenários podem exigir entradas adicionais do agente, como client_type e session_id, ou saídas, como links de fontes de recuperação, que não devem constar no histórico de conversas para interações futuras.
Para esses cenários, o MLflow ResponsesAgent suporta nativamente os campos custom_inputs e custom_outputs. Podes aceder às entradas personalizadas através request.custom_inputs dos exemplos do framework acima.
O aplicativo de revisão de Avaliação do Agente não suporta a renderização de rastros para agentes com campos de entrada adicionais.
Fornecer custom_inputs no AI Playground e na aplicação de revisão
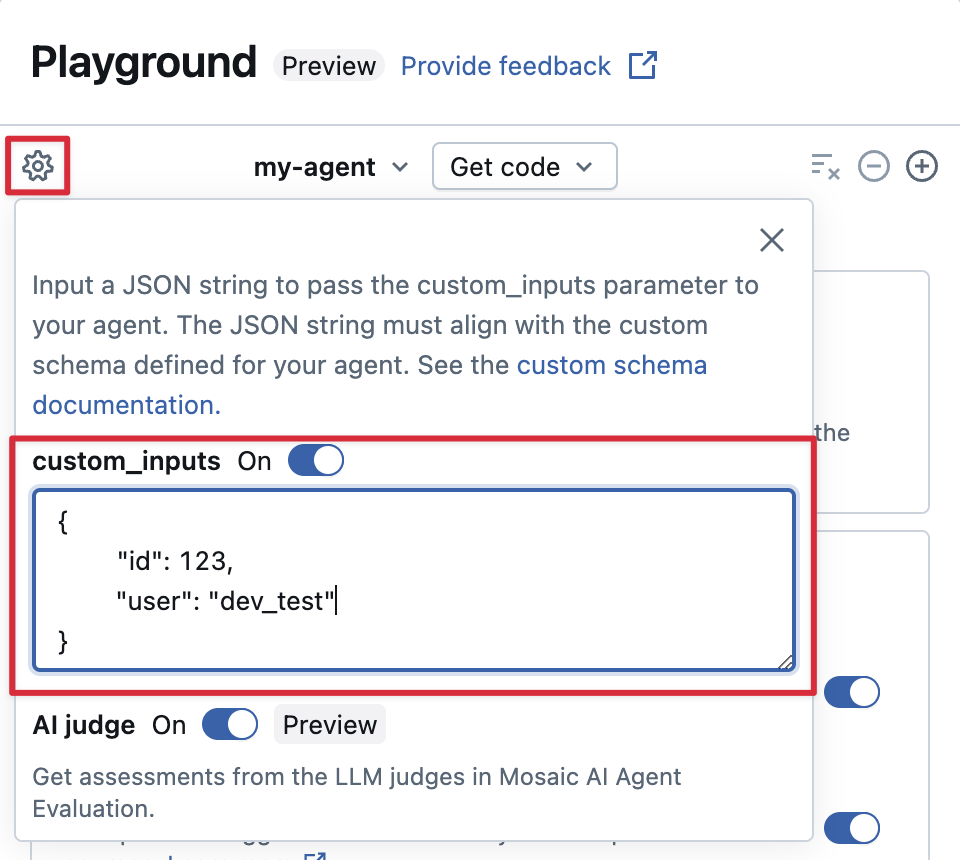
Se o seu agente aceitar entradas adicionais usando o custom_inputs campo, você poderá fornecer manualmente essas entradas no AI Playground e no aplicativo de revisão.
No AI Playground ou na aplicação Agent Review, selecione o ícone de engrenagem

Habilite custom_inputs.
Forneça um objeto JSON que corresponda ao esquema de entrada definido pelo agente.
Esquemas de retriever personalizados
Esquemas recuperadores personalizados
Os agentes de IA geralmente usam retrievers para encontrar e consultar dados não estruturados de índices de pesquisa vetorial. Por exemplo, para ferramentas de recuperação, consulte Ligar agentes a dados não estruturados.
Rastreie esses retrievers dentro do seu agente com as spans MLflow RETRIEVER para habilitar as funcionalidades do produto Databricks, incluindo:
- Exibição automática de links para documentos de origem recuperados na interface do usuário do AI Playground
- Execução automática de julgamentos automatizados de fundamentação na recuperação e relevância na Avaliação de Agentes
Observação
O Databricks recomenda o uso de ferramentas de recuperação fornecidas pelos pacotes Databricks AI Bridge, como databricks_langchain.VectorSearchRetrieverTool e databricks_openai.VectorSearchRetrieverTool, porque eles já estão em conformidade com o esquema MLflow retriever. Veja como desenvolver localmente ferramentas de pesquisa vetorial com o AI Bridge.
Se o seu agente incluir partes de retriever com um esquema personalizado, chame mlflow.models.set_retriever_schema ao definir o agente no código. Isso mapeia as colunas de saída do seu retriever para os campos esperados do MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Observação
A doc_uri coluna é especialmente importante ao avaliar o desempenho do retriever.
doc_uri é o identificador principal dos documentos devolvidos pelo recuperador, permitindo-lhe compará-los com conjuntos de avaliação das verdades de referência. Consulte Conjuntos de avaliação (MLflow 2).
Passo 3. Executa a aplicação do agente localmente
Configure o seu ambiente local:
Instalar
uv(gestor de pacotes Python),nvm(gestor de versões de Node) e CLI do Databricks:-
uvInstalação -
nvmInstalação - Execute o seguinte para usar o Node 20 LTS:
nvm use 20 -
databricks CLIInstalação
-
Muda o diretório para a
agent-openai-agents-sdkpasta.Executa os scripts de início rápido fornecidos para instalar dependências, configurar o ambiente e iniciar a aplicação.
uv run quickstart uv run start-app
Num navegador, acede a http://localhost:8000 para começar a conversar com o agente.
Passo 4. Configurar a autenticação
O seu agente precisa de autenticação para aceder aos recursos do Databricks. O Databricks Apps fornece dois métodos de autenticação:
Autorização de aplicação (por defeito)
A autorização de aplicações utiliza um princípio de serviço que o Azure Databricks cria automaticamente para a sua aplicação. Todos os utilizadores partilham as mesmas permissões.
Conceder permissões ao experimento MLflow:
- Clique em Editar na página inicial da sua aplicação.
- Navegue até ao passo Configurar .
- Na secção recursos da app, adicione o recurso de experimentação MLflow com
Can Editpermissão.
Para outros recursos (Vector Search, espaços Genie, pontos de serviço), adicione-os da mesma forma na secção de Recursos da Aplicação.
Consulte autorização de aplicação para mais detalhes.
Autorização do utilizador
A autorização do utilizador permite ao seu agente agir com as permissões individuais de cada utilizador. Use isto quando precisar de controlo de acesso por utilizador ou de registos de auditoria.
Adicione este código ao seu agente:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Importante: Inicialize o get_user_workspace_client() dentro das suas funções @invoke ou @stream, não durante o arranque da aplicação. As credenciais de utilizador só existem ao lidar com um pedido.
Configurar os escopos: Adicione escopos de autorização na interface de aplicações do Databricks para definir quais APIs o seu agente pode aceder em nome dos utilizadores.
Consulte autorização de utilizador para instruções completas de configuração.
Passo 5. Avaliar o agente
O modelo inclui código de avaliação de agentes. Consulte agent_server/evaluate_agent.py para obter mais informações. Avalie a relevância e segurança das respostas do seu agente executando o seguinte num terminal:
uv run agent-evaluate
Passo 6. Implementar o agente para as aplicações Databricks
Depois de configurar a autenticação, implemente o seu agente no Databricks. Certifique-se de que tem a CLI do Databricks instalada e configurada.
Se clonaste o repositório localmente, cria a aplicação Databricks antes de a implementar. Se criaste a tua aplicação através da interface do espaço de trabalho, salta este passo, pois a aplicação e o experimento MLflow já estão configurados.
databricks apps create agent-openai-agents-sdkSincroniza ficheiros locais com o teu espaço de trabalho. Veja Implementar a aplicação.
DATABRICKS_USERNAME=$(databricks current-user me | jq -r .userName) databricks sync . "/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk"Implemente a sua aplicação Databricks.
databricks apps deploy agent-openai-agents-sdk --source-code-path /Workspace/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk
Para futuras atualizações do agente, sincroniza e reimplementa o teu agente.
Passo 7. Consultar o agente implementado
Os utilizadores consultam o seu agente implementado usando tokens OAuth. Tokens de acesso pessoal (PATs) não são suportados para aplicações Databricks.
Gerar um token OAuth usando a CLI Databricks:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Utilize o token para consultar o agente:
curl -X POST <app-url.databricksapps.com>/invocations \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Limitações
Apenas tamanhos de computação médios e grandes são suportados. Consulte Configurar o tamanho de computação para um aplicativo Databricks.