Nota
O acesso a esta página requer autorização. Pode tentar iniciar sessão ou alterar os diretórios.
O acesso a esta página requer autorização. Pode tentar alterar os diretórios.
Azure Cosmos DB
Hubs de Eventos do Azure
Azure Monitor
Azure Stream Analytics
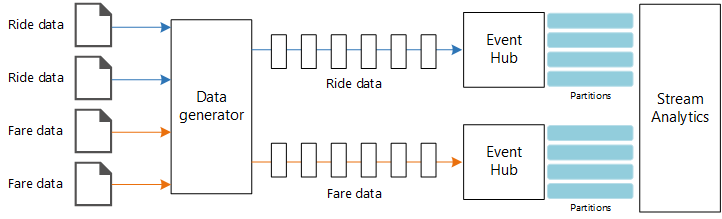
Esta arquitetura de referência mostra um pipeline de processamento de fluxo de ponta a ponta. O pipeline ingere dados de duas fontes, correlaciona registos nos dois fluxos e calcula uma média móvel ao longo de um intervalo de tempo. Os resultados são armazenados para análise posterior.
Arquitetura

Descarregue um ficheiro Visio desta arquitetura.
Workflow
A arquitetura é composta pelos seguintes componentes:
Origens de dados. Nessa arquitetura, existem duas fontes de dados que geram fluxos de dados em tempo real. O primeiro fluxo contém informações de viagem e o segundo contém informações sobre tarifas. A arquitetura de referência inclui um gerador de dados simulado que lê de um conjunto de arquivos estáticos e envia os dados para Hubs de Eventos. Em uma aplicação real, as fontes de dados seriam dispositivos instalados nos táxis.
Hubs de Eventos do Azure. Event Hubs é um serviço de ingestão de eventos. Essa arquitetura usa duas instâncias de hub de eventos, uma para cada fonte de dados. Cada fonte de dados envia um fluxo de dados para o hub de eventos associado.
Azure Stream Analytics. O Stream Analytics é um mecanismo de processamento de eventos. Uma tarefa de Stream Analytics lê os fluxos de dados dos dois hubs de eventos e executa o processamento de stream.
Azure Cosmos DB. A saída do trabalho do Stream Analytics é uma série de registros, que são gravados como documentos JSON em um banco de dados de documentos do Azure Cosmos DB.
Microsoft Power BI. O Power BI é um conjunto de ferramentas de análise de negócios para analisar dados para insights de negócios. Nessa arquitetura, ele carrega os dados do Azure Cosmos DB. Isso permite que os usuários analisem o conjunto completo de dados históricos que foram coletados. Você também pode transmitir os resultados diretamente do Stream Analytics para o Power BI para uma exibição em tempo real dos dados. Para obter mais informações, veja Transmissão em tempo real no Power BI.
Azure Monitor. O Azure Monitor coleta métricas de desempenho sobre os serviços do Azure implantados na solução. Ao visualizá-los em um painel, você pode obter informações sobre a integridade da solução.
Detalhes do cenário
Cenário: Uma empresa de táxis recolhe dados sobre cada viagem de táxi. Para esse cenário, assumimos que há dois dispositivos separados enviando dados. O táxi tem um medidor que envia informações sobre cada viagem - a duração, distância e locais de embarque e desembarque. Um dispositivo separado aceita pagamentos de clientes e envia dados sobre tarifas. A empresa de táxis quer calcular a gorjeta média por quilómetro percorrido, em tempo real, de forma a detetar tendências.
Potenciais casos de utilização
Esta solução é otimizada para o cenário de varejo.
Ingestão de dados
Para simular uma fonte de dados, essa arquitetura de referência usa o conjunto de dados do New York City Taxi Data[1]. Este conjunto de dados contém dados sobre viagens de táxi na cidade de Nova Iorque durante um período de quatro anos (2010–2013). Ele contém dois tipos de registro: dados de viagem e dados de tarifa. Os dados da viagem incluem a duração da viagem, a distância da viagem e o local de embarque e desembarque. Os dados da tarifa incluem valores de tarifas, impostos e gorjetas. Os campos comuns em ambos os tipos de registro incluem número de medalhão, licença de hack e ID do fornecedor. Juntos, estes três campos identificam exclusivamente um táxi mais um motorista. Os dados são armazenados em formato CSV.
[1] Donovan, Brian; Work, Dan (2016): Dados da viagem de táxi de Nova Iorque (2010-2013). Universidade de Illinois em Urbana-Champaign. https://doi.org/10.13012/J8PN93H8
O gerador de dados é uma aplicação .NET que lê os registos e envia-os para Hubs de Eventos do Azure. O gerador envia dados de viagem em formato JSON e dados de tarifa em formato CSV.
Os Hubs de Eventos usam partições para segmentar os dados. As partições permitem que um consumidor leia cada partição em paralelo. Ao enviar dados para Hubs de Eventos, você pode especificar a chave de partição explicitamente. Caso contrário, os registos são atribuídos a partições de forma circular.
Neste cenário específico, os dados de viagem e os dados de tarifa devem ter o mesmo ID de partição para um determinado táxi. Isso permite que o Stream Analytics aplique um grau de paralelismo quando correlaciona os dois fluxos. Um registro na partição n dos dados da viagem corresponderá a um registro na partição n dos dados da tarifa.
No gerador de dados, o modelo de dados comum para ambos os tipos de registro tem uma PartitionKey propriedade que é a concatenação de Medallion, HackLicensee VendorId.
public abstract class TaxiData
{
public TaxiData()
{
}
[JsonProperty]
public long Medallion { get; set; }
[JsonProperty]
public long HackLicense { get; set; }
[JsonProperty]
public string VendorId { get; set; }
[JsonProperty]
public DateTimeOffset PickupTime { get; set; }
[JsonIgnore]
public string PartitionKey
{
get => $"{Medallion}_{HackLicense}_{VendorId}";
}
Esta propriedade é usada para fornecer uma chave de partição explícita ao enviar para Hubs de Eventos:
using (var client = pool.GetObject())
{
return client.Value.SendAsync(new EventData(Encoding.UTF8.GetBytes(
t.GetData(dataFormat))), t.PartitionKey);
}
Processamento de fluxos
O trabalho de processamento de fluxo é definido usando uma consulta SQL com várias etapas distintas. As duas primeiras etapas selecionam registros dos dois fluxos de entrada.
WITH
Step1 AS (
SELECT PartitionId,
TRY_CAST(Medallion AS nvarchar(max)) AS Medallion,
TRY_CAST(HackLicense AS nvarchar(max)) AS HackLicense,
VendorId,
TRY_CAST(PickupTime AS datetime) AS PickupTime,
TripDistanceInMiles
FROM [TaxiRide] PARTITION BY PartitionId
),
Step2 AS (
SELECT PartitionId,
medallion AS Medallion,
hack_license AS HackLicense,
vendor_id AS VendorId,
TRY_CAST(pickup_datetime AS datetime) AS PickupTime,
tip_amount AS TipAmount
FROM [TaxiFare] PARTITION BY PartitionId
),
A próxima etapa une os dois fluxos de entrada para selecionar registros correspondentes de cada fluxo.
Step3 AS (
SELECT tr.TripDistanceInMiles,
tf.TipAmount
FROM [Step1] tr
PARTITION BY PartitionId
JOIN [Step2] tf PARTITION BY PartitionId
ON tr.PartitionId = tf.PartitionId
AND tr.PickupTime = tf.PickupTime
AND DATEDIFF(minute, tr, tf) BETWEEN 0 AND 15
)
Essa consulta une registros em um conjunto de campos que identificam exclusivamente os registros correspondentes (PartitionId e PickupTime).
Nota
Queremos que os fluxos TaxiRide e TaxiFare sejam unidos pela combinação única de Medallion, HackLicense, VendorId e PickupTime. Neste caso, o PartitionId cobre o Medallion, HackLicense e VendorId campos, mas isso não deve ser tomado como geralmente o caso.
No Stream Analytics, as junções são temporais, o que significa que os registros são unidos dentro de uma janela de tempo específica. Caso contrário, o trabalho poderá esperar indefinidamente por um pareamento. A função DATEDIFF especifica a distância temporal com que dois registos correspondentes podem estar separados para uma correspondência.
O último passo do trabalho calcula a gorjeta média por milha, agrupada por uma janela de salto de cinco minutos.
SELECT System.Timestamp AS WindowTime,
SUM(tr.TipAmount) / SUM(tr.TripDistanceInMiles) AS AverageTipPerMile
INTO [TaxiDrain]
FROM [Step3] tr
GROUP BY HoppingWindow(Duration(minute, 5), Hop(minute, 1))
O Stream Analytics fornece várias funções de janela. Uma janela de salto avança no tempo por um período fixo, neste caso um minuto por salto. O resultado é calcular uma média móvel nos últimos cinco minutos.
Na arquitetura mostrada aqui, apenas os resultados do trabalho do Stream Analytics são salvos no Azure Cosmos DB. Para um cenário de big data, considere também usar Captura de Hubs de Eventos para salvar os dados brutos de eventos no Azure Blob Storage. Manter os dados brutos permitirá que você execute consultas em lote sobre seus dados históricos posteriormente, a fim de obter novos insights a partir dos dados.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Otimização de Custos
A Otimização de Custos consiste em procurar formas de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Lista de verificação de revisão de projeto para Otimização de custos.
Utilize a calculadora de preços do Azure para prever os custos. Aqui estão algumas considerações para serviços usados nessa arquitetura de referência.
Azure Stream Analytics
O preço do Azure Stream Analytics é calculado pelo número de unidades de streaming (US$ 0,11/hora) necessárias para processar os dados no serviço.
O Stream Analytics pode ser caro se você não estiver processando os dados em tempo real ou pequenas quantidades de dados. Para esses casos de uso, considere usar o Funções do Azure ou os Aplicativos Lógicos para mover dados dos Hubs de Eventos do Azure para um armazenamento de dados.
Hubs de Eventos do Azure e Azure Cosmos DB
Para obter considerações de custo dos Hubs de Eventos do Azure e do Azure Cosmos DB, consulte o Processamento de fluxo com a arquitetura de referência do Azure Databricks .
Excelência Operacional
A Excelência Operacional abrange os processos operacionais que implantam um aplicativo e o mantêm em execução na produção. Para obter mais informações, consulte Lista de verificação de revisão de projeto para o Operational Excellence.
Monitorização
Com qualquer solução de processamento de fluxo, é importante monitorar o desempenho e a integridade do sistema. O Azure Monitor coleta métricas e logs de diagnóstico para os serviços do Azure usados na arquitetura. O Azure Monitor está incorporado na plataforma Azure e não requer qualquer código adicional na sua aplicação.
Qualquer um dos seguintes sinais de aviso indica que você deve expandir o recurso relevante do Azure:
- Os Hubs de Eventos restringem as solicitações ou estão prestes a atingir a cota diária de mensagens.
- O trabalho do Stream Analytics usa consistentemente mais de 80% das Unidades de Streaming (SU) alocadas.
- O Azure Cosmos DB começa a limitar as solicitações.
A arquitetura de referência inclui um painel personalizado, que é implantado no portal do Azure. Depois de implantar a arquitetura, pode-se exibir o painel abrindo o portal Azure e selecionando TaxiRidesDashboard da lista de painéis. Para obter mais informações sobre como criar e implantar painéis personalizados no portal do Azure, consulte Criar painéis do Azure programaticamente.
A imagem a seguir mostra o painel depois que o trabalho do Stream Analytics foi executado por cerca de uma hora.
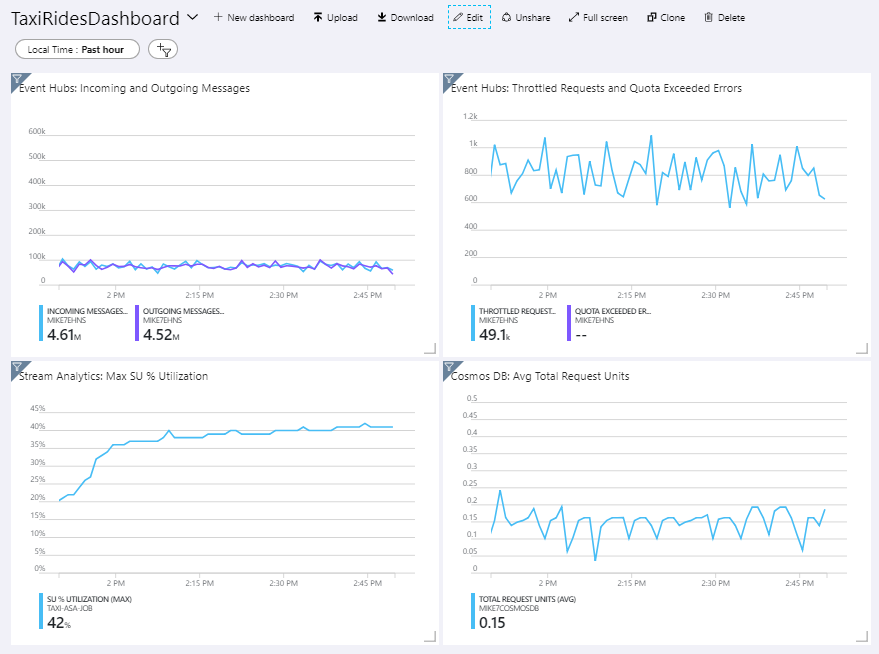
O painel no canto inferior esquerdo mostra que o consumo de SU para o trabalho do Stream Analytics sobe durante os primeiros 15 minutos e, em seguida, estabiliza. Este é um padrão típico à medida que o trabalho atinge um estado estacionário.
Observe que os Hubs de Eventos estão a limitar as solicitações, mostradas no painel do canto superior direito. Uma solicitação limitada ocasional não é um problema, porque o SDK do cliente de Hubs de Eventos tenta automaticamente novamente quando recebe um erro de limitação. No entanto, se vê erros de limitação consistentes, isso significa que o hub de eventos precisa de mais unidades de transferência de dados. O gráfico a seguir mostra uma execução de teste usando o recurso de auto-inflação dos Hubs de Eventos, que dimensiona automaticamente as unidades de taxa de transferência conforme necessário.
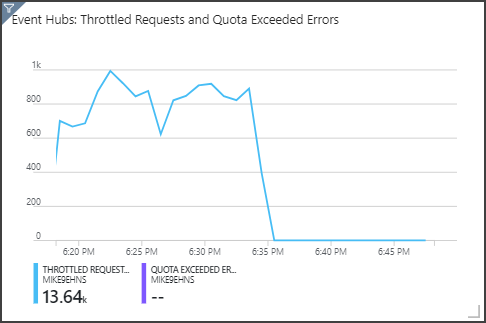
A auto-insuflação foi ativada por volta das 06:35. Você pode ver a queda p nas solicitações limitadas, já que os Hubs de Eventos aumentaram automaticamente para 3 unidades de taxa de transferência.
Curiosamente, isso teve o efeito colateral de aumentar a utilização de SU no trabalho do Stream Analytics. Através da limitação, os Hubs de Eventos reduziram artificialmente a taxa de ingestão para a tarefa do Stream Analytics. Na verdade, é comum que a resolução de um gargalo de desempenho revele outro. Nesse caso, a alocação de SU adicional para o trabalho do Stream Analytics resolveu o problema.
DevOps
Crie grupos de recursos separados para ambientes de produção, desenvolvimento e teste. A utilização de grupos de recursos separados torna mais fácil gerir as implementações, eliminar as implementações de teste e atribuir direitos de acesso.
Use o modelo de template do Azure Resource Manager para implantar os recursos do Azure seguindo a Infraestrutura como Código (IaC). Com modelos, automatizar implantações usando os Serviços de DevOps do Azure ou outras soluções de CI/CD é mais fácil.
Coloque cada carga de trabalho em um modelo de implantação separado e armazene os recursos em sistemas de controle do código-fonte. Você pode implantar os modelos juntos ou individualmente como parte de um processo de CI/CD, facilitando o processo de automação.
Nessa arquitetura, os Hubs de Eventos do Azure, o Log Analytics e o Azure Cosmos DB são identificados como uma única carga de trabalho. Esses recursos estão incluídos em um único modelo ARM.
Considere fasear as suas cargas de trabalho. Implementa para várias fases e faz verificações de validação em cada fase antes de continuares para a próxima fase. Dessa forma, você pode enviar atualizações para seus ambientes de produção de forma altamente controlada e minimizar problemas de implantação imprevistos.
Considere usar o Azure Monitor para analisar o desempenho do seu pipeline de processamento de fluxo.
Para obter mais informações, consulte o pilar de excelência operacional no Microsoft Azure Well-Architected Framework.
Eficiência de desempenho
Eficiência de desempenho é a capacidade de sua carga de trabalho de escalar para atender às demandas colocadas pelos usuários de maneira eficiente. Para obter mais informações, consulte Lista de verificação de revisão de design para Eficiência de desempenho.
Hubs de Eventos
A capacidade de taxa de transferência dos Hubs de Eventos é medida em unidades de taxa de transferência. Você pode dimensionar automaticamente um hub de eventos habilitando a auto-inflação, que dimensiona automaticamente as unidades de taxa de transferência com base no tráfego, até um máximo configurado.
Stream Analytics
Para o Stream Analytics, os recursos de computação alocados para um trabalho são medidos em Unidades de Streaming. Os trabalhos do Stream Analytics são melhor dimensionados se puderem ser paralelizados. Dessa forma, o Stream Analytics pode distribuir o trabalho entre vários nós de computação.
Para a entrada de Hubs de Eventos, utilize a palavra-chave PARTITION BY para particionar a tarefa de Stream Analytics. Os dados serão divididos em subconjuntos com base nas partições dos Hubs de Eventos.
Funções de janelas e junções temporais requerem SU adicional. Sempre que possível, use PARTITION BY para que cada partição seja processada separadamente. Para obter mais informações, consulte Compreender e ajustar unidades de streaming.
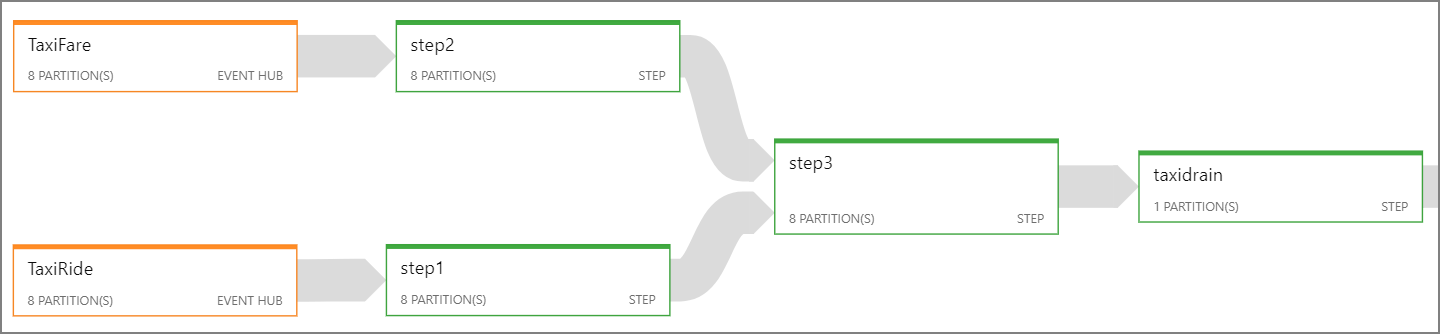
Se não for possível paralelizar todo o trabalho do Stream Analytics, tente dividi-lo em várias etapas, começando com uma ou mais etapas paralelas. Dessa forma, os primeiros passos podem correr em paralelo. Por exemplo, nesta arquitetura de referência:
- As etapas 1 e 2 são
SELECTinstruções que selecionam registros dentro de uma única partição. - A etapa 3 executa uma junção particionada em dois fluxos de entrada. Esta etapa aproveita o fato de que os registros correspondentes compartilham a mesma chave de partição e, portanto, têm a garantia de ter o mesmo ID de partição em cada fluxo de entrada.
- A etapa 4 agrega todas as partições. Esta etapa não pode ser paralelizada.
Use o diagrama de trabalho do Stream Analytics para ver quantas partições são atribuídas a cada etapa do trabalho. O diagrama a seguir mostra o diagrama de trabalho para essa arquitetura de referência:
Azure Cosmos DB
A capacidade de taxa de transferência do Azure Cosmos DB é medida em Unidades de Solicitação (RUs). Para dimensionar um contêiner do Azure Cosmos DB para além de 10.000 RU, você deve especificar uma chave de partição ao criar o contêiner e incluir a chave de partição em cada documento.
Nessa arquitetura de referência, novos documentos são criados apenas uma vez por minuto (o intervalo da janela de salto), portanto, os requisitos de taxa de transferência são bastante baixos. Por esse motivo, não há necessidade de atribuir uma chave de partição neste cenário.