Estilo de arquitetura de computação grande
O termo big compute descreve cargas de trabalho de grande escala que exigem um grande número de núcleos, muitas vezes numerando centenas ou milhares. Os cenários incluem renderização de imagens, dinâmica de fluidos, modelagem de risco financeiro, exploração de petróleo, projeto de medicamentos e análise de estresse de engenharia, entre outros.
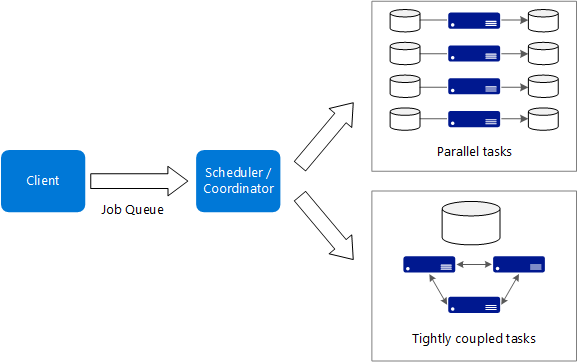
Aqui estão algumas características típicas de grandes aplicações de computação:
- O trabalho pode ser dividido em tarefas discretas, que podem ser executadas em vários núcleos simultaneamente.
- Cada tarefa é finita. Ele pega alguma entrada, faz algum processamento e produz saída. Todo o aplicativo é executado por uma quantidade finita de tempo (minutos a dias). Um padrão comum é provisionar um grande número de núcleos em um burst e, em seguida, girar para baixo para zero assim que o aplicativo for concluído.
- O aplicativo não precisa ficar 24 horas por dia, 7 dias por semana. No entanto, o sistema deve lidar com falhas de nó ou falhas de aplicativo.
- Para algumas aplicações, as tarefas são independentes e podem ser executadas em paralelo. Em outros casos, as tarefas estão intimamente ligadas, o que significa que devem interagir ou trocar resultados intermediários. Nesse caso, considere o uso de tecnologias de rede de alta velocidade, como InfiniBand e RDMA (acesso remoto direto à memória).
- Dependendo da sua carga de trabalho, você pode usar tamanhos de VM de computação intensiva (H16r, H16mr e A9).
Quando usar esta arquitetura
- Operações computacionais intensivas, como simulação e processamento de números.
- Simulações que são computacionalmente intensivas e devem ser divididas entre CPUs em vários computadores (10-1000s).
- Simulações que exigem muita memória para um computador e devem ser divididas em vários computadores.
- Cálculos de longa duração que levariam muito tempo para serem concluídos em um único computador.
- Cálculos menores que devem ser executados 100s ou 1000s de vezes, como simulações de Monte Carlo.
Benefícios
- Alto desempenho com processamento "embaraçosamente paralelo".
- Pode aproveitar centenas ou milhares de núcleos de computador para resolver grandes problemas mais rapidamente.
- Acesso a hardware especializado de alto desempenho, com redes InfiniBand dedicadas de alta velocidade.
- Você pode provisionar VMs conforme necessário para fazer o trabalho e, em seguida, derrubá-las.
Desafios
- Gerenciando a infraestrutura de VM.
- Gerenciando o volume de processamento de números
- Provisionamento de milhares de núcleos em tempo hábil.
- Para tarefas firmemente acopladas, adicionar mais núcleos pode ter retornos decrescentes. Pode ser necessário experimentar para encontrar o número ideal de núcleos.
Big compute usando o Azure Batch
O Azure Batch é um serviço gerenciado para executar aplicativos de computação de alto desempenho (HPC) em grande escala.
Usando o Lote do Azure, você configura um pool de VMs e carrega os aplicativos e arquivos de dados. Em seguida, o serviço em lote provisiona as VMs, atribui tarefas às VMs, executa as tarefas e monitora o progresso. O lote pode dimensionar automaticamente as VMs em resposta à carga de trabalho. O Batch também fornece agendamento de tarefas.
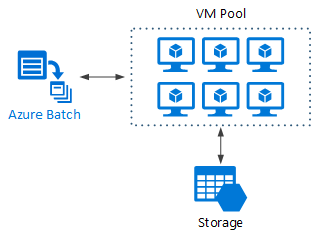
Grande computação em execução em máquinas virtuais
Você pode usar o Microsoft HPC Pack para administrar um cluster de VMs e agendar e monitorar trabalhos de HPC. Com essa abordagem, você deve provisionar e gerenciar as VMs e a infraestrutura de rede. Considere essa abordagem se você tiver cargas de trabalho HPC existentes e quiser mover parte ou toda ela para o Azure. Você pode mover todo o cluster HPC para o Azure ou pode manter seu cluster HPC local, mas usar o Azure para capacidade de intermitência. Para obter mais informações, consulte Soluções em lote e HPC para cargas de trabalho de computação em grande escala.
Pacote HPC implantado no Azure
Nesse cenário, o cluster HPC é criado inteiramente no Azure.

O nó principal fornece serviços de gerenciamento e agendamento de tarefas para o cluster. Para tarefas firmemente acopladas, use uma rede RDMA que forneça comunicação de largura de banda muito alta e baixa latência entre VMs. Para obter mais informações, consulte Implantar um cluster HPC Pack 2016 no Azure.
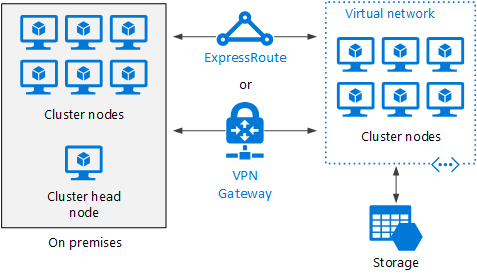
Burst um cluster HPC para o Azure
Nesse cenário, uma organização está executando o HPC Pack local e usa VMs do Azure para capacidade de intermitência. O nó principal do cluster está no local. A Rota Expressa ou o Gateway VPN conecta a rede local à VNet do Azure.