Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Os sistemas empresariais modernos gerem volumes cada vez maiores de dados heterogéneos. Essa heterogeneidade significa que um único armazenamento de dados geralmente não é a melhor abordagem. Em vez disso, geralmente é melhor armazenar diferentes tipos de dados em diferentes armazenamentos de dados, cada um focado em uma carga de trabalho ou padrão de uso específico. O termo persistência poliglota é usado para descrever soluções que usam uma combinação de tecnologias de armazenamento de dados. Portanto, é importante entender os principais modelos de armazenamento e suas compensações.
Selecionar o armazenamento de dados certo para suas necessidades é uma decisão de design fundamental. Há literalmente centenas de implementações para escolher entre bancos de dados SQL e NoSQL. Os armazenamentos de dados geralmente são categorizados de acordo com a forma como estruturam os dados e os tipos de operações às quais dão suporte. Este artigo descreve vários dos modelos de armazenamento mais comuns. Observe que uma determinada tecnologia de armazenamento de dados pode suportar vários modelos de armazenamento. Por exemplo, um sistema de gerenciamento de banco de dados relacional (RDBMS) também pode suportar armazenamento de chave/valor ou gráfico. Na verdade, há uma tendência geral para o chamado suporte multimodelo, onde um único sistema de banco de dados suporta vários modelos. Mas ainda é útil entender os diferentes modelos em alto nível.
Nem todos os armazenamentos de dados em uma determinada categoria fornecem o mesmo conjunto de recursos. A maioria dos armazenamentos de dados fornece funcionalidade do lado do servidor para consultar e processar dados. Às vezes, essa funcionalidade é incorporada ao mecanismo de armazenamento de dados. Em outros casos, os recursos de armazenamento e processamento de dados são separados, e pode haver várias opções de processamento e análise. Os armazenamentos de dados também suportam diferentes interfaces programáticas e de gerenciamento.
Geralmente, você deve começar considerando qual modelo de armazenamento é mais adequado às suas necessidades. Em seguida, considere um armazenamento de dados específico dentro dessa categoria, com base em fatores como conjunto de recursos, custo e facilidade de gerenciamento.
Observação
Saiba mais sobre como identificar e revisar seus requisitos de serviço de dados para adoção de nuvem no Microsoft Cloud Adoption Framework for Azure. Da mesma forma, você também pode aprender sobre ao selecionar ferramentas e serviços de armazenamento.
Sistemas de gerenciamento de banco de dados relacional
Os bancos de dados relacionais organizam os dados como uma série de tabelas bidimensionais com linhas e colunas. A maioria dos fornecedores fornece um dialeto da linguagem de consulta estruturada (SQL) para recuperar e gerenciar dados. Um RDBMS normalmente implementa um mecanismo transacionalmente consistente que está em conformidade com o modelo ACID (Atomic, Consistent, Isolated, Durable) para atualizar informações.
Um RDBMS normalmente suporta um modelo de esquema na gravação, onde a estrutura de dados é definida antecipadamente e todas as operações de leitura ou gravação devem usar o esquema.
Esse modelo é muito útil quando garantias fortes de consistência são importantes — onde todas as alterações são atômicas e as transações sempre deixam os dados em um estado consistente. No entanto, um RDBMS geralmente não pode ser dimensionado horizontalmente sem fragmentar os dados de alguma forma. Além disso, os dados em um RDBMS devem ser normalizados, o que não é apropriado para todos os conjuntos de dados.
Serviços do Azure
- Banco de Dados SQL do Azure | (Linha de Base de Segurança)
- Banco de Dados do Azure para MySQL | (Linha de Base de Segurança)
- Banco de Dados do Azure para PostgreSQL | (Linha de Base de Segurança)
Carga de trabalho
- Os registos são frequentemente criados e atualizados.
- Várias operações devem ser concluídas em uma única transação.
- As relações são impostas usando restrições de banco de dados.
- Os índices são usados para otimizar o desempenho da consulta.
Tipo de dados
- Os dados são altamente normalizados.
- Os esquemas de banco de dados são necessários e impostos.
- Relações muitos-para-muitos entre entidades de dados no banco de dados.
- As restrições são definidas no esquema e impostas a quaisquer dados no banco de dados.
- Os dados exigem alta integridade. Índices e relacionamentos precisam ser mantidos com precisão.
- Os dados exigem uma forte consistência. As transações operam de forma a garantir que todos os dados sejam 100% consistentes para todos os usuários e processos.
- O tamanho das entradas de dados individuais é pequeno a médio.
Exemplos
- Gestão de inventário
- Gestão de encomendas
- Base de dados de relatórios
- Contabilidade
Repositórios de chave/valor
Um armazenamento de chave/valor associa cada valor de dados a uma chave exclusiva. A maioria dos armazenamentos de chave/valor suporta apenas operações simples de consulta, inserção e exclusão. Para modificar um valor (parcial ou completamente), um aplicativo deve substituir os dados existentes para o valor inteiro. Na maioria das implementações, ler ou escrever um único valor é uma operação atômica.
Um aplicativo pode armazenar dados arbitrários como um conjunto de valores. Qualquer informação de esquema deve ser fornecida pelo aplicativo. O armazenamento de chave/valor simplesmente recupera ou armazena o valor através da chave.
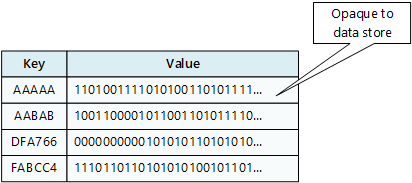
Os armazenamentos de chave/valor são altamente otimizados para aplicativos que executam pesquisas simples, mas são menos adequados se você precisar consultar dados em diferentes armazenamentos de chave/valor. Os armazenamentos de chave/valor também não são otimizados para consulta por valor.
Um único armazenamento de chave/valor pode ser extremamente escalável, pois o armazenamento de dados pode facilmente distribuir dados entre vários nós em máquinas separadas.
Serviços do Azure
- Azure Cosmos DB para Tabela e Azure Cosmos DB para NoSQL | (Linha de Base de Segurança do Azure Cosmos DB)
- Redis Cache do Azure | (Linha de Base de Segurança)
- Armazenamento de Tabelas do Azure | (Linha de Base de Segurança)
Carga de trabalho
- Os dados são acessados usando uma única chave, como um dicionário.
- Não são necessárias associações, bloqueios ou uniões.
- Não são utilizados mecanismos de agregação.
- Os índices secundários geralmente não são usados.
Tipo de dados
- Cada chave está associada a um único valor.
- Não há imposição de esquema.
- Não há relações entre entidades.
Exemplos
- Armazenamento em cache de dados
- Gestão de sessões
- Preferência do usuário e gerenciamento de perfil
- Recomendação de produtos e veiculação de anúncios
Bases de dados documentais
Um banco de dados de documentos armazena uma coleção de documentos , onde cada documento consiste em campos nomeados e dados. Os dados podem ser valores simples ou elementos complexos, como listas e subcoleções. Os documentos são recuperados por chaves exclusivas.
Normalmente, um documento contém os dados de uma única entidade, como um cliente ou um pedido. Um documento pode conter informações que seriam espalhadas por várias tabelas relacionais em um RDBMS. Os documentos não precisam ter a mesma estrutura. Os aplicativos podem armazenar dados diferentes em documentos à medida que os requisitos de negócios mudam.
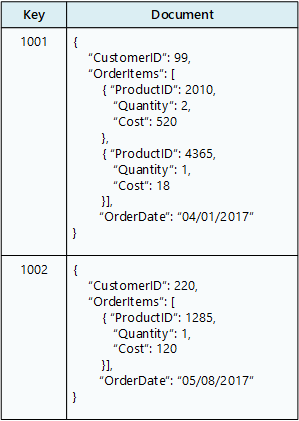 repositório de documentos
repositório de documentos
Serviço do Azure
Carga de trabalho
- As operações de inserção e atualização são comuns.
- Nenhuma incompatibilidade de impedância objeto-relacional. Os documentos podem corresponder melhor às estruturas de objeto usadas no código do aplicativo.
- Os documentos individuais são recuperados e escritos como um único bloco.
- Os dados requerem índice em vários campos.
Tipo de dados
- Os dados podem ser gerenciados de forma desnormalizada.
- O tamanho dos dados de documentos individuais é relativamente pequeno.
- Cada tipo de documento pode usar seu próprio esquema.
- Os documentos podem incluir campos opcionais.
- Os dados do documento são semiestruturados, o que significa que os tipos de dados de cada campo não são estritamente definidos.
Exemplos
- Catálogo de produtos
- Gestão de conteúdos
- Gestão de inventário
Bases de dados gráficas
Um banco de dados gráfico armazena dois tipos de informações, nós e bordas. As bordas especificam relações entre nós. Os nós e as bordas podem ter propriedades que fornecem informações sobre esse nó ou borda, semelhantes às colunas de uma tabela. As arestas também podem ter uma direção específica que indica a natureza da relação.
Os bancos de dados gráficos podem executar consultas de forma eficiente na rede de nós e bordas e analisar as relações entre entidades. O diagrama a seguir mostra o banco de dados de pessoal de uma organização estruturado como um gráfico. As entidades são funcionários e departamentos, e as arestas indicam as relações hierárquicas e os departamentos em que os funcionários trabalham.
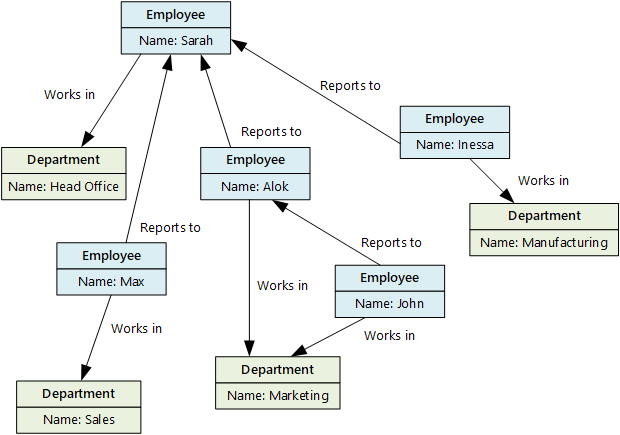
Essa estrutura facilita a realização de consultas como "Encontrar todos os funcionários que se reportam direta ou indiretamente a Sarah" ou "Quem trabalha no mesmo departamento que John?" Para gráficos grandes com muitas entidades e relacionamentos, você pode executar análises muito complexas muito rapidamente. Muitos bancos de dados gráficos fornecem uma linguagem de consulta que você pode usar para atravessar uma rede de relacionamentos de forma eficiente.
Serviços do Azure
- Azure Cosmos DB para Apache Gremlin | (Linha de Base de Segurança)
- SQL Server (linha de base de segurança) |
Carga de trabalho
- Relações complexas entre itens de dados envolvendo muitos saltos entre itens de dados relacionados.
- A relação entre os itens de dados é dinâmica e muda ao longo do tempo.
- As relações entre objetos são cidadãos de primeira classe, sem necessidade de chaves estrangeiras e junções para atravessar.
Tipo de dados
- Nós e relações.
- Os nós são semelhantes a linhas de tabela ou documentos JSON.
- Os relacionamentos são tão importantes quanto os nós e são expostos diretamente na linguagem de consulta.
- Objetos compostos, como uma pessoa com vários números de telefone, tendem a ser divididos em nós pequenos e separados, combinados com relações percorríveis.
Exemplos
- Organogramas
- Gráficos sociais
- Deteção de fraudes
- Mecanismos de recomendação
Análise de dados
Os armazenamentos de análise de dados fornecem soluções massivamente paralelas para ingerir, armazenar e analisar dados. Os dados são distribuídos em vários servidores para maximizar a escalabilidade. Grandes formatos de arquivo de dados, como arquivos delimitadores (CSV), parquete ORC são amplamente utilizados na análise de dados. Os dados históricos normalmente são armazenados em repositórios de dados, como armazenamento de blob ou Azure Data Lake Storage Gen2, que são depois acedidos pelo Azure Synapse, Databricks ou HDInsight como tabelas externas. Um cenário típico que utiliza dados armazenados no formato parquet devido ao seu desempenho é descrito no artigo Usar tabelas externas com o Synapse SQL.
Serviços do Azure
- Azure Synapse Analytics | (Linha de Base de Segurança)
- Azure Data Lake | (Linha de Base de Segurança)
- Azure Data Explorer | (Linha de Base de Segurança)
- Azure Analysis Services
- HDInsight | (Linha de base de segurança)
- Azure Databricks | (Baseline de Segurança)
Carga de trabalho
- Análise de dados
- BI Empresarial
Tipo de dados
- Dados históricos de várias fontes.
- Geralmente desnormalizada num esquema de "estrela" ou "floco de neve", consistindo em tabelas de fatos e dimensões.
- Normalmente carregado com novos dados de forma programada.
- As tabelas de dimensão geralmente incluem várias versões históricas de uma entidade, referidas como uma dimensão que muda lentamente.
Exemplos
- Armazém de dados empresariais
Bancos de dados da família de colunas
Um banco de dados de família de colunas organiza os dados em linhas e colunas. Em sua forma mais simples, um banco de dados de família de colunas pode parecer muito semelhante a um banco de dados relacional, pelo menos conceitualmente. O verdadeiro poder de um banco de dados de família de colunas reside em sua abordagem desnormalizada para estruturar dados esparsos.
Você pode pensar em um banco de dados de família de colunas como contendo dados tabulares com linhas e colunas, mas as colunas são divididas em grupos conhecidos como famílias de colunas. Cada família de colunas contém um conjunto de colunas que estão logicamente relacionadas entre si e normalmente são recuperadas ou manipuladas como uma unidade. Outros dados acessados separadamente podem ser armazenados em famílias de colunas separadas. Dentro de uma família de colunas, novas colunas podem ser adicionadas dinamicamente e as linhas podem ser esparsas (ou seja, uma linha não precisa ter um valor para cada coluna).
O diagrama a seguir mostra um exemplo com duas famílias de colunas, Identity e Contact Info. Os dados de uma única entidade têm a mesma chave de linha em cada família de colunas. Essa estrutura, onde as linhas de qualquer objeto em uma família de colunas podem variar dinamicamente, é um benefício importante da abordagem de família de colunas, tornando essa forma de armazenamento de dados altamente adequada para armazenar dados estruturados e voláteis.

Ao contrário de um armazenamento de chave/valor ou um banco de dados de documentos, a maioria dos bancos de dados da família de colunas armazena dados em ordem de chave, em vez de calcular um hash. Muitas implementações permitem criar índices sobre colunas específicas em uma família de colunas. Os índices permitem recuperar dados por valor de colunas, em vez de chave de linha.
As operações de leitura e gravação para uma linha são geralmente atômicas com uma única família de colunas, embora algumas implementações forneçam atomicidade em toda a linha, abrangendo várias famílias de colunas.
Serviços do Azure
- Azure Cosmos DB para Apache Cassandra | (Linha de Base de Segurança)
- HBase no HDInsight | (Linha de Base de Segurança)
Carga de trabalho
- A maioria dos bancos de dados da família de colunas executa operações de gravação extremamente rapidamente.
- As operações de atualização e exclusão são raras.
- Projetado para fornecer alta taxa de transferência e acesso de baixa latência.
- Suporta acesso de consulta fácil a um conjunto específico de campos dentro de um registro muito maior.
- Massivamente escalável.
Tipo de dados
- Os dados são armazenados em tabelas que consistem em uma coluna chave e uma ou mais famílias de colunas.
- Colunas específicas podem variar de acordo com linhas individuais.
- As células individuais são acedidas através dos comandos get e put
- Várias linhas são retornadas usando um comando de varredura.
Exemplos
- Recomendações
- Personalização
- Dados do sensor
- Telemetria
- Mensagens
- Análise de redes sociais
- Análise da Web
- Monitorização da atividade
- Dados meteorológicos e outras séries cronológicas
Bases de Dados dos Motores de Pesquisa
Uma base de dados de motor de busca permite que as aplicações pesquisem informações mantidas em armazenamentos de dados externos. Um banco de dados de mecanismo de pesquisa pode indexar grandes volumes de dados e fornecer acesso quase em tempo real a esses índices.
Os índices podem ser multidimensionais e podem suportar pesquisas de texto livre em grandes volumes de dados de texto. A indexação pode ser realizada usando um modelo pull, acionado pelo banco de dados do mecanismo de pesquisa, ou usando um modelo push, iniciado por código de aplicativo externo.
A pesquisa pode ser exata ou confusa. Uma pesquisa difusa encontra documentos que correspondem a um conjunto de termos e calcula a sua proximidade. Alguns mecanismos de busca também suportam análise linguística que pode retornar correspondências com base em sinônimos, expansões de gênero (por exemplo, correspondência de dogs a pets) e derivação (correspondência de palavras com a mesma raiz).
Serviço do Azure
Carga de trabalho
- Índices de dados de várias fontes e serviços.
- As consultas são ad hoc e podem ser complexas.
- É necessária uma pesquisa de texto completo.
- É necessária uma consulta ad hoc de autoatendimento.
Tipo de dados
- Texto semiestruturado ou não estruturado
- Texto com referência a dados estruturados
Exemplos
- Catálogos de produtos
- Pesquisa no site
- Registo
Bases de dados de séries cronológicas
Os dados de séries temporais são um conjunto de valores organizados por tempo. As bases de dados de séries cronológicas normalmente recolhem grandes quantidades de dados em tempo real a partir de um grande número de fontes. As atualizações são raras e as exclusões geralmente são feitas como operações em massa. Embora os registros gravados em um banco de dados de séries cronológicas sejam geralmente pequenos, geralmente há um grande número de registros e o tamanho total dos dados pode crescer rapidamente.
Serviço do Azure
Carga de trabalho
- Os registos são geralmente acrescentados sequencialmente por ordem cronológica.
- Uma proporção esmagadora das operações (95-99%) são escritas.
- As atualizações são raras.
- As exclusões ocorrem em massa e são feitas em blocos ou registros contíguos.
- Os dados são lidos sequencialmente em ordem de tempo crescente ou decrescente, muitas vezes em paralelo.
Tipo de dados
- Um carimbo de data/hora é usado como chave primária e mecanismo de classificação.
- As tags podem definir informações adicionais sobre o tipo, origem e outras informações sobre a entrada.
Exemplos
- Monitorização e telemetria de eventos.
- Sensor ou outros dados de IoT.
Armazenamento de objetos
O armazenamento de objetos é otimizado para armazenar e recuperar grandes objetos binários (imagens, arquivos, fluxos de vídeo e áudio, objetos e documentos de dados de aplicativos grandes, imagens de disco de máquinas virtuais). Grandes arquivos de dados também são popularmente usados neste modelo, por exemplo, arquivo delimitador (CSV), parquete ORC. Os repositórios de objetos podem gerenciar quantidades extremamente grandes de dados não estruturados.
Serviço do Azure
- Armazenamento de Blob do Azure | (Linha de Base de Segurança)
- | do Azure Data Lake Storage Gen2 (Linha de Base de Segurança)
Carga de trabalho
- Identificado por chave.
- Normalmente, o conteúdo é um ativo, como um delimitador, uma imagem ou um arquivo de vídeo.
- O conteúdo deve ser durável e externo a qualquer camada de aplicativo.
Tipo de dados
- O tamanho dos dados é grande.
- O valor é opaco.
Exemplos
- Imagens, vídeos, documentos de escritório, PDFs
- HTML estático, JSON, CSS
- Arquivos de log e auditoria
- Backups de banco de dados
Ficheiros partilhados
Às vezes, o uso de arquivos simples pode ser o meio mais eficaz de armazenar e recuperar informações. O uso de compartilhamentos de arquivos permite que os arquivos sejam acessados através de uma rede. Dada a segurança apropriada e os mecanismos de controle de acesso simultâneos, o compartilhamento de dados dessa maneira pode permitir que os serviços distribuídos forneçam acesso a dados altamente escalável para executar operações básicas e de baixo nível, como solicitações simples de leitura e gravação.
Serviço do Azure
Arquivos do Azure (Linha de Base de Segurança)
Carga de trabalho
- Migração de aplicativos existentes que interagem com o sistema de arquivos.
- É necessário interface SMB.
Tipo de dados
- Arquivos em um conjunto hierárquico de pastas.
- Acessível com bibliotecas de E/S padrão.
Exemplos
- Arquivos herdados
- Conteúdo compartilhado acessível entre várias VMs ou instâncias de aplicativos
Auxiliado com essa compreensão de diferentes modelos de armazenamento de dados, a próxima etapa é avaliar sua carga de trabalho e aplicativo e decidir qual armazenamento de dados atenderá às suas necessidades específicas. Use a árvore de decisão de armazenamento de dados para ajudar nesse processo.
Próximos passos
- Soluções e Serviços de Armazenamento em Nuvem do Azure
- Revise suas opções de armazenamento
- Introdução ao Armazenamento do Azure
- Introdução ao Azure Data Explorer