Adicionar um conjunto de dados de treinamento de voz profissional
Quando você estiver pronto para criar um texto personalizado para voz de fala para seu aplicativo, a primeira etapa é reunir gravações de áudio e scripts associados para começar a treinar o modelo de voz. Para obter detalhes sobre a gravação de amostras de voz, consulte o tutorial. O serviço de Fala usa esses dados para criar uma voz exclusiva sintonizada para corresponder à voz nas gravações. Depois de treinar a voz, você pode começar a sintetizar a fala em seus aplicativos.
Todos os dados carregados devem atender aos requisitos para o tipo de dados escolhido. É importante formatar corretamente os dados antes de serem carregados, o que garante que os dados serão processados com precisão pelo serviço de Fala. Para confirmar se os dados estão formatados corretamente, consulte Tipos de dados de treinamento.
Nota
- Os usuários de assinatura padrão (S0) podem carregar cinco arquivos de dados simultaneamente. Se você atingir o limite, aguarde até que pelo menos um dos seus arquivos de dados termine a importação. Em seguida, tente novamente.
- O número máximo de arquivos de dados que podem ser importados por assinatura é de 500 arquivos .zip para usuários de assinatura padrão (S0). Consulte Cotas e limites do serviço de fala para obter mais detalhes.
Carregue os seus dados
Quando estiver pronto para carregar seus dados, vá para a guia Preparar dados de treinamento para adicionar seu primeiro conjunto de treinamento e carregar dados . Um conjunto de treinamento é um conjunto de expressões de áudio e seus scripts de mapeamento usados para treinar um modelo de voz. Você pode usar um conjunto de treinamento para organizar seus dados de treinamento. O serviço verifica a prontidão dos dados por cada conjunto de treinamento. Você pode importar vários dados para um conjunto de treinamento.
Para carregar dados de treinamento, siga estas etapas:
- Inicie sessão no Speech Studio.
- Selecione Voz personalizada O nome> do seu projeto Preparar dados de formação Carregar dados>.>
- No assistente Carregar dados, escolha um tipo de dados e, em seguida, selecione Avançar.
- Selecione arquivos locais do seu computador ou insira a URL de armazenamento de Blob do Azure para carregar dados.
- Em Especificar o conjunto de treinamento de destino, selecione um conjunto de treinamento existente ou crie um novo. Se você criou um novo conjunto de treinamento, verifique se ele está selecionado na lista suspensa antes de continuar.
- Selecione Seguinte.
- Introduza um nome e uma descrição para os seus dados e, em seguida, selecione Seguinte.
- Reveja os detalhes do carregamento e selecione Submeter.
Nota
Não são aceites IDs duplicados. Os enunciados com o mesmo ID serão removidos.
Nomes de áudio duplicados são removidos do treinamento. Verifique se os dados selecionados não contêm os mesmos nomes de áudio no arquivo .zip ou em vários arquivos .zip. Se os IDs de enunciado (em arquivos de áudio ou script) forem duplicados, eles serão rejeitados.
Os arquivos de dados são validados automaticamente quando você seleciona Enviar. A validação de dados inclui uma série de verificações nos arquivos de áudio para verificar seu formato, tamanho e taxa de amostragem. Se houver erros, corrija-os e envie novamente.
Depois de carregar os dados, você pode verificar os detalhes na visualização de detalhes do conjunto de treinamento. Na página de detalhes, você pode verificar ainda mais o problema de pronúncia e o nível de ruído para cada um dos seus dados. A pontuação de pronúncia no nível da frase varia de 0 a 100. Uma pontuação abaixo de 70 normalmente indica um erro de fala ou incompatibilidade de script. Os enunciados com uma pontuação global inferior a 70 serão rejeitados. Um sotaque pesado pode reduzir sua pontuação de pronúncia e afetar a voz digital gerada.
Resolver problemas de dados online
Após o upload, você pode verificar os detalhes de dados do conjunto de treinamento. Antes de continuar a treinar seu modelo de voz, você deve tentar resolver quaisquer problemas de dados.
Você pode identificar e resolver problemas de dados por enunciado no Speech Studio.
Na página de detalhes, vá para a página Dados aceitos ou Dados rejeitados. Selecione os enunciados individuais que deseja alterar e, em seguida, selecione Editar.
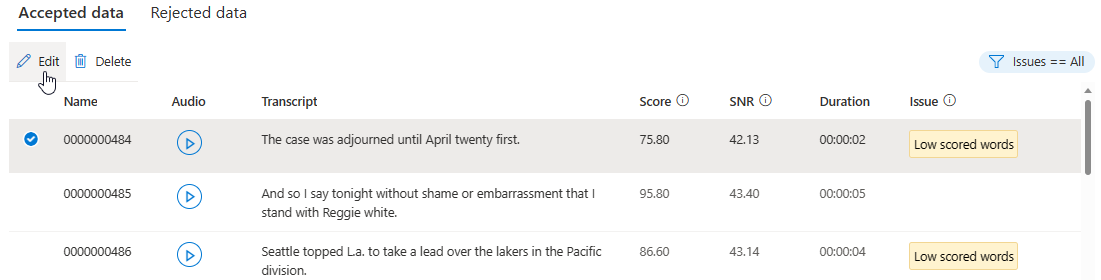
Você pode escolher quais problemas de dados serão exibidos com base em seus critérios.
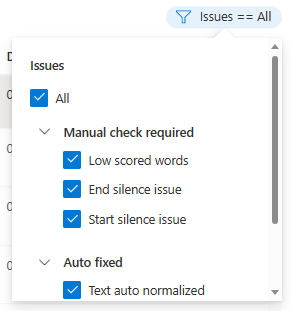
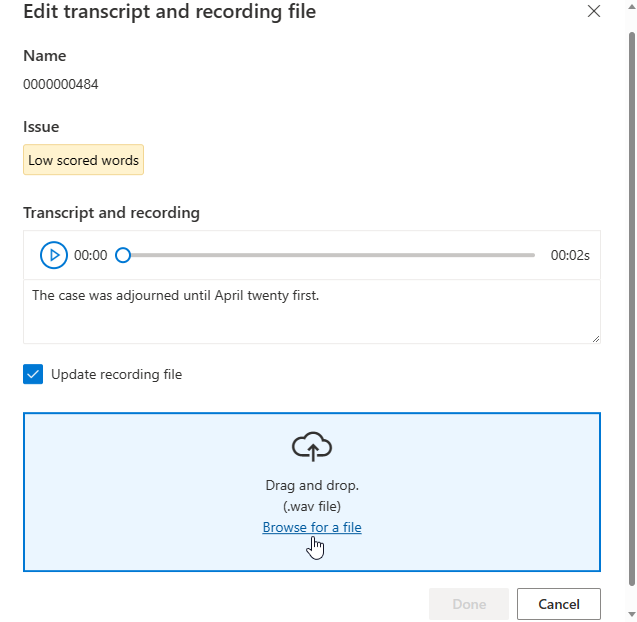
A janela Editar será exibida.
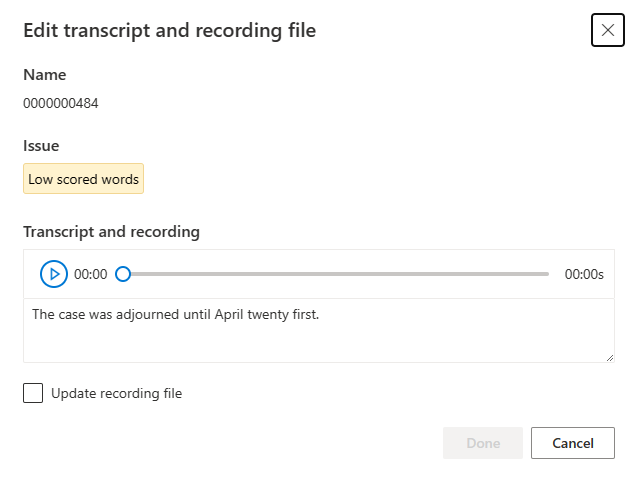
Atualize a transcrição ou o arquivo de gravação de acordo com a descrição do problema na janela de edição.
Pode editar a transcrição na caixa de texto e, em seguida, selecionar Concluído
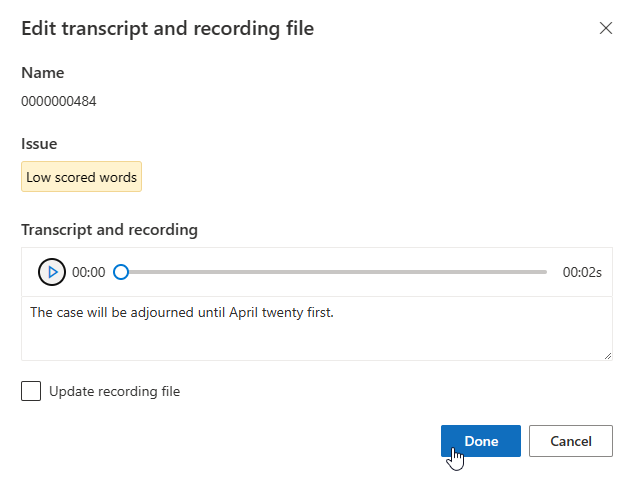
Se você precisar atualizar o arquivo de gravação, selecione Atualizar arquivo de gravação e, em seguida, carregue o arquivo de gravação fixo (.wav).
Depois de fazer alterações nos dados, você precisa verificar a qualidade dos dados clicando em Analisar dados antes de usar esse conjunto de dados para treinamento.
Não é possível selecionar este conjunto de treinamento para o modelo de treinamento antes que a análise seja concluída.
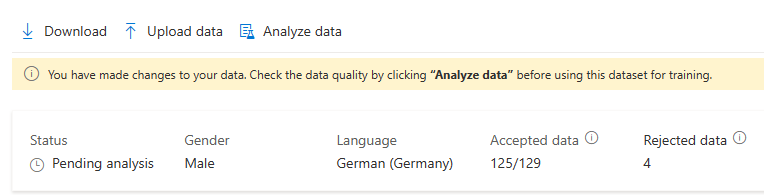
Você também pode excluir expressões com problemas selecionando-as e clicando em Excluir.
Problemas típicos de dados
As questões dividem-se em três tipos. Consulte as tabelas a seguir para verificar os respetivos tipos de erros.
Rejeitado automaticamente
Os dados com esses erros não serão usados para treinamento. Os dados importados com erros serão ignorados, pelo que não é necessário eliminá-los. Você pode corrigir esses erros de dados on-line ou carregar os dados corrigidos novamente para treinamento.
| Category | Nome | Descrição |
|---|---|---|
| Script | Separador inválido | Você deve separar o ID do enunciado e o conteúdo do script com um caractere Tab. |
| Script | ID de script inválido | O ID da linha de script deve ser numérico. |
| Script | Script duplicado | Cada linha do conteúdo do script deve ser exclusiva. A linha é duplicada com {}. |
| Script | Script muito longo | O script deve ter menos de 1.000 caracteres. |
| Script | Sem áudio correspondente | O ID de cada enunciado (cada linha do arquivo de script) deve corresponder ao ID de áudio. |
| Script | Nenhum script válido | Nenhum script válido é encontrado neste conjunto de dados. Corrija as linhas de script que aparecem na lista detalhada de problemas. |
| Áudio | Sem script correspondente | Nenhum arquivo de áudio corresponde à ID do script. O nome dos arquivos .wav deve corresponder aos IDs no arquivo de script. |
| Áudio | Formato de áudio inválido | O formato de áudio dos arquivos .wav é inválido. Verifique o formato de arquivo .wav usando uma ferramenta de áudio como o SoX. |
| Áudio | Baixa taxa de amostragem | A taxa de amostragem dos ficheiros .wav não pode ser inferior a 16 KHz. |
| Áudio | Áudio demasiado longo | A duração do áudio é superior a 30 segundos. Divida o áudio longo em vários arquivos. É uma boa ideia fazer enunciados inferiores a 15 segundos. |
| Áudio | Sem áudio válido | Nenhum áudio válido é encontrado neste conjunto de dados. Verifique os seus dados de áudio e carregue novamente. |
| Incompatibilidade | Enunciado com baixa pontuação | A pontuação de pronúncia ao nível da frase é inferior a 70. Reveja o script e o conteúdo de áudio para se certificar de que correspondem. |
Auto-fixo
Os seguintes erros são corrigidos automaticamente, mas você deve revisar e confirmar que as correções foram feitas corretamente.
| Category | Nome | Descrição |
|---|---|---|
| Incompatibilidade | Silêncio auto fixo | O silêncio de arranque é detetado como sendo inferior a 100 ms e foi automaticamente alargado para 100 ms. Faça o download do conjunto de dados normalizado e revise-o. |
| Incompatibilidade | Silêncio auto fixo | O silêncio final é detetado como sendo inferior a 100 ms, e foi estendido para 100 ms automaticamente. Faça o download do conjunto de dados normalizado e revise-o. |
| Script | Texto normalizado automaticamente | O texto é automaticamente normalizado para dígitos, símbolos e abreviaturas. Reveja o guião e o áudio para se certificar de que correspondem. |
Verificação manual necessária
Os erros não resolvidos listados na tabela a seguir afetam a qualidade do treinamento, mas os dados com esses erros não serão excluídos durante o treinamento. Para um treinamento de maior qualidade, é uma boa ideia corrigir esses erros manualmente.
| Category | Nome | Descrição |
|---|---|---|
| Script | Texto não normalizado | Este script contém símbolos. Normalize os símbolos para corresponder ao áudio. Por exemplo, normalize / para cortar. |
| Script | Enunciados de perguntas insuficientes | Pelo menos 10% do total de enunciados devem ser frases de interrogação. Isso ajuda o modelo de voz a expressar adequadamente um tom questionador. |
| Script | Enunciados de exclamação insuficientes | Pelo menos 10% do total de enunciados devem ser frases de exclamação. Isso ajuda o modelo de voz a expressar adequadamente um tom animado. |
| Script | Sem pontuação final válida | Adicione uma das seguintes opções no final da linha: ponto final (meia largura '.' ou largura total '。 '), ponto de exclamação (meia largura '!' ou largura total '!'), ou ponto de interrogação (meia largura '?' ou largura total '?'). |
| Áudio | Baixa taxa de amostragem para voz neural | Recomenda-se que a taxa de amostragem de seus arquivos .wav seja de 24 KHz ou superior para a criação de vozes neurais. Se for mais baixo, será automaticamente aumentado para 24 KHz. |
| Volume | Volume global demasiado baixo | O volume não deve ser inferior a -18 dB (10% do volume máximo). Controle o nível médio de volume dentro do intervalo adequado durante o registro da amostra ou a preparação dos dados. |
| Volume | Estouro de volume | O volume excedente é detetado em {}s. Ajustar o aparelho de controlo para evitar o estouro de volume no seu valor máximo. |
| Volume | Iniciar problema de silêncio | Os primeiros 100 ms de silêncio não estão limpos. Reduza o nível de ruído de gravação e deixe os primeiros 100 ms no início silenciosos. |
| Volume | Acabar com a questão do silêncio | Os últimos 100 ms de silêncio não estão limpos. Reduza o nível de ruído de gravação e deixe os últimos 100 ms no final silenciosos. |
| Incompatibilidade | Palavras com pontuação baixa | Reveja o script e o conteúdo de áudio para se certificar de que correspondem e controlar o nível de ruído do piso. Reduza a duração do silêncio longo ou divida o áudio em várias expressões se for muito longo. |
| Incompatibilidade | Iniciar problema de silêncio | Um áudio extra foi ouvido antes da primeira palavra. Revise o script e o conteúdo de áudio para garantir que eles correspondam, controle o nível de ruído e torne os primeiros 100 ms silenciosos. |
| Incompatibilidade | Acabar com a questão do silêncio | Áudio extra foi ouvido após a última palavra. Revise o script e o conteúdo de áudio para garantir que eles correspondam, controle o nível de ruído do piso e torne os últimos 100 ms silenciosos. |
| Incompatibilidade | Baixa relação sinal-ruído | Nível SNR de áudio é inferior a 20 dB. Recomenda-se pelo menos 35 dB. |
| Incompatibilidade | Nenhuma pontuação disponível | Falha ao reconhecer o conteúdo de fala neste áudio. Verifique o áudio e o conteúdo do script para se certificar de que o áudio é válido e corresponde ao script. |
Próximos passos
Você precisa de um conjunto de dados de treinamento para criar uma voz profissional. Um conjunto de dados de treinamento inclui arquivos de áudio e script. Os arquivos de áudio são gravações do talento de voz lendo os arquivos de script. Os arquivos de script são o texto dos arquivos de áudio.
Neste artigo, você cria um conjunto de treinamento e obtém sua ID de recurso. Em seguida, usando o ID do recurso, você pode carregar um conjunto de arquivos de áudio e script.
Criar um conjunto de treinamento
Para criar um conjunto de treinamento, use a operação TrainingSets_Create da API de voz personalizada. Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a propriedade necessária
projectId. Consulte Criar um projeto. - Defina a propriedade necessária
voiceKindcomoMaleouFemale. O tipo não pode ser alterado mais tarde. - Defina a propriedade necessária
locale. Esta deve ser a localidade dos dados do conjunto de treinamento. A localidade do conjunto de treinamento deve ser a mesma que a localidade da declaração de consentimento. A localidade não pode ser alterada posteriormente. Você pode encontrar a lista de localidades de texto para fala aqui. - Opcionalmente, defina a propriedade para a
descriptiondescrição do conjunto de treinamento. A descrição do conjunto de treinamento pode ser alterada posteriormente.
Faça uma solicitação HTTP PUT usando o URI, conforme mostrado no exemplo de TrainingSets_Create a seguir.
- Substitua
YourResourceKeypela chave de recurso de fala. - Substitua
YourResourceRegionpela região de recursos de Fala. - Substitua
JessicaTrainingSetIdpor um ID de conjunto de treinamento de sua escolha. O ID sensível a maiúsculas e minúsculas será usado no URI do conjunto de treinamento e não poderá ser alterado posteriormente.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
Deverá receber um corpo de resposta no seguinte formato:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Carregar dados do conjunto de treinamento
Para carregar um conjunto de treinamento de áudio e scripts, use a operação TrainingSets_UploadData da API de voz personalizada.
Antes de chamar essa API, armazene arquivos de gravação e script no Blob do Azure. No exemplo abaixo, os arquivos de gravação são *.wav, os arquivos de script são https://contoso.blob.core.windows.net/voicecontainer/jessica300/https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a propriedade necessária
kindcomoAudioAndScript. O tipo determina o tipo de conjunto de treinamento. - Defina a propriedade necessária
audios. Dentro daaudiospropriedade, defina as seguintes propriedades:- Defina a propriedade necessária
containerUrlpara a URL do contêiner de Armazenamento de Blob do Azure que contém os arquivos de áudio. Use assinaturas de acesso compartilhado (SAS) para um contêiner com permissões de leitura e lista. - Defina a propriedade required
extensionspara as extensões dos arquivos de áudio. - Opcionalmente, defina a propriedade para definir um prefixo
prefixpara o nome do blob.
- Defina a propriedade necessária
- Defina a propriedade necessária
scripts. Dentro dascriptspropriedade, defina as seguintes propriedades:- Defina a propriedade required
containerUrlcomo a URL do contêiner de Armazenamento de Blob do Azure que contém os arquivos de script. Use assinaturas de acesso compartilhado (SAS) para um contêiner com permissões de leitura e lista. - Defina a propriedade required
extensionspara as extensões dos arquivos de script. - Opcionalmente, defina a propriedade para definir um prefixo
prefixpara o nome do blob.
- Defina a propriedade required
Faça uma solicitação HTTP POST usando o URI, conforme mostrado no exemplo de TrainingSets_UploadData a seguir.
- Substitua
YourResourceKeypela chave de recurso de fala. - Substitua
YourResourceRegionpela região de recursos de Fala. - Substitua
JessicaTrainingSetIdse você especificou um ID de conjunto de treinamento diferente na etapa anterior.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
O cabeçalho de resposta contém a Operation-Location propriedade. Use este URI para obter detalhes sobre a operação TrainingSets_UploadData. Aqui está um exemplo do cabeçalho da resposta:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345