Resolver problemas de estrangulamentos de desempenho no Azure Databricks
Nota
Este artigo baseia-se numa biblioteca de open source alojada no GitHub em: https://github.com/mspnp/spark-monitoring.
A biblioteca original suporta o Azure Databricks Runtimes 10.x (Spark 3.2.x) e anterior.
O Databricks contribuiu com uma versão atualizada para suportar o l4jv2 Azure Databricks Runtimes 11.0 (Spark 3.3.x) e superior no ramo em: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Tenha em atenção que a versão 11.0 não é retrocompatível devido aos diferentes sistemas de registo utilizados no Databricks Runtimes. Certifique-se de que utiliza a compilação correta para o Databricks Runtime. A biblioteca e o repositório do GitHub estão no modo de manutenção. Não existem planos para lançamentos adicionais e o suporte para problemas será apenas de melhor esforço. Para quaisquer perguntas adicionais sobre a biblioteca ou o mapa de objetivos para monitorização e registo dos seus ambientes do Azure Databricks, contacte azure-spark-monitoring-help@databricks.com.
Este artigo descreve como utilizar dashboards de monitorização para encontrar estrangulamentos de desempenho em tarefas do Spark no Azure Databricks.
O Azure Databricks é um serviço de análise baseado no Apache Spark que torna mais fácil desenvolver e implementar análises de macrodados rapidamente. A monitorização e resolução de problemas de desempenho é fundamental quando opera cargas de trabalho de produção do Azure Databricks. Para identificar problemas de desempenho comuns, é útil utilizar visualizações de monitorização com base em dados telemétricos.
Pré-requisitos
Para configurar os dashboards do Grafana apresentados neste artigo:
Configure o cluster do Databricks para enviar telemetria para uma área de trabalho do Log Analytics com a Biblioteca de Monitorização do Azure Databricks. Para obter detalhes, veja o readme do GitHub.
Implementar o Grafana numa máquina virtual. Veja Utilizar dashboards para visualizar as métricas do Azure Databricks.
O dashboard do Grafana implementado inclui um conjunto de visualizações de série temporal. Cada gráfico é um gráfico de série temporal de métricas relacionadas com uma tarefa do Apache Spark, as fases da tarefa e as tarefas que compõem cada fase.
Descrição geral do desempenho do Azure Databricks
O Azure Databricks baseia-se no Apache Spark, um sistema de computação distribuído para fins gerais. O código da aplicação, conhecido como trabalho, é executado num cluster do Apache Spark, coordenado pelo gestor de clusters. Em geral, uma tarefa é a unidade de computação de nível mais elevado. Uma tarefa representa a operação completa executada pela aplicação Spark. Uma operação típica inclui ler dados de uma origem, aplicar transformações de dados e escrever os resultados no armazenamento ou noutro destino.
As tarefas são divididas por fases. A tarefa avança pelas fases sequencialmente, o que significa que as fases posteriores têm de aguardar pela conclusão de fases anteriores. As fases contêm grupos de tarefas idênticas que podem ser executadas em paralelo em vários nós do cluster do Spark. As tarefas são a unidade de execução mais granular que está a ocorrer num subconjunto dos dados.
As secções seguintes descrevem algumas visualizações do dashboard que são úteis para a resolução de problemas de desempenho.
Latência da tarefa e fase
A latência da tarefa é a duração da execução de uma tarefa a partir do momento em que é iniciada até ser concluída. É apresentado como percentis de uma execução de trabalho por cluster e ID de aplicação, para permitir a visualização de valores atípicos. O gráfico seguinte mostra um histórico de tarefas em que o percentil 90 atingiu os 50 segundos, apesar de o percentil 50 ter sido consistentemente cerca de 10 segundos.
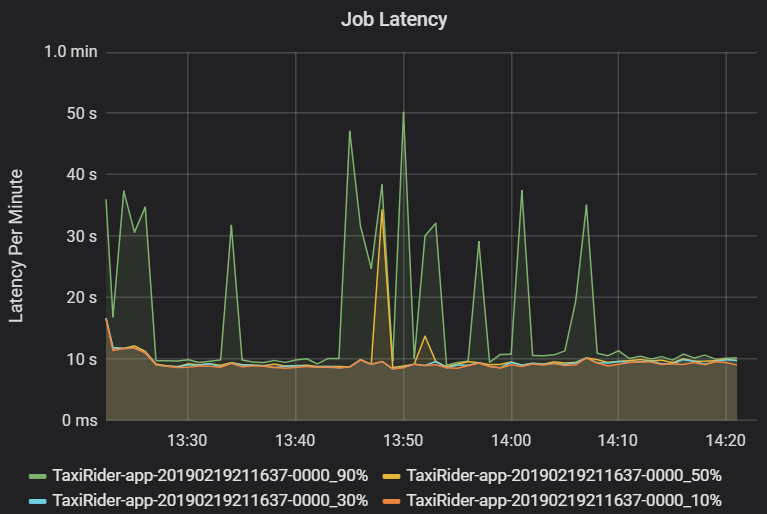
Investigue a execução de trabalhos por cluster e aplicação, procurando picos de latência. Assim que os clusters e as aplicações com latência elevada forem identificados, avance para investigar a latência da fase.
A latência de fase também é apresentada como percentis para permitir a visualização de valores atípicos. A latência de fase é dividida pelo cluster, aplicação e nome da fase. Identifique picos na latência de tarefas no gráfico para determinar que tarefas estão a impedir a conclusão da fase.
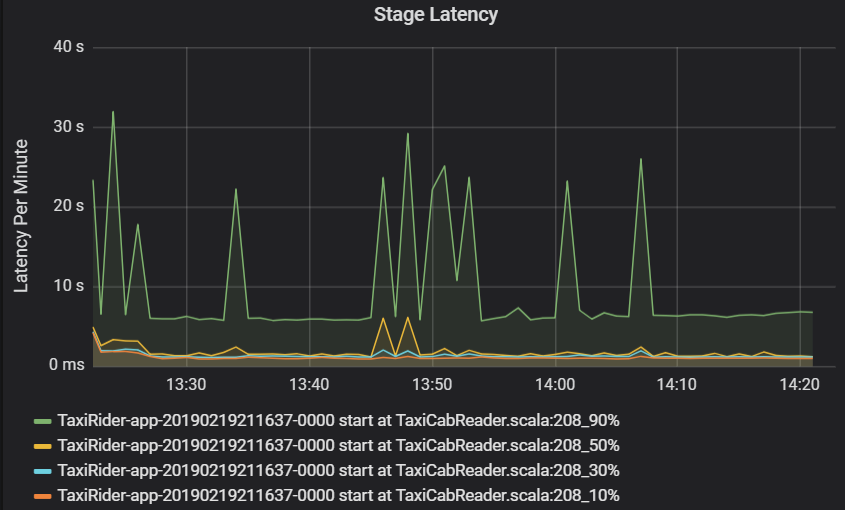
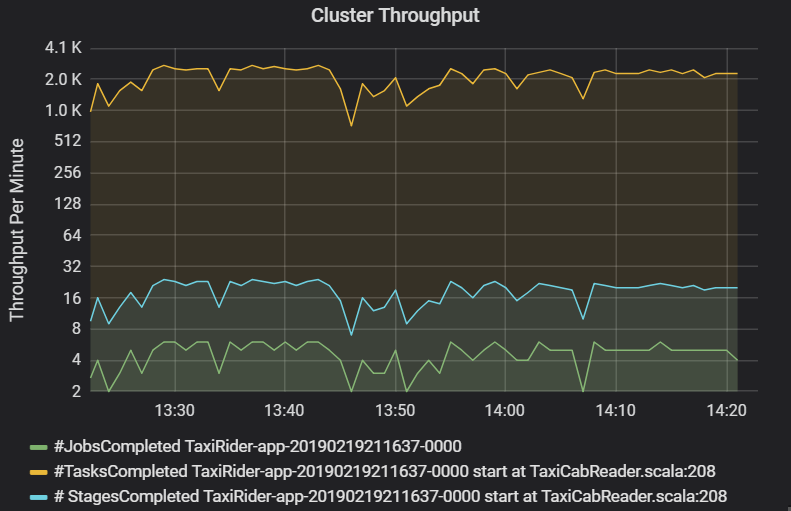
O gráfico de débito do cluster mostra o número de tarefas, fases e tarefas concluídas por minuto. Isto ajuda-o a compreender a carga de trabalho em termos do número relativo de fases e tarefas por trabalho. Aqui, pode ver que o número de tarefas por minuto varia entre 2 e 6, enquanto o número de fases é de cerca de 12 a 24 por minuto.
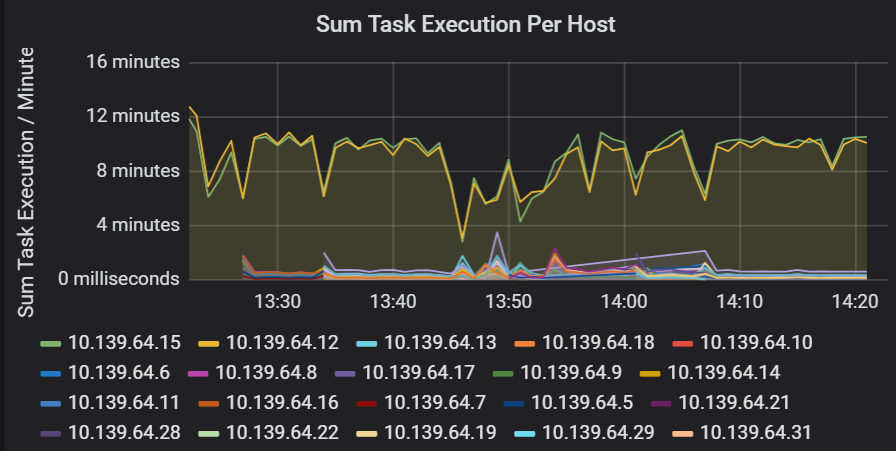
Soma da latência de execução de tarefas
Esta visualização mostra a soma da latência de execução de tarefas por anfitrião em execução num cluster. Utilize este gráfico para detetar tarefas que são executadas lentamente devido ao atraso do anfitrião num cluster ou a uma desalocada de tarefas por executor. No gráfico seguinte, a maioria dos anfitriões tem uma soma de cerca de 30 segundos. No entanto, dois dos anfitriões têm somas que rondam os 10 minutos. Os anfitriões estão lentos ou o número de tarefas por executor é desalocado.
O número de tarefas por executor mostra que são atribuídos a dois executores um número desproporcionado de tarefas, o que causa um estrangulamento.
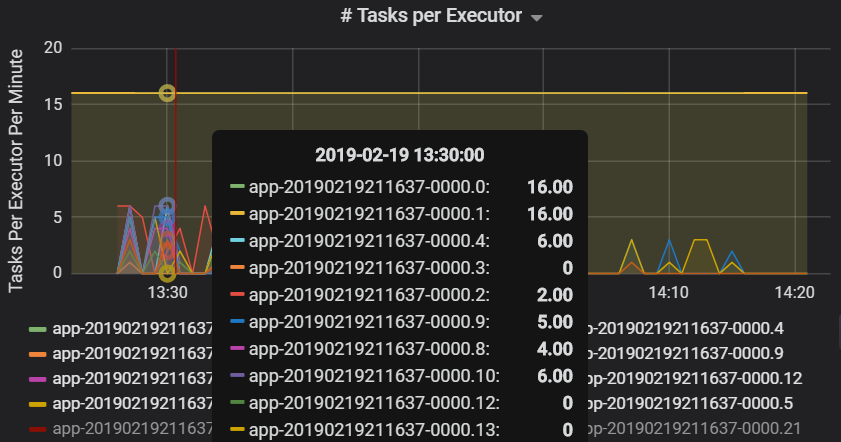
Métricas de tarefas por fase
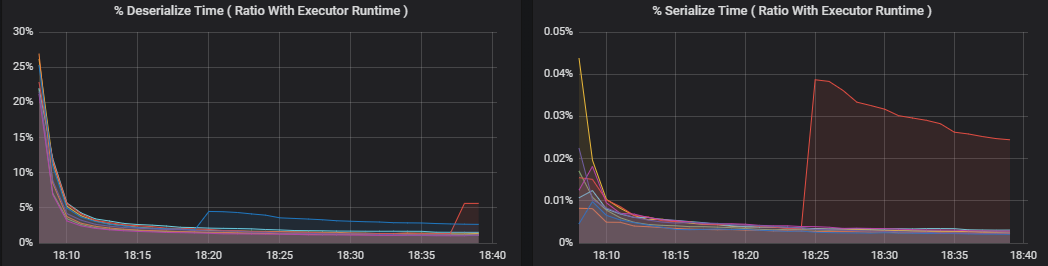
A visualização das métricas de tarefas dá a discriminação dos custos de uma execução de tarefas. Pode utilizá-lo para ver o tempo relativo despendido em tarefas como serialização e desserialização. Estes dados podem mostrar oportunidades de otimização, por exemplo, ao utilizar variáveis de difusão para evitar o envio de dados. As métricas de tarefa também mostram o tamanho dos dados aleatórios de uma tarefa e os tempos de leitura e escrita aleatórios. Se estes valores forem elevados, significa que muitos dados estão a ser movidos pela rede.
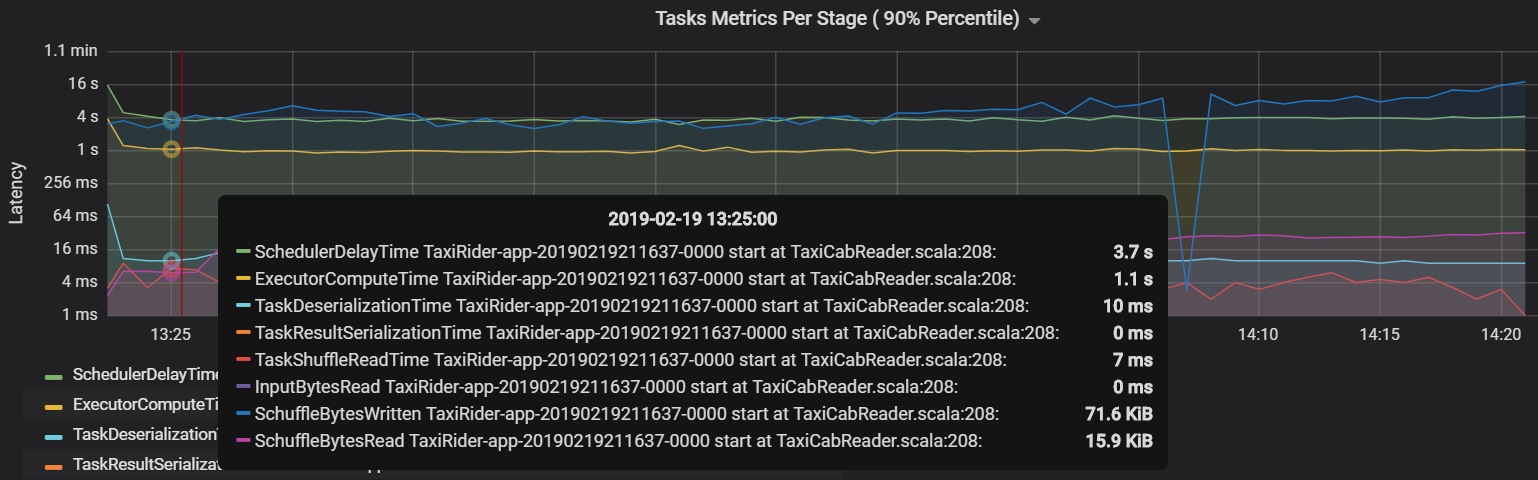
Outra métrica de tarefa é o atraso do agendador, que mede o tempo que demora a agendar uma tarefa. Idealmente, este valor deve ser baixo em comparação com o tempo de computação do executor, que é o tempo gasto na execução da tarefa.
O gráfico seguinte mostra um tempo de atraso do agendador (3,7 s) que excede o tempo de computação do executor (1,1 s). Isto significa que é gasto mais tempo a aguardar que as tarefas sejam agendadas do que a realizar o trabalho real.
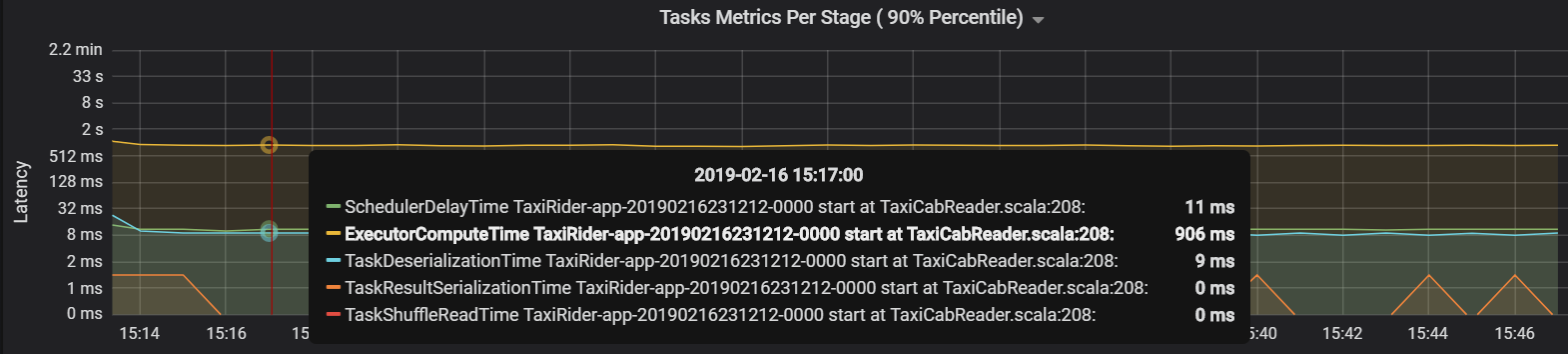
Neste caso, o problema foi causado por ter demasiadas partições, o que causou muita sobrecarga. Reduzir o número de partições diminuiu o tempo de atraso do agendador. O gráfico seguinte mostra que a maior parte do tempo é despendido a executar a tarefa.
Débito e latência de transmissão em fluxo
O débito de transmissão em fluxo está diretamente relacionado com a transmissão em fluxo estruturada. Existem duas métricas importantes associadas ao débito de transmissão em fluxo: linhas de entrada por segundo e linhas processadas por segundo. Se as linhas de entrada por segundo ultrapassarem as linhas processadas por segundo, significa que o sistema de processamento de fluxos está a ficar para trás. Além disso, se os dados de entrada forem provenientes dos Hubs de Eventos ou do Kafka, as linhas de entrada por segundo devem acompanhar a taxa de ingestão de dados no front-end.
Duas tarefas podem ter um débito de cluster semelhante, mas métricas de transmissão em fluxo muito diferentes. A seguinte captura de ecrã mostra duas cargas de trabalho diferentes. São semelhantes em termos de débito de cluster (trabalhos, fases e tarefas por minuto). Mas a segunda execução processa 12 000 linhas/seg versus 4000 linhas/seg.
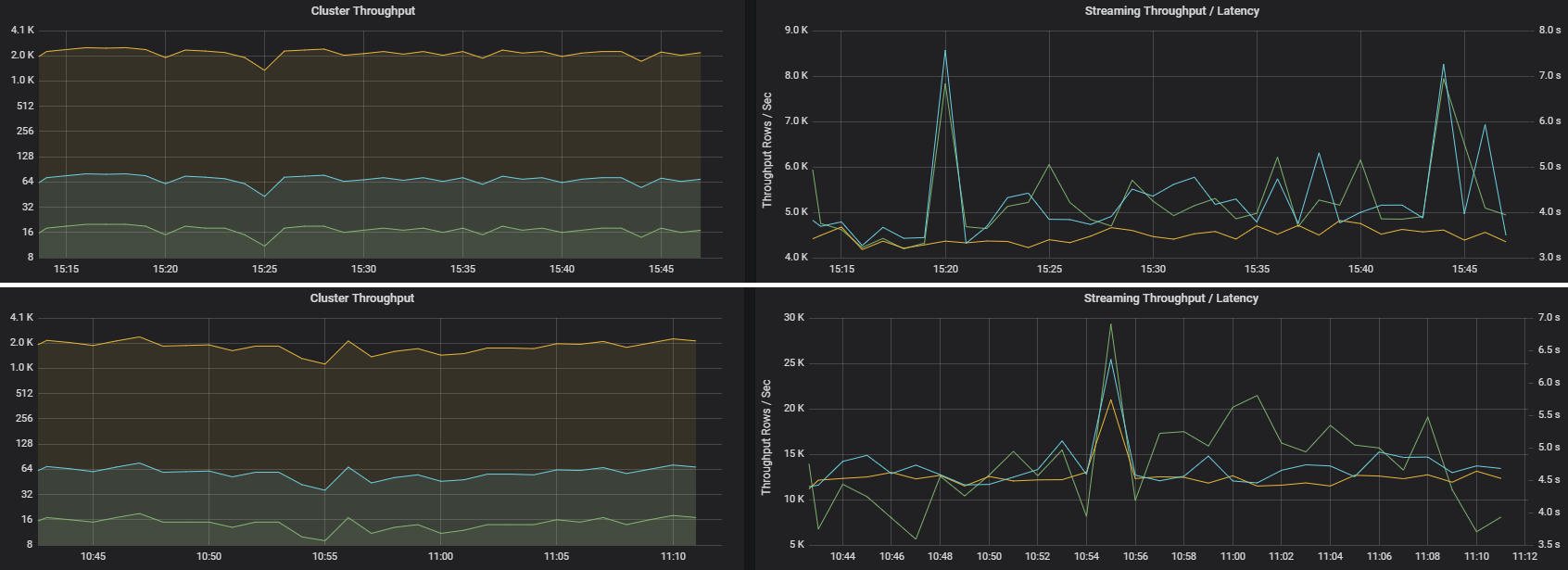
O débito de transmissão em fluxo é, muitas vezes, uma métrica empresarial melhor do que o débito do cluster, porque mede o número de registos de dados que são processados.
Consumo de recursos por executor
Estas métricas ajudam a compreender o trabalho que cada executor executa.
As métricas de percentagem medem quanto tempo um executor gasta em várias coisas, expressas como uma proporção de tempo gasto em comparação com o tempo de computação geral do executor. As métricas são:
- % Serializar tempo
- % Anular a serialização do tempo
- % de tempo do executor da CPU
- % de tempo JVM
Estas visualizações mostram o quanto cada uma destas métricas contribui para o processamento geral do executor.
As métricas aleatórias são métricas relacionadas com a aleatorização de dados nos executores.
- E/S aleatorização
- Baralhar memória
- Utilização do sistema de ficheiros
- Utilização do disco
Estrangulamentos de desempenho comuns
Dois estrangulamentos de desempenho comuns no Spark são os stragglers de tarefas e uma contagem de partições aleatórias não ideal.
Stragglers de tarefas
As fases de um trabalho são executadas sequencialmente, com as fases anteriores a bloquear as posteriores. Se uma tarefa executar uma partição de redistribuição mais lentamente do que outras tarefas, todas as tarefas no cluster têm de aguardar que a tarefa lenta seja atualizada antes de a fase poder terminar. Isto pode acontecer pelos seguintes motivos:
Um anfitrião ou grupo de anfitriões está lento. Sintomas: latência de tarefa, fase ou trabalho elevada e débito de cluster baixo. A soma das latências de tarefas por anfitrião não será distribuída uniformemente. No entanto, o consumo de recursos será distribuído uniformemente pelos executores.
As tarefas têm uma agregação dispendiosa para executar (distorção de dados). Sintomas: latência de tarefas elevada, latência de fase elevada, latência de trabalho elevada ou débito de cluster baixo, mas a soma das latências por anfitrião é distribuída uniformemente. O consumo de recursos será distribuído uniformemente pelos executores.
Se as partições tiverem um tamanho desigual, uma partição maior poderá causar uma execução de tarefas desequilibrada (distorção da partição). Sintomas: o consumo de recursos do executor é elevado em comparação com outros executores em execução no cluster. Todas as tarefas em execução nesse executor serão executadas lentamente e manterão a execução da fase no pipeline. Diz-se que estas fases são barreiras de palco.
Contagem de partições aleatórias não ideal
Durante uma consulta de transmissão em fluxo estruturada, a atribuição de uma tarefa a um executor é uma operação de utilização intensiva de recursos para o cluster. Se os dados aleatórios não forem o tamanho ideal, a quantidade de atraso de uma tarefa afetará negativamente o débito e a latência. Se existirem poucas partições, os núcleos no cluster serão subutilizados, o que pode resultar na ineficiência do processamento. Por outro lado, se existirem demasiadas partições, existe uma grande sobrecarga de gestão para um pequeno número de tarefas.
Utilize as métricas de consumo de recursos para resolver problemas de distorção de partições e desalojamento de executores no cluster. Se uma partição for distorcida, os recursos do executor serão elevados em comparação com outros executadores em execução no cluster.
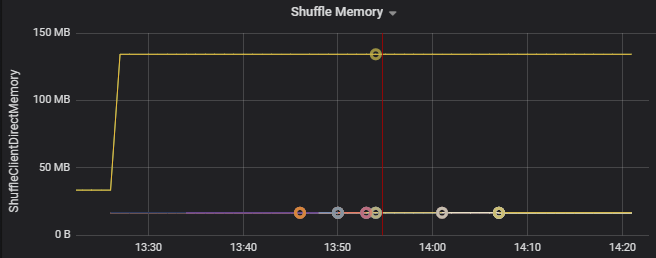
Por exemplo, o gráfico seguinte mostra que a memória utilizada ao alternar nos dois primeiros executores é 90X maior do que os outros executadores:
Passos seguintes
- Monitorizar o Azure Databricks numa Área de Trabalho do Log Analytics do Azure
- Percurso de aprendizagem: Criar e operar soluções de machine learning com o Azure Databricks
- Documentação do Azure Databricks
- Descrição geral do Azure Monitor
Recursos relacionados
- Monitorizar o Azure Databricks
- Send Azure Databricks application logs to Azure Monitor (Enviar registos de aplicações do Azure Databricks para o Azure Monitor)
- Use dashboards to visualize Azure Databricks metrics (Utilizar dashboards para visualizar as métricas do Azure Databricks)
- Arquitetura de análise moderna com o Azure Databricks
- Pipelines de ingestão, ETL e processamento de fluxos com o Azure Databricks
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários