As arquiteturas de macrodados servem para processar a ingestão, o processamento e a análise de dados que sejam demasiado grandes ou complexos para os sistemas de base de dados tradicionais.

Normalmente, as soluções de macrodados envolvem um ou mais dos seguintes tipos de cargas de trabalho:
- Processamento em lotes de origens de macrodados inativas.
- Processamento em tempo real de macrodados em movimento.
- Exploração interativa de macrodados.
- Análise preditiva e machine learning.
A maioria das arquiteturas de macrodados incluem alguns ou todos os componentes abaixo:
Origens de dados: todas as soluções de macrodados começam com uma ou mais origens de dados. Exemplos incluem:
- Arquivos de dados de armazenamento, como bases de dados relacionais.
- Ficheiros estáticos produzidos por aplicações, como ficheiros de registo de servidores Web.
- Origens de dados em tempo real, como dispositivos IoT.
Armazenamento de dados: os dados para as operações de processamento em lotes são, normalmente, armazenados num arquivo de ficheiros distribuído que pode incluir elevados volumes de ficheiros grandes em diferentes formatos. Este tipo de arquivo é, muitas vezes, conhecido como data lake. As opções para implementar este armazenamento incluem contentores do Azure Data Lake Store ou contentores de blobs no Armazenamento do Azure.
Processamento em lotes: uma vez que os conjuntos de dados são tão grandes, muitas vezes, as soluções de macrodados têm processar os ficheiros de dados com trabalhos de lote de execução longa para filtrar, agregar e preparar os dados para análise. Normalmente, estes trabalhos envolvem ler os ficheiros de origem, processá-los e escrever a saída em ficheiros novos. As opções incluem executar trabalhos de U-SQL no Azure Data Lake Analytics, utilizar trabalhos de Hive, Pig ou Map/Reduce personalizados num cluster Hadoop do HDInsight ou utilizar programas de Java, Scala ou Python num cluster do HDInsight Spark.
Ingestão de mensagens em tempo real: se a solução incluir origens em tempo real, a arquitetura tem de ter uma forma de capturar e armazenar as mensagens em tempo real para o processamento de fluxos. Pode ser um arquivo de dados simples, no qual as mensagens recebidas são largadas numa pasta para processamento. No entanto, muitas soluções precisam que o arquivo de ingestão de mensagens funcione como memória intermédia para as mensagens e que suporte o processamento de escalamento horizontal, a entrega fiável e outras semânticas de colocação de mensagens em fila. As opções incluem os Hubs de Eventos do Azure, os Hubs IoT do Azure e o Kafka.
Processamento em fluxo: após a captura das mensagens em tempo real, a solução tem de processá-las ao filtrar, agregar e preparar os dados para análise. Os dados de fluxos processados são, depois, escritos num sink de saída. O Azure Stream Analytics disponibiliza um serviço de processamento em fluxo gerido e baseado em consultas SQL de execução permanente que funcionam em fluxos independentes. Você também pode usar tecnologias de streaming Apache de código aberto, como o Spark Streaming, em um cluster HDInsight.
Arquivo de dados analíticos: muitas soluções de macrodados preparam os dados para análise e, em seguida, disponibilizam os dados processados num formato estruturado que pode ser consultado com ferramentas analíticas. O arquivo de dados analíticos utilizado para disponibilizar estas consultas pode ser um armazém de dados relacional do tipo Kimball, conforme se vê na maioria das soluções de business intelligence (BI) tradicionais. Em alternativa, os dados podem ser apresentados através de uma tecnologia NoSQL de baixa latência, como o HBase, ou de uma base de dados interativa Hive que fornece uma abstração de metadados em ficheiros de dados no arquivo de dados distribuído. O Azure Synapse Analytics fornece um serviço gerido para armazéns de dados com base na cloud e de grande escala. O HDInsight suporta o Interactive Hive, o HBase e o Spark SQL, que também podem ser utilizados para disponibilizar os dados para análise.
Análises e relatórios: o objetivo da maioria das soluções de macrodados é proporcionar informações sobre os dados através de análises e relatórios. Para permitir aos utilizadores analisar os dados, a arquitetura pode incluir uma camada de modelação de dados, como um cubo OLAP multidimensional ou um modelo de dados em tabela no Azure Analysis Services. Também pode suportar business intelligence de gestão personalizada através da utilização das tecnologias de modelação e visualização no Microsoft Power BI ou no Microsoft Excel. As análises e os relatórios também podem assumir a forma de exploração de dados interativa por parte de cientistas de dados ou analistas de dados. Nestes cenários, muitos serviços do Azure suportam blocos de notas analíticos, como o Jupyter, que permitem a estes utilizadores tirar partido das respetivas competências em Python ou R. Na exploração de dados em grande escala, pode utilizar o Microsoft R Server, seja autónomo ou com o Spark.
Orquestração: a maioria das soluções de macrodados consiste em operações de processamento de dados repetidas, encapsuladas em fluxos de trabalho, que transformam os dados de origem, movem os dados entre várias origens e sinks, carregam os dados processados para um arquivo de dados analíticos ou enviam os resultados diretamente para um relatório ou dashboard. Para automatizar estes fluxos de trabalho, pode utilizar uma tecnologia de orquestração como o Azure Data Factory ou o Apache Oozie e o Sqoop.
O Azure inclui vários serviços que podem ser utilizados numa arquitetura de macrodados. Inserem-se em aproximadamente duas categorias:
- Serviços gerenciados, incluindo Azure Data Lake Store, Azure Data Lake Analytics, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub e Azure Data Factory.
- Tecnologias de código aberto baseadas na plataforma Apache Hadoop, incluindo HDFS, HBase, Hive, Spark, Oozie, Sqoop e Kafka. Estas tecnologias estão disponíveis no Azure no serviço Azure HDInsight.
Estas opções não são mutuamente exclusivas e muitas soluções combinam tecnologias de código aberto e serviços do Azure.
Quando utilizar esta arquitetura
Considere este estilo de arquitetura se tiver de:
- Armazenar e processar dados em volumes demasiados grandes para uma base de dados tradicional.
- Transformar dados não estruturados para análises e relatórios.
- Capturar, processar e analisar fluxos independentes de dados em tempo real ou com baixa latência.
- Use o Azure Machine Learning ou os Serviços Cognitivos do Azure.
Benefícios
- Opções tecnológicas. Pode combinar e serviços geridos do Azure e tecnologias Apache em clusters do HDInsight, para aproveitar as competências atuais ou os investimentos em tecnologia.
- Desempenho através de paralelismo. As soluções de macrodados tiram partido do paralelismo, permitindo soluções de elevado desempenho que se dimensionam para grandes volumes de dados.
- Dimensionamento elástico. Todos os componentes na arquitetura de macrodados suportam o aprovisionamento de escalamento horizontal, para que possa ajustar a sua solução a cargas de trabalho pequenas ou grandes e pagar apenas pelos recursos que utilizar.
- Interoperabilidade com soluções existentes. Os componentes da arquitetura de macrodados também são utilizados para processamento de IoT e soluções de BI empresarial, que lhe permitem criar uma solução integrada em várias cargas de trabalho de dados.
Desafios
- Complexidade. As soluções de macrodados podem ser extremamente complexas, com numerosos componentes para processar a ingestão de dados de várias origens de dados. Criar, testar e resolver problemas de processos de macrodados pode ser desafiante. Além disso, poderá haver um grande número de definições de configuração em vários sistemas que têm de ser utilizadas para otimizar o desempenho.
- Competências. Muitas tecnologias de macrodados são altamente especializadas e utilizam estruturas e linguagens que não são típicas nas arquiteturas de aplicações mais comuns. Por outro lado, as tecnologias de macrodados estão a desenvolver novas APIs que se baseiam em linguagens mais estabelecidas. Por exemplo, a linguagem U-SQL no Azure Data Lake Analytics baseia-se numa combinação de Transact-SQL e c#. Da mesma forma, APIs baseadas em SQL estão disponíveis para Hive, HBase e Spark.
- Maturidade tecnológica. Muitas das tecnologias utilizadas para macrodados estão a evoluir. Ao passo que as principais tecnologias Hadoop, como o Hive e o Pig, estabilizaram, as tecnologias emergentes, como o Spark, apresentam enormes alterações e melhorias a cada nova versão. Os serviços geridos como o Azure Data Lake Analytics e o Azure Data Factory são relativamente recentes quando comparados com outros serviços do Azure e é provável que evoluam ao longo do tempo.
- Segurança. Normalmente, as soluções de macrodados dependem do armazenamento de todos os dados estáticos num data lake centralizado. Proteger o acesso a estes dados pode ser desafiante, especialmente quando os dados têm de ser ingeridos e consumidos por várias aplicações e plataformas.
Melhores práticas
Tirar partido do paralelismo. A maioria das tecnologias de processamento de macrodados distribuem a carga de trabalho em várias unidades de processamento. Para isso, os ficheiros de dados estáticos têm de ser criados e armazenados num formato divisível. Os sistemas de ficheiros distribuídos, como, por exemplo, o HDFS, podem otimizar o desempenho de leitura e escrita e o processamento propriamente dito é realizado por múltiplos nós do cluster em paralelo, o que reduz os tempos globais dos trabalhos.
Dados de partição. O processamento em lote geralmente acontece em uma programação recorrente — por exemplo, semanal ou mensal. Crie partições de ficheiros de dados e de estruturas de dados, como tabelas, com base em períodos de tempo que correspondam à agenda de processamento. Desta forma, a ingestão de dados e o agendamento de trabalhos são simplificados, o que permite resolver falhas mais facilmente. Além disso, as tabelas de partições que são utilizadas no Hive, no U-SQL ou nas consultas SQL podem melhorar significativamente o desempenho das consultas.
Aplicar semântica de esquema na leitura. O uso de um data lake permite combinar o armazenamento de arquivos em vários formatos, sejam eles estruturados, semiestruturados ou não estruturados. Utilize a semântica de esquema na leitura, que projeta um esquema nos dados quando estes são processados e não quando são armazenados. Esta opção acrescenta flexibilidade à solução e impede estrangulamentos durante a ingestão de dados provocados pela validação de dados e a verificação de tipo.
Processar dados no local. as soluções de BI tradicionais utilizam, frequentemente, um processo de extração, transformação e carregamento (ETL) para mover dados para um armazém de dados. Com dados de volumes maiores e uma maior variedade de formatos, as soluções de macrodados, geralmente, utilizam variações de ETL, como transformação, extração e carregamento (TEL). Com esta abordagem, os dados são processados no arquivo de dados distribuído, que os transforma na estrutura necessária antes de os mover para um arquivo de dados analíticos.
Equilibrar os custos de utilização e de tempo. Nos trabalhos de processamento em lotes, é importante ter em conta dois fatores - o custo por unidade dos nós de computação e o custo por minuto relativo à utilização desses nós para concluir os trabalhos. Por exemplo, um trabalho de lote pode demorar horas oito com quatro nós de cluster. No entanto, poderá dar-se o caso de o trabalho utilizar os quatro nós apenas durante as duas primeiras horas e, depois disso, só são precisos dois nós. Nesse caso, executar o trabalho inteiro em dois nós aumentaria o tempo total, mas não o duplicaria, pelo que o custo total seria inferior. Em alguns cenários de negócios, um tempo de processamento mais longo pode ser preferível ao custo mais alto do uso de recursos de cluster subutilizados.
Recursos de cluster separados. Quando implementa clusters do HDInsight, obtém, normalmente, um desempenho superior se aprovisionar recursos de cluster separados para cada tipo de carga de trabalho. Por exemplo, apesar de os clusters do Spark incluírem o Hive, se tiver de fazer processamentos exaustivos com o Hive e o Spark, deve considerar implementar clusters do Spark e do Hadoop dedicados em separado. Da mesma forma, se estiver a utilizar o HBase e o Storm para processamento de fluxos de baixa latência e o Hive para o processamento de lotes, considere implementar clusters separados para o Storm, o HBase e o Hadoop.
Orquestrar a ingestão de dados. Em alguns casos, as aplicações empresariais já existentes podem escrever ficheiros de dados para processamento de lotes diretamente em contentores de blobs de armazenamento do Azure, onde podem ser consumidos pelo HDInsight ou o Azure Data Lake Analytics. No entanto, muitas vezes, terá de orquestrar a ingestão de dados de origens no local ou externas no data lake. Utilize um fluxo de trabalho ou um pipeline de orquestração, como os que o Azure Data Factory ou o Oozie suportam, para fazer a orquestração de forma previsível e gerida centralmente.
Limpar os dados confidenciais no início. O fluxo de trabalho de ingestão de dados deve limpar os dados confidenciais no início do processo, para evitar armazená-los no data lake.
Arquitetura de IoT
A Internet das Coisas (IoT) é um subconjunto especializado de soluções de big data. O diagrama seguinte mostra uma arquitetura lógica possível para IoT. O diagrama realça os componentes de transmissão em fluxo de eventos da arquitetura.
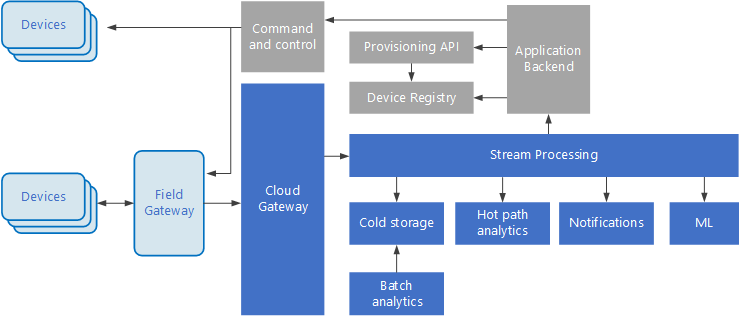
O gateway de cloud ingere os eventos de dispositivos no limite da cloud, através de um sistema de mensagens fiável de baixa latência.
Os dispositivos podem enviar eventos diretamente para o gateway de cloud ou através de um gateway de campo. Um gateway de campo é um software ou dispositivo especializado, normalmente na mesma localização dos dispositivos, que recebe eventos e os reencaminha para o gateway de cloud. O gateway de campo também pode pré-processar os eventos de dispositivos não processados, ao executar funções como a filtragem, a agregação ou a transformação de protocolos.
Após a ingestão, os eventos passam por um ou mais processadores de fluxos que podem encaminhar os dados (por exemplo, para o armazenamento) ou realizar análises e outros processamentos.
Seguem-se alguns tipos comuns de processamento. (Esta lista não é de todo exaustiva.)
Escrita de dados de eventos no armazenamento amovível, para arquivo ou análise de lotes.
Análise de caminhos de acesso frequente, mediante a análise do fluxo de eventos (quase) em tempo real, para detetar anomalias, reconhecer padrões ao longo de períodos de tempo sucessivos ou acionar alertas quando ocorre uma condição específica no fluxo.
Processamento de tipos especiais de mensagens sem ser de telemetria provenientes dos dispositivos, como notificações e alarmes.
Aprendizagem automática (Machine Learning).
As caixas apresentadas com um sombreado cinzento mostram os componentes de um sistema de IoT que não estão diretamente relacionados com a transmissão em fluxo de eventos, mas são incluídos aqui a fim de proporcionar uma perspetiva completa.
O registo de dispositivos é uma base de dados de dispositivos aprovisionados, incluindo os IDs dos dispositivos e, normalmente, os metadados dos dispositivos, como a localização.
A API de aprovisionamento é uma interface externa comum para aprovisionar e registar novos dispositivos.
Algumas soluções de IoT permitem o envio de mensagens de comando e controlo para os dispositivos.
Esta secção apresentou uma vista muito abrangente da IoT e existem muitas pequenas nuances e desafios a ter em consideração. Para ter acesso a um debate e uma arquitetura de referência mais detalhados, veja Arquitetura de referência do Microsoft Azure IoT (PDF para transferência).
Próximos passos
- Saiba mais sobre arquiteturas de big data.
- Saiba mais sobre o design da arquitetura da Internet das Coisas (IoT).