Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
O padrão Bulkhead é um tipo de design de aplicação que tolera falhas. Numa arquitetura de compartimento, também conhecida como arquitetura baseada em células, os elementos de uma aplicação são isolados em diversos grupos de forma que, caso um falhe, os outros elementos continuem a operar. O padrão Bulkhead deve o seu nome às divisórias seccionadas (anteparas) do casco de um navio. Se o casco do navio ficar comprometido, apenas as secções danificadas se enchem com água, impedindo que o navio se afunde.
Contexto e problema
Uma aplicação baseada na cloud pode incluir múltiplos serviços, e cada serviço tem um ou mais consumidores. A carga excessiva ou a falha num serviço afeta todos os consumidores do serviço.
Além disso, um consumidor pode enviar pedidos para múltiplos serviços simultaneamente e usar recursos para cada pedido. Quando o consumidor envia um pedido para um serviço mal configurado ou não responsivo, os recursos que o pedido do cliente utiliza podem permanecer indisponíveis durante um período prolongado. À medida que as solicitações ao serviço continuam, esses recursos podem ser esgotados. Por exemplo, o pool de conexões do cliente pode estar esgotado. Nesse momento, os pedidos do consumidor a outros serviços são afetados. Eventualmente, o consumidor não pode enviar pedidos para outros serviços, não apenas para o serviço original que não responde.
O esgotamento de recursos afeta serviços que têm múltiplos consumidores. Muitos pedidos de um cliente podem esgotar os recursos disponíveis no serviço. O esgotamento de recursos pode significar que outros consumidores não conseguem consumir o serviço, o que provoca um efeito de falha em cascata.
Solução
Particionar as instâncias de serviço em diferentes grupos com base na carga do consumidor e nos requisitos de disponibilidade. Este design ajuda a isolar falhas. Pode manter a funcionalidade do serviço para alguns consumidores, mesmo durante uma falha.
Um consumidor pode também particionar recursos para garantir que os recursos usados para chamar um serviço não afetam os recursos usados para chamar outro serviço. Por exemplo, um consumidor que chama vários serviços pode receber um pool de conexões para cada serviço. Se um serviço começar a falhar, só afeta o pool de ligação atribuído a esse serviço. O consumidor pode continuar a utilizar outros serviços.
Este padrão fornece os benefícios seguintes:
Isola os consumidores e serviços de falhas em cascata. Um problema que afeta um consumidor ou serviço pode ser isolado dentro do seu próprio compartimento para evitar que toda a solução falhe.
Preserva alguma funcionalidade caso ocorra uma falha de serviço. Outros serviços e funcionalidades da aplicação continuam a funcionar.
Proporciona diferentes níveis de qualidade de serviço para aplicações consumidoras. Pode configurar um pool de consumidores de alta prioridade para usar serviços de alta prioridade.
O diagrama seguinte mostra compartimentos de isolamento estruturados em torno de pools de conexões que chamam serviços individuais. Se o Serviço A falhar ou causar um problema, o pool de ligação fica isolado, pelo que apenas as cargas de trabalho que utilizam o pool de threads atribuído ao Serviço A são afetadas. As cargas de trabalho que usam os Serviços B e C não são afetadas e podem continuar funcionando sem interrupção.
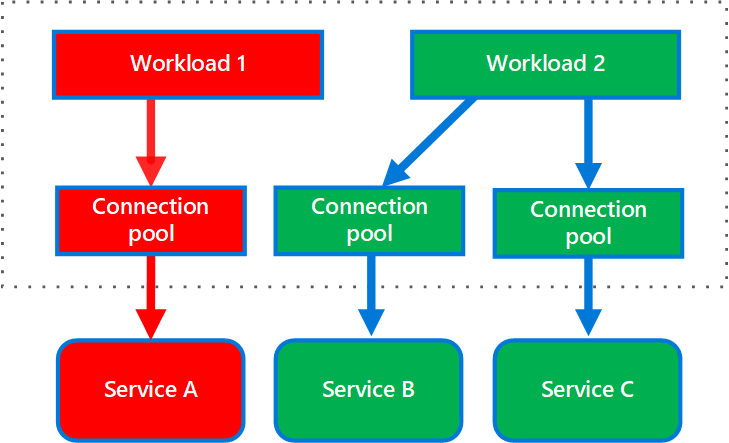
Diagrama que mostra duas cargas de trabalho, Carga de Trabalho 1 e Carga de Trabalho 2, e três serviços, Serviço A, Serviço B e Serviço C. A Carga de Trabalho 1 utiliza um pool de ligações atribuído ao Serviço A. A Carga de Trabalho 2 usa dois pools de ligações. Um pool de ligação é atribuído ao Serviço B e o outro ao Serviço C. O pool de ligação que o Workload 1 utiliza é isolado. Os pools de ligação que o Workload 2 utiliza podem continuar a chamar o Serviço B e o Serviço C.
O diagrama seguinte mostra múltiplos clientes que chamam um único serviço. Cada cliente é atribuído a uma instância de serviço separada. O Cliente 1 faz demasiados pedidos e sobrecarrega a sua instância. Como cada instância de serviço está isolada das outras, os outros clientes podem continuar a fazer chamadas.
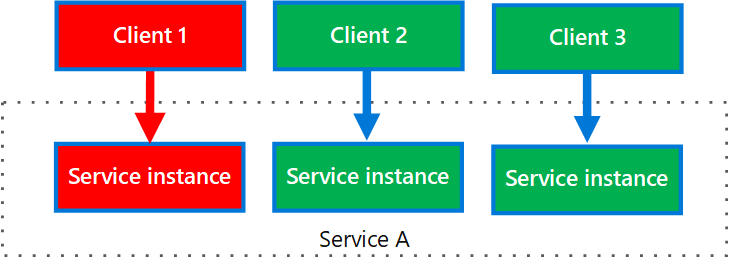
Diagrama que mostra três clientes, Cliente 1, Cliente 2 e Cliente 3, e três instâncias de serviço que fazem parte do Serviço A. Cada cliente liga-se à sua própria instância de serviço. As instâncias de serviço são isoladas. Se o Cliente 1 sobrecarregar a sua instância, os Clientes 2 e 3 não são afetados.
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar este padrão:
Defina partições em torno do negócio e requisitos técnicos da aplicação.
Se usar design tático orientado por domínio para desenhar microserviços, os limites de partição devem alinhar-se com os contextos limitados.
Ao dividir serviços ou consumidores em anteparas, considere o nível de isolamento proporcionado pela tecnologia e o impacto em termos de custo, desempenho e gerenciamento.
Para proporcionar uma gestão de falhas mais sofisticada, considere combinar anteparas com padrões de retentação, disjuntor e estrangulamento.
Ao particionar os consumidores em anteparos, considere usar processos, pools de threads e semáforos. Projetos como resilience4j e Polly oferecem uma estrutura para a criação de anteparas de consumo.
Ao particionar serviços em anteparas, considere implantá-los em máquinas virtuais, contentores ou processos separados. Os contentores oferecem um bom equilíbrio de isolamento de recursos com sobrecarga consideravelmente baixa.
Serviços que comunicam através de mensagens assíncronas podem ser isolados através de diferentes conjuntos de filas. Cada fila pode ter um conjunto dedicado de instâncias que processam mensagens na fila ou um único grupo de instâncias que utilizam um algoritmo para desalinhar e despachar o processamento.
Determine o nível de granularidade das anteparas. Por exemplo, se quiseres distribuir inquilinos entre partições, podes colocar cada inquilino numa partição separada ou colocar vários inquilinos numa só partição.
Monitorizar o desempenho de cada partição e o acordo de nível de serviço (SLA).
Use controlos de plataforma incorporados, como limites de taxa de gestão de API do Azure, isolamento de unidades de pedido (RU) do Azure Cosmos DB e limites de recursos no Azure Kubernetes Service (AKS) ou Azure Container Apps. Não recrie estes mecanismos de limitação e isolamento no código da sua aplicação.
Cargas de trabalho de IA e inferência frequentemente exigem separações rigorosas devido a quotas a nível de implementação e limites de concorrência, por exemplo, isolando implementações do Azure OpenAI por carga de trabalho ou por locatário.
Quando utilizar este padrão
Utilize este padrão quando:
- Queres isolar recursos para dependências específicas para que uma interrupção num serviço não afete toda a aplicação.
- Queres isolar os consumidores críticos dos consumidores normais.
- Tens de proteger a aplicação de falhas em cascata.
Este padrão pode não ser adequado quando:
- Uma utilização menos eficiente dos recursos pode não ser aceitável no projeto.
- A complexidade adicional não é necessária.
Design da carga de trabalho
Avalie como utilizar o padrão Bulkhead no design de uma carga de trabalho para responder aos objetivos e princípios abordados nos pilares do Azure Well-Architected Framework. A tabela a seguir fornece orientação sobre como esse padrão suporta as metas de cada pilar.
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e garantem que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | A estratégia de isolamento de falhas introduzida através da segmentação intencional e completa entre componentes tenta conter falhas no anteparo que enfrenta o problema, prevenindo o impacto noutros anteparos. - RE:02 Fluxos críticos - RE:07 Autopreservação |
| As decisões de design de segurança ajudam a garantir a confidencialidade, integridade e disponibilidade dos dados e sistemas da sua carga de trabalho. | A segmentação entre componentes ajuda a restringir os incidentes de segurança à secção comprometida. - SE:04 Segmentação |
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender às demandas de forma eficiente por meio de otimizações em escala, dados e código. | Cada antepara pode ser dimensionada individualmente para atender de forma eficiente às necessidades da tarefa encapsulada na antepara. - PE:02 Planeamento da capacidade - PE:05 Dimensionamento e particionamento |
Se este padrão introduzir compensações dentro de um pilar, considere-as em relação aos objetivos dos outros pilares.
Exemplo
O ficheiro de configuração Kubernetes seguinte cria um contentor isolado para executar um único serviço, com os seus próprios recursos e limites de CPU e memória.
apiVersion: v1
kind: Pod
metadata:
name: drone-management
spec:
containers:
- name: drone-management-container
image: drone-service
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "1"
Passos seguintes
- Utilize políticas de limite de taxa de gestão de API para controlar o débito de pedidos por cliente.
- Use os controlos de concorrência do Azure Functions para limitar execuções paralelas.
- Defina limites de recursos das Aplicações Container para controlar CPU e memória por carga de trabalho.
- Atribuir débito de RU do Azure Cosmos DB por contêiner para um isolamento previsível.