Crie e treine um modelo de extração personalizado
Este conteúdo aplica-se a:![]() v4.0 (GA) | Versões anteriores:
v4.0 (GA) | Versões anteriores:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1
v2.1
Os modelos personalizados do Document Intelligence exigem um punhado de documentos de treinamento para começar. Se tiver pelo menos cinco documentos, poderá começar a preparação de um modelo personalizado. Você pode treinar um modelo de modelo personalizado (formulário personalizado) ou um modelo neural personalizado (documento personalizado). Este documento orienta você pelo processo de treinamento dos modelos personalizados.
Requisitos de entrada do modelo personalizado
Primeiro, certifique-se de que seu conjunto de dados de treinamento siga os requisitos de entrada para Document Intelligence.
Formatos de ficheiro suportados:
| Modelo | Imagem: JPEG/JPG, PNG, BMP, TIFF, , HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lida | ✔ | ✔ | ✔ |
| Esquema | ✔ | ✔ | ✔ |
| Documento Geral | ✔ | ✔ | |
| Pré-criado | ✔ | ✔ | |
| Extração personalizada | ✔ | ✔ | |
| Classificação personalizada | ✔ | ✔ | ✔ |
Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 pixels x 50 pixels e 10.000 pixels x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a cerca
8de texto pontual a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GB com um máximo de 10.000 páginas. Para 2024-11-30 (GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Dicas de dados de treinamento
Siga estas sugestões para otimizar ainda mais o conjunto de dados para a preparação:
- Use documentos PDF baseados em texto em vez de documentos baseados em imagem. Os PDFs digitalizados são processados como imagens.
- Use exemplos que tenham todos os campos preenchidos para formulários com campos de entrada.
- Utilize formulários com diferentes valores em cada campo.
- Use um conjunto de dados maior (10 a 15 imagens) se as imagens do formulário forem de qualidade inferior.
Carregue seus dados de treinamento
Depois de reunir um conjunto de formulários ou documentos para treinamento, você precisa carregá-lo em um contêiner de armazenamento de blob do Azure. Se você não souber como criar uma conta de armazenamento do Azure com um contêiner, siga o início rápido do Armazenamento do Azure para o portal do Azure. Você pode usar o nível de preço gratuito (F0) para experimentar o serviço e atualizar posteriormente para um nível pago para produção.
Vídeo: Treine seu modelo personalizado
- Depois de reunir e carregar seu conjunto de dados de treinamento, você estará pronto para treinar seu modelo personalizado. No vídeo a seguir, criamos um projeto e exploramos alguns dos fundamentos para rotular e treinar um modelo com sucesso.
Criar um projeto no Document Intelligence Studio
O Document Intelligence Studio fornece e orquestra todas as chamadas de API necessárias para concluir seu conjunto de dados e treinar seu modelo.
Comece navegando até o Document Intelligence Studio. Na primeira vez que usar o Studio, você precisará inicializar sua assinatura, grupo de recursos e recurso. Em seguida, siga os pré-requisitos para projetos personalizados para configurar o Studio para acessar seu conjunto de dados de treinamento.
No Studio, selecione o bloco Modelo de extração personalizado e selecione o botão Criar um projeto .
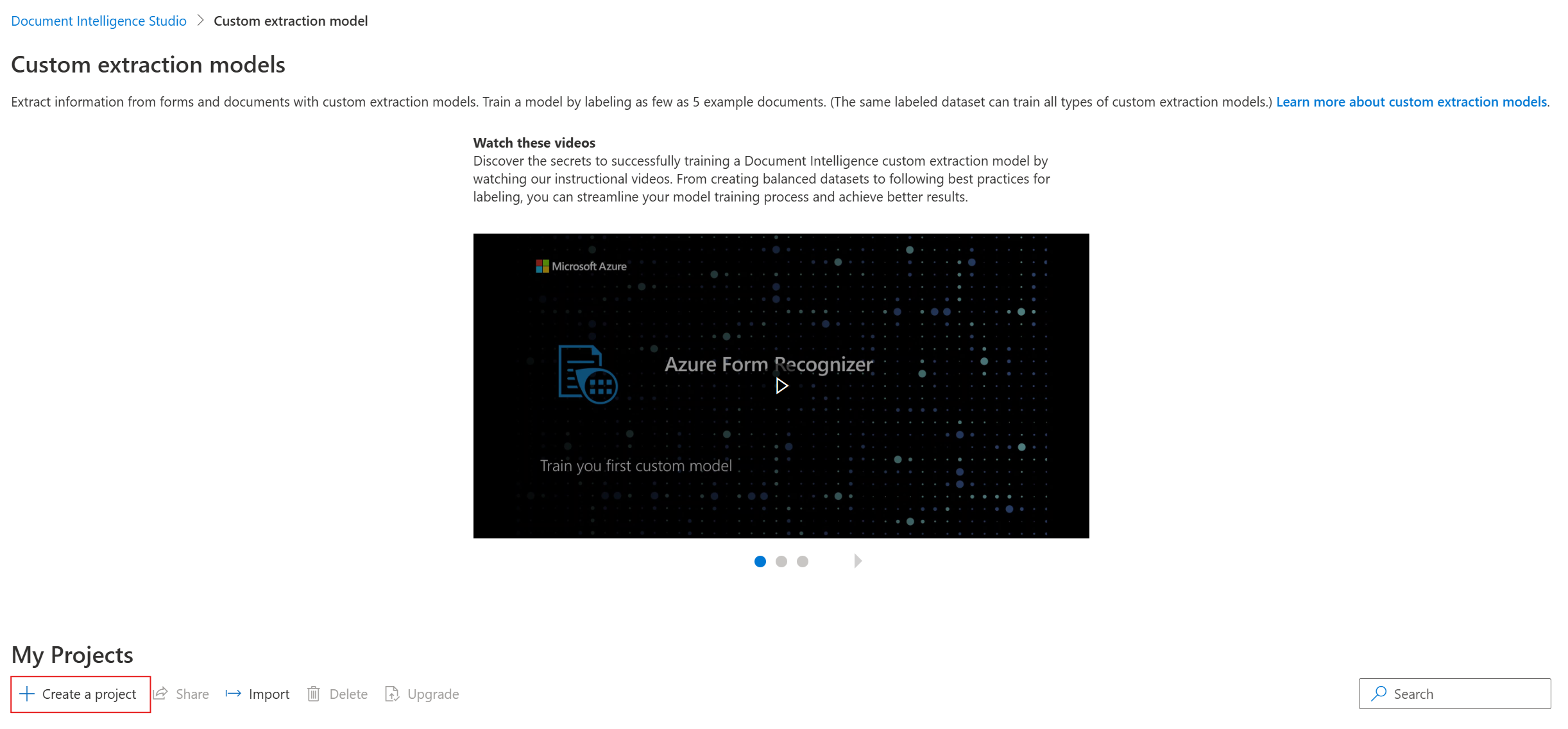
Na caixa de diálogo, forneça um nome para seu
create projectprojeto, opcionalmente uma descrição, e selecione continuar.Na próxima etapa do fluxo de trabalho, escolha ou crie um recurso de Document Intelligence antes de selecionar continuar.
Importante
Os modelos neurais personalizados estão disponíveis apenas em poucas regiões. Se você planeja treinar um modelo neural, selecione ou crie um recurso em uma dessas regiões suportadas.
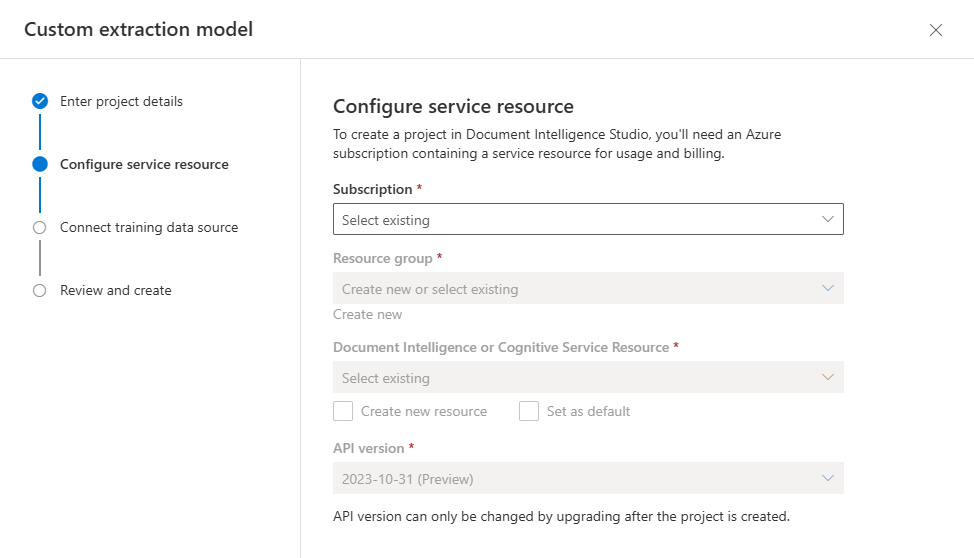
Em seguida, selecione a conta de armazenamento usada para carregar seu conjunto de dados de treinamento de modelo personalizado. O caminho da pasta deve estar vazio se os documentos de treinamento estiverem na raiz do contêiner. Se os documentos estiverem em uma subpasta, insira o caminho relativo da raiz do contêiner no campo Caminho da pasta. Depois que sua conta de armazenamento estiver configurada, selecione continuar.
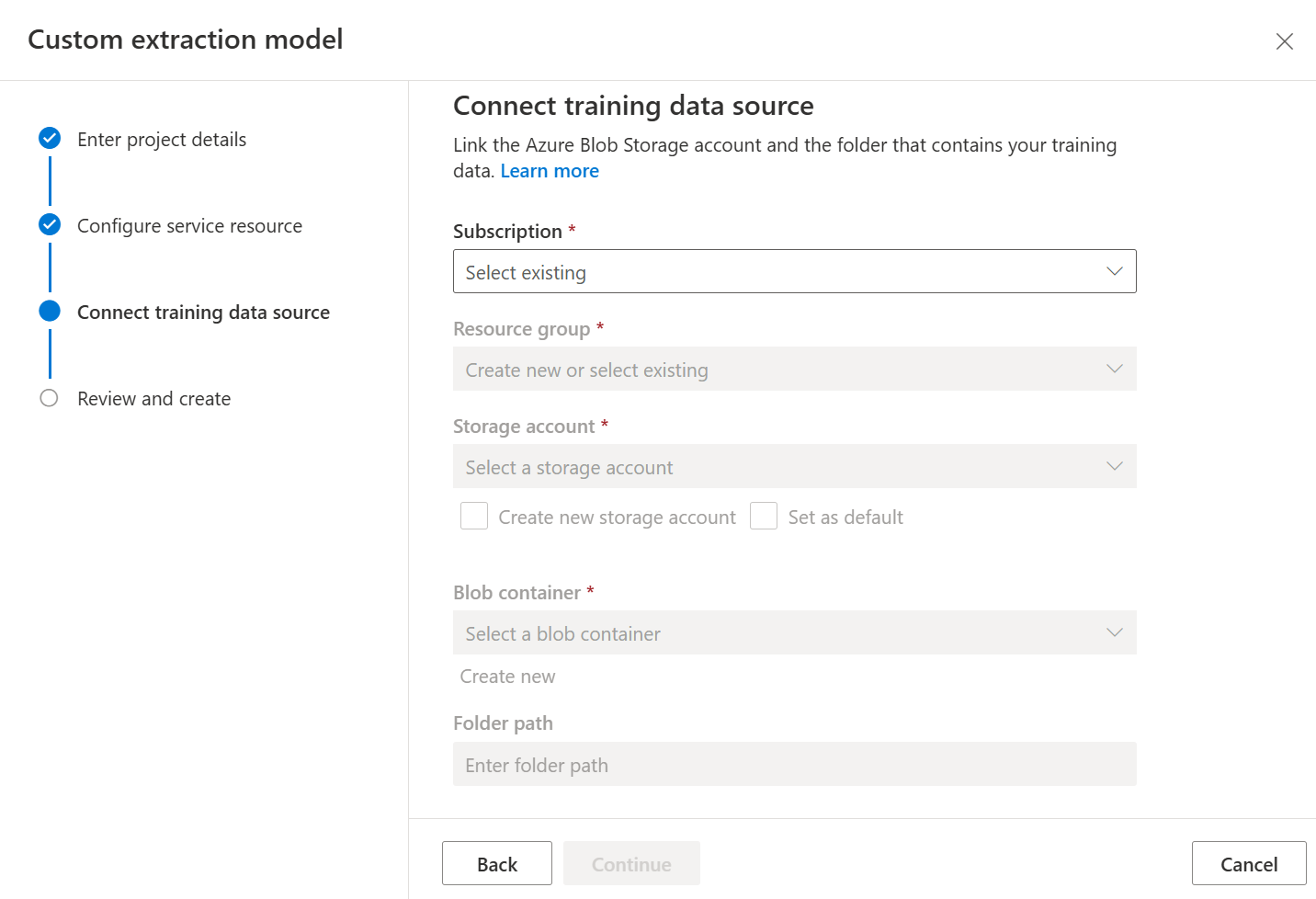
Finalmente, revise as configurações do projeto e selecione Criar projeto para criar um novo projeto. Agora você deve estar na janela de rotulagem e ver os arquivos em seu conjunto de dados listados.
Rotule seus dados
Em seu projeto, sua primeira tarefa é rotular seu conjunto de dados com os campos que você deseja extrair.
Os arquivos que você carregou para o armazenamento são listados à esquerda da tela, com o primeiro arquivo pronto para ser rotulado.
Comece a rotular seu conjunto de dados e criar seu primeiro campo selecionando o botão de adição (➕) no canto superior direito da tela.
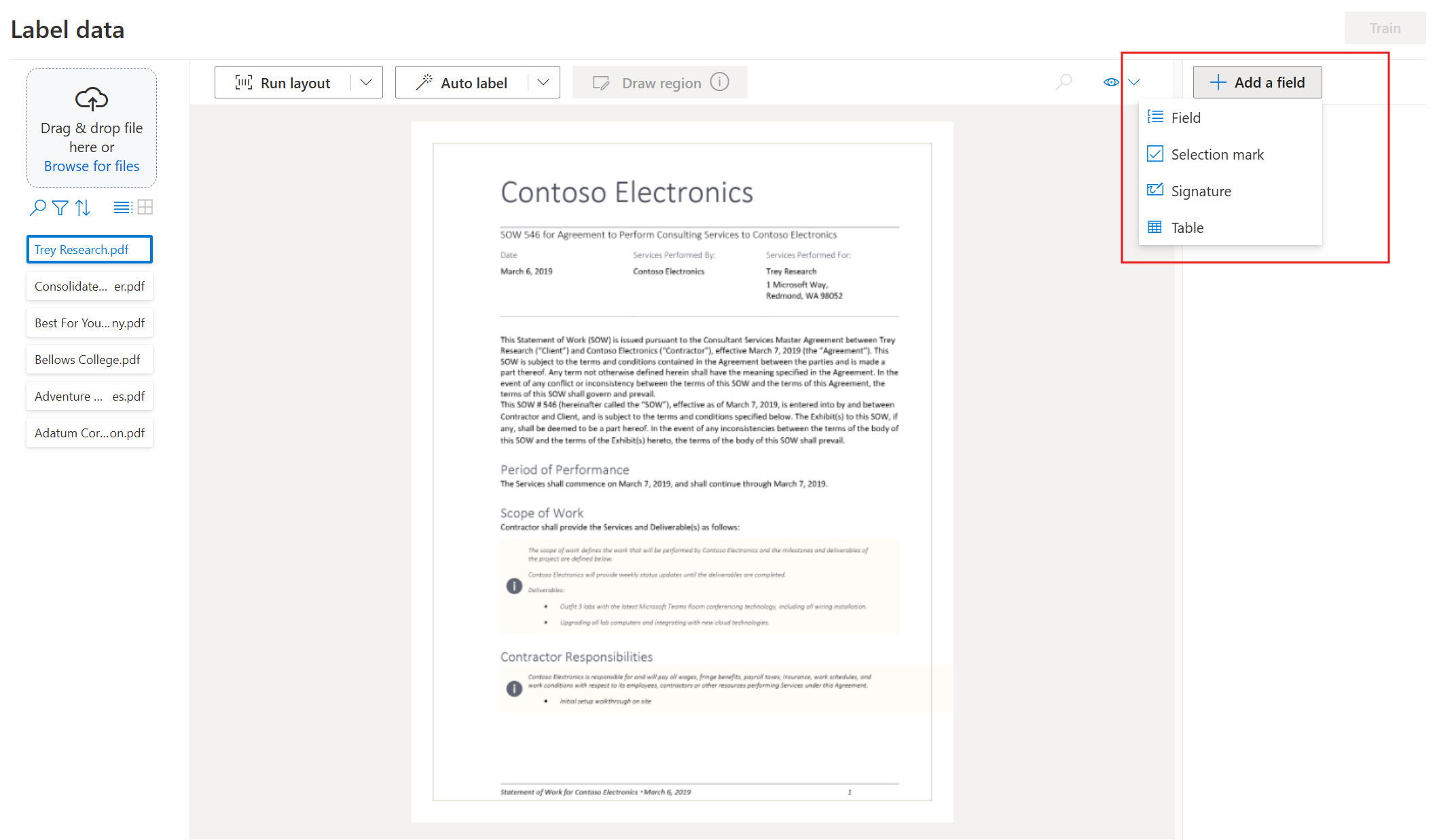
Insira um nome para o campo.
Atribua um valor ao campo escolhendo uma palavra ou palavras no documento. Selecione o campo na lista suspensa ou na lista de campos na barra de navegação direita. O valor rotulado está abaixo do nome do campo na lista de campos.
Repita o processo para todos os campos que você deseja rotular para seu conjunto de dados.
Rotule os documentos restantes em seu conjunto de dados selecionando cada documento e selecionando o texto a ser rotulado.
Agora você tem todos os documentos em seu conjunto de dados rotulados. Os arquivos .labels.json e .ocr.json correspondem a cada documento do conjunto de dados de treinamento e a um novo arquivo de fields.json. Este conjunto de dados de treinamento é enviado para treinar o modelo.
Preparar o modelo
Com seu conjunto de dados rotulado, você está pronto para treinar seu modelo. Selecione o botão de trem no canto superior direito.
Na caixa de diálogo do modelo de trem, forneça um ID de modelo exclusivo e, opcionalmente, uma descrição. O ID do modelo aceita um tipo de dados de cadeia de caracteres.
Para o modo de construção, selecione o tipo de modelo que deseja treinar. Saiba mais sobre os tipos de modelo e os recursos.
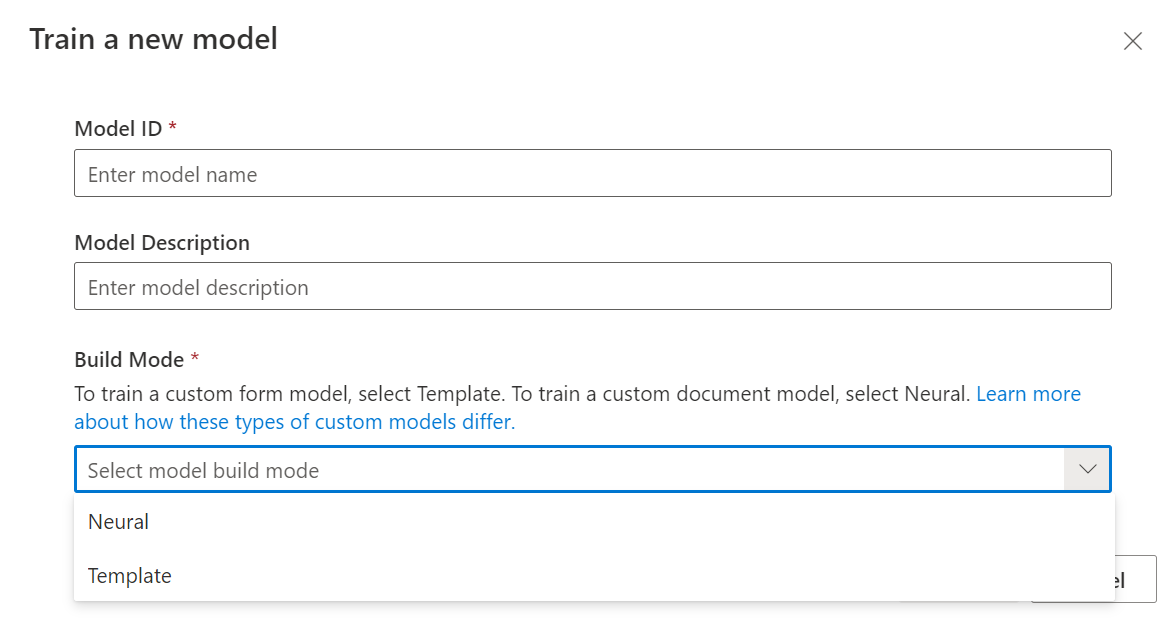
Selecione Treinar para iniciar o processo de treinamento.
Os modelos de modelo treinam em poucos minutos. Os modelos neurais podem levar até 30 minutos para treinar.
Navegue até ao menu Modelos para ver o estado da operação do comboio.
Testar o modelo
Quando o treinamento do modelo estiver concluído, você poderá testá-lo selecionando o modelo na página de listagem de modelos.
Selecione o modelo e selecione no botão Testar .
Selecione o
+ Addbotão para selecionar um arquivo para testar o modelo.Com um arquivo selecionado, escolha o botão Analisar para testar o modelo.
Os resultados do modelo são exibidos na janela principal e os campos extraídos são listados na barra de navegação direita.
Valide seu modelo avaliando os resultados para cada campo.
A barra de navegação direita também tem o código de exemplo para invocar seu modelo e os resultados JSON da API.
Parabéns por ter aprendido a treinar um modelo personalizado no Document Intelligence Studio! Seu modelo está pronto para uso com a API REST ou o SDK para analisar documentos.
Aplica-se a:![]() v2.1.
Outras versões:v3.0
v2.1.
Outras versões:v3.0
Ao usar o modelo personalizado do Document Intelligence, você fornece seus próprios dados de treinamento para a operação Train Custom Model , para que o modelo possa ser treinado para seus formulários específicos do setor. Siga este guia para aprender a coletar e preparar dados para treinar o modelo de forma eficaz.
Necessita de pelo menos cinco formulários preenchidos do mesmo tipo.
Se quiser usar dados de treinamento rotulados manualmente, você deve começar com pelo menos cinco formulários preenchidos do mesmo tipo. Você ainda pode usar formulários sem rótulo, além do conjunto de dados necessário.
Requisitos de entrada do modelo personalizado
Primeiro, certifique-se de que seu conjunto de dados de treinamento siga os requisitos de entrada para Document Intelligence.
Formatos de ficheiro suportados:
| Modelo | Imagem: JPEG/JPG, PNG, BMP, TIFF, , HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lida | ✔ | ✔ | ✔ |
| Esquema | ✔ | ✔ | ✔ |
| Documento Geral | ✔ | ✔ | |
| Pré-criado | ✔ | ✔ | |
| Extração personalizada | ✔ | ✔ | |
| Classificação personalizada | ✔ | ✔ | ✔ |
Para obter melhores resultados, forneça uma foto nítida ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de nível gratuito, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para analisar documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 pixels x 50 pixels e 10.000 pixels x 10.000 pixels.
Se os seus PDFs forem bloqueados por uma palavra-passe, terá de remover o bloqueio antes da submetê-los.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1024 x 768 pixels. Esta dimensão corresponde a cerca
8de texto pontual a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GB com um máximo de 10.000 páginas. Para 2024-11-30 (GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Dicas de dados de treinamento
Siga estas dicas para otimizar ainda mais seu conjunto de dados para treinamento.
- Use documentos PDF baseados em texto em vez de documentos baseados em imagem. Os PDFs digitalizados são processados como imagens.
- Use exemplos que tenham todos os campos preenchidos para formulários preenchidos.
- Utilize formulários com diferentes valores em cada campo.
- Use um conjunto de dados maior (10-15 imagens) para formulários preenchidos.
Carregue seus dados de treinamento
Depois de reunir o conjunto de documentos para treinamento, você precisa carregá-lo em um contêiner de armazenamento de blob do Azure. Se você não souber como criar uma conta de armazenamento do Azure com um contêiner, siga o início rápido do Armazenamento do Azure para o portal do Azure. Use a camada de desempenho padrão.
Se você quiser usar dados rotulados manualmente, carregue os arquivos .labels.json e .ocr.json que correspondem aos seus documentos de treinamento. Você pode usar a ferramenta Sample Labeling (ou sua própria interface do usuário) para gerar esses arquivos.
Organizar seus dados em subpastas (opcional)
Por padrão, a API Train Custom Model usa apenas documentos localizados na raiz do contêiner de armazenamento. No entanto, você pode treinar com dados em subpastas se especificá-los na chamada da API. Normalmente, o corpo da chamada Modelo Personalizado de Trem tem o seguinte formato, onde <SAS URL> é a URL de assinatura de acesso compartilhado do seu contêiner:
{
"source":"<SAS URL>"
}
Se você adicionar o seguinte conteúdo ao corpo da solicitação, a API treinará com documentos localizados em subpastas. O "prefix" campo é opcional e limita o conjunto de dados de treinamento a arquivos cujos caminhos começam com a cadeia de caracteres fornecida. Assim, um valor de "Test", por exemplo, faz com que a API examine apenas os arquivos ou pastas que começam com a palavra Test.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Próximos passos
Agora que você aprendeu como criar um conjunto de dados de treinamento, siga um guia de início rápido para treinar um modelo personalizado de Document Intelligence e começar a usá-lo em seus formulários.