Testar a qualidade de reconhecimento de um modelo de fala personalizado
Você pode inspecionar a qualidade de reconhecimento de um modelo de fala personalizado no Speech Studio. Você pode reproduzir o áudio carregado e determinar se o resultado de reconhecimento fornecido está correto. Depois que um teste é criado com êxito, você pode ver como um modelo transcreveu o conjunto de dados de áudio ou comparar os resultados de dois modelos lado a lado.
O teste de modelo lado a lado é útil para validar qual modelo de reconhecimento de fala é melhor para um aplicativo. Para obter uma medida objetiva de precisão, que requer a entrada de conjuntos de dados de transcrição, consulte Modelo de teste quantitativamente.
Importante
Durante o teste, o sistema realizará uma transcrição. Isso é importante ter em mente, pois os preços variam de acordo com a oferta de serviço e o nível de assinatura. Consulte sempre os preços oficiais dos serviços de IA do Azure para obter os detalhes mais recentes.
Criar um teste
Siga estas instruções para criar um teste:
Inicie sessão no Speech Studio.
Navegue até Speech Studio>Custom speech e selecione o nome do seu projeto na lista.
Selecione Modelos>de teste Criar novo teste.
Selecione Inspecionar qualidade (dados somente áudio)>Avançar.
Escolha um conjunto de dados de áudio que você gostaria de usar para teste e selecione Avançar. Se não houver conjuntos de dados disponíveis, cancele a configuração e vá para o menu Conjuntos de dados de fala para carregar conjuntos de dados.
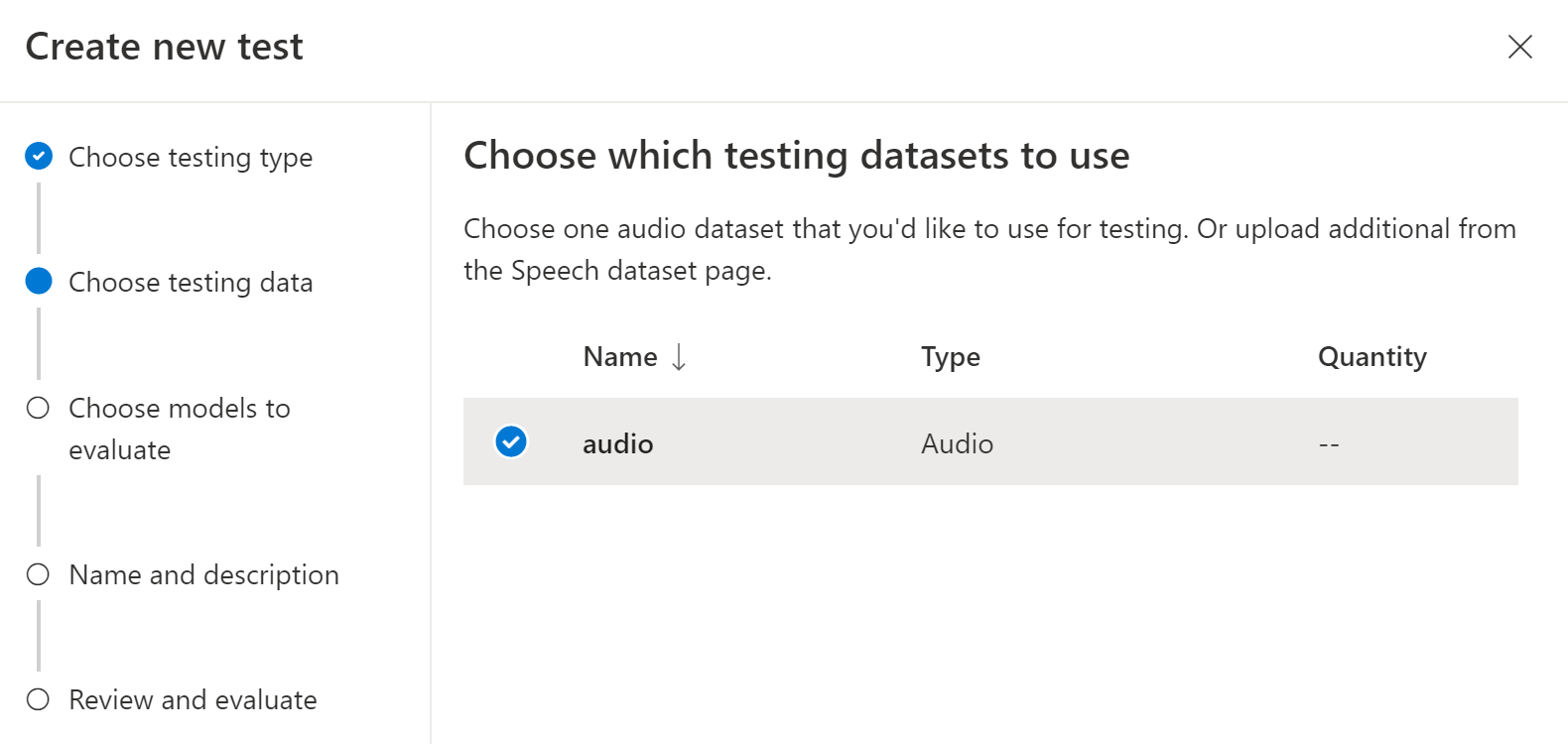
Escolha um ou dois modelos para avaliar e comparar a precisão.
Introduza o nome e a descrição do teste e, em seguida, selecione Seguinte.
Reveja as definições e, em seguida, selecione Guardar e fechar.
Para criar um teste, use o spx csr evaluation create comando. Construa os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina o
projectparâmetro como a ID de um projeto existente. Esse parâmetro é recomendado para que você também possa visualizar o teste no Speech Studio. Você pode executar ospx csr project listcomando para obter projetos disponíveis. - Defina o parâmetro necessário
model1para a ID de um modelo que você deseja testar. - Defina o parâmetro necessário
model2para a ID de outro modelo que você deseja testar. Se você não quiser comparar dois modelos, use o mesmo modelo para ambosmodel1emodel2. - Defina o parâmetro necessário
datasetpara a ID de um conjunto de dados que você deseja usar para o teste. - Defina o
languageparâmetro, caso contrário, a CLI de fala define "en-US" por padrão. Esse parâmetro deve ser a localidade do conteúdo do conjunto de dados. A localidade não pode ser alterada posteriormente. O parâmetro Speech CLIlanguagecorresponde àlocalepropriedade na solicitação e resposta JSON. - Defina o parâmetro necessário
name. Este parâmetro é o nome exibido no Speech Studio. O parâmetro Speech CLInamecorresponde àdisplayNamepropriedade na solicitação e resposta JSON.
Aqui está um exemplo de comando da CLI de fala que cria um teste:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
Deverá receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
A propriedade de nível self superior no corpo da resposta é o URI da avaliação. Use este URI para obter detalhes sobre o projeto e os resultados do teste. Você também usa esse URI para atualizar ou excluir a avaliação.
Para obter ajuda da CLI de fala com avaliações, execute o seguinte comando:
spx help csr evaluation
Para criar um teste, use a operação Evaluations_Create da API REST de fala para texto. Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a
projectpropriedade como o URI de um projeto existente. Essa propriedade é recomendada para que você também possa exibir o teste no Speech Studio. Você pode fazer uma solicitação de Projects_List para obter projetos disponíveis. - Defina a propriedade required
model1como o URI de um modelo que você deseja testar. - Defina a propriedade required
model2para o URI de outro modelo que você deseja testar. Se você não quiser comparar dois modelos, use o mesmo modelo para ambosmodel1emodel2. - Defina a propriedade required
datasetpara o URI de um conjunto de dados que você deseja usar para o teste. - Defina a propriedade necessária
locale. Essa propriedade deve ser a localidade do conteúdo do conjunto de dados. A localidade não pode ser alterada posteriormente. - Defina a propriedade necessária
displayName. Esta propriedade é o nome exibido no Speech Studio.
Faça uma solicitação HTTP POST usando o URI, conforme mostrado no exemplo a seguir. Substitua YourSubscriptionKey pela chave de recurso Fala, substitua YourServiceRegion pela região de recurso Fala e defina as propriedades do corpo da solicitação conforme descrito anteriormente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Deverá receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
A propriedade de nível self superior no corpo da resposta é o URI da avaliação. Use este URI para obter detalhes sobre o projeto da avaliação e os resultados do teste. Você também usa esse URI para atualizar ou excluir a avaliação.
Obter resultados de testes
Você deve obter os resultados do teste e inspecionar os conjuntos de dados de áudio em comparação com os resultados da transcrição para cada modelo.
Siga estas etapas para obter os resultados do teste:
- Inicie sessão no Speech Studio.
- Selecione Fala> personalizada Seu nome >de projeto Modelos de teste.
- Selecione o link por nome de teste.
- Após a conclusão do teste, conforme indicado pelo status definido como Bem-sucedido, você verá os resultados que incluem o número WER para cada modelo testado.
Esta página lista todos os enunciados em seu conjunto de dados e os resultados de reconhecimento, juntamente com a transcrição do conjunto de dados enviado. Você pode alternar vários tipos de erro, incluindo inserção, exclusão e substituição. Ao ouvir o áudio e comparar os resultados de reconhecimento em cada coluna, você pode decidir qual modelo atende às suas necessidades e determinar onde mais treinamento e melhorias são necessários.
Para obter os resultados do teste, use o spx csr evaluation status comando. Construa os parâmetros de solicitação de acordo com as seguintes instruções:
- Defina o parâmetro necessário
evaluationpara o ID da avaliação que você deseja obter os resultados do teste.
Aqui está um exemplo de comando da CLI de fala que obtém resultados de teste:
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
Os modelos, o conjunto de dados de áudio, as transcrições e mais detalhes são retornados no corpo da resposta.
Deverá receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Para obter ajuda da CLI de fala com avaliações, execute o seguinte comando:
spx help csr evaluation
Para obter resultados de teste, comece usando a operação Evaluations_Get da API REST de fala para texto.
Faça uma solicitação HTTP GET usando o URI, conforme mostrado no exemplo a seguir. Substitua YourEvaluationId pelo ID de avaliação, substitua YourSubscriptionKey pela chave de recurso Fala e substitua YourServiceRegion pela região do recurso Fala.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
Os modelos, o conjunto de dados de áudio, as transcrições e mais detalhes são retornados no corpo da resposta.
Deverá receber um corpo de resposta no seguinte formato:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Compare a transcrição com o áudio
Você pode inspecionar a saída de transcrição por cada modelo testado, em relação ao conjunto de dados de entrada de áudio. Se incluiu dois modelos no teste, pode comparar a sua qualidade de transcrição lado a lado.
Para rever a qualidade das transcrições:
- Inicie sessão no Speech Studio.
- Selecione Fala> personalizada Seu nome >de projeto Modelos de teste.
- Selecione o link por nome de teste.
- Reproduza um arquivo de áudio enquanto lê a transcrição correspondente por um modelo.
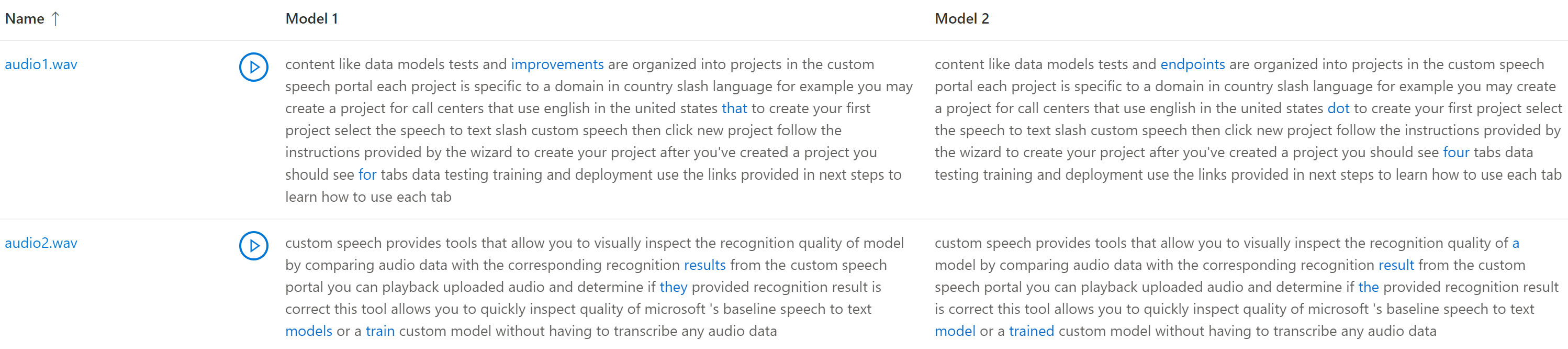
Se o conjunto de dados de teste incluísse vários arquivos de áudio, você verá várias linhas na tabela. Se você incluiu dois modelos no teste, as transcrições são mostradas em colunas lado a lado. As diferenças de transcrição entre modelos são mostradas em fonte de texto azul.
O conjunto de dados de teste de áudio, transcrições e modelos testados são retornados nos resultados do teste. Se apenas um modelo foi testado, o valor corresponde a model1 model2, e o transcription1 valor corresponde .transcription2
Para rever a qualidade das transcrições:
- Faça o download do conjunto de dados de teste de áudio, a menos que você já tenha uma cópia.
- Faça o download das transcrições de saída.
- Reproduza um arquivo de áudio enquanto lê a transcrição correspondente por um modelo.
Se estiver a comparar a qualidade entre dois modelos, preste especial atenção às diferenças entre as transcrições de cada modelo.
O conjunto de dados de teste de áudio, transcrições e modelos testados são retornados nos resultados do teste. Se apenas um modelo foi testado, o valor corresponde a model1 model2, e o transcription1 valor corresponde .transcription2
Para rever a qualidade das transcrições:
- Faça o download do conjunto de dados de teste de áudio, a menos que você já tenha uma cópia.
- Faça o download das transcrições de saída.
- Reproduza um arquivo de áudio enquanto lê a transcrição correspondente por um modelo.
Se estiver a comparar a qualidade entre dois modelos, preste especial atenção às diferenças entre as transcrições de cada modelo.