Anti-padrão de Instâncias Impróprias
Às vezes, novas instâncias de uma classe são continuamente criadas, quando ela deve ser criada uma vez e, em seguida, compartilhada. Esse comportamento pode prejudicar o desempenho e é chamado de antipadrão de instanciação impróprio. Um antipadrão é uma resposta comum a um problema recorrente que geralmente é ineficaz e pode até ser contraproducente.
Descrição do problema
Muitas bibliotecas oferecem abstrações de recursos externos. Internamente, estas classes normalmente gerem as suas próprias ligações ao recurso, e agem como mediadores que os clientes podem utilizar para aceder ao recurso. Seguem-se alguns exemplos das classes de mediador que são relevantes para as aplicações do Azure:
System.Net.Http.HttpClient. Comunica com um serviço Web com HTTP.Microsoft.ServiceBus.Messaging.QueueClient. Publica e recebe mensagens para uma fila do Service Bus.Microsoft.Azure.Documents.Client.DocumentClient. Conecta-se a uma instância do Azure Cosmos DB.StackExchange.Redis.ConnectionMultiplexer. Liga ao Redis, incluindo a Cache do Azure para Redis.
Estas classes destinam-se a ser instanciadas uma vez e reutilizadas em toda a duração de uma aplicação. No entanto, é um mal entendido comum que estas classes devem ser compradas apenas conforme necessário e lançadas rapidamente. (As listadas aqui são bibliotecas .NET, mas o padrão não é exclusivo do .NET.) O exemplo de ASP.NET a seguir cria uma instância de HttpClient para se comunicar com um serviço remoto. Pode encontrar o exemplo completo aqui.
public class NewHttpClientInstancePerRequestController : ApiController
{
// This method creates a new instance of HttpClient and disposes it for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
using (var httpClient = new HttpClient())
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
}
Numa aplicação Web, esta técnica não é dimensionável. Um novo objeto HttpClient é criado para cada pedido de utilizador. Com muita carga, o servidor Web poderá esgotar o número de sockets disponíveis, resultando em SocketException erros.
Este problema não está limitado à classe HttpClient. Outras classes que encapsulam recursos num wrapper ou são dispendiosas de criar poderão causar problemas semelhantes. O exemplo seguinte cria uma instância da classe ExpensiveToCreateService. Aqui o problema não é necessariamente esgotamento de socket, mas simplesmente quanto tempo demora para criar cada instância. Criar e destruir continuamente instâncias desta classe poderá afetar negativamente a escalabilidade do sistema.
public class NewServiceInstancePerRequestController : ApiController
{
public async Task<Product> GetProductAsync(string id)
{
var expensiveToCreateService = new ExpensiveToCreateService();
return await expensiveToCreateService.GetProductByIdAsync(id);
}
}
public class ExpensiveToCreateService
{
public ExpensiveToCreateService()
{
// Simulate delay due to setup and configuration of ExpensiveToCreateService
Thread.SpinWait(Int32.MaxValue / 100);
}
...
}
Como corrigir antipadrão de instanciação impróprio
Se a classe que encapsula num wrapper os recursos externos for partilhável e segura quanto a threads, crie uma instância singleton partilhada ou um conjunto de instâncias reutilizáveis da classe.
O exemplo seguinte utiliza uma instância HttpClient estática e, por conseguinte, partilha a ligação entre todos os pedidos.
public class SingleHttpClientInstanceController : ApiController
{
private static readonly HttpClient httpClient;
static SingleHttpClientInstanceController()
{
httpClient = new HttpClient();
}
// This method uses the shared instance of HttpClient for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
Considerações
O elemento-chave deste anti-padrão é criar e destruir repetidamente instâncias de um objeto partilhável . Se uma classe não for partilhável (não seguro quanto a threads), então este anti-padrão não se aplica.
O tipo de recurso partilhado pode ditar se deve utilizar um singleton ou criar um conjunto. A classe
HttpClientfoi concebida para ser partilhada, em vez de agrupada. Outros objetos poderão suportar o conjunto, ao ativar o sistema para distribuir a carga de trabalho em várias instâncias.Os objetos que partilha em vários pedidos têm ser seguros quanto a threads. A classe
HttpClientfoi concebida para ser utilizada desta forma, mas outras classes podem não suportar pedidos simultâneos, por isso, veja a documentação disponível.Se cuidado em relação à definição de propriedades em objetos partilhados, dado que pode levar a condições race. Por exemplo, definir
DefaultRequestHeadersna classeHttpClientantes de cada pedido pode criar uma condição race. Definir esse tipo de propriedades uma vez (por exemplo, durante o arranque) e criar instâncias separadas se precisar de configurar definições diferentes.Alguns tipos de recursos são escassos e não devem ser mantidos. As ligações de bases de dados são um exemplo. Ter uma ligação de base de dados aberta que não é necessária pode impedir que outros utilizadores em simultâneo tenham acesso à base de dados.
No .NET Framework, muitos objetos que estabelecem ligações a recursos externos são criados com métodos de fábrica estáticos de outras classes que gerem estas ligações. Estes objetos destinam-se a ser guardados e reutilizados, em vez de eliminados e recriados. Por exemplo, no Azure Service Bus, o objeto
QueueClienté criado através de um objetoMessagingFactory. Internamente, oMessagingFactorygere ligações. Para obter mais informações, veja as Melhores Práticas de melhorias do desempenho com as Mensagens do Service Bus.
Como detetar antipadrão de instanciação impróprio
Os sintomas deste problema incluem uma redução no débito ou uma taxa de aumento de erro, juntamente com um ou mais dos seguintes acontecimentos:
- Um aumento de exceções que indicam esgotamento de recursos, como sockets, ligações de base de dados, identificadores de ficheiros, etc.
- Aumento da utilização da memória e da libertação da memória.
- Um aumento na atividade de rede, disco e base de dados.
Pode realizar os passos seguintes para ajudar a identificar este problema:
- Realizar a monitorização de processos do sistema de produção para identificar os pontos em que os tempos de resposta se tornam mais lentos ou o sistema falha devido à falta de recursos.
- Examine os dados telemétricos capturados nestes pontos para determinar as operações que podem estar a criar e a destruir objetos que consomem recursos.
- Realize o teste de carga em cada operação suspeita num ambiente de teste controlado, em vez do sistema de produção.
- Veja o código de origem e examine a forma como os objetos mediadores são geridos.
Veja os rastreios de pilha para as operações com uma execução lenta ou para gerar exceções quando o sistema está sob carga. Estas informações podem ajudar a identificar a forma como estas operações estão a utilizar os recursos. As exceções podem ajudar a determinar se os erros são causados pelos recursos partilhados se estarem a esgotar.
Diagnóstico de exemplo
As secções seguintes aplicam estes passos para o exemplo de aplicação descrito anteriormente.
Identificar pontos de lentidão ou de falha
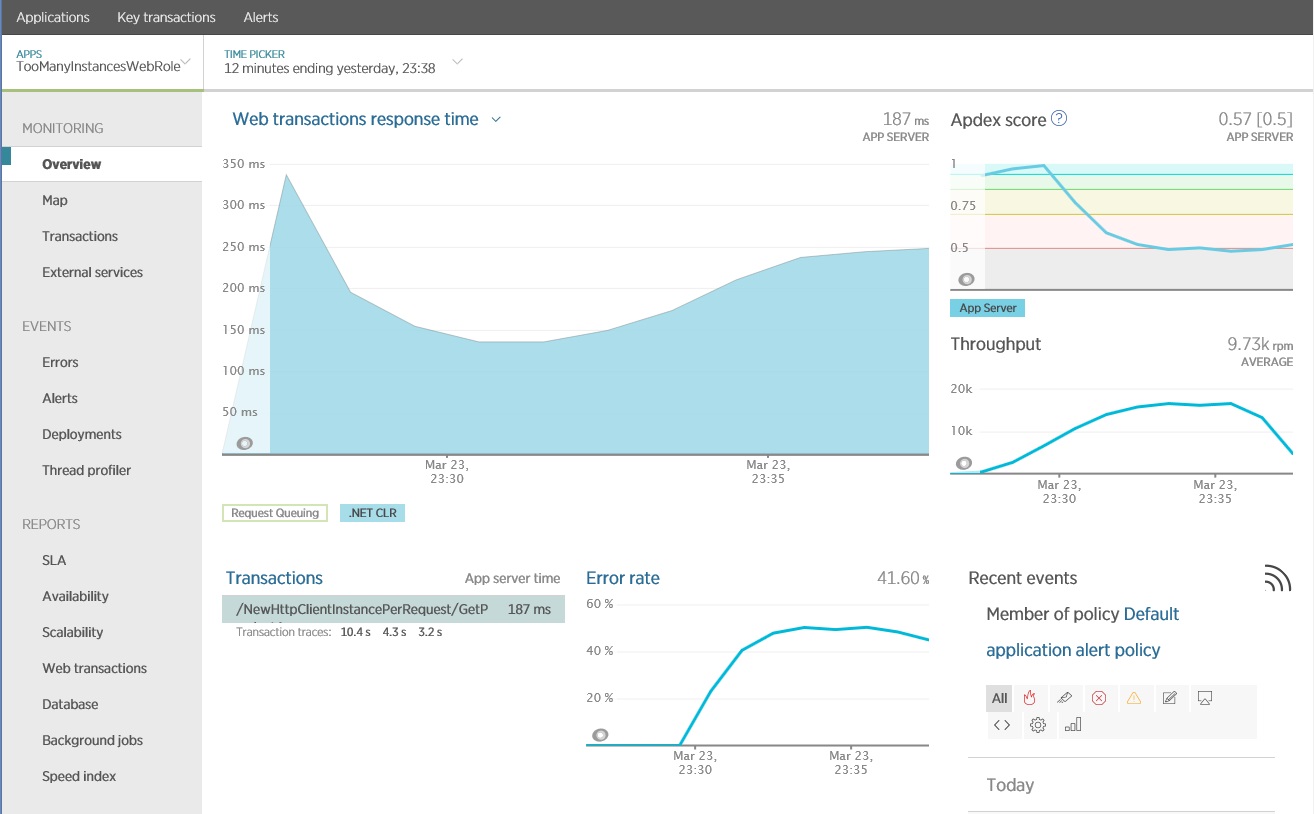
A imagem seguinte mostra os resultados gerados com o New Relic APM, que mostra as operações que têm um tempo de resposta fraco. Neste caso, o método GetProductAsync no controlador NewHttpClientInstancePerRequest merece ainda mais investigação. Tenha em atenção que a taxa de erros também aumenta quando estas operações estão em execução.
Examinar os dados telemétricos e localizar correlações
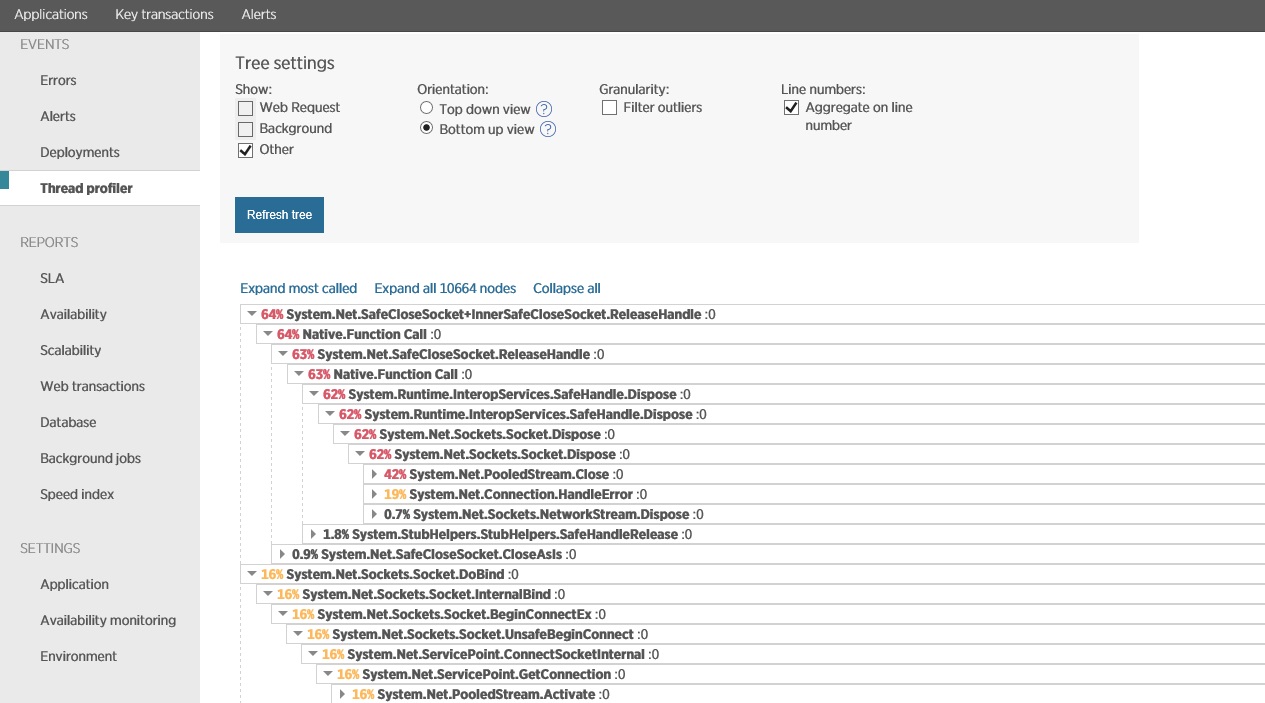
A imagem seguinte mostra os dados capturados com a criação de perfis de thread durante o mesmo período correspondente à imagem anterior. O sistema passa muito tempo a abrir ligações de socket e ainda mais tempo a fechá-las e a processar exceções de socket.
Realizar teste de carga
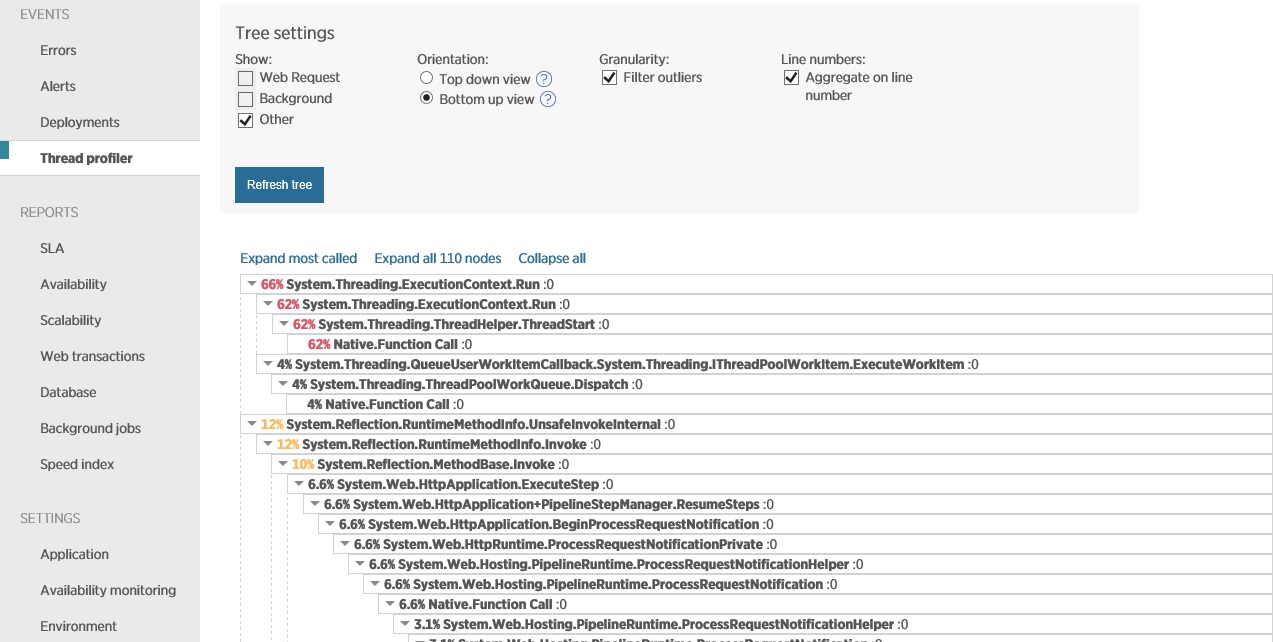
Utilize o teste de carga para simular as operações habituais que os utilizadores podem realizar. Esta ação pode ajudar a identificar quais as partes de um sistema que são afetadas pelo esgotamento de recursos em diferentes cargas. Realize estes testes num ambiente controlado, em vez do sistema de produção. O gráfico seguinte mostra o débito de pedidos processados pelo controlador NewHttpClientInstancePerRequest, à medida que a carga de utilizador aumenta para 100 utilizadores em simultâneo.
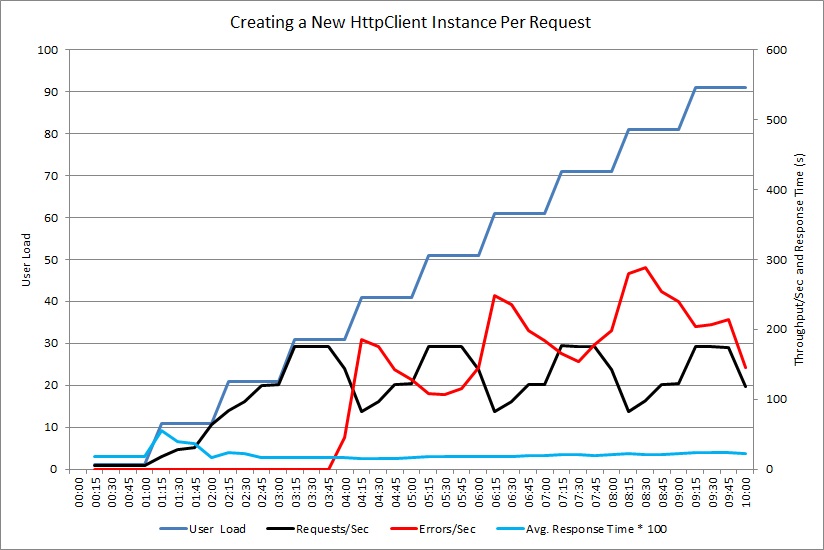
Em primeiro lugar, o volume de pedidos processados por segundo aumenta à medida que a carga de trabalho é aumentada. Em cerca de 30 utilizadores, no entanto, o volume de pedidos com êxito atinge um limite e o sistema começa a gerar exceções. De ora em diante, o volume de exceções aumenta gradualmente de acordo com a carga do utilizador.
O teste de carga comunicou estas falhas como erros de HTTP 500 (Servidor Interno). Rever a telemetria mostrou que estes erros foram causados pela execução do sistema fora dos recursos de socket, uma vez que foram criados cada vez mais objetos HttpClient.
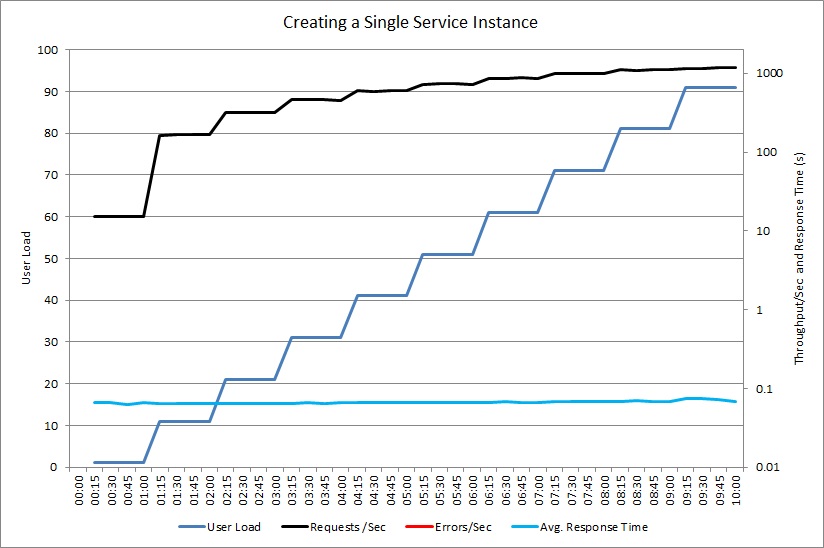
O gráfico seguinte mostra um teste semelhante para um controlador que cria o objeto ExpensiveToCreateService personalizado.
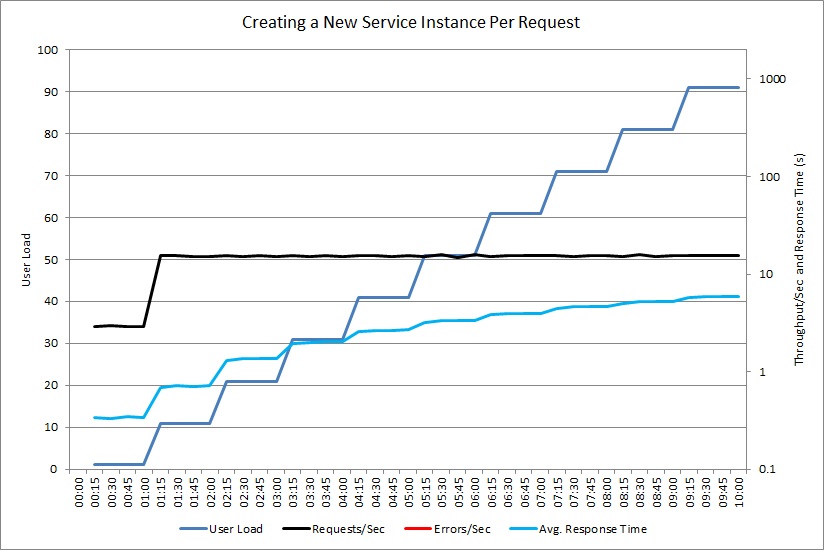
Neste momento, o controlador não gera quaisquer exceções, mas o débito ainda atinge um patamar, enquanto o tempo de resposta médio aumenta por um fator de 20. (O gráfico usa uma escala logarítmica para tempo de resposta e taxa de transferência.) A telemetria mostrou que a criação de novas instâncias do foi a ExpensiveToCreateService principal causa do problema.
Implementar a solução e verificar o resultado
Após mudar o método GetProductAsync para partilhar numa única instância HttpClient, um segundo teste de carga mostrou uma melhoria do desempenho. Não foram comunicados erros e o sistema foi capaz de lidar com um aumento da carga de até 500 pedidos por segundo. O tempo de resposta médio foi reduzido para metade, em comparação com o teste anterior.
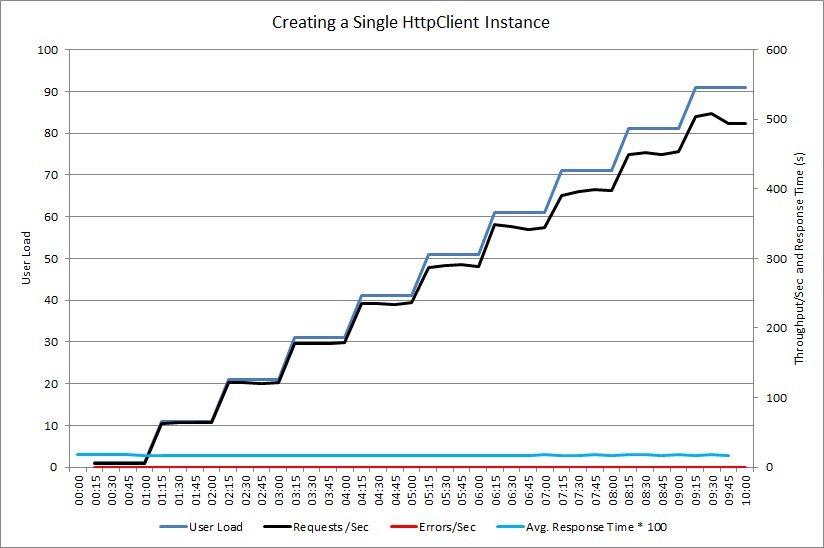
Para comparação, a imagem seguinte mostra a telemetria de rastreio de pilha. Neste momento, o sistema passa a maior parte do tempo a realizar trabalho real, em vez de abrir e fechar sockets.
O gráfico seguinte mostra um teste de carga semelhante com uma instância partilhada do objeto ExpensiveToCreateService. Novamente, o volume de pedidos processados aumenta de acordo com a carga de utilizador, enquanto o tempo de resposta médio permanece baixo.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários