Este artigo descreve como uma equipa de desenvolvimento utilizou métricas para encontrar estrangulamentos e melhorar o desempenho de um sistema distribuído. O artigo baseia-se em testes de carga reais que fizemos para uma aplicação de exemplo. A aplicação é da Linha de Base do Azure Kubernetes Service (AKS) para microsserviços.
Este artigo faz parte de uma série. Leia a primeira parte aqui.
Cenário: uma aplicação cliente inicia uma transação empresarial que envolve vários passos.
Este cenário envolve uma aplicação de entrega de drones que é executada no AKS. Os clientes utilizam uma aplicação Web para agendar entregas por drone. Cada transação requer vários passos efetuados por microsserviços separados no back-end:
- O serviço de Entrega gere as entregas.
- O serviço Drone Scheduler agenda drones para recolha.
- O serviço Pacote gere pacotes.
Existem outros dois serviços: um serviço de Ingestão que aceita pedidos de cliente e os coloca numa fila para processamento e um serviço de Fluxo de Trabalho que coordena os passos no fluxo de trabalho.
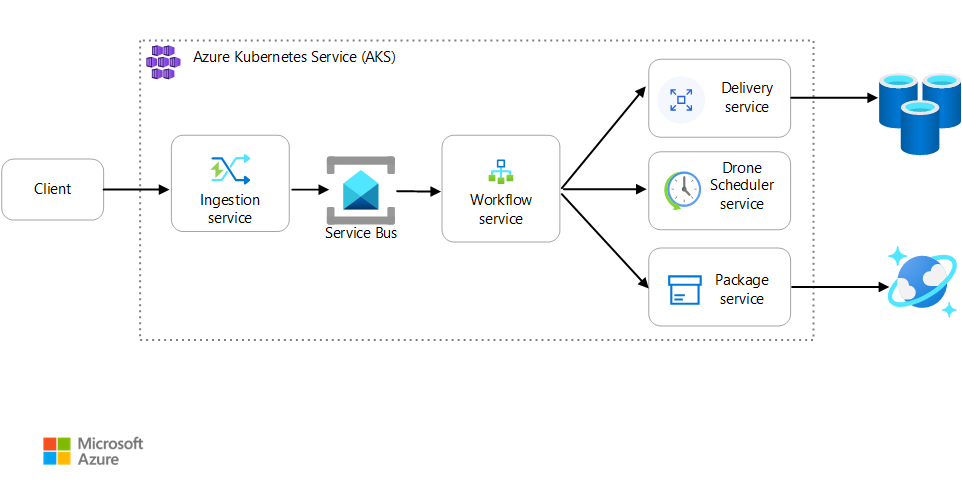
Para obter mais informações sobre este cenário, veja Estruturar uma arquitetura de microsserviços.
Teste 1: Linha de Base
Para o primeiro teste de carga, a equipa criou um cluster do AKS de seis nós e implementou três réplicas de cada microsserviço. O teste de carga foi um teste de carregamento de passos, começando em dois utilizadores simulados e aumentando para 40 utilizadores simulados.
| Definição | Valor |
|---|---|
| Nós do cluster | 6 |
| Pods | 3 por serviço |
O gráfico seguinte mostra os resultados do teste de carga, conforme mostrado no Visual Studio. A linha roxa desenha a carga do utilizador e a linha laranja desenha o total de pedidos.
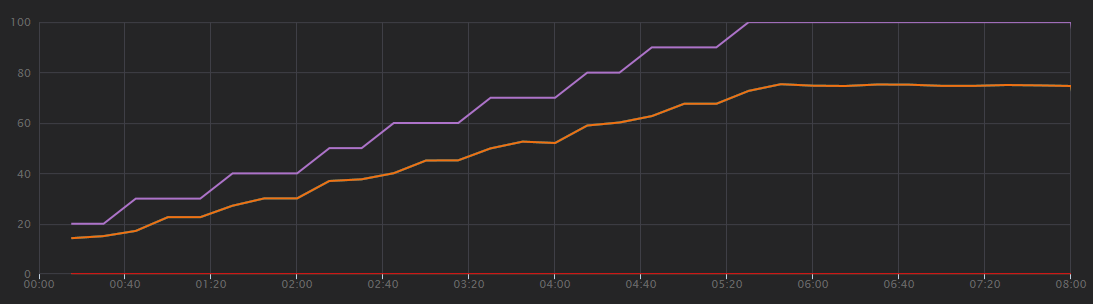
A primeira coisa a ter em conta neste cenário é que os pedidos de cliente por segundo não são uma métrica útil de desempenho. Isto deve-se ao facto de a aplicação processar pedidos de forma assíncrona, pelo que o cliente recebe imediatamente uma resposta. O código de resposta é sempre HTTP 202 (Aceite), o que significa que o pedido foi aceite, mas o processamento não está concluído.
O que realmente queremos saber é se o back-end está a acompanhar a taxa de pedidos. A fila do Service Bus pode absorver picos, mas se o back-end não conseguir lidar com uma carga sustentada, o processamento irá ficar cada vez mais para trás.
Eis um gráfico mais informativo. Desenha o número de mensagens recebidas e enviadas na fila do Service Bus. As mensagens recebidas são apresentadas a azul claro e as mensagens enviadas são apresentadas a azul escuro:
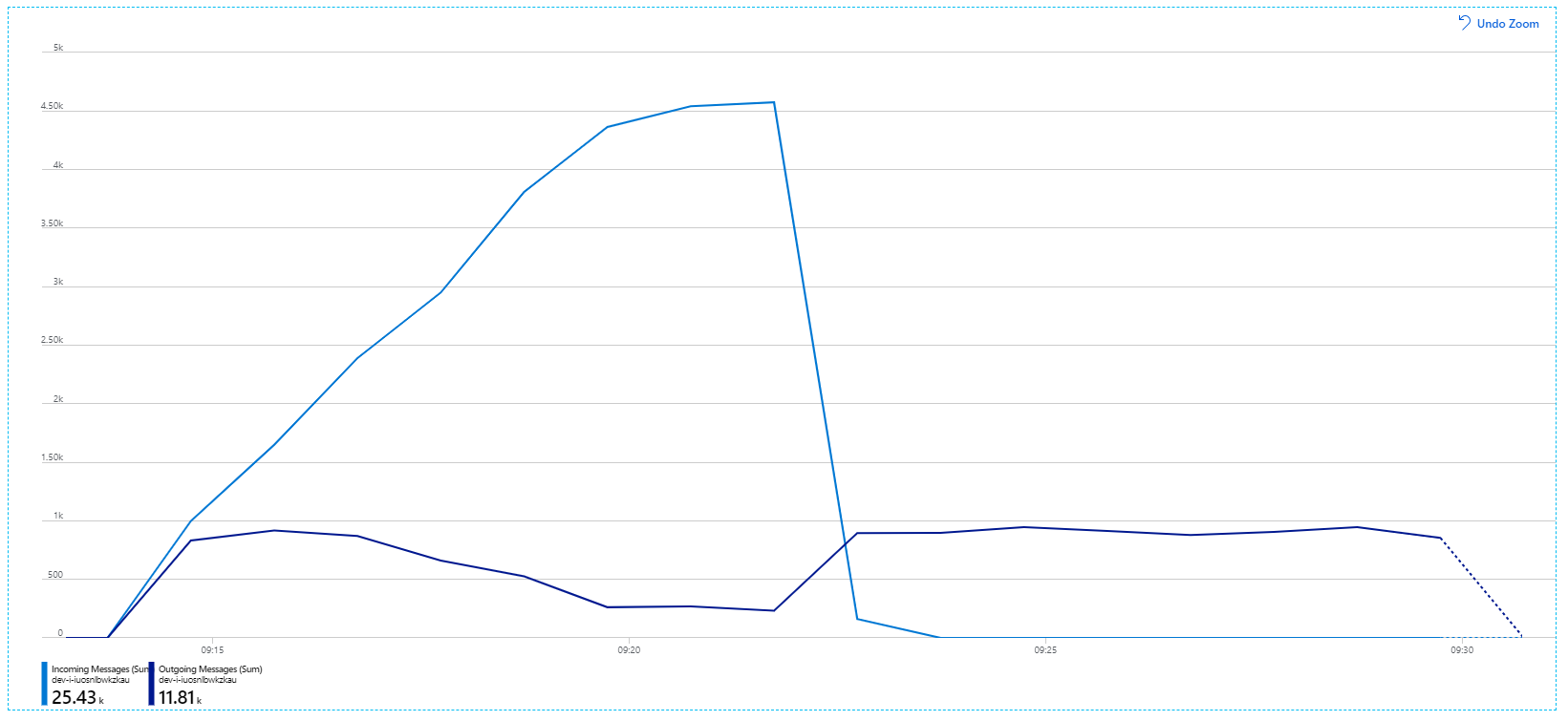
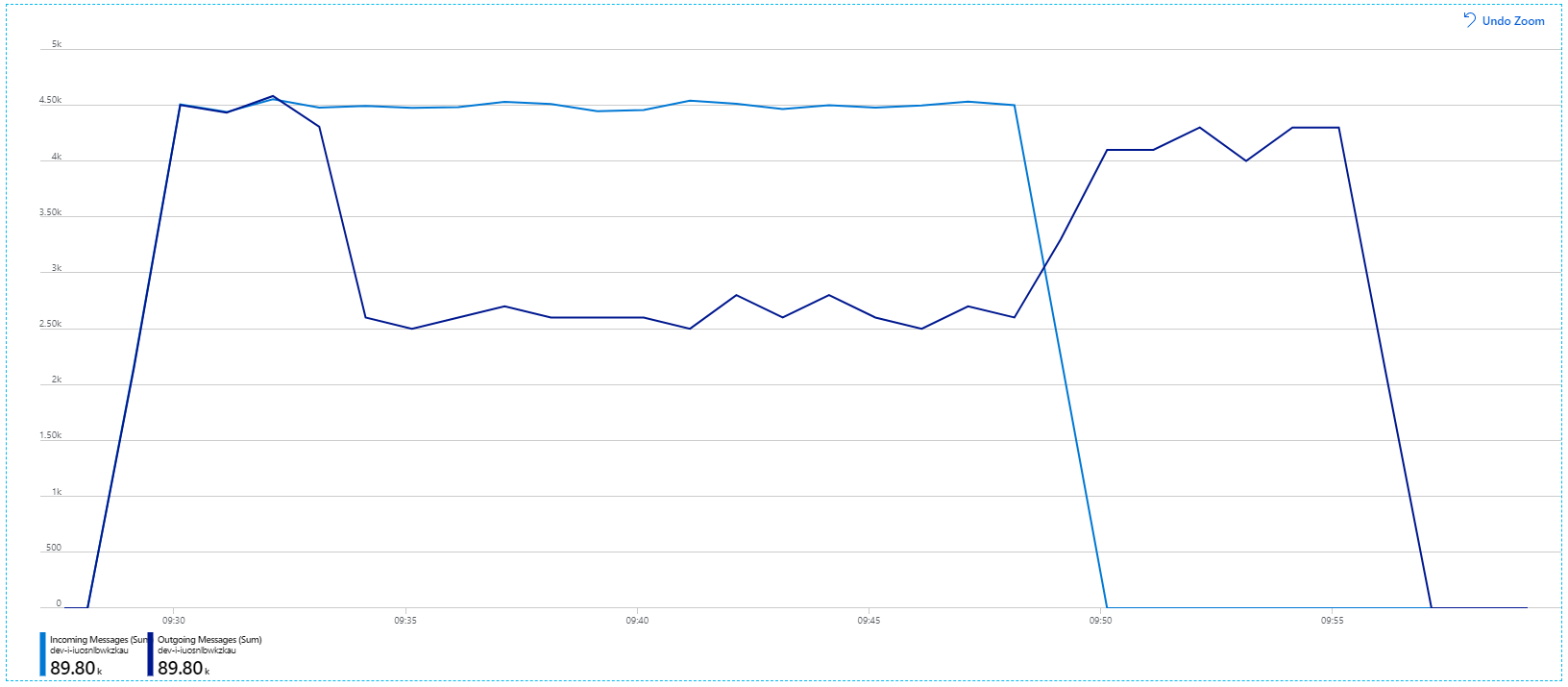
Este gráfico mostra que a taxa de mensagens recebidas aumenta, atinge um pico e, em seguida, recua para zero no final do teste de carga. Mas o número de mensagens enviadas atinge o pico no início do teste e, em seguida, diminui. Isto significa que o serviço Fluxo de Trabalho, que processa os pedidos, não está a acompanhar. Mesmo depois de o teste de carga terminar (por volta das 9:22 no gráfico), as mensagens continuam a ser processadas à medida que o serviço Fluxo de Trabalho continua a drenar a fila.
O que está a abrandar o processamento? A primeira coisa a procurar são erros ou exceções que possam indicar um problema sistemático. O Mapa da Aplicação no Azure Monitor mostra o gráfico de chamadas entre componentes e é uma forma rápida de detetar problemas e, em seguida, clicar para obter mais detalhes.
Com certeza, o Mapa da Aplicação mostra que o serviço Fluxo de Trabalho está a receber erros do serviço de Entrega:
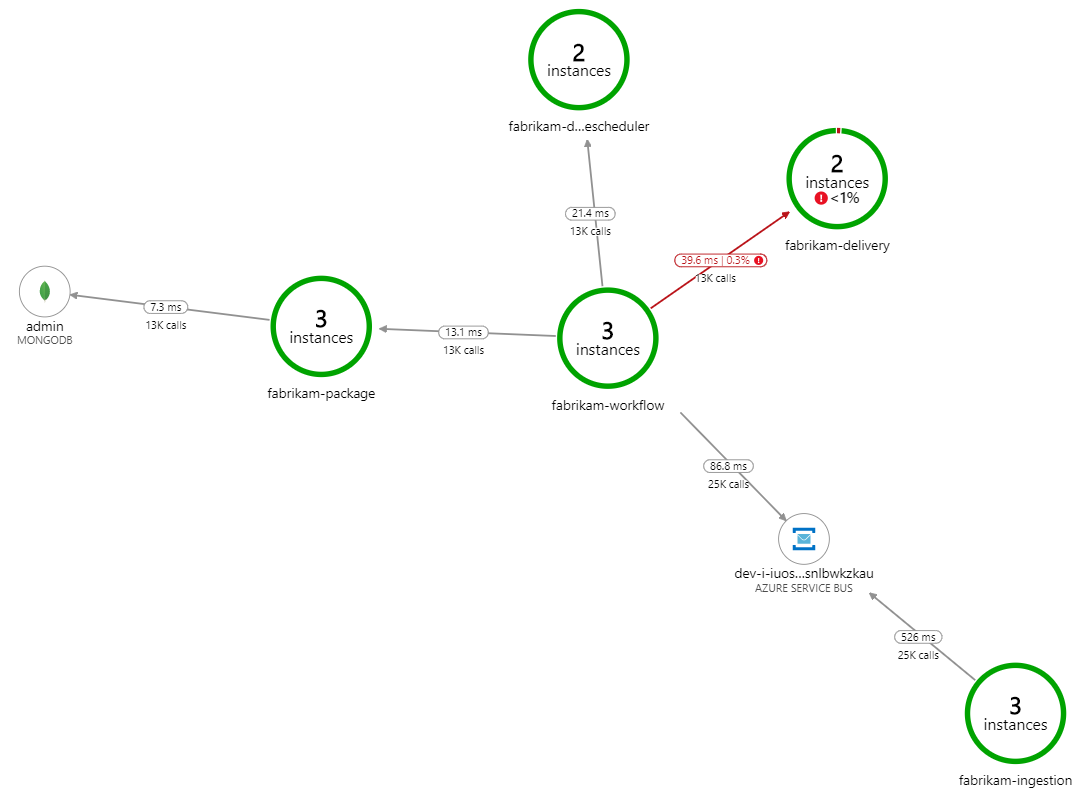
Para ver mais detalhes, pode selecionar um nó no gráfico e clicar numa vista de transação ponto a ponto. Neste caso, mostra que o serviço de Entrega está a devolver erros HTTP 500. As mensagens de erro indicam que está a ser emitida uma exceção devido aos limites de memória no Cache do Azure para Redis.
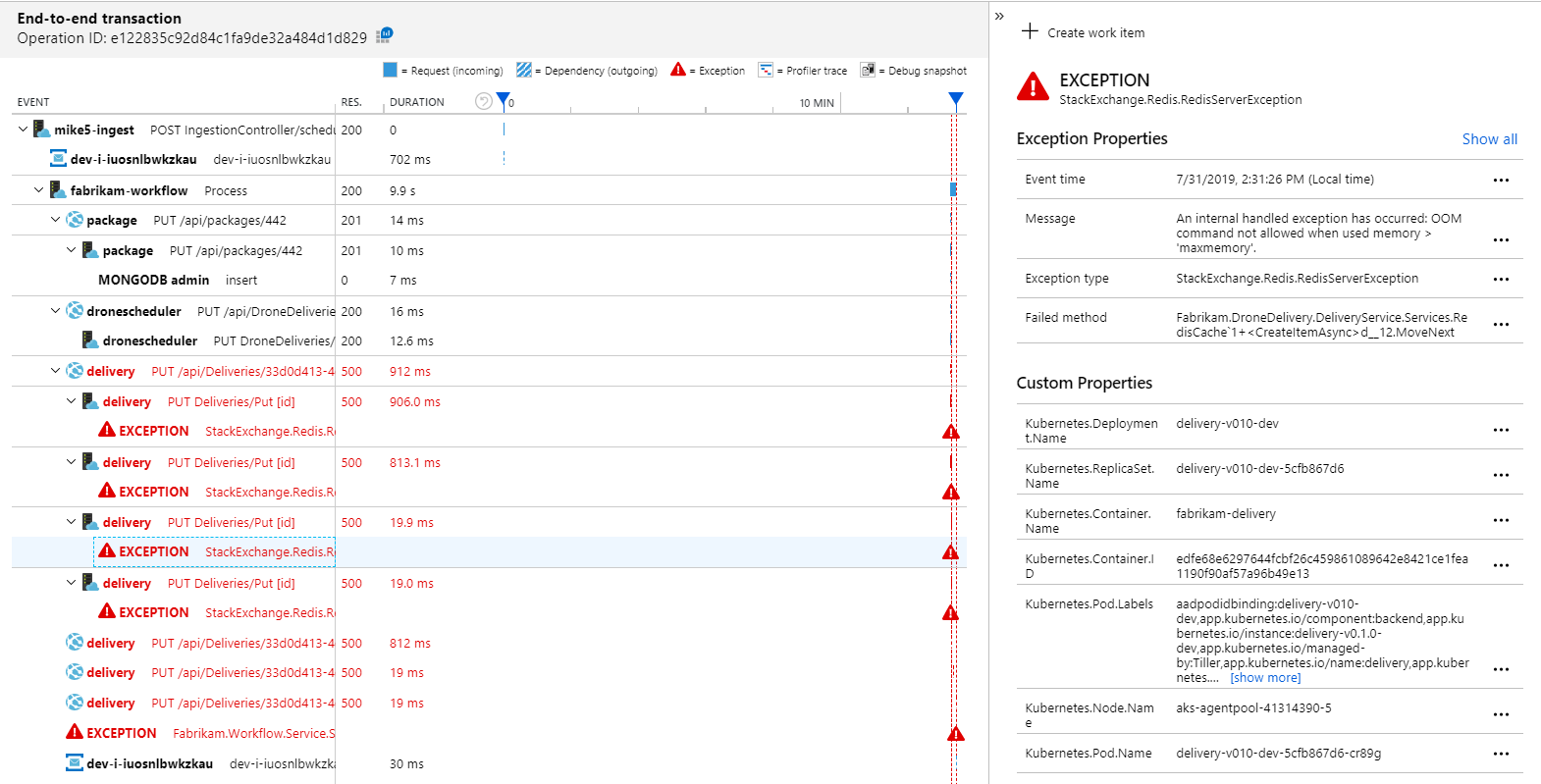
Poderá reparar que estas chamadas para Redis não aparecem no Mapa da Aplicação. Isto deve-se ao facto de a biblioteca .NET do Application Insights não ter suporte incorporado para controlar o Redis como uma dependência. (Para obter uma lista do que é suportado fora da caixa, veja Coleção automática de dependências.) Como contingência, pode utilizar a API TrackDependency para controlar qualquer dependência. Os testes de carga revelam frequentemente estes tipos de lacunas na telemetria, que podem ser remediadas.
Teste 2: aumento do tamanho da cache
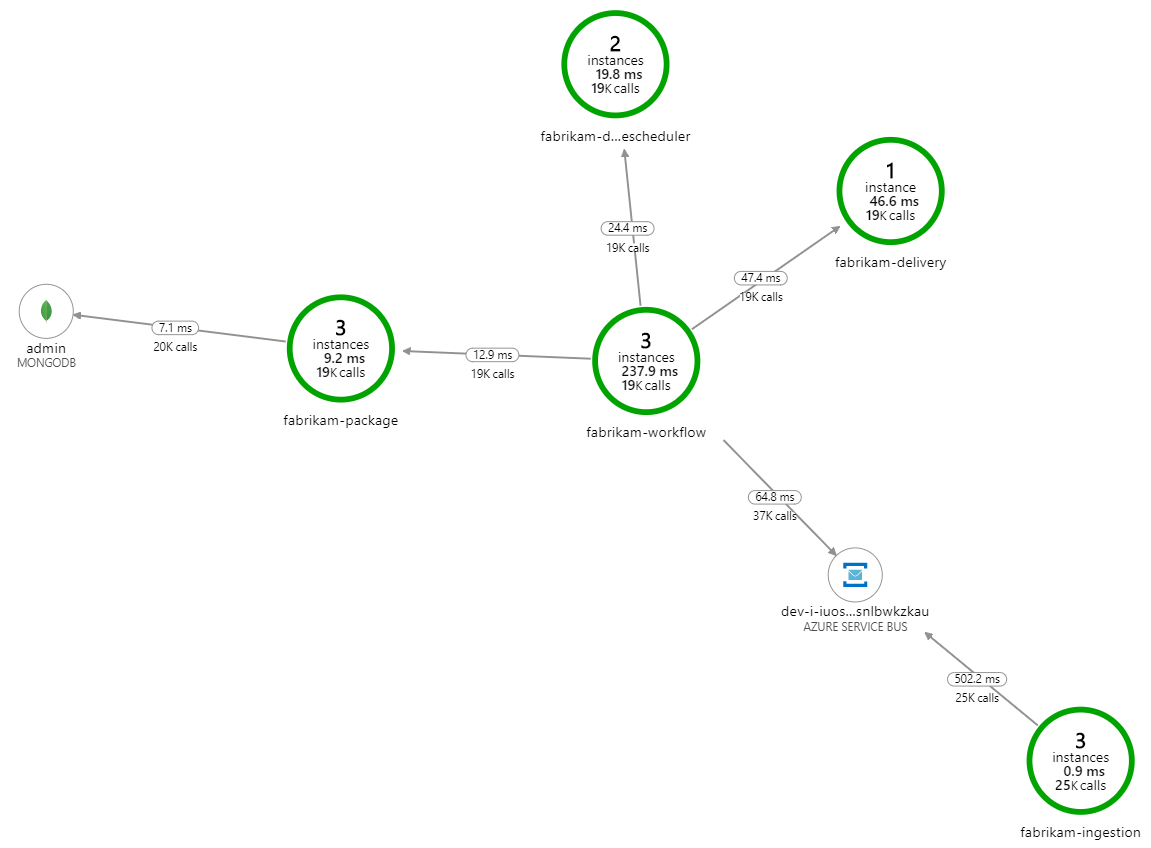
Para o segundo teste de carga, a equipa de desenvolvimento aumentou o tamanho da cache em Cache do Azure para Redis. (Veja Como Dimensionar Cache do Azure para Redis.) Esta alteração resolveu as exceções de memória esgotada e agora o Mapa da Aplicação mostra zero erros:
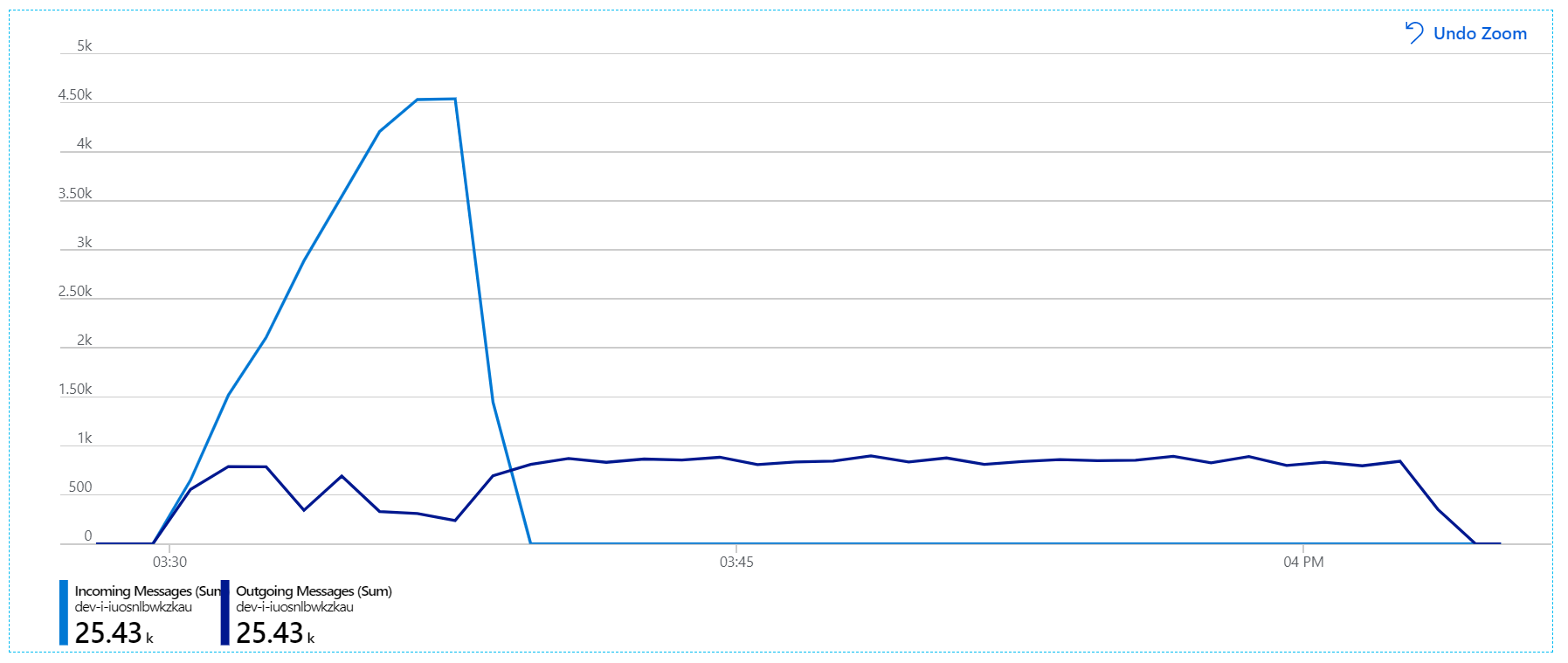
No entanto, continua a existir um atraso dramático no processamento de mensagens. No pico do teste de carga, a taxa de mensagens recebidas é superior a 5× a taxa de saída:
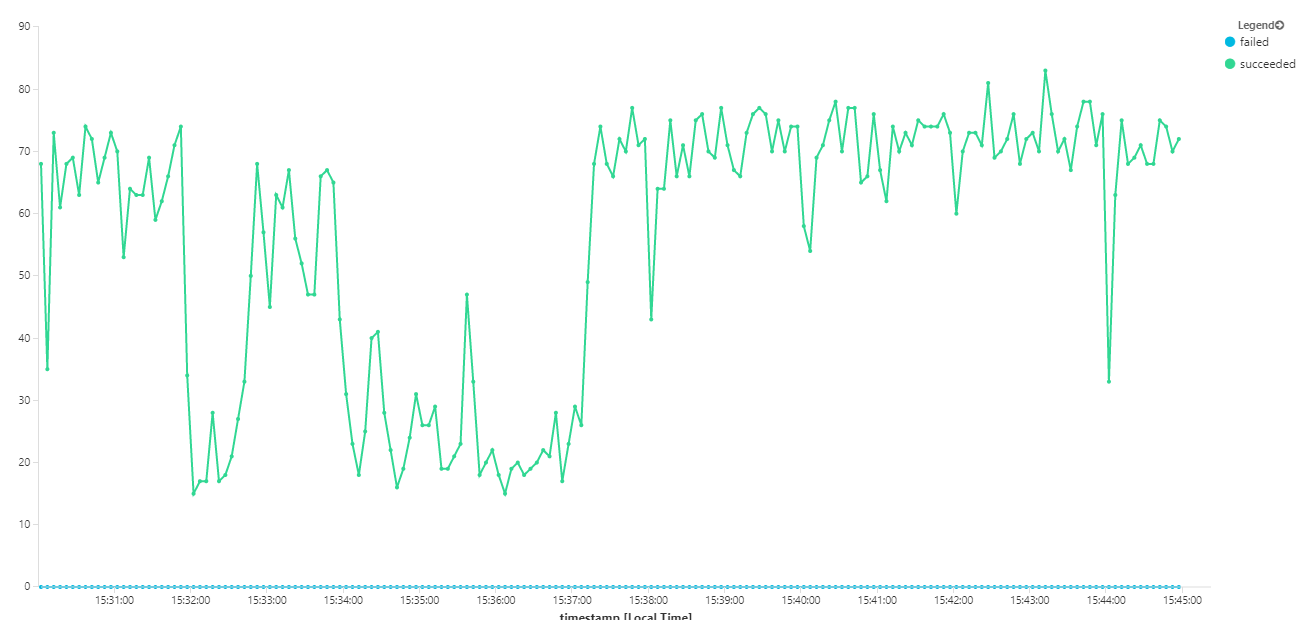
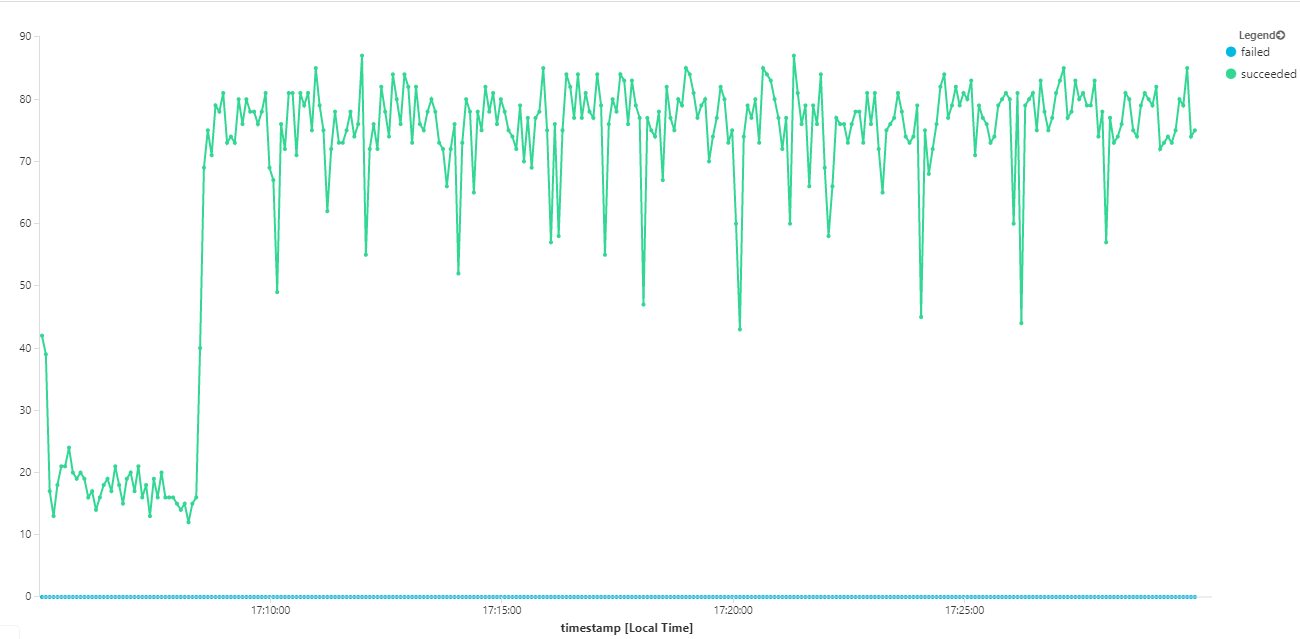
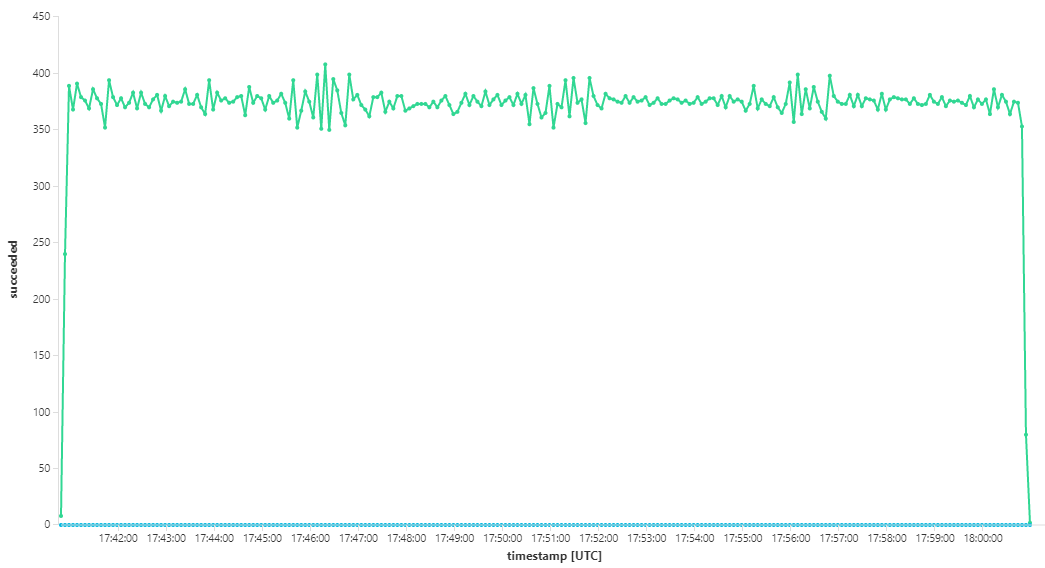
O gráfico seguinte mede o débito em termos de conclusão de mensagens, ou seja, a taxa a que o serviço fluxo de trabalho marca as mensagens do Service Bus como concluídas. Cada ponto no gráfico representa 5 segundos de dados, mostrando o débito máximo de ~16 segundos.
Este gráfico foi gerado ao executar uma consulta na área de trabalho do Log Analytics com a linguagem de consulta Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Teste 3: Aumentar horizontalmente os serviços de back-end
Parece que o back-end é o estrangulamento. Um passo seguinte fácil é aumentar horizontalmente os serviços empresariais (Package, Delivery e Drone Scheduler) e ver se o débito melhora. Para o próximo teste de carga, a equipa aumentou verticalmente estes serviços de três réplicas para seis réplicas.
| Definição | Valor |
|---|---|
| Nós do cluster | 6 |
| Serviço de ingestão | 3 réplicas |
| Serviço de fluxo de trabalho | 3 réplicas |
| Serviços do Package, Delivery, Drone Scheduler | 6 réplicas cada |
Infelizmente, este teste de carga mostra apenas melhorias modestas. As mensagens a enviar ainda não estão a acompanhar as mensagens recebidas:
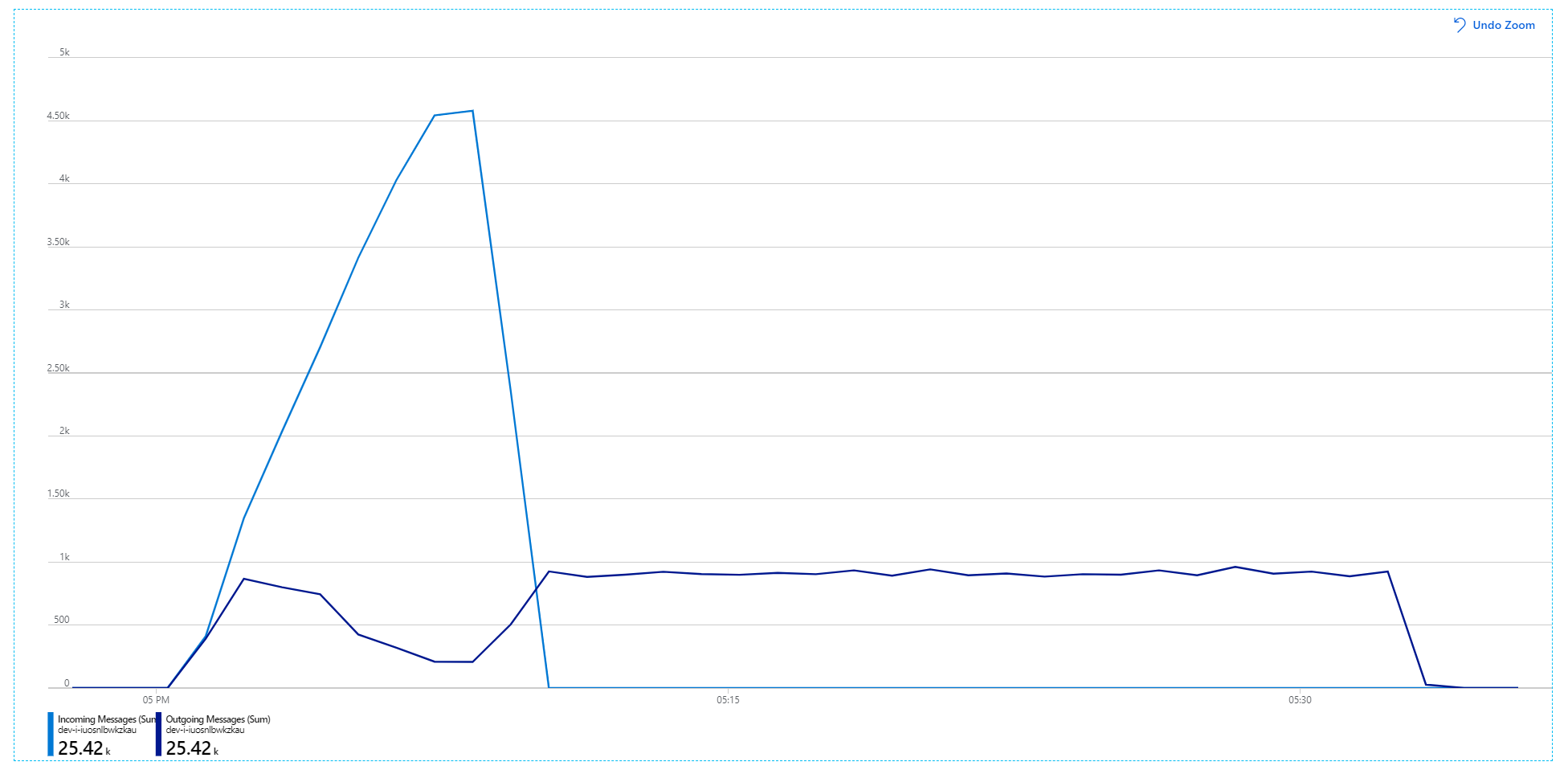
O débito é mais consistente, mas o máximo alcançado é praticamente o mesmo que o teste anterior:
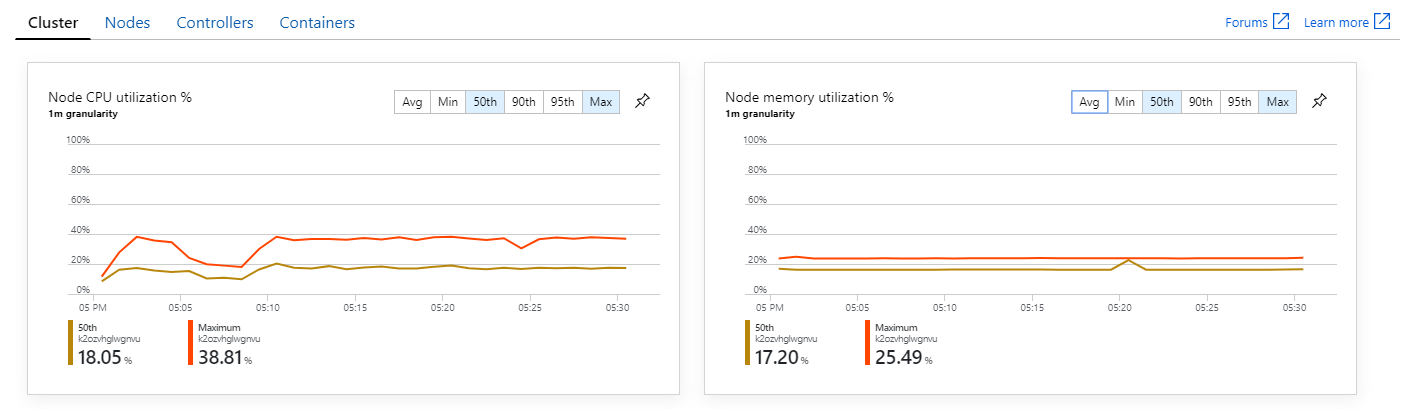
Além disso, ao analisar as informações de contentor do Azure Monitor, parece que o problema não é causado pelo esgotamento de recursos no cluster. Primeiro, as métricas ao nível do nó mostram que a utilização da CPU permanece abaixo dos 40% mesmo no percentil 95 e a utilização da memória é de cerca de 20%.
Num ambiente do Kubernetes, é possível que os pods individuais estejam limitados a recursos mesmo quando os nós não estão. Mas a vista ao nível do pod mostra que todos os pods estão em bom estado de funcionamento.
Neste teste, parece que apenas adicionar mais pods ao back-end não vai ajudar. O próximo passo consiste em analisar mais detalhadamente o serviço Fluxo de Trabalho para compreender o que está a acontecer quando processa mensagens. O Application Insights mostra que a duração média da operação do Process serviço Fluxo de Trabalho é de 246 ms.
Também podemos executar uma consulta para obter métricas sobre as operações individuais em cada transação:
| destino | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| contínua | 37 | 57 |
| package | 12 | 17 |
| dronescheduler | 21 | 41 |
A primeira linha nesta tabela representa a fila do Service Bus. As outras linhas são as chamadas para os serviços de back-end. Para referência, eis a consulta do Log Analytics para esta tabela:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
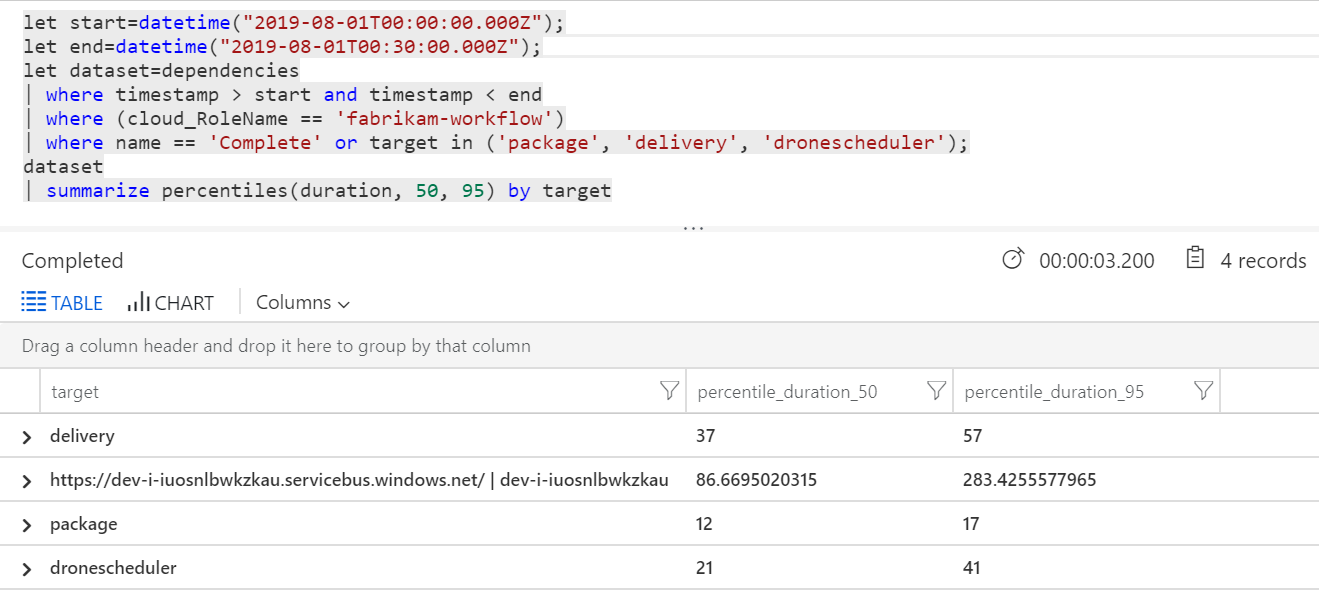
Estas latências parecem razoáveis. Mas aqui está a informação chave: se o tempo total da operação for ~250 ms, isso coloca um limite superior estrito sobre a rapidez com que as mensagens podem ser processadas em série. Por conseguinte, a chave para melhorar o débito é o paralelismo maior.
Isto deve ser possível neste cenário, por duas razões:
- Estas são chamadas de rede, pelo que a maior parte do tempo é despendida à espera da conclusão de E/S
- As mensagens são independentes e não precisam de ser processadas por ordem.
Teste 4: Aumentar o paralelismo
Para este teste, a equipa focou-se no aumento do paralelismo. Para tal, ajustaram duas definições no cliente do Service Bus utilizado pelo serviço Fluxo de Trabalho:
| Definições | Descrição | Predefinição | Valor novo |
|---|---|---|---|
MaxConcurrentCalls |
O número máximo de mensagens a processar em simultâneo. | 1 | 20 |
PrefetchCount |
Quantas mensagens o cliente irá obter antecipadamente na cache local. | 0 | 3.000 |
Para obter mais informações sobre estas definições, veja Best Practices for performance improvements using Service Bus Messaging (Melhores Práticas para melhorar o desempenho com as Mensagens do Service Bus). A execução do teste com estas definições produziu o seguinte gráfico:
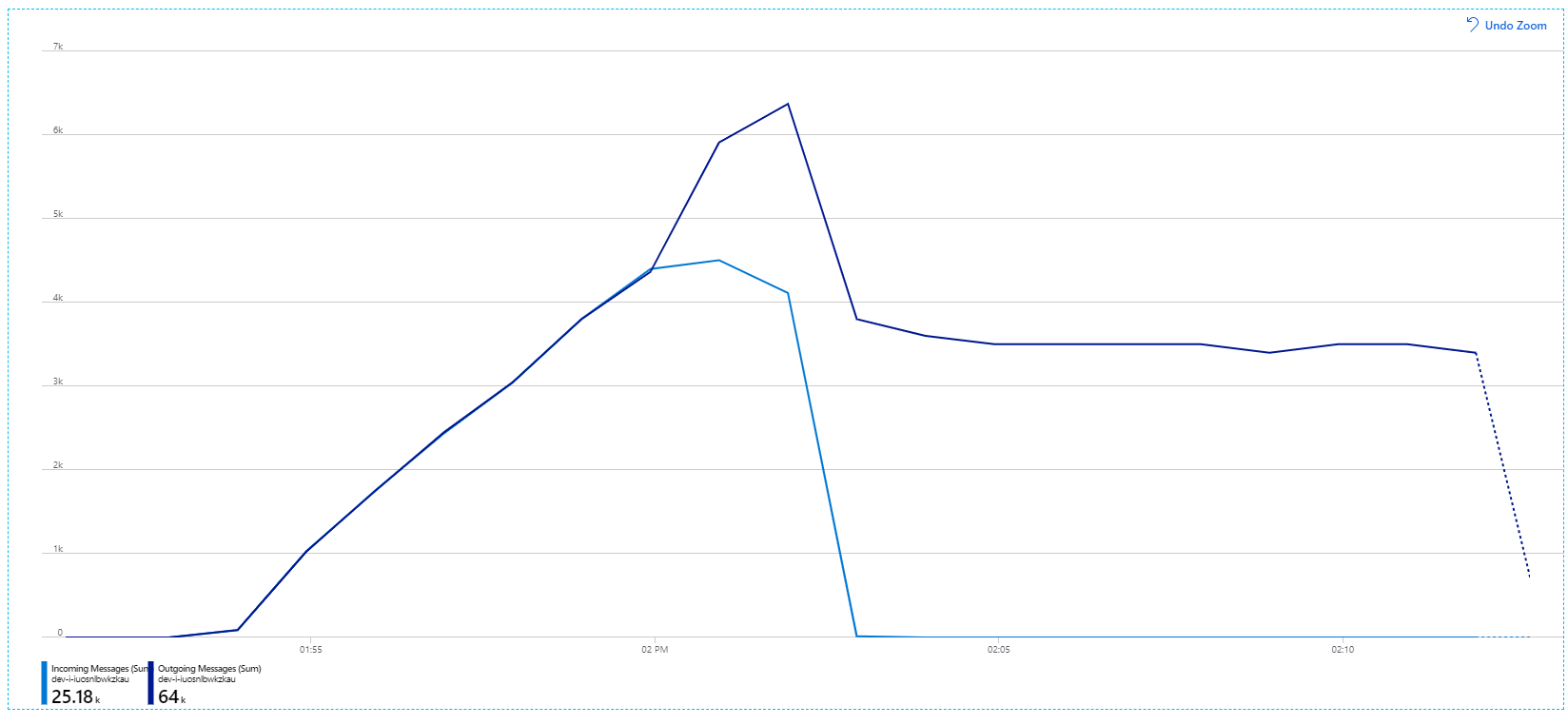
Lembre-se de que as mensagens recebidas são apresentadas a azul claro e as mensagens enviadas são apresentadas a azul escuro.
À primeira vista, este é um gráfico muito estranho. Durante algum tempo, a taxa de mensagens a enviar controla exatamente a taxa de entrada. Mas, então, com cerca de 2:03, a taxa de mensagens recebidas diminui, enquanto o número de mensagens a enviar continua a aumentar, excedendo na verdade o número total de mensagens recebidas. Parece impossível.
A pista para este mistério pode ser encontrada na vista Dependências no Application Insights. Este gráfico resume todas as chamadas que o serviço de Fluxo de Trabalho efetuou ao Service Bus:
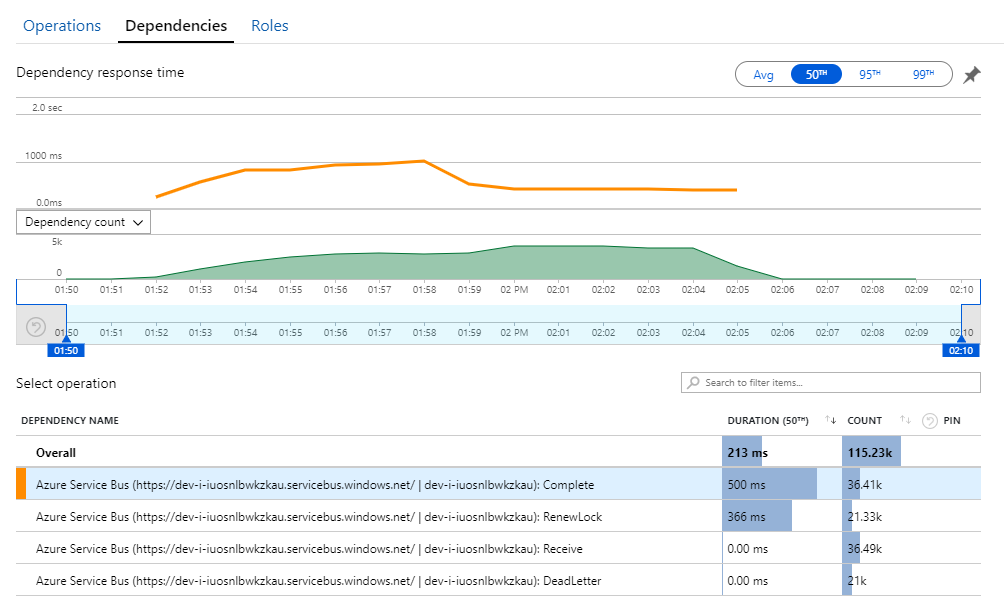
Repare que a entrada para DeadLetter. Estas chamadas indicam que as mensagens estão a entrar na fila de cartas não entregues do Service Bus.
Para compreender o que está a acontecer, tem de compreender a semântica Peek-Lock no Service Bus. Quando um cliente utiliza Peek-Lock, o Service Bus obtém e bloqueia atomicamente uma mensagem. Enquanto o bloqueio é mantido, é garantido que a mensagem não será entregue a outros recetores. Se o bloqueio expirar, a mensagem fica disponível para outros recetores. Após um número máximo de tentativas de entrega (o que é configurável), o Service Bus colocará as mensagens numa fila de cartas não entregues, onde podem ser examinadas mais tarde.
Lembre-se de que o serviço Fluxo de Trabalho está a pré-instalar grandes lotes de mensagens — 3000 mensagens de cada vez). Isto significa que o tempo total para processar cada mensagem é mais longo, o que resulta no tempo limite das mensagens, voltar à fila e, eventualmente, entrar na fila de letras mortas.
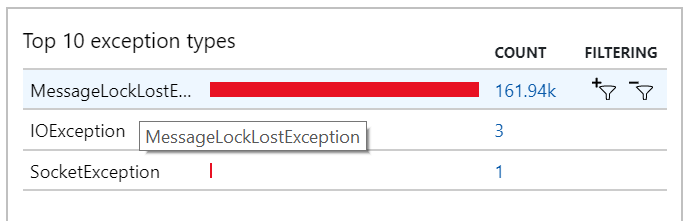
Também pode ver este comportamento nas exceções, onde são registadas MessageLostLockException inúmeras exceções:
Teste 5: Aumentar a duração do bloqueio
Para este teste de carga, a duração do bloqueio de mensagens foi definida como 5 minutos, para evitar tempos limite de bloqueio. O gráfico de mensagens recebidas e enviadas mostra agora que o sistema está a acompanhar a taxa de mensagens recebidas:
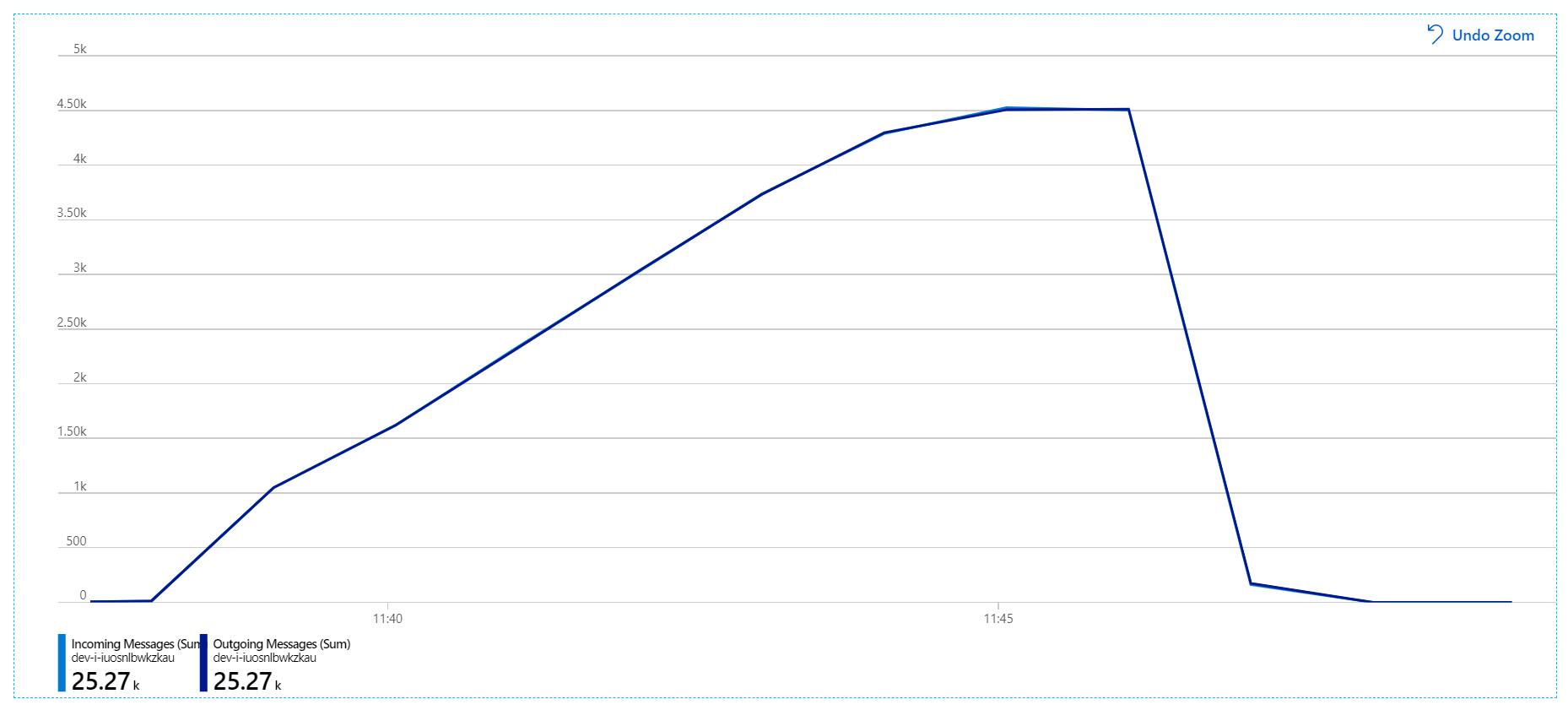
Durante a duração total do teste de carga de 8 minutos, a aplicação concluiu 25 operações K, com um débito máximo de 72 operações/seg, o que representa um aumento de 400% no débito máximo.
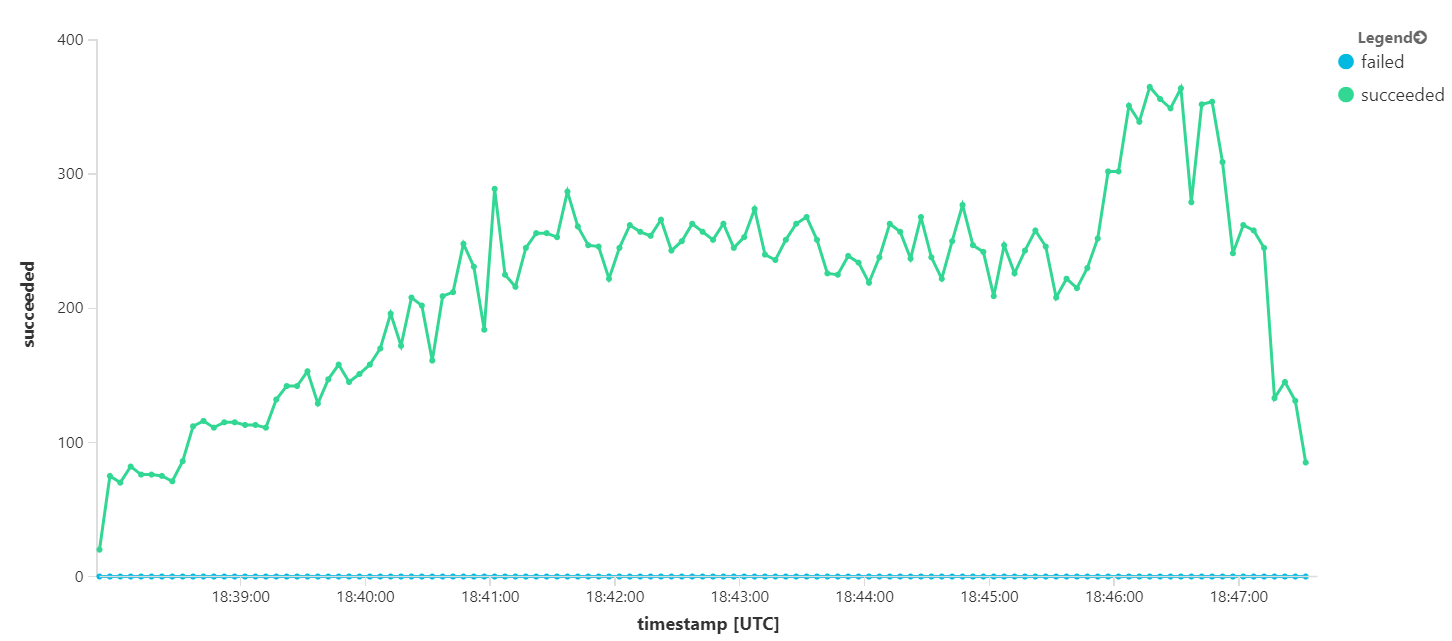
No entanto, executar o mesmo teste com uma duração mais longa mostrou que a aplicação não conseguiu suportar esta taxa:
As métricas de contentor mostram que a utilização máxima da CPU foi próxima de 100%. Neste momento, a aplicação parece estar vinculada à CPU. Dimensionar o cluster pode melhorar o desempenho agora, ao contrário da tentativa anterior de aumentar horizontalmente.
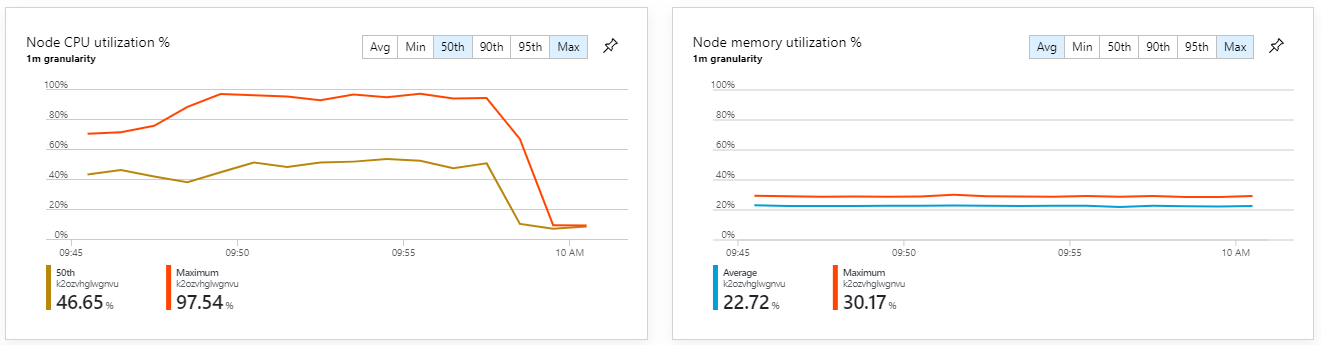
Teste 6: Aumentar horizontalmente os serviços de back-end (novamente)
Para o teste de carga final da série, a equipa aumentou horizontalmente o cluster e os pods do Kubernetes da seguinte forma:
| Definição | Valor |
|---|---|
| Nós do cluster | 12 |
| Serviço de ingestão | 3 réplicas |
| Serviço de fluxo de trabalho | 6 réplicas |
| Serviços do Package, Delivery, Drone Scheduler | 9 réplicas cada |
Este teste resultou num débito sustentado mais elevado, sem atrasos significativos no processamento de mensagens. Além disso, a utilização da CPU do nó manteve-se abaixo dos 80%.
Resumo
Para este cenário, foram identificados os seguintes estrangulamentos:
- Exceções de memória esgotada no Cache do Azure para Redis.
- Falta de paralelismo no processamento de mensagens.
- Duração insuficiente do bloqueio de mensagens, o que leva a que sejam colocados tempos limite de bloqueio e mensagens na fila de letras não entregues.
- Esgotamento da CPU.
Para diagnosticar estes problemas, a equipa de desenvolvimento baseou-se nas seguintes métricas:
- A taxa de mensagens do Service Bus recebidas e enviadas.
- Mapa da Aplicação no Application Insights.
- Erros e exceções.
- Consultas personalizadas do Log Analytics.
- Utilização da CPU e da memória nas informações de contentor do Azure Monitor.
Passos seguintes
Para obter mais informações sobre a conceção deste cenário, veja Estruturar uma arquitetura de microsserviços.