Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Use o kit de processamento em lote para complementar e dimensionar cargas de trabalho em contêineres de fala. Disponível como um contêiner, esse utilitário de código aberto ajuda a facilitar a transcrição em lote para um grande número de arquivos de áudio, em qualquer número de pontos de extremidade de contêiner de fala locais e baseados em nuvem.

O contêiner do kit de lote está disponível gratuitamente no GitHub e no hub do Docker. Só lhe são cobrados os contentores de Voz que utiliza.
| Funcionalidade | Descrição |
|---|---|
| Distribuição de arquivos de áudio em lote | Despache automaticamente um grande número de arquivos para pontos de extremidade de contêiner de fala locais ou baseados em nuvem. Os arquivos podem estar em qualquer volume compatível com POSIX, incluindo sistemas de arquivos de rede. |
| Integração com o Speech SDK | Passe sinalizadores comuns para o SDK de fala, incluindo: n-melhores hipóteses, diarização, linguagem, mascaramento de palavrões. |
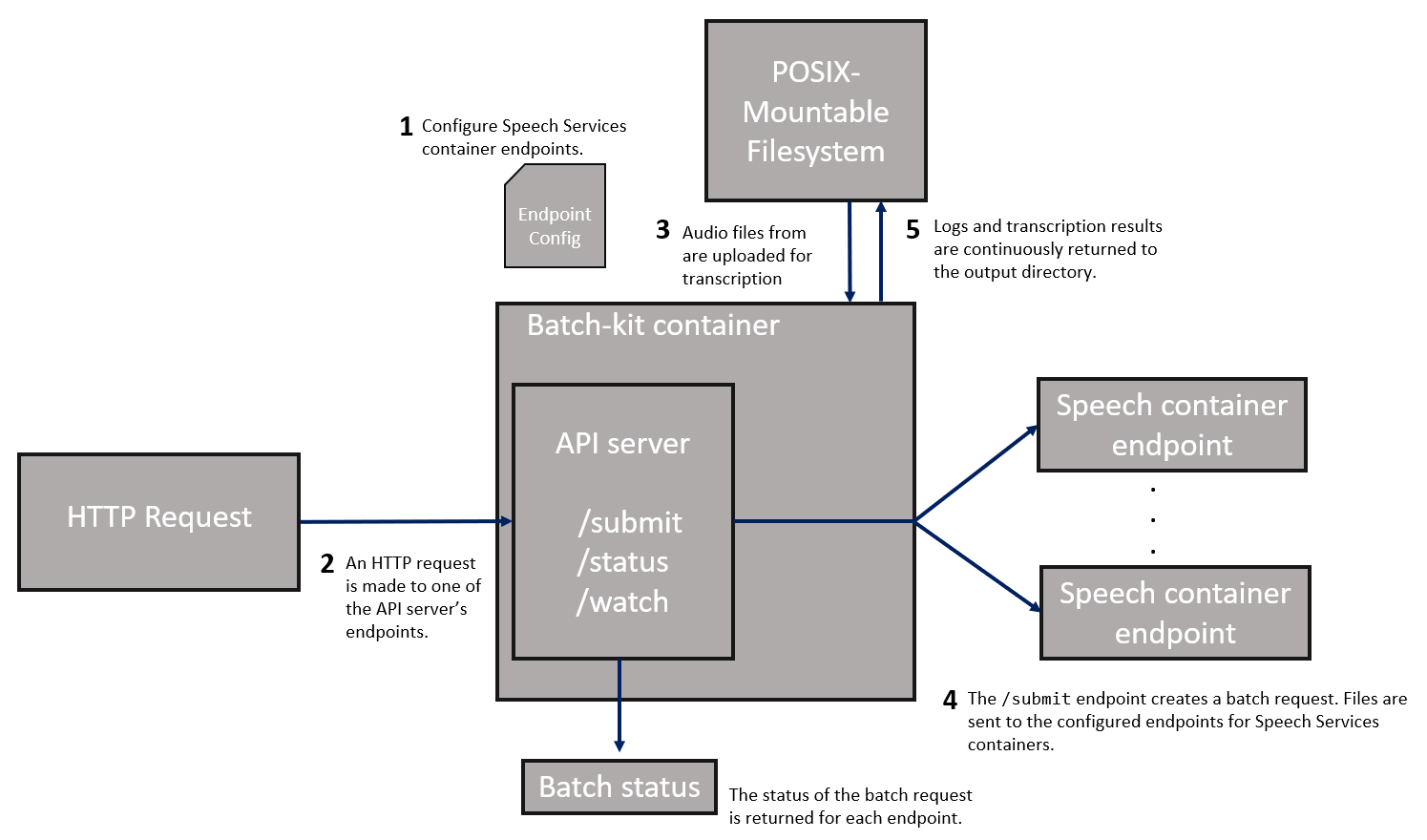
| Modos de execução | Execute o cliente em lote uma vez, continuamente em segundo plano ou crie pontos de extremidade HTTP para arquivos de áudio. |
| Tolerância a falhas | Tente novamente e continue a transcrição automaticamente sem perder o progresso e diferencie entre quais erros podem e não podem ser repetidos. |
| Deteção de disponibilidade de endpoint | Se um ponto de extremidade ficar indisponível, o cliente em lote continuará transcrevendo, usando outros pontos de extremidade de contêiner. Quando o cliente está disponível, ele começa automaticamente a usar o ponto de extremidade. |
| Hot-swapping de terminais | Adicione, remova ou modifique pontos de extremidade do contêiner de fala durante o tempo de execução sem interromper o progresso do lote. As atualizações são imediatas. |
| Registo em tempo real | Registro em tempo real de solicitações tentadas, carimbos de data/hora e motivos de falha, com arquivos de log do SDK de fala para cada arquivo de áudio. |
Obtenha a imagem do contêiner com docker pull
Use o comando docker pull para baixar o contêiner do kit de lote mais recente.
Nota
O exemplo a seguir extrai uma imagem de contêiner público do Docker Hub. Recomendamos que você se autentique com sua conta do Docker Hub (docker login) primeiro, em vez de fazer uma solicitação pull anônima. Para melhorar a confiabilidade ao usar conteúdo público, importe e gerencie a imagem em um registro de contêiner privado do Azure.
Saiba mais sobre como trabalhar com imagens públicas.
docker pull docker.io/batchkit/speech-batch-kit:latest
Configuração do ponto final
O cliente em lote usa um arquivo de configuração yaml que especifica os pontos de extremidade de contêiner locais. O exemplo a seguir pode ser escrito em /mnt/my_nfs/config.yaml, que é usado nos exemplos a seguir.
MyContainer1:
concurrency: 5
host: 192.168.0.100
port: 5000
rtf: 3
MyContainer2:
concurrency: 5
host: BatchVM0.corp.redmond.microsoft.com
port: 5000
rtf: 2
MyContainer3:
concurrency: 10
host: localhost
port: 6001
rtf: 4
Este exemplo de yaml especifica três contêineres de fala em três hosts. O primeiro host é especificado por um endereço IPv4, o segundo está sendo executado na mesma VM que o cliente em lote e o terceiro contêiner é especificado pelo nome de host DNS de outra VM. O concurrency valor especifica o máximo de transcrições de arquivo simultâneas que podem ser executadas no mesmo contêiner. O rtf valor (Real-Time Fator) é opcional e pode ser usado para ajustar o desempenho.
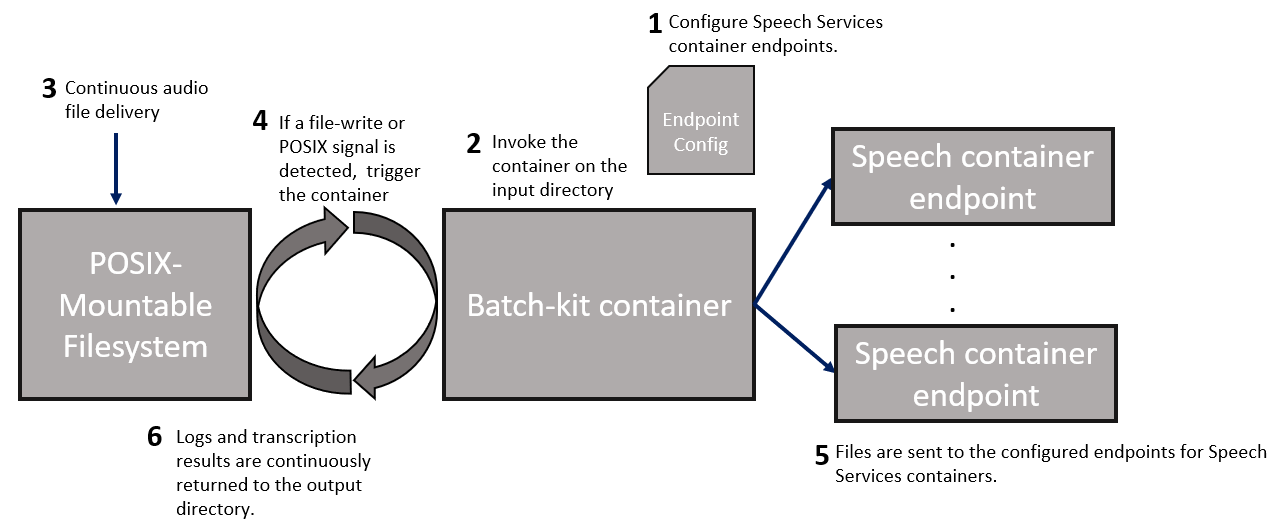
O cliente em lote pode detetar dinamicamente se um ponto de extremidade fica indisponível (por exemplo, devido a uma reinicialização do contêiner ou problema de rede) e quando ele fica disponível novamente. As solicitações de transcrição não são enviadas para contêineres que não estão disponíveis e o cliente continua usando outros contêineres disponíveis. Você pode adicionar, remover ou editar pontos de extremidade a qualquer momento sem interromper o progresso do lote.
Executar o contêiner de processamento em lote
Nota
- Este exemplo usa o mesmo diretório (
/my_nfs) para o arquivo de configuração e os diretórios de entradas, saídas e logs. Você pode usar diretórios hospedados ou montados em NFS para essas pastas. - A execução do cliente com o
–hsinalizador lista os parâmetros de linha de comando disponíveis e seus valores padrão. - O contêiner de processamento em lote só é suportado no Linux.
Use o comando Docker run para iniciar o contêiner. Este comando inicia um shell interativo dentro do contêiner.
docker run --network host --rm -ti -v /mnt/my_nfs:/my_nfs --entrypoint /bin/bash /mnt/my_nfs:/my_nfs docker.io/batchkit/speech-batch-kit:latest
Para executar o cliente em lote:
run-batch-client -config /my_nfs/config.yaml -input_folder /my_nfs/audio_files -output_folder /my_nfs/transcriptions -log_folder /my_nfs/logs -file_log_level DEBUG -nbest 1 -m ONESHOT -diarization None -language en-US -strict_config
Para executar o cliente em lote e o contêiner em um único comando:
docker run --network host --rm -ti -v /mnt/my_nfs:/my_nfs docker.io/batchkit/speech-batch-kit:latest -config /my_nfs/config.yaml -input_folder /my_nfs/audio_files -output_folder /my_nfs/transcriptions -log_folder /my_nfs/logs
O cliente começa a ser executado. Se um arquivo de áudio foi transcrito em uma execução anterior, o cliente ignora automaticamente o arquivo. Os arquivos são enviados com uma nova tentativa automática se ocorrerem erros transitórios, e você pode diferenciar entre quais erros deseja que o cliente tente novamente. Em um erro de transcrição, o cliente continua a transcrição e pode tentar novamente sem perder o progresso.
Modos de execução
O kit de processamento em lote oferece três modos, usando o --run-mode parâmetro.
ONESHOT modo transcreve um único lote de arquivos de áudio (de um diretório de entrada e lista de arquivos opcionais) para uma pasta de saída.
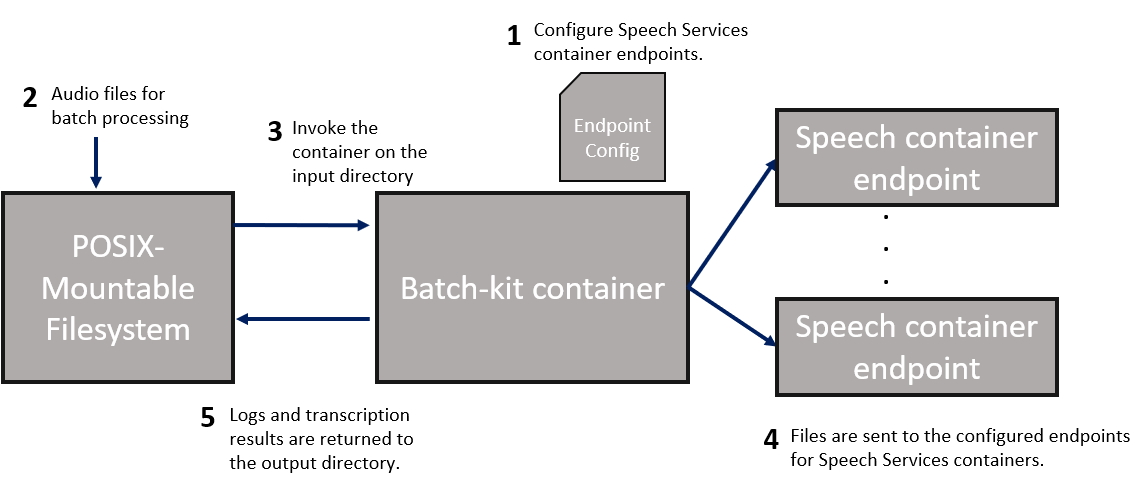
- Defina os pontos de extremidade do contêiner de fala que o cliente em lote usa no
config.yamlarquivo. - Coloque arquivos de áudio para transcrição em um diretório de entrada.
- Invoque o contêiner no diretório para começar a processar os arquivos. Se o arquivo de áudio já estiver transcrito em uma execução anterior com o mesmo diretório de saída (mesmo nome de arquivo e soma de verificação), o cliente ignorará o arquivo.
- Os arquivos são despachados para os pontos de extremidade do contêiner a partir da etapa 1.
- Os logs e a saída do contêiner de fala são retornados para o diretório de saída especificado.
Registo
Nota
O cliente em lote pode substituir o arquivo run.log periodicamente se ele ficar muito grande.
O cliente cria um arquivo run.log no diretório especificado pelo -log_folder argumento no comando docker run . Os logs são capturados no nível de depuração por padrão. Os mesmos logs são enviados para o stdout/stderr, e filtrados dependendo dos -file_log_level argumentos ou console_log_level . Esse log só é necessário para depuração ou se você precisar enviar um rastreamento para suporte. A pasta de log também contém os logs do SDK de fala para cada arquivo de áudio.
O diretório de saída especificado por -output_folder contém um arquivo run_summary.json , que é reescrito periodicamente a cada 30 segundos ou sempre que novas transcrições são concluídas. Você pode usar esse arquivo para verificar o progresso à medida que o lote prossegue. Ele também contém as estatísticas de execução final e o status final de cada arquivo quando o lote é concluído. O lote é concluído quando o processo tem uma saída limpa.