Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Importante
A partir de 20 de setembro de 2023, não poderá criar novos recursos Personalizer. O serviço Personalizer será retirado a 1 de outubro de 2026. Recomendamos migrar para o open-source microsoft/learning-loop.
Este tutorial executa um loop do Personalizer no Azure Notebook, demonstrando o ciclo de vida completo de um loop do Personalizer.
O loop sugere que tipo de café um cliente deve pedir. Os usuários e suas preferências são armazenados em um conjunto de dados do usuário. As informações sobre o café são armazenadas em um conjunto de dados de café.
Utilizadores e café
O notebook, simulando a interação do usuário com um site, seleciona um usuário aleatório, hora do dia e tipo de clima do conjunto de dados. Um resumo das informações do usuário é:
| Clientes - recursos de contexto | Horários do dia | Tipos de clima |
|---|---|---|
| Alice Bob Cathy Dave |
Manhã Tarde Noite |
Ensolarado Chuvoso Nevado |
Para ajudar o Personalizador a aprender, ao longo do tempo, o sistema também sabe detalhes sobre a seleção de café para cada pessoa.
| Café - funcionalidades de ação | Tipos de temperatura | Locais de origem | Tipos de assado | Orgânico |
|---|---|---|---|---|
| Cappacino | Quente | Quénia | Escuro | Orgânico |
| Cerveja gelada | Frio | Brasil | Luz | Orgânico |
| Mocha gelado | Frio | Etiópia | Luz | Não orgânico |
| Latte | Quente | Brasil | Escuro | Não orgânico |
O objetivo do ciclo do Personalizador é encontrar a melhor correspondência entre os utilizadores e o café pelo maior tempo possível.
O código deste tutorial está disponível no repositório GitHub Personalizer Samples.
Como funciona a simulação
No início do sistema em execução, as sugestões do Personalizer só são bem-sucedidas entre 20% a 30%. Este sucesso é indicado pela recompensa enviada de volta para a Personalizer Reward API, dando uma pontuação de 1. Depois de algumas chamadas de *Rank* e *Reward*, o sistema melhora.
Após as solicitações iniciais, execute uma avaliação offline. Isso permite que o Personalizer analise os dados e sugira uma política de aprendizagem melhor. Aplique a nova política de aprendizagem e execute o bloco de anotações novamente com 20% da contagem de solicitações anteriores. O ciclo terá um melhor desempenho com a nova política de aprendizagem.
Classificação e recompensa das chamadas
Para cada uma das poucas milhares de chamadas para o serviço Personalizer, o Azure Notebook envia o pedido Rank para a API REST:
- Um ID exclusivo para o evento Rank/Request
- Recursos de contexto - Uma escolha aleatória do usuário, clima e hora do dia - simulando um usuário em um site ou dispositivo móvel
- Ações com Recursos - Todos os dados do café - a partir dos quais o Personalizador faz uma sugestão
O sistema recebe a solicitação e, em seguida, compara essa previsão com a escolha conhecida do usuário para a mesma hora do dia e clima. Se a escolha conhecida for a mesma que a escolha prevista, uma Recompensa de 1 é enviada de volta para o Personalizador. Caso contrário, a recompensa enviada de volta é 0.
Nota
Esta é uma simulação para que o algoritmo para a recompensa seja simples. Em um cenário do mundo real, o algoritmo deve usar a lógica de negócios, possivelmente com pesos para vários aspetos da experiência do cliente, para determinar a pontuação de recompensa.
Pré-requisitos
- Uma conta Azure Notebook.
- Um recurso Personalizador de IA do Azure.
- Se já usaste o recurso Personalizer, certifica-te de limpar os dados no portal Azure do recurso.
- Carrega todos os ficheiros para este exemplo para um projeto Azure Notebook.
Descrições dos ficheiros:
- Personalizer.ipynb é o caderno Jupyter para este tutorial.
- User dataset é armazenado num objeto JSON.
- Conjunto de dados Coffee é armazenado num objeto JSON.
- Example Request JSON é o formato esperado para um pedido POST à API Rank.
Configurar recurso do Personalizer
No portal Azure, configure o seu recurso Personalizer com a frequência do modelo update definida para 15 segundos e um tempo de espera recompensa de 10 minutos. Esses valores são encontrados na página Configuração.
| Configuração | Valor |
|---|---|
| atualizar a frequência do modelo | 15 segundos |
| tempo de espera de recompensa | 10 minutos |
Esses valores têm uma duração muito curta para mostrar as alterações neste tutorial. Esses valores não devem ser usados num cenário de produção sem validar que alcançam o seu objetivo com o seu loop do Personalizador.
Configurar o Azure Notebook
- Muda o kernel para
Python 3.6. - Abra o ficheiro
Personalizer.ipynb.
Executar células do Bloco de Anotações
Execute cada célula executável e aguarde até que ela retorne. Você sabe que está feito quando os colchetes ao lado da célula exibem um número em vez de um *. As seções a seguir explicam o que cada célula faz programaticamente e o que esperar para a saída.
Incluir os módulos de Python
Inclua os módulos de Python obrigatórios. A célula não tem saída.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Definir a chave de recurso e o nome do Personalizador
No portal Azure, encontre a sua chave e endpoint na página Quickstart do seu recurso Personalizer. Altere o valor de <your-resource-name> para o nome do seu recurso do Personalizador. Altere o valor de <your-resource-key> para a sua chave Personalizador.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Imprimir data e hora atuais
Use esta função para anotar as horas de início e término da função iterativa, iterações.
Estas células não têm saída. A função produz a data e hora atuais quando chamada.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Obter a hora da última atualização do modelo
Quando a função, get_last_updated, é chamada, a função imprime a data e a hora da última modificação em que o modelo foi atualizado.
Estas células não têm saída. A função produz a última data de treinamento do modelo quando chamada.
A função usa uma API GET REST para obter propriedades do modelo.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Obter configuração de política e serviço
Valide o estado do serviço com essas duas chamadas REST.
Estas células não têm saída. A função produz os valores de serviço quando chamada.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Construa URLs e leia arquivos de dados JSON
Esta célula
- cria as URLs usadas em chamadas REST
- define o cabeçalho de segurança usando sua chave de recurso do Personalizer
- define a semente aleatória para o ID do evento Rank
- leituras nos arquivos de dados JSON
- Chama o método
get_last_updated- A política de aprendizagem foi removida na saída do exemplo - Chama o método
get_service_settings
A célula tem saída das chamadas das funções get_last_updated e get_service_settings.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Verifique se a rewardWaitTime da saída está configurada para 10 minutos e se a modelExportFrequency está configurada para 15 segundos.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Solução de problemas da primeira chamada REST
Esta célula anterior é a primeira célula que chama o Personalizador. Verifique se o código de status REST na saída é <Response [200]>. Se você receber um erro, como 404, mas tiver certeza de que a chave de recurso e o nome estão corretos, recarregue o bloco de anotações.
Certifique-se de que a contagem de café e usuários sejam ambos 4. Se você receber um erro, verifique se você carregou todos os 3 arquivos JSON.
Configurar tabela métrica no portal do Azure
Mais adiante neste tutorial, o longo processo de execução de 10.000 solicitações é visível a partir do navegador com uma caixa de texto de atualização. Pode ser mais fácil de ver em um gráfico ou como uma soma total, quando o processo de longa duração termina. Para exibir essas informações, use as métricas fornecidas com o recurso. Você pode criar o gráfico agora que concluiu uma solicitação para o serviço e, em seguida, atualizá-lo periodicamente enquanto o processo de longa duração está em andamento.
No portal Azure, selecione o seu recurso Personalizer.
Na navegação de recursos, selecione Métricas abaixo de Monitoramento.
No gráfico, selecione Adicionar métrica.
O namespace de recurso e métrica já está definido. Você só precisa selecionar a métrica de chamadas bem-sucedidas e a agregação de soma.
Altere o filtro de tempo para as últimas 4 horas.
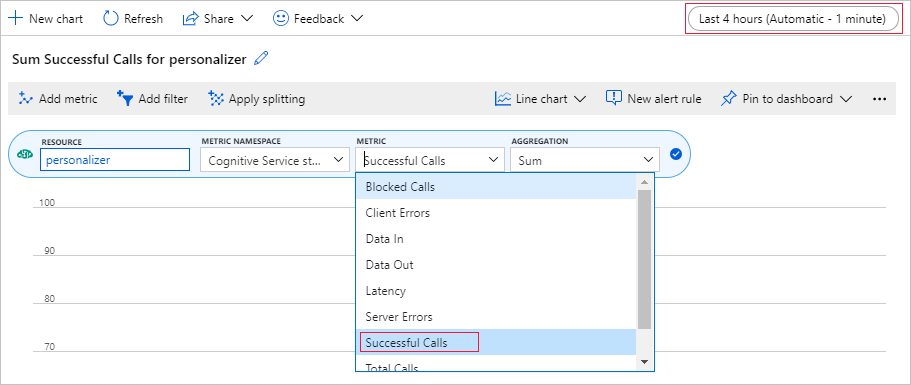
Você verá três chamadas bem-sucedidas no gráfico.
Gerar um ID de evento exclusivo
Esta função gera um ID exclusivo para cada chamada de classificação. O ID é usado para identificar as informações de classificação e chamada de recompensa. Esse valor pode vir de um processo comercial, como um ID de visualização da Web ou um ID de transação.
A célula não tem saída. A função de facto emite o ID exclusivo quando chamada.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Obter usuário aleatório, clima e hora do dia
Essa função seleciona um usuário exclusivo, clima e hora do dia e, em seguida, adiciona esses itens ao objeto JSON para enviar à solicitação Rank.
A célula não tem saída. Quando a função é chamada, ela retorna o nome do usuário aleatório, clima aleatório e hora aleatória do dia.
A lista de 4 usuários e suas preferências - apenas algumas preferências são mostradas para brevidade:
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Adicionar todos os dados do café
Esta função adiciona toda a lista de café ao objeto JSON para enviar à solicitação Rank.
A célula não tem saída. A função muda o rankjsonobj quando chamado.
O exemplo das características de um único café é:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Compare a previsão com a preferência conhecida do usuário
Esta função é chamada depois que a API Rank é chamada, para cada iteração.
Esta função compara a preferência do utilizador por café, com base no tempo e hora do dia, com a sugestão do Personalizador para o utilizador para esses filtros. Se a sugestão corresponder, uma pontuação de 1 é retornada, caso contrário, a pontuação é 0. A célula não tem saída. A função produz a pontuação quando chamada.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Percorrer/Iterar sobre chamadas para Classificação e Recompensa
A próxima célula é o trabalho principal do Caderno, obtendo um usuário aleatório, obtendo a lista de café, enviando ambos para a API Rank. Comparando a previsão com as preferências conhecidas do usuário e, em seguida, enviando a recompensa de volta para o serviço Personalizador.
O loop é executado por num_requests vezes. O Personalizer precisa de alguns milhares de chamadas para Rank and Reward para criar um modelo.
Segue-se um exemplo do JSON enviado para a API Rank. A lista de café não está completa, por uma questão de brevidade. Você pode ver o JSON completo de café em coffee.json.
JSON enviado para a API de classificação:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Resposta JSON da API de classificação:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Finalmente, cada loop mostra a seleção aleatória do usuário, clima, hora do dia e recompensa determinada. A recompensa de 1 indica que o recurso Personalizador selecionou o tipo de café correto para determinado usuário, clima e hora do dia.
1 Alice Rainy Morning Latte 1
A função usa:
- Rank: uma API POST REST para obter classificação.
- Recompensa: uma API POST REST para relatar recompensa.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Executar 10.000 iterações
Execute o loop do Personalizer para 10.000 iterações. Este é um evento de longa duração. Não feche o navegador que está a executar o notebook. Atualize periodicamente o gráfico de métricas no portal do Azure para ver o total de chamadas para o serviço. Quando se tem cerca de 20.000 chamadas, uma chamada de rank e recompensa para cada iteração do ciclo, as iterações estão concluídas.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Criar gráficos dos resultados para ver melhorias
Crie um gráfico a partir de count e rewards.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Executar gráfico para 10.000 solicitações de classificação
Execute a createChart função.
createChart(count,rewards)
Ler o gráfico
Este gráfico mostra o sucesso do modelo para a política de aprendizagem padrão atual.
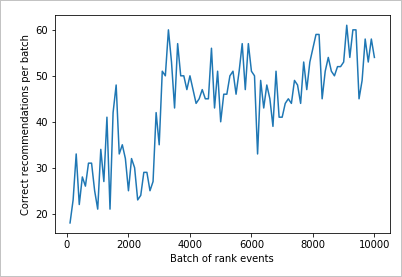
O alvo ideal é que, no final do teste, o loop esteja com uma média de taxa de sucesso próxima de 100% menos a exploração. O valor padrão de exploração é 20%.
100-20=80
Este valor de exploração encontra-se no portal Azure, para o recurso Personalizer, na página Configuration.
Para encontrar uma melhor política de aprendizagem, com base nos seus dados para a API de classificação, execute uma avaliação offline no portal para o seu loop do Personalizador.
Executar uma avaliação offline
No portal Azure, abra a página Avaliações do recurso Personalizer.
Selecione Criar avaliação.
Insira os dados necessários de nome da avaliação e intervalo de datas para a avaliação do loop. O intervalo de datas deve incluir apenas os dias em que você está se concentrando para sua avaliação.
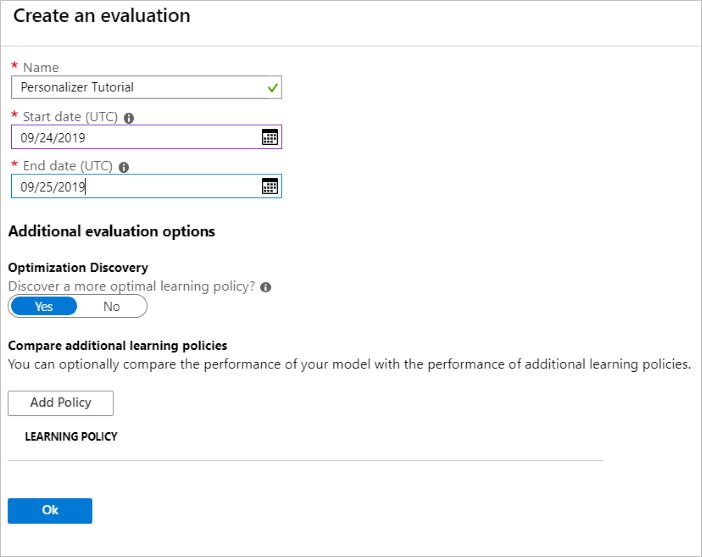
O objetivo de executar essa avaliação offline é determinar se há uma melhor política de aprendizagem para os recursos e ações usados nesse ciclo. Para encontrar essa melhor política de aprendizagem, certifique-se de que a Descoberta de otimização esteja ativada.
Selecione OK para iniciar a avaliação.
Esta página Avaliações lista a nova avaliação e o seu estado atual. Dependendo da quantidade de dados que você tem, essa avaliação pode levar algum tempo. Você pode voltar a esta página depois de alguns minutos para ver os resultados.
Quando a avaliação estiver concluída, selecione a avaliação e, em seguida, selecione Comparação de diferentes políticas de aprendizagem. Isso mostra as políticas de aprendizagem disponíveis e como elas se comportariam com os dados.
Selecione a política de aprendizagem mais importante na tabela e selecione Aplicar. Isso aplica a melhor política de aprendizagem ao seu modelo e re-treina.
Altere a frequência do modelo de atualização para 5 minutos
- No portal Azure, ainda no recurso Personalizer, selecione a página Configuration.
- Altere a frequência de atualização do modelo e o tempo de espera de recompensa para 5 minutos e selecione Salvar.
Saiba mais sobre o tempo de espera de recompensa e a frequência de atualização do modelo.
#Verify new learning policy and times
get_service_settings()
Verifique se tanto rewardWaitTime como modelExportFrequency da saída estão definidos para 5 minutos.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Validar nova política de aprendizagem
Volte ao ficheiro Azure Notebooks e continue executando o mesmo ciclo, mas apenas por 2.000 iterações. Atualize periodicamente o gráfico de métricas no portal do Azure para ver o total de chamadas para o serviço. Quando há cerca de 4.000 chamadas, uma chamada de classificação e recompensa para cada iteração do ciclo, as iterações são concluídas.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
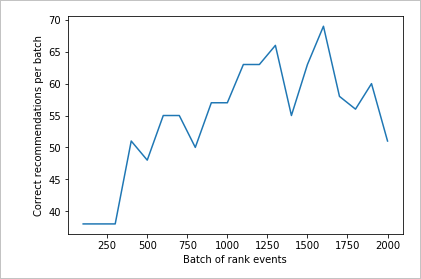
Executar gráfico para 2.000 solicitações de classificação
Execute a createChart função.
createChart(count2,rewards2)
Rever o segundo gráfico
O segundo gráfico deve mostrar um aumento visível nas previsões de classificação alinhadas com as preferências do usuário.
Limpar recursos
Se você não pretende continuar a série de tutoriais, limpe os seguintes recursos:
- Apaga o teu projeto do Azure Notebook.
- Exclua seu recurso do Personalizador.
Próximos passos
O caderno Jupyter e os ficheiros de dados usados neste exemplo estão disponíveis no repositório GitHub do Personalizer.