O Processo de Ciência de Dados da Equipe (TDSP) é uma metodologia de ciência de dados ágil e iterativa que você pode usar para fornecer soluções de análise preditiva e aplicativos de IA de forma eficiente. O TDSP ajuda a melhorar a colaboração e a aprendizagem da equipa, sugerindo como as funções da equipa funcionam melhor em conjunto. O TDSP inclui práticas recomendadas e estruturas da Microsoft e de outros líderes do setor para ajudar sua equipe a implementar com sucesso iniciativas de ciência de dados e aproveitar plenamente os benefícios do seu programa de análise.
Este artigo fornece uma visão geral do TDSP e seus principais componentes. Ele apresenta orientações sobre como implementar o TDSP usando ferramentas e infraestrutura da Microsoft. Você pode encontrar recursos mais detalhados ao longo do artigo.
Principais componentes do TDSP
O TDSP tem os seguintes componentes-chave:
- Uma definição do ciclo de vida da ciência de dados
- Uma estrutura de projeto padronizada
- Infraestrutura e recursos recomendados para projetos de ciência de dados
- Ferramentas e utilitários recomendados para a execução do projeto
Ciclo de vida da ciência de dados
O TDSP fornece um ciclo de vida que você pode usar para estruturar o desenvolvimento de seus projetos de ciência de dados. O ciclo de vida descreve todas as etapas que os projetos bem-sucedidos seguem.
Você pode combinar o TDSP baseado em tarefas com outros ciclos de vida de ciência de dados, como o processo padrão entre setores para mineração de dados (CRISP-DM), o processo de descoberta de conhecimento em bancos de dados (KDD) ou outro processo personalizado. A um nível elevado, estas diferentes metodologias têm muito em comum.
Você deve usar esse ciclo de vida se tiver um projeto de ciência de dados que faça parte de um aplicativo inteligente. Aplicativos inteligentes implantam modelos de aprendizado de máquina ou IA para análise preditiva. Você também pode usar esse processo para projetos exploratórios de ciência de dados e projetos de análise improvisados.
O ciclo de vida do TDSP é composto por cinco estágios principais que sua equipe executa iterativamente. Estas etapas incluem:
- Compreensão do negócio
- Aquisição e compreensão de dados
- Modelação
- Implementação
- Aceitação do cliente
Aqui está uma representação visual do ciclo de vida do TDSP:
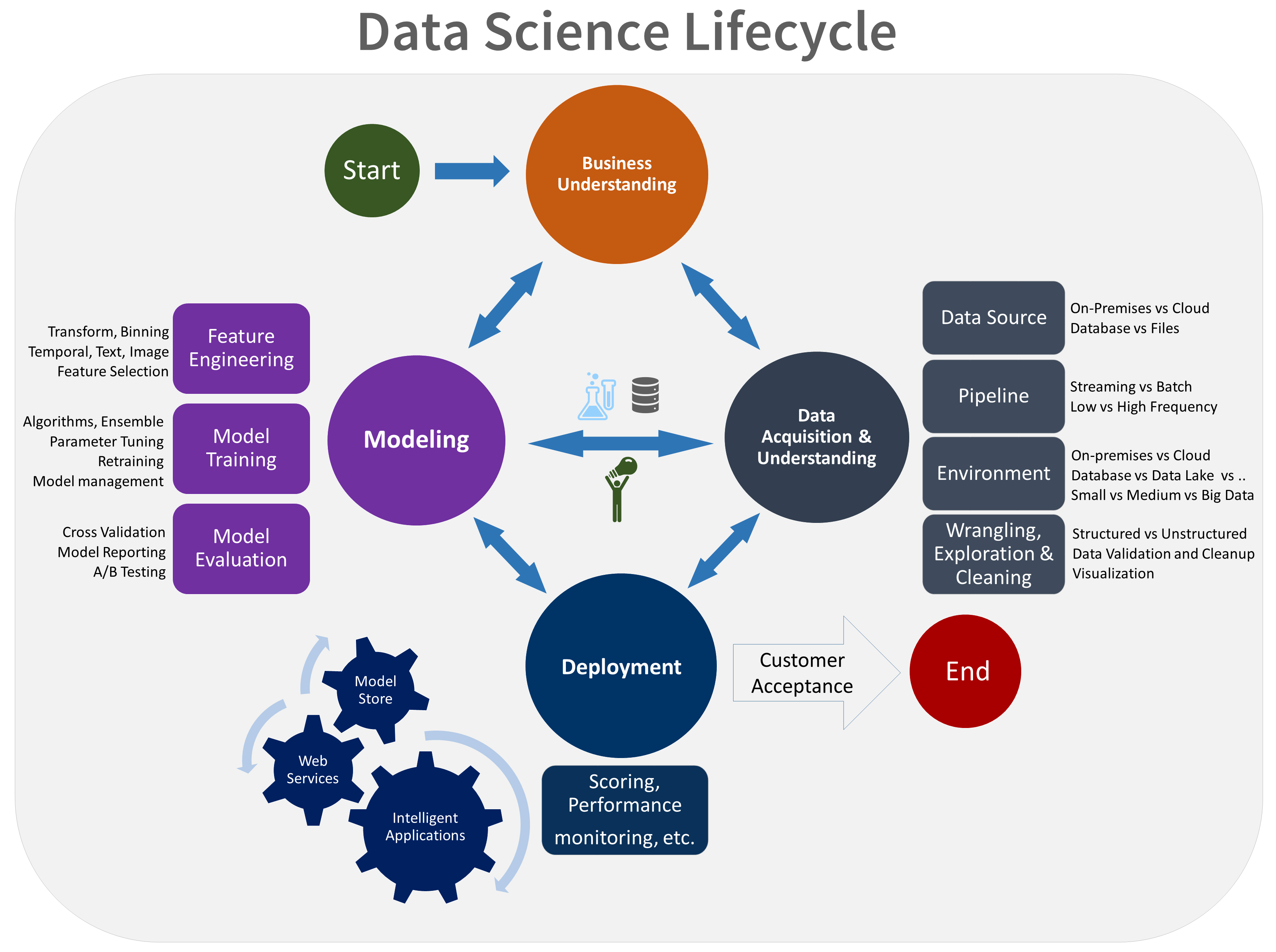
Para obter informações sobre as metas, tarefas e artefatos de documentação para cada estágio, consulte O ciclo de vida do Processo de Ciência de Dados da Equipe.
Essas tarefas e artefatos estão associados a funções de projeto, por exemplo:
- Arquiteto de soluções.
- Gestor de projeto.
- Engenheiro de dados.
- Cientista de dados.
- Desenvolvedor de aplicativos.
- Líder de projeto.
O diagrama a seguir mostra as tarefas (em azul) e artefatos (em verde) associados a cada estágio do ciclo de vida (no eixo horizontal) para essas funções (no eixo vertical).

Estrutura de projeto padronizada
Sua equipe pode usar a infraestrutura do Azure para organizar seus ativos de ciência de dados.
O Azure Machine Learning dá suporte ao MLflow de código aberto. Recomendamos o uso do MLflow para ciência de dados e gerenciamento de projetos de IA. O MLflow foi projetado para gerenciar o ciclo de vida completo do aprendizado de máquina. Ele treina e serve modelos em diferentes plataformas, para que você possa usar um conjunto consistente de ferramentas, independentemente de onde seus experimentos são executados. Você pode usar o MLflow localmente em seu computador, em um destino de computação remoto, em uma máquina virtual ou em uma instância de computação do Machine Learning.
O MLflow consiste em várias funcionalidades principais:
Rastrear experimentos: com o MLflow, você pode acompanhar experimentos, incluindo parâmetros, versões de código, métricas e arquivos de saída. Esse recurso ajuda você a comparar diferentes execuções e gerenciar o processo de experimentação de forma eficiente.
Código do pacote: Ele oferece um formato padronizado para empacotar código de aprendizado de máquina, que inclui dependências e configurações. Esse empacotamento facilita a reprodução de execuções e o compartilhamento de código com outras pessoas.
Gerenciar modelos: o MLflow fornece funcionalidades para gerenciar e versionar modelos. Ele suporta várias estruturas de aprendizado de máquina, para que você possa armazenar, versionar e servir modelos.
Servir e implantar modelos: o MLflow integra recursos de serviço e implantação de modelos, para que você possa implantar facilmente modelos em diversos ambientes.
Registrar modelos: você pode gerenciar o ciclo de vida de um modelo, incluindo controle de versão, transições de estágio e anotações. O MLflow é útil para manter um armazenamento de modelo centralizado em um ambiente colaborativo.
Usar uma API e uma interface do usuário: dentro do Azure, o MLflow é empacotado dentro da API de Aprendizado de Máquina versão 2, para que você possa interagir com o sistema programaticamente. Você pode usar o portal do Azure para interagir com uma interface do usuário.
O MLflow tem como objetivo simplificar e padronizar o processo de desenvolvimento de machine learning, desde a experimentação até a implantação.
O Machine Learning integra-se com repositórios Git, para que possa utilizar serviços compatíveis com Git: GitHub, GitLab, Bitbucket, Azure DevOps ou outro serviço compatível com Git. Além dos ativos já rastreados no Machine Learning, sua equipe pode desenvolver sua própria taxonomia dentro de seu serviço compatível com Git para armazenar outras informações do projeto, como:
- Documentação
- Projeto, por exemplo, o relatório final do projeto
- Relatório de dados, por exemplo, o dicionário de dados ou relatórios de qualidade de dados
- Modelo, por exemplo, relatórios de modelo
- Código
- Preparação de dados
- Desenvolvimento do modelo
- Operacionalização, incluindo segurança e conformidade
Infraestruturas e recursos
O TDSP fornece recomendações para gerenciar análises compartilhadas e infraestrutura de armazenamento, como:
- Sistemas de arquivos na nuvem para armazenar conjuntos de dados
- Bases de Dados
- Clusters de Big Data, por exemplo SQL ou Spark
- Serviços de aprendizagem automática
Você pode colocar a infraestrutura de análise e armazenamento, onde os conjuntos de dados brutos e processados são armazenados, na nuvem ou no local. Esta infraestrutura permite uma análise reprodutível. Evita igualmente a duplicação, que pode conduzir a incoerências e a custos de infraestrutura desnecessários. A infraestrutura tem ferramentas para provisionar os recursos compartilhados, rastreá-los e permitir que cada membro da equipe se conecte a esses recursos com segurança. Também é uma boa prática fazer com que os membros do projeto criem um ambiente de computação consistente. Vários membros da equipe podem então replicar e validar experimentos.
Aqui está um exemplo de uma equipe trabalhando em vários projetos e compartilhando vários componentes de infraestrutura de análise de nuvem:

Ferramentas e utilitários
Na maioria das organizações, é desafiador introduzir processos. A infraestrutura fornece ferramentas para implementar o TDSP e o ciclo de vida ajudam a reduzir as barreiras e aumentar a consistência de sua adoção.
Com o Machine Learning, os cientistas de dados podem aplicar ferramentas de código aberto como parte do pipeline ou fluxo de trabalho da ciência de dados. Dentro do Machine Learning, a Microsoft promove ferramentas de IA responsáveis, o que ajuda a alcançar o Padrão de IA Responsável da Microsoft.
Citações revistas por pares
O TDSP é uma metodologia bem estabelecida usada em todos os compromissos da Microsoft e, portanto, foi documentada e estudada na literatura revisada por pares. Essas citações oferecem uma oportunidade para investigar recursos e aplicativos do TDSP. Consulte a página de visão geral do ciclo de vida para obter uma lista de citações.