Antipadrão Front-end ocupado
A execução de trabalho assíncrono num elevado número de threads em segundo plano pode prejudicar as outras tarefas de recursos simultâneas em primeiro plano ao diminuir os tempos de resposta para níveis inaceitáveis.
Descrição do problema
As tarefas com muitos recursos podem aumentar os tempos de resposta para os pedidos de utilizador e causar uma latência elevada. Uma forma de melhorar os tempos de resposta é descarregar uma tarefa com muitos recursos num thread separado. Esta abordagem permite à aplicação permanecer reativa durante o processamento em segundo plano. No entanto, as tarefas executadas num thread em segundo plano continuam a consumir recursos. Se existirem demasiadas, estas podem prejudicar os threads que estão a processar os pedidos.
Nota
O termo recurso pode abranger inúmeros aspetos, tais como a utilização da CPU, a ocupação da memória e a E/S da rede ou do disco.
Normalmente, este problema ocorre quando uma aplicação é desenvolvida como fragmento de código monolítico, com toda a lógica de negócio combinada numa única camada partilhada com a camada de apresentação.
Segue-se um exemplo da utilização do ASP.NET que demonstra o problema. Pode encontrar o exemplo completo aqui.
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
O método
Postno controladorWorkInFrontEndimplementa uma operação POST de HTTP. Esta operação simula uma tarefa com utilização intensiva da CPU de longa execução. O trabalho é executado num thread separado, numa tentativa de permitir a rápida conclusão da operação POST.O método
Getno controladorUserProfileimplementa uma operação GET de HTTP. Este método é muito menos intensivo em termos de CPU.
A principal preocupação consiste nos requisitos de recursos do método Post. Embora coloque o trabalho no thread em segundo plano, o trabalho ainda pode consumir recursos consideráveis da CPU. Estes recursos são partilhados com outras operações executadas por outros utilizadores em simultâneo. Se um número moderado de utilizadores enviar este pedido em simultâneo, é provável que o desempenho geral seja afetado, o que torna todas as operações mais lentas. Os utilizadores podem obter uma latência significativa no método Get, por exemplo.
Como resolver o problema
Mova os processos que consomem recursos significativos para um back-end separado.
Com esta abordagem, o front-end coloca as tarefas com muitos recursos numa fila de mensagens. O back-end escolhe as tarefas para o processamento assíncrono. A fila também age como equilibrador de carga ao colocar os pedidos do back-end na memória intermédia. Se o comprimento da fila se tornar demasiado longo, pode configurar o dimensionamento automático para aumentar horizontalmente o back-end.
Segue-se uma versão revista do código anterior. Nesta versão, o método Post coloca uma mensagem numa fila do Service Bus.
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
O back-end obtém as mensagens da fila do Service Bus e efetua o processamento.
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
Considerações
- Esta abordagem adiciona mais alguma complexidade à aplicação. Tem de processar a colocação e a remoção da fila em segurança para evitar a perda de pedidos em caso de falha.
- A aplicação utiliza uma dependência num serviço adicional para a fila de mensagens.
- O ambiente de processamento tem de ser suficientemente dimensionável para processar a carga de trabalho esperada e cumprir os objetivos de débito necessários.
- Embora esta abordagem deva melhorar a capacidade de resposta global, as tarefas movidas para o back-end podem demorar mais tempo a concluir.
Como detetar o problema
Os sintomas de um front-end ocupado incluem latência elevada quando estão a ser efetuadas tarefas com muitos recursos. É provável que os usuários finais relatem tempos de resposta estendidos ou falhas causadas pelo tempo limite dos serviços. Essas falhas também podem retornar erros HTTP 500 (Servidor Interno) ou HTTP 503 (Serviço Indisponível). Analise os registos de eventos do servidor Web, os quais contêm provavelmente informações mais detalhadas sobre as causas e as circunstâncias dos erros.
Pode realizar os passos seguintes para ajudar a identificar este problema:
- Efetue a monitorização de processos do sistema de produção para identificar os pontos em que os tempos de resposta se tornam mais lentos.
- Analise os dados de telemetria capturados nestes pontos para determinar a combinação de operações efetuadas e os recursos utilizados.
- Localize quaisquer correlações entre os fracos tempos de resposta e os volumes e combinações de operações que ocorreram a essas horas.
- Teste a carga de cada operação suspeita para identificar que operações estão a consumir recursos e a prejudicar outras operações.
- Reveja o código fonte dessas operações para determinar por que motivo podem causar um consumo excessivo de recursos.
Diagnóstico de exemplo
As secções seguintes aplicam estes passos para o exemplo de aplicação descrito anteriormente.
Identificar os pontos de abrandamento
Instrumente cada método para controlar a duração e os recursos consumidos por cada pedido. Em seguida, monitorize a aplicação em produção. Isto pode fornecer uma vista geral de como os pedidos competem entre si. Durante períodos de esforço, os pedidos com falta de recursos de execução lenta irão, provavelmente, afetar outras operações e este comportamento pode ser observado pela monitorização do sistema e pela queda de desempenho.
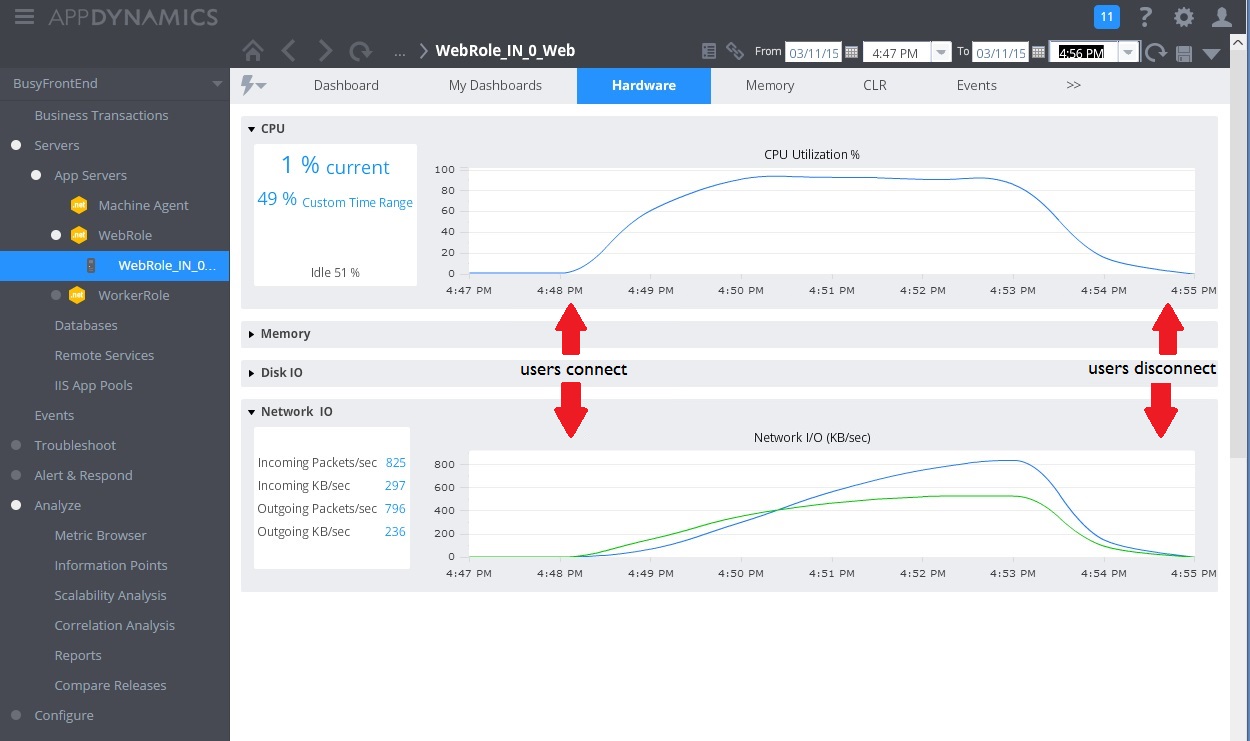
A imagem seguinte mostra um dashboard de monitorização. (Nós usamos AppDynamics para nossos testes.) Inicialmente, o sistema tem carga leve. Em seguida, os utilizadores começam a pedir o método UserProfile GET. O desempenho é razoavelmente bom até outros utilizadores começarem a emitir pedidos para o método WorkInFrontEnd POST. Nessa altura, os tempos de resposta aumentam significativamente (primeira seta). Os tempos de resposta só melhoram após a diminuição do volume de pedidos para o controlador WorkInFrontEnd (segunda seta).
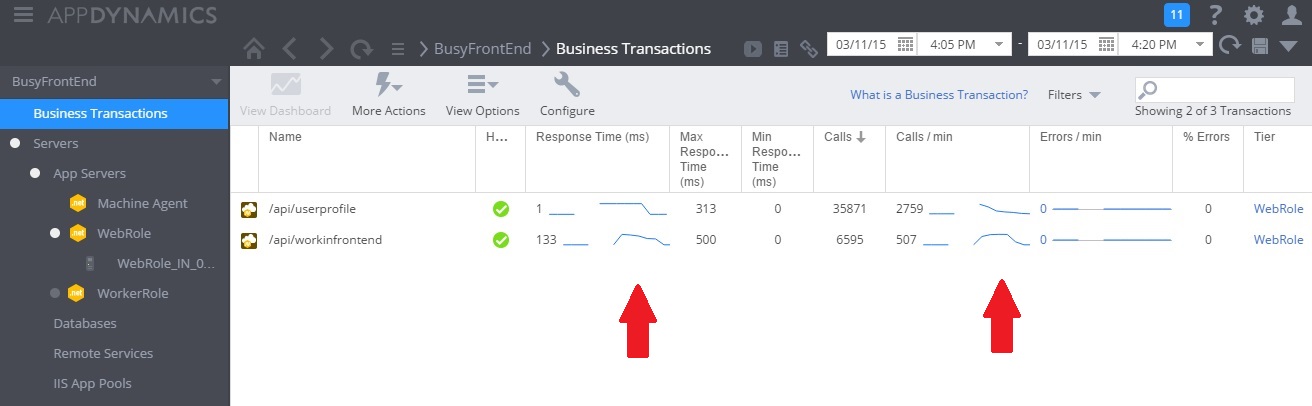
Examinar os dados telemétricos e localizar correlações
A imagem seguinte mostra algumas das métricas recolhidas para monitorizar a utilização de recursos durante o mesmo intervalo. Ao início, poucos utilizadores estão a aceder ao sistema. À medida que se ligam mais utilizadores, a utilização da CPU torna-se muito elevada (100%). Repare também que a velocidade de E/S da rede sobe inicialmente à medida que aumenta a utilização da CPU. No entanto, após os picos de utilização da CPU, a E/S da rede desce. Isto acontece porque o sistema só consegue processar um número relativamente pequeno de pedidos depois de a CPU atingir a sua capacidade. À medida que os utilizadores desligam, a carga da CPU diminui.
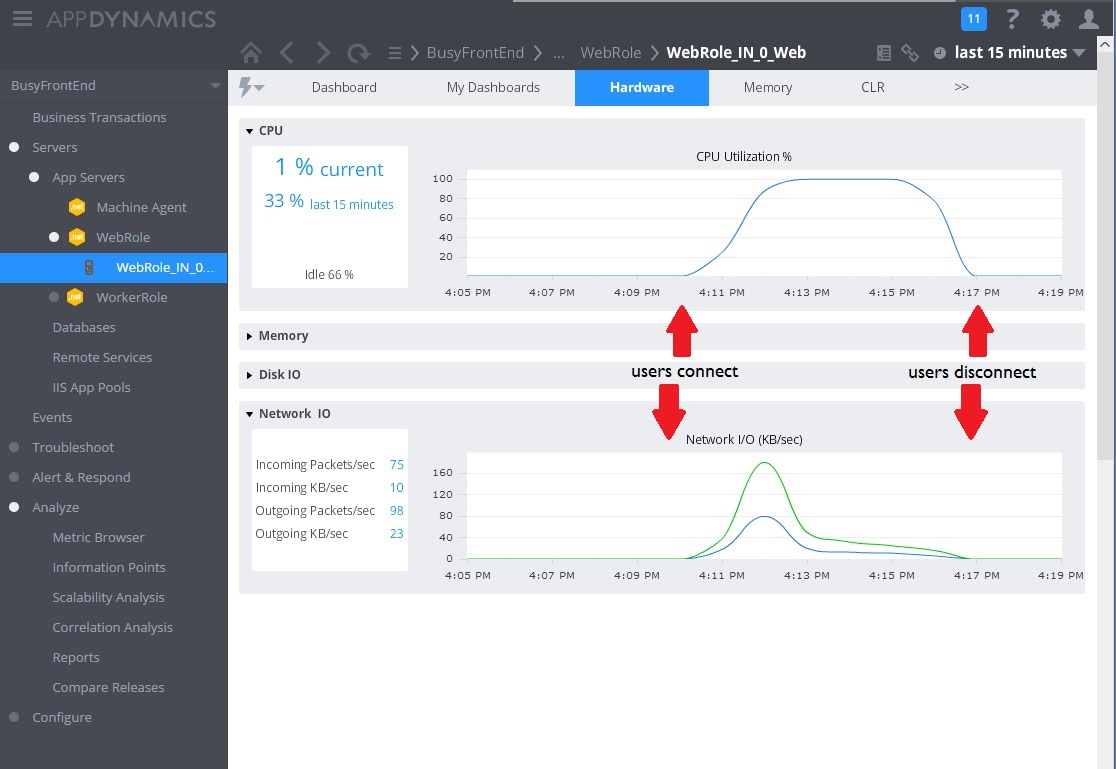
Neste momento, parece que o método Post no controlador WorkInFrontEnd é o candidato ideal a ser examinado mais detalhadamente. É necessário trabalho adicional num ambiente controlado para confirmar a hipótese.
Efetuar teste de carga
O passo seguinte consiste em efetuar testes num ambiente controlado. Por exemplo, execute uma série de testes de carga que incluam e, em seguida, omitam cada pedido à vez para ver os efeitos.
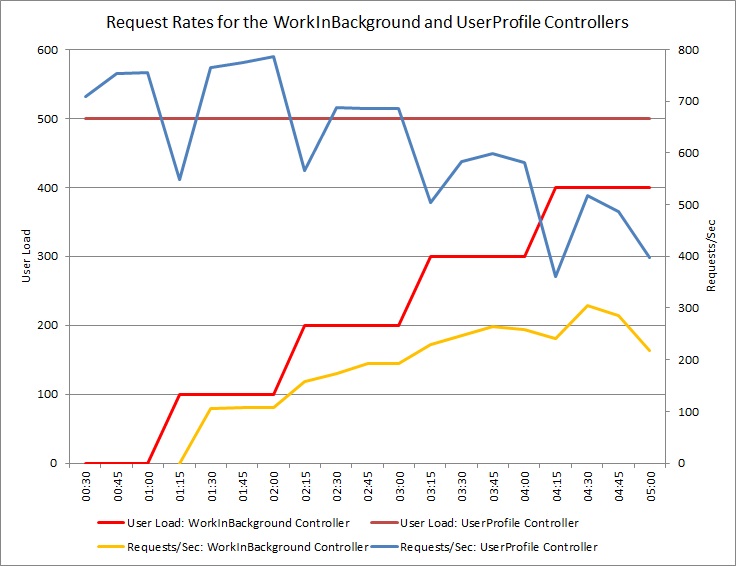
O gráfico abaixo mostra os resultados de um teste de carga efetuado numa implementação idêntica do serviço cloud utilizado nos testes anteriores. O teste utilizou uma carga constante de 500 utilizadores a efetuar a operação Get no controlador UserProfile, juntamente com uma carga de utilizadores a efetuar a operação Post no controlador WorkInFrontEnd.
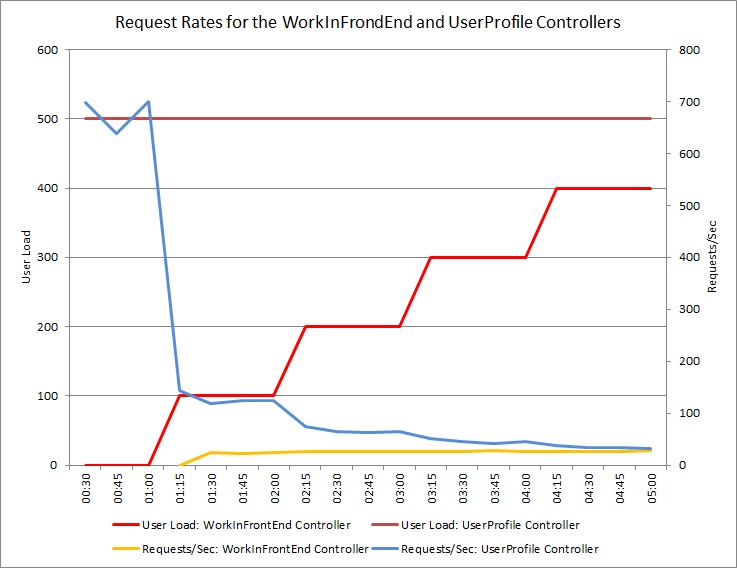
Inicialmente, a carga é 0, pelo que apenas os utilizadores ativos estão a efetuar os pedidos UserProfile. O sistema consegue responder a aproximadamente 500 pedidos por segundo. Após 60 segundos, uma carga de 100 utilizadores adicionais começa a enviar pedidos POST para o controlador WorkInFrontEnd. Quase imediatamente, a carga de trabalho enviada para o controlador UserProfile desce para cerca de 150 pedidos por segundo. Isto deve-se ao modo de funcionamento da execução dos testes de carga. Aguarda uma resposta antes de enviar o pedido seguinte, por isso, quanto mais tempo demorar a receber uma resposta, menor é a taxa de pedidos.
À medida que mais utilizadores enviam pedidos POST para o controlador WorkInFrontEnd, a taxa de resposta do controlador UserProfile continua a descer. Mas note que o volume de solicitações tratadas pelo WorkInFrontEnd controlador permanece relativamente constante. A saturação do sistema torna-se aparente à medida que a taxa global de ambos os pedidos tende a diminuir para um limite gradual baixo.
Rever o código fonte
O passo final é analisar o código fonte. A equipa de desenvolvimento estava ciente de que o método Post pode demorar uma quantidade considerável de tempo, motivo pelo qual a implementação original utilizou um thread separado. Isso resolveu o problema imediato, porque o método Post não bloqueou à espera da conclusão de uma tarefa de execução longa.
No entanto, o trabalho realizado por este método continua a consumir CPU, memória e outros recursos. Permitir que este processo seja executado de modo assíncrono pode, na verdade, prejudicar o desempenho, uma vez que os utilizadores podem acionar um grande número destas operações em simultâneo, de forma não controlada. Existe um limite para o número de threads que um servidor pode executar. Ultrapassado este limite, é provável que a aplicação obtenha uma exceção quando tentar iniciar um novo thread.
Nota
Isto não significa que deve evitar operações assíncronas. É recomendado efetuar uma espera assíncrona numa chamada de rede. (Veja o Antipadrão de E/S síncrono.) O problema aqui é que o trabalho intensivo de CPU foi gerado em outro thread.
Implementar a solução e verificar o resultado
A imagem seguinte mostra a monitorização do desempenho após a implementação da solução. A carga era semelhante à apresentada anteriormente, mas os tempos de resposta para o controlador UserProfile são agora muito mais rápidos. O volume de pedidos aumentou ao longo da mesma duração, de 2.759 para 23.565.
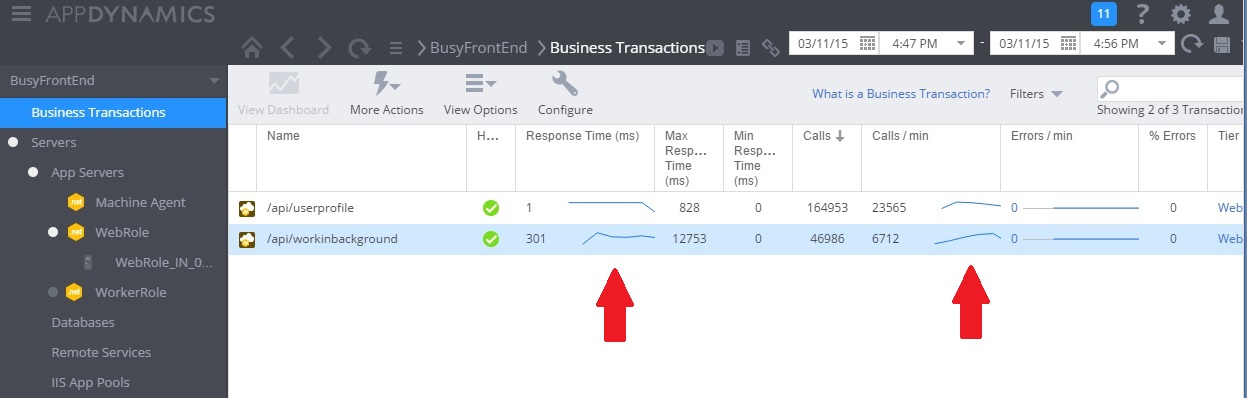
Tenha em atenção que o controlador WorkInBackground também processou um volume muito maior de pedidos. No entanto, não pode fazer uma comparação direta neste caso, porque o trabalho a efetuar neste controlador é muito diferente do código original. A nova versão simplesmente coloca um pedido na fila, em vez de efetuar um cálculo demorado. O ponto principal é que este método já não arrasta todo o sistema em carga.
A utilização da CPU e da rede também mostram um melhor desempenho. A utilização da CPU nunca atingiu 100% e o volume de pedidos de rede processados foi muito maior do que anteriormente e só diminuiu quando a carga de trabalho desceu.
O gráfico seguinte mostra os resultados de um teste de carga. O volume global de pedidos servidos foi significativamente maior em comparação com os testes anteriores.
Orientação relacionada
- Autoscaling best practices (Melhores práticas de dimensionamento automático)
- Melhores práticas para tarefas em segundo plano
- Padrão de Redistribuição de Carga Baseada na Fila
- Estilo de arquitetura Web-Fila-Trabalho
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários