Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Neste guia, você aprenderá como melhorar a qualidade do seu modelo de Visão Personalizada. A qualidade do seu classificador ou detetor de objetos depende da quantidade, qualidade e variedade de dados rotulados que você fornece e do quão equilibrado é o conjunto de dados geral. Um bom modelo tem um conjunto de dados de treinamento equilibrado que é representativo do que é submetido a ele. O processo de construção de tal modelo é iterativo; É comum fazer algumas rodadas de treinamento para alcançar os resultados esperados.
A seguir está um padrão geral para ajudá-lo a treinar um modelo mais preciso:
- Treino de primeira fase
- Adicione mais imagens e dados de equilíbrio; retreinar
- Adicione imagens com fundo variável, iluminação, tamanho do objeto, ângulo da câmera e estilo; retreinar
- Usar novas imagens para testar a previsão
- Modificar dados de treinamento existentes de acordo com os resultados da previsão
Evitar sobreajuste
Às vezes, um modelo aprende a fazer previsões com base em características arbitrárias que suas imagens têm em comum. Por exemplo, se estiver a criar um classificador para maçãs vs. citrinos e tiver utilizado imagens de maçãs nas mãos e de citrinos em pratos brancos, o classificador pode dar uma importância indevida às mãos vs. pratos, em vez de maçãs vs. citrinos.
Para corrigir esse problema, forneça imagens com diferentes ângulos, planos de fundo, tamanho do objeto, grupos e outras variações. As seções a seguir expandem esses conceitos.
Garantir a quantidade de dados
O número de imagens de treinamento é o fator mais importante para seu conjunto de dados. Recomendamos o uso de pelo menos 50 imagens por rótulo como ponto de partida. Com menos imagens, há um risco maior de sobreajuste e, embora seus números de desempenho possam sugerir boa qualidade, seu modelo pode ter dificuldades com dados do mundo real.
Garantir o equilíbrio dos dados
Também é importante considerar as quantidades relativas de seus dados de treinamento. Por exemplo, usar 500 imagens para um rótulo e 50 imagens para outro rótulo cria um conjunto de dados de treinamento desequilibrado. Isso faz com que o modelo seja mais preciso na previsão de um rótulo do que de outro. É provável que veja melhores resultados se mantiver pelo menos uma proporção de 1:2 entre a etiqueta com menos imagens e a etiqueta com mais imagens. Por exemplo, se a etiqueta com mais imagens tiver 500 imagens, a etiqueta com menos imagens deve ter pelo menos 250 imagens para formação.
Garanta a variedade de dados
Certifique-se de usar imagens representativas do que será enviado ao classificador durante o uso normal. Caso contrário, seu modelo poderia aprender a fazer previsões com base em características arbitrárias que suas imagens têm em comum. Por exemplo, se estiver a criar um classificador para maçãs vs. citrinos e tiver utilizado imagens de maçãs nas mãos e de citrinos em pratos brancos, o classificador pode dar uma importância indevida às mãos vs. pratos, em vez de maçãs vs. citrinos.

Para corrigir esse problema, inclua uma variedade de imagens para garantir que seu modelo possa generalizar bem. Abaixo estão algumas maneiras de tornar seu conjunto de treinamento mais diversificado:
Fundo: Forneça imagens do seu objeto com diferentes fundos. Fotos em contextos naturais são melhores do que fotos em frente a fundos neutros, pois fornecem mais informações para o classificador.

Iluminação: Forneça imagens com iluminação variada (ou seja, tiradas com flash, alta exposição, e assim por diante), especialmente se as imagens usadas para previsão tiverem iluminação diferente. Também é útil usar imagens com saturação, matiz e brilho variáveis.

Tamanho do objeto: Forneça imagens nas quais os objetos variam em tamanho e número (por exemplo, uma foto de cachos de bananas e um closeup de uma única banana). Tamanhos diferentes ajudam o classificador a generalizar melhor.

Ângulo da câmera: Forneça imagens tiradas com diferentes ângulos de câmera. Como alternativa, se todas as suas fotos tiverem de ser tiradas com câmaras fixas (como câmaras de vigilância), certifique-se de que atribui uma etiqueta diferente a cada objeto que ocorre regularmente para evitar sobreajustes, interpretando objetos não relacionados (como postes de iluminação) como a principal característica.

Estilo: Forneça imagens de diferentes estilos da mesma classe (por exemplo, diferentes variedades da mesma fruta). No entanto, se você tiver objetos de estilos drasticamente diferentes (como o Mickey Mouse versus um mouse da vida real), recomendamos que você os rotule como classes separadas para representar melhor suas características distintas.

Utilize imagens negativas (somente classificadores)
Se estiver a utilizar um classificador de imagens, poderá ter de adicionar amostras negativas para ajudar a tornar o classificador mais preciso. Amostras negativas são imagens que não correspondem a nenhuma das outras tags. Quando carregar estas imagens, aplique a etiqueta especial Negativo.
Os detetores de objetos lidam com amostras negativas automaticamente, porque quaisquer áreas de imagem fora das caixas delimitadoras desenhadas são consideradas negativas.
Nota
O serviço Visão Personalizada suporta algum tratamento automático de imagens negativas. Por exemplo, se estiveres a construir um classificador de uva versus banana e submeteres uma imagem de um sapato para previsão, o classificador deve pontuar essa imagem como próxima de 0% tanto para uva como para banana.
Por outro lado, nos casos em que as imagens negativas são apenas uma variação das imagens utilizadas no treino, é provável que o modelo classifique as imagens negativas como uma classe rotulada devido às grandes semelhanças. Por exemplo, se tiveres um classificador para laranja versus toranja e introduzires uma imagem de uma clementina, poderá classificar a clementina como uma laranja, porque muitas características da clementina se assemelham às das laranjas. Se suas imagens negativas forem dessa natureza, recomendamos que você crie uma ou mais tags extras (como Outras) e rotule as imagens negativas com essa tag durante o treinamento para permitir que o modelo diferencie melhor entre essas classes.
Manipular oclusão e truncamento (somente detectores de objetos)
Se desejar que o detetor de objetos detete objetos truncados (objetos parcialmente cortados da imagem) ou ocluídos (objetos parcialmente bloqueados por outros objetos na imagem), será necessário incluir imagens de treinamento que abranjam esses casos.
Nota
A questão dos objetos serem ocluídos por outros objetos não deve ser confundida com o Limiar de Sobreposição, um parâmetro para avaliar o desempenho do modelo. O controlador Limite de Sobreposição no site da Visão Personalizada relaciona-se com a quantidade de sobreposição que uma caixa delimitadora prevista deve ter com a caixa delimitadora verdadeira para ser considerada correta.
Use imagens de previsão para treinamento adicional
Quando o utilizador utiliza ou testa o modelo ao enviar imagens para o endpoint de previsão, o serviço Custom Vision armazena essas imagens. Em seguida, você pode usá-los para melhorar o modelo.
Para visualizar as imagens enviadas para o modelo, abra a página da Web Visão Personalizada, vá para seu projeto e selecione a guia Previsões . A visualização padrão mostra imagens da iteração atual. Você pode usar o menu suspenso Iteração para visualizar imagens enviadas durante iterações anteriores.
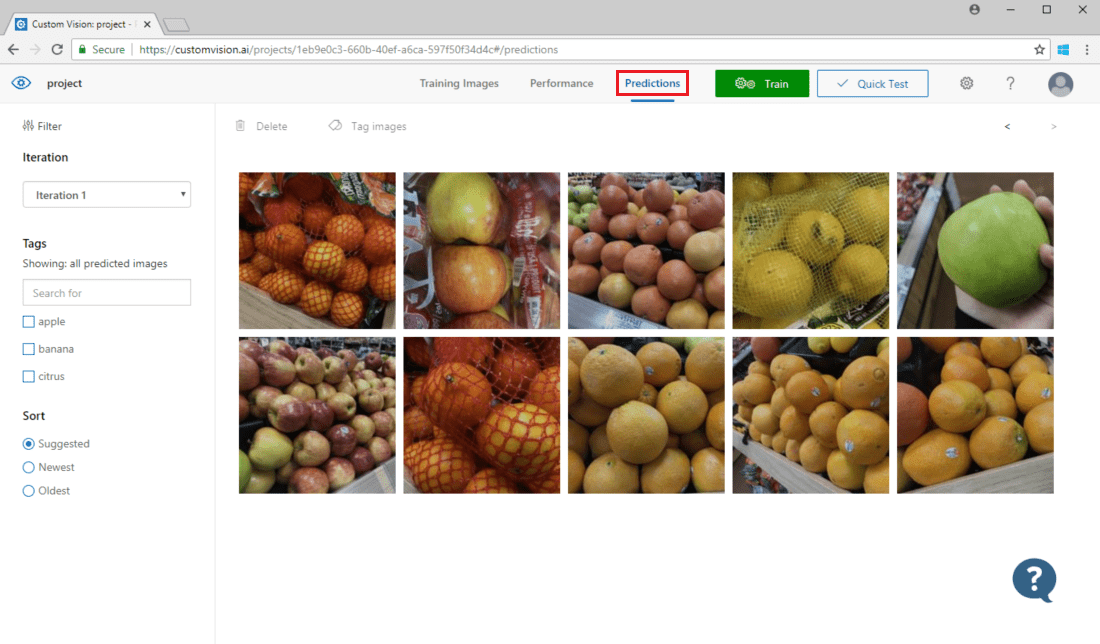
Passe o cursor sobre uma imagem para ver as tags que foram previstas pelo modelo. As imagens são ordenadas para que as que podem trazer mais melhorias para o modelo sejam listadas no topo. Para usar um método de classificação diferente, faça uma seleção na seção Classificar .
Para adicionar uma imagem aos dados de treinamento existentes, selecione a imagem, defina a(s) marca(s) correta(s) e selecione Salvar e fechar. A imagem é removida de Previsões e adicionada ao conjunto de imagens de treinamento. Você pode visualizá-lo selecionando o separador Imagens de Treinamento.
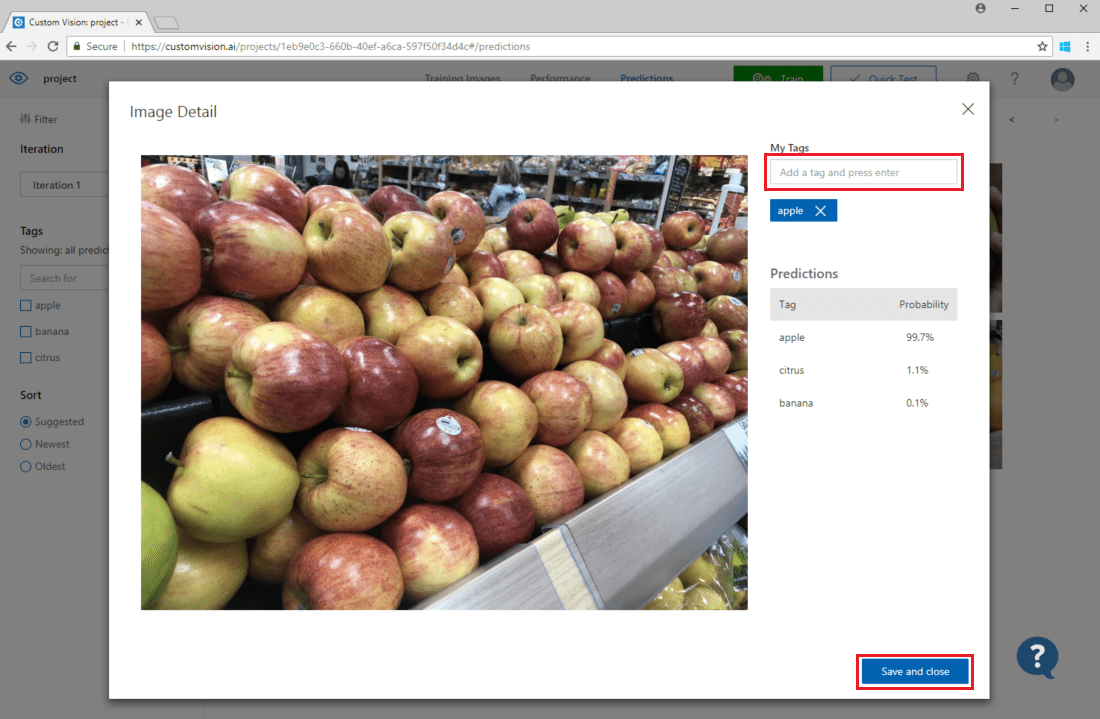
Em seguida, use o botão Treinar para treinar novamente o modelo.
Inspecione visualmente as previsões
Para inspecionar previsões de imagem, vá para o separador Imagens de Treinamento, selecione sua iteração de treinamento anterior no menu suspenso Iteração e marque uma ou mais tags na secção Tags. A visualização agora deve exibir uma caixa vermelha ao redor de cada uma das imagens para as quais o modelo não conseguiu prever corretamente a tag fornecida.
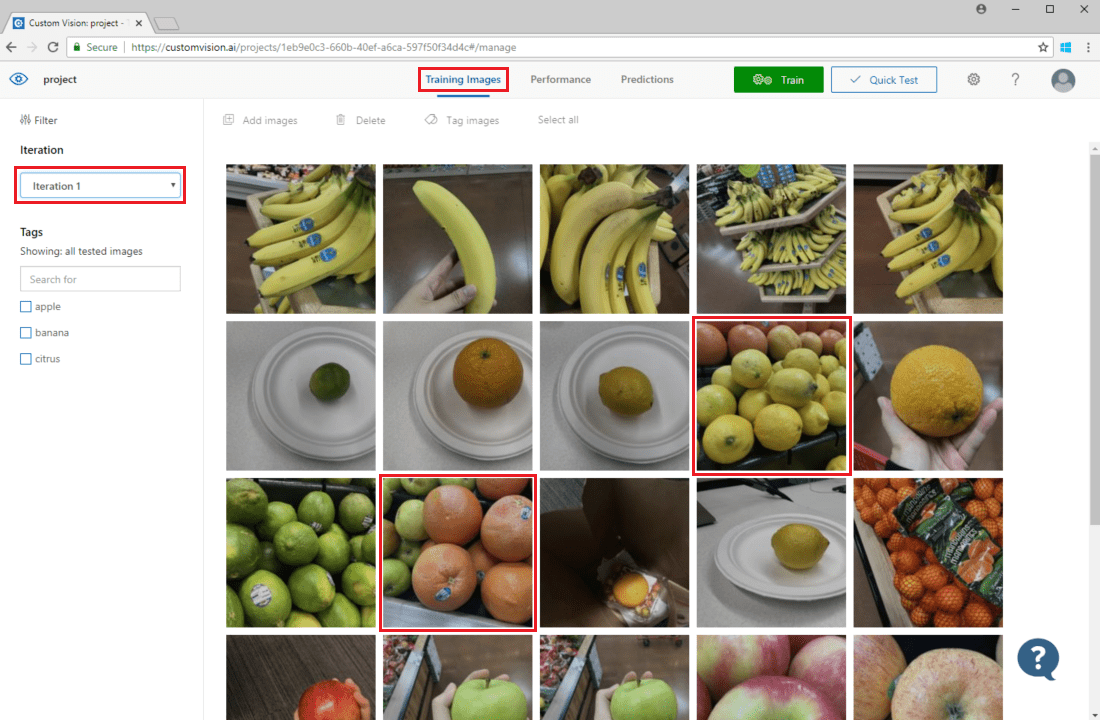
Às vezes, uma inspeção visual pode identificar padrões que você pode corrigir adicionando mais dados de treinamento ou modificando dados de treinamento existentes. Por exemplo, um classificador para maçãs vs. limas pode rotular incorretamente todas as maçãs verdes como limas. Em seguida, você pode corrigir esse problema adicionando e fornecendo dados de treinamento que contêm imagens marcadas de maçãs verdes.
Próximo passo
Neste guia, você aprendeu várias técnicas para tornar seu modelo de classificação de imagem personalizado ou modelo de detetor de objetos mais preciso. Em seguida, saiba como testar imagens programaticamente enviando-as para a API de previsão.